这个例子是抓取禅道-组织 -用户列表里的数据。使用xpath抓取数据,非常的高效,只需要复制出列表中元素的xpath就可以准确定位。 1、 首先找出员工列表中“001”、“admin”、“002”的
这个例子是抓取禅道-组织 -用户列表里的数据。使用xpath抓取数据,非常的高效,只需要复制出列表中元素的xpath就可以准确定位。
-用户列表里的数据。使用xpath抓取数据,非常的高效,只需要复制出列表中元素的xpath就可以准确定位。
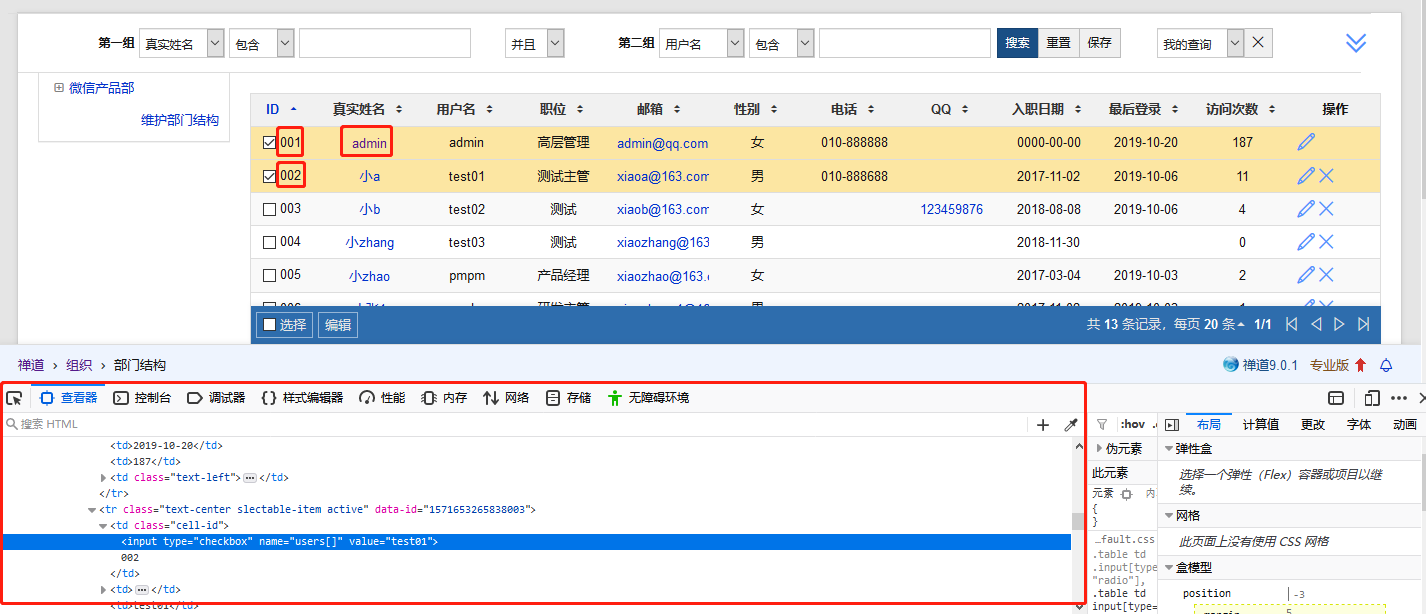
1、 首先找出员工列表中“001”、“admin”、“002”的xpath
“001” xpath: /html/body/div[1]/div[1]/div[4]/form/table/tbody/tr[1]/td[1]/input
“admin” xpath:/html/body/div[1]/div[1]/div[4]/form/table/tbody/tr[1]/td[2]/a
“002” xpath: /html/body/div[1]/div[1]/div[4]/form/table/tbody/tr[2]/td[1]/input
分析得出,整个列表的元素公用的xpath为: /html/body/div[1]/div[1]/div[4]/form/table/tbody/tr
2、将响应的text属性值取出,使用 etree.HTML(text) 将字符串格式的 html 片段解析成 html 文档。
3、取出第一列元素的相对路径,作为item.xpath的参数,就取出第一列元素。将i1打印出来,发现并不是我们需要的值,可以设置断点调试,看到i1[0]的tail属性(i1[0].tail)才是我们需要的第一列“ID”的值。
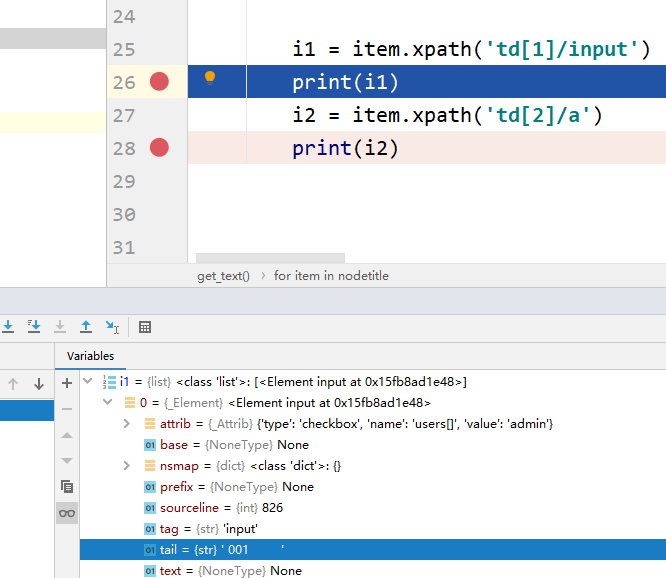
4、同步骤3,可知i2[0].text是我们需要取得第二列“真实姓名”的值。但如果该列值为空的话,‘td[2/a]’路径就变成‘td[2]’,相对路径就是错误的,程序会出错。代码做如下处理:
i2 = item.xpath(‘td[2]/a‘)
if i2 ==[]:
i2=item.xpath(‘td[2]‘)
5、实现代码如下:
from lxml import etree
import requests
from requests.auth import HTTPBasicAuth
from requests.exceptions import RequestException
def get_url(url):
try:
b = requests.post(url, auth=HTTPBasicAuth(‘xxxxx‘, yyyyyy))#xxxxx为禅道登录的用户名 yyyyyy 为禅道登录的密码
if b.status_code == 200:
return b.text
return b.status_code
except RequestException:
return None
def get_text(html):
tree = etree.HTML(html)
xp = ‘/html/body/div[1]/div[1]/div[4]/form/table/tbody/tr‘
nodetitle = tree.xpath(xp)
print(nodetitle)
for item in nodetitle:
i1 = item.xpath(‘td[1]/input‘) #取出第一列的值(ID)
print(i1[0].tail)
i2 = item.xpath(‘td[2]/a‘) #取出第二列的值(真实姓名)
if i2 ==[]:
i2=item.xpath(‘td[2]‘)
print(i2[0].text)
def main():
url = ‘http://39.106.90.48:9000/zentao/company-browse.html‘
html = get_url(url)
t = get_text(html)
print(t)
if __name__ == ‘__main__‘:
main()
6、如果我们想得到其他列的值,可以参考步骤3、4来获取
