一、Hystrix 是什么
在微服务架构中,我们将系统拆分成了若干弱小的单元,单元与单元之间通过HTTP或者TCP等方式相互访问,各单元的应用间通过服务注册与订阅的方式相互依赖。由于每个单元都在不同的进程中运行,依赖 远程调用 的方式执行,这样就可能引起因为网速变慢或者网络故障导致请求变慢或超时,若此时调用方的请求在不断增加,最后就会因等待出现故障的依赖方响应形成任务积压,最终导致自身服务的瘫痪。
Hystrix 是Netflix 中的一个组件库,它隔离了服务之间的访问点,阻止了故障节点之间可能会引起的雪崩效应,并提供了后备选项。
在微服务架构中,存在着许多的服务单元,若单一节点的故障,就很容易因为依赖关系而引发故障的蔓延,最终导致整个生态系统的瘫痪。为了解决这样的问题,产生了 断路器 等一系列的保护机制措施。
在 分布式架构中 ,断路器模式的作用也是类似的,当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
雪崩效应
雪崩效应就像是水滴石穿,蝴蝶效应一样,是指微小的事物随着时间的推移,会变得越来越巨大,从而对整个环境造成影响的现象。例如:在生态系统中,某一类物种的灭绝可能对整个生态系统造成不了太大的损失,但是这类物种的灭绝可能会引发其他物种的死亡,其他物种的灭绝又会影响另外一种物种的灭亡,就像雪球越滚越大,最终会导致整个生态系统的崩溃。
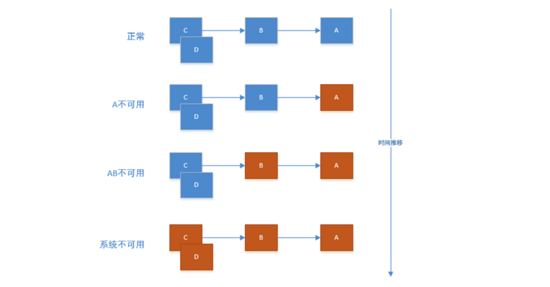
如上图所示:A作为服务提供者,B为A的服务消费者,C和D是B的服务消费者。A不可用引起了B的不可用,并将不可用像滚雪球一样放大到C和D时,雪崩效应就形成了。
雪崩效应产生场景
流量激增 : 比如异常流量,用户重试导致系统负载升高;
缓存刷新 : 假设A为 client 端,B为 Server 端,假设A系统请求都流向B系统,请求超出了B系统的承载能力,就会造成B系统崩溃
连接未释放 : 代码循环调用的逻辑问题,资源未释放引起的内存泄漏等问题;
硬件故障 : 比如宕机,机房断电等
线程同步等待 : 系统间经常采用同步服务调用模式,核心服务和非核心服务共用一个线程池和消息队列。如果一个核心业务线程调用非核心业务线程,这个非核心线程交由第三方系统完成,当第三方系统本身出现问题,导致核心线程阻塞,一直处于等待状态,而进程间的调用是有超时限制的,最终这条线程将断掉,也可能引发雪崩;
常见解决方案
针对上述的雪崩问题,每一条都有一个自己的解决方案,但是任何一个解决方案能够应对所有场景
- 针对流量激增,采用自动扩容以应对流量激增,或者在负载均衡器上安装限流模块
- 针对缓存刷新,参考Cache应用的服务过载案例研究
- 针对硬件故障,采用多机房灾备,跨机房路由
- 针对同步等待,采用线程隔离,熔断器等机制
通过实践发现,线程同步等待是最常见引发的雪崩效应的场景。
二、Hystrix断路器搭建
在开始使用Spring Cloud Hystrix断路器之前,我们先用之前实现的一些内容作为基础,构建一个如下图所示的服务调用关系:

如图所示,上面需要的角色有三个,服务有四个
- ribbon-connsumer: ribbon消费者,消费server-provider提供的服务
- server-provider: 服务提供者,提供服务供消费者消费(有点像父母默默的付出一样),启动两个实例,还记得怎么启动吗?—server.port 启动
- eureka-server: eureka注册中心,提供最基本的订阅发布功能。消费者和服务提供者都需要往注册中心注册自己
依次启动上面的四个服务,发现注册中心已经成功注册了四个服务(包括自己)

调用http://localhost:9000/ribbon-consumer 发现能够通过Ribbon进行远端调用
在未加入断路器之前,关闭ribbon-consumer 的连接,再次调用http://localhost:9000/ribbon-consumer,发现服务无法提供(使用Postman 测试)

下面开始引入Hystrix
在ribbon-consumer 工程的pom.xml的dependency节点下引入spring-cloud-starter-hystrix依赖
在ribbon-consumer 工程的 主加载类 中添加 @EnableCircuitBreaker 开启断路器的功能
注意:这里也可以使用@SpringCloudApplication注解来修饰应用主类,具体定义如下
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
public @interface SpringCloudApplication {}
SpringCloudApplication 注解上有@EnableCircuitBreaker 注解,用来开启断路器的功能,其他主要注解是@SpringBootApplication ,这个注解是SpringBoot的启动类注解, @EnableDiscoveryClient该注解可以发现Eureka注册中心
改造消费方式,新增 HystrixService 类,并且注入 RestTemplate 实例,然后,将在RibbonController中对RestTemplate 的使用迁移到hystrixService方法中,最后,在hystrixService上添加@HystrixCommand注解来指定回掉方法。
// HystrixService
@Service
public class HystrixService {
@Resource
RestTemplate restTemplate;
// 指定回掉方法是下面的hystrixCallback
@HystrixCommand(fallbackMethod = "hystrixCallBack")
public String hystrixService(){
return restTemplate.getForEntity("http://server-provider/hystrix",String.class).getBody();
}
public String hystrixCallBack(){
return "error";
}
}
服务提供者 的业务非常简单,具体代码如下
@RequestMapping(value = "/hystrix", method = RequestMethod.GET)
public String hystrix(){
return "hystrix";
}
下面来验证一下通过断路器的回掉实现,重启之前关闭的8081端口,恢复成为四个服务的状态,并确保http://localhost:9000/ribbon-consumer/ 能够提供服务,并且以轮询的方式循环访问8081 和 8082 端口的服务。此时断开8081端口,发现页面上展示的不再是 hystrix ,而是"error",而另一个服务是正常能够打印。
三、断路器优化
经过以上服务的搭建,相信你已经能够搭建出来最基本的Hystrix熔断器,并且实现了服务熔断机制,下面就来对断路器做一下简单的优化,来模拟 服务阻塞(长时间未响应) 的情况。
优化 server-provider 代码如下:
@RequestMapping(value = "/hystrix", method = RequestMethod.GET)
public String hystrix() throws InterruptedException {
ServiceInstance serviceInstance = discoveryClient.getLocalServiceInstance();
// 让线程等待几秒钟
int sleepTime = new Random().nextInt(3000);
Thread.sleep(sleepTime);
System.out.println("weak up!!!");
log.info("sleepTime = " + sleepTime);
return "hystrix";
}
依次启动所有的服务,在主页上访问 http://localhost:9000/ribbon-consumer ,多次刷新主页,发现error 和 hystrix 是交替出现的,这是为何?
因为hystrix断路器的 默认超时时间 是2000毫秒,所以这里采用了0 - 3000 的随机数,也就是访问请求在 0 -2000 毫秒内是不超时的,不会触发断路器,而> 2000 毫秒是超市的,默认会触发断路器。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自由互联。