1、首先,终端执行命令升级pip: python -m pip install --upgrade pip
2、安装,wheel(建议网络安装) pip install wheel
3、安装,lxml(建议下载安装)
4、安装,Twisted(建议下载安装)
5、安装,Scrapy(建议网络安装) pip install Scrapy
测试Scrapy是否安装成功
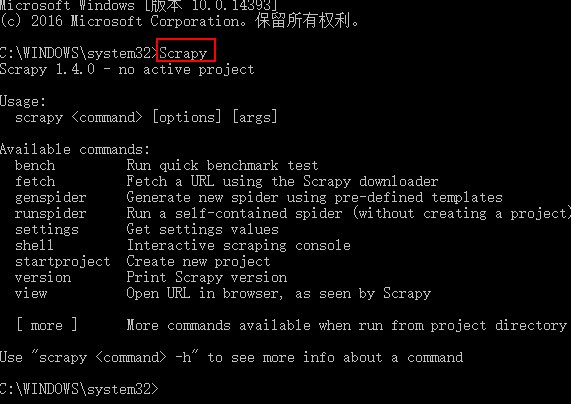
Scrapy框架指令
scrapy -h 查看帮助信息
Available commands:
bench Run quick benchmark test (scrapy bench 硬件测试指令,可以测试当前服务器每分钟最多能爬多少个页面)
fetch Fetch a URL using the Scrapy downloader (scrapy fetch http://www.iqiyi.com/ 获取一个网页html源码)
genspider Generate new spider using pre-defined templates ()
runspider Run a self-contained spider (without creating a project) ()
settings Get settings values ()
shell Interactive scraping console ()
startproject Create new project (cd 进入要创建项目的目录,scrapy startproject 项目名称 ,创建scrapy项目)
version Print Scrapy version ()
view Open URL in browser, as seen by Scrapy ()
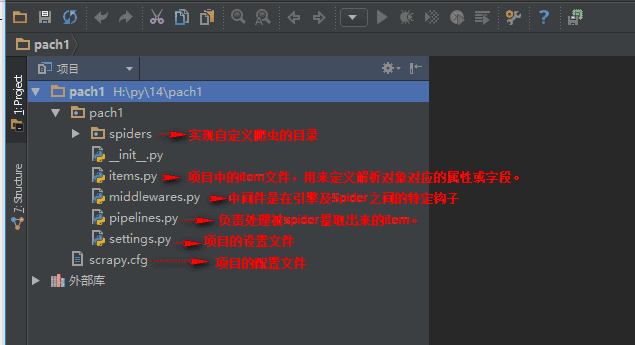
创建项目以及项目说明
scrapy startproject adc 创建项目
项目说明
目录结构如下:
├── firstCrawler
│ ├── init.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── init.py
└── scrapy.cfg
scrapy.cfg: 项目的配置文件tems.py: 项目中的item文件,用来定义解析对象对应的属性或字段。pipelines.py: 负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库)settings.py: 项目的设置文件.- spiders:实现自定义爬虫的目录
- middlewares.py:Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
项目指令
项目指令是需要cd进入项目目录执行的指令
scrapy -h 项目指令帮助
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version (scrapy version 查看scrapy版本信息)
view Open URL in browser, as seen by Scrapy (scrapy view http://www.zhimaruanjian.com/ 下载一个网页并打开)
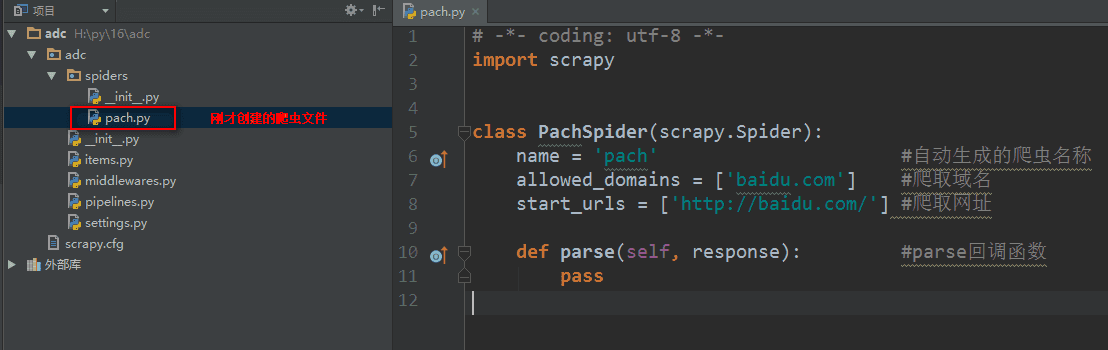
创建爬虫文件
创建爬虫文件是根据scrapy的母版来创建爬虫文件的
scrapy genspider -l 查看scrapy创建爬虫文件可用的母版
Available templates:母版说明
basic 创建基础爬虫文件
crawl 创建自动爬虫文件
csvfeed 创建爬取csv数据爬虫文件
xmlfeed 创建爬取xml数据爬虫文件
创建一个基础母版爬虫,其他同理
scrapy genspider -t 母版名称 爬虫文件名称 要爬取的域名 创建一个基础母版爬虫,其他同理
如:scrapy genspider -t basic pach baidu.com
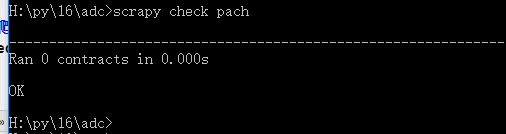
scrapy check 爬虫文件名称 测试一个爬虫文件是否合规
如:scrapy check pach
如果你依然在编程的世界里迷茫,可以加入我们的Python学习扣qun:784758214,看看前辈们是如何学习的。交流经验。从基础的python脚本到web开发、爬虫、django、数据挖掘等,零基础到项目实战的资料都有整理。送给每一位python的小伙伴!分享一些学习的方法和需要注意的小细节,点击加入我们的 python学习者聚集地
scrapy crawl 爬虫名称 执行爬虫文件,显示日志 【重点】
scrapy crawl 爬虫名称 --nolog 执行爬虫文件,不显示日志【重点】