1.情景展示
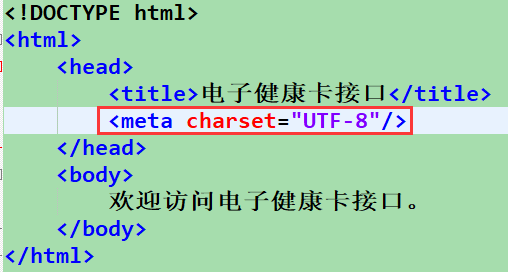
html文件已经声明字符集为UTF-8,但是浏览器访问依旧乱码。
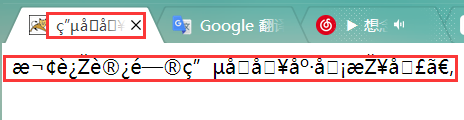
标题和页面内容都是乱码,这是怎么回事?
2.原因分析
charset="UTF-8"是让浏览器要用utf-8来解释,而文档的编码格式,是保存时的选择决定的。
也就是说:这个HTML文件保存时的字符集不是UTF-8!
所以,HTML的编码格式不是utf-8却让浏览器以utf-8的格式进行解析,自然会乱码。
但是,事实果真如此吗?
使用notepad++打开该文件,发现文档的字符集就是:utf-8。

这是不是很奇怪?
3.解决方案
从网上看到,说是默认编码格式是ANSI,需要改成UTF-8,显然,我的格式现在已经是UTF-8了,为什么还是乱码?
抱着死马当活马医的态度,选中文件--》打开方式选择记事本--》文件另存为:(编码格式已经默认为UTF-8了)
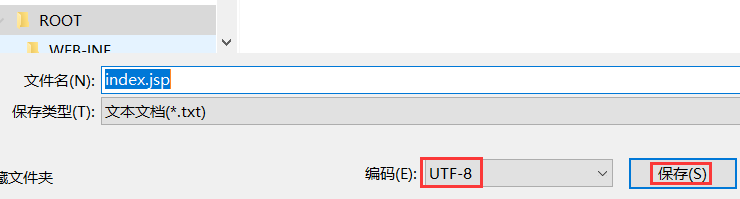
替换原文件。
这个时候,再用notepad++打开该文件,你会发现该文件编码集已经发生了改变:

编码集由UTF-8改为UTF-8-BOM了。
这次再用浏览器访问该网页,中文显示不再乱码了。
4.效果展示
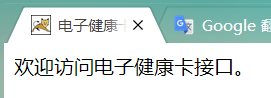
到这就结束了,怎么可能,程序员的探索精神哪里去了?
5.扩展应用
对于已经熟练使用开发工具的人,谁也不会傻到将文档的编码集设置为ANSI的,指定文档编码集的工作已经由开发工具替代了,我们只需要设置一下就好了。
那么,现在来探索一下,使用ANSI编码的html文件,究竟能不能被浏览器正确解析。
第一步:在桌面新建一个文本文档。
双击打开,手敲html模板:

保存之后,修改文件后缀名为html

使用浏览器打开,可以正常显示,不会乱码!
此时的文档编码为:ANSI,可以使用记事本重新打开该html文件--》文件--》另存为:
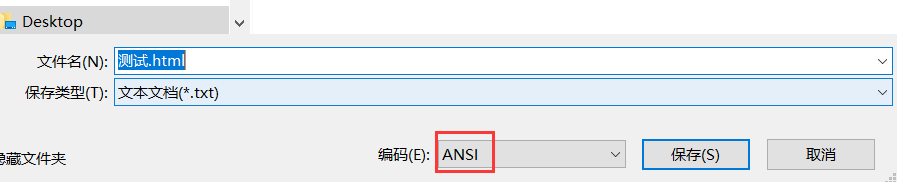
或者,直接使用notepad++打开该文件,右下角显示的就是:该文件的编码集。

这就可以证明,使用记事本创建的文件,默认的编码集是:ANSI。
第二步:添加uf-8声明,告知浏览器以utf-8格式解析html内容

再次打开浏览器,显示已经乱码了。
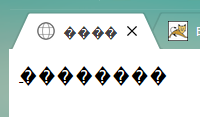
这,才是网络上流传的由ANSI编码引起乱码的真相!!!
第三步:将该文件的字符集改为utf-8。
使用记事本打开该文件--》另存为--》字符集指定为UTF-8,保存,替换原文件

使用浏览器再次访问,这就又可以显示正常了。
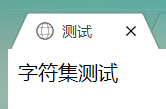
此时显示正常是因为:文档编码集为UTF-8,浏览器也以UTF-8的字符集来解析html文件。
此时,再用notepad++打开,右下角的字符集也变成了:UTF-8-BOM。

第四步:得出结论。
使用Windows记事本新建的文件,默认字符集是:ANSI,另存为UTF-8格式,其实际格式为带有BOM的utf-8,并不是我们平常开发是指定的(真正意义上的)utf-8!
此时,是不是完事了?没有,继续!
新的问题来了:为什么UTF-8-BOM,浏览器解析不乱码,而UTF-8,浏览器解析就乱码呢?
通过notepad++,将该文件的字符集改为无bom格式的utf-8,也就是真正的utf-8。

修改成功。
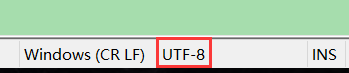
保存,再次使用浏览器打开该文件,你会发现:仍然可以正常显示。
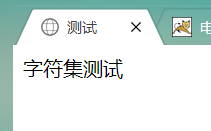
是不是很奇怪?为了进一步验证,我们这次再把刚开始的那个html文件由utf-8-bom改成utf-8试试!
结果还是不行,还是会乱码!

结论:我这种情况,估计很少有人碰到,不管它了,就这吧。不过,可以肯定的是:
不管文档的编码集是UTF-8,还是UTF-8-BOM,都不影响浏览器以UTF-8字符集进行正常解析中文!
但是,至于为什么开头的文件使用UTF-8为何会乱码,无从得知!
写在最后
哪位大佬如若发现文章存在纰漏之处或需要补充更多内容,欢迎留言!!!
相关推荐:
- 个人主页