目录 一. 下载环境 二. 创建Hadoop用户 1.进入用户,打开终端输入如下命令: 2.设置密码 三. 进行Hadoop内部环境的搭建 四. 安装ssh并配置无密码登陆 1.登陆 2.设置无密码登陆 五.安装Java环
目录
- 一. 下载环境
- 二. 创建Hadoop用户
- 1.进入用户,打开终端输入如下命令:
- 2.设置密码
- 三. 进行Hadoop内部环境的搭建
- 四. 安装ssh并配置无密码登陆
- 1.登陆
- 2.设置无密码登陆
- 五.安装Java环境
- 六.安装Hadoop
- 七.Hadoop伪分布配置
- 1.配置文件
- 2.开启NameNode 和 DataNode 守护进程
- 八.Hadoop集群搭建
- 总结
一. 下载环境
Ubuntu 2.x.x 版本
二. 创建Hadoop用户
在虚拟机创建安装完成后。
1.进入用户,打开终端输入如下命令:
sudo useradd -m hadoop -s /bin/bash
则创建好了可以登陆的Hadoop用户
/bin/bash 作为 shell
2.设置密码
在终端输入
sudo passwd hadoop #需输入两次密码 sudo adduser hadoop sudo #给Hadoop添加管理员权限
完成
三. 进行Hadoop内部环境的搭建
更新apt
打开终端输入
sudo apt-get update #更新apt sudo apt-get install vim #下载vim 用于修改配置文件
四. 安装ssh并配置无密码登陆
1.登陆
sudo apt-get install openssh-serve #下载 ssh localhost #登陆 首次登陆输入yes并输入密码登陆完成
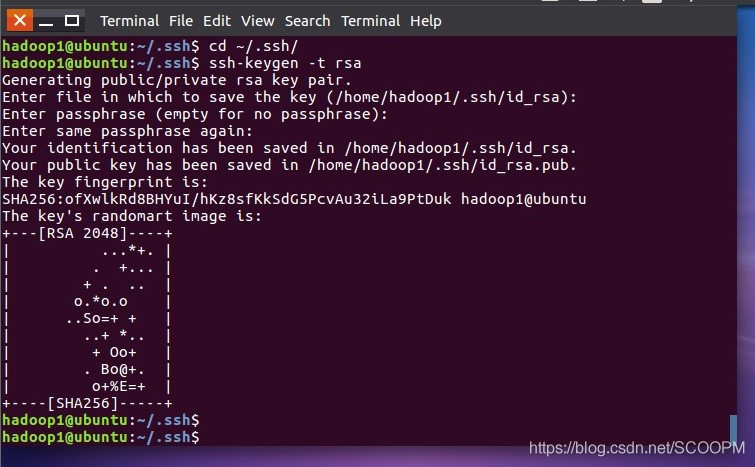
2.设置无密码登陆
exit #退出登陆 ssh-keygen -t rsa #出现提示后按回车 cat ./id_rsa.pub >> ./authorized_keys #加入授权 ssh localhost #再次登陆ssh 不需要密码
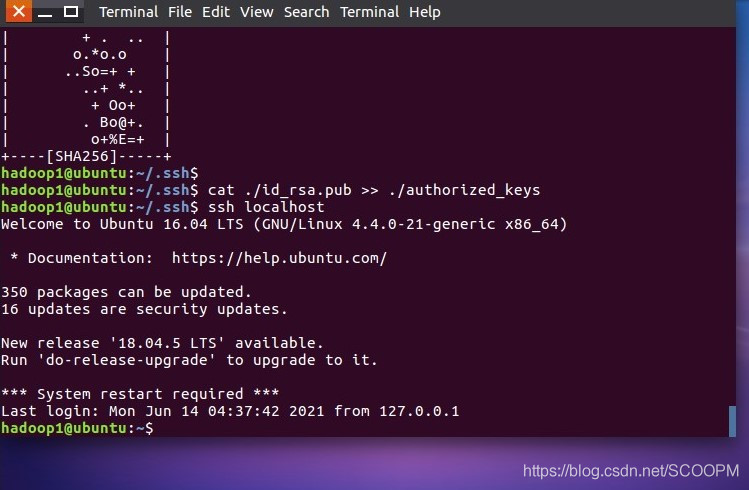
若出现需要密码登陆但错误,需要将ssh删除,重新下载安装进行配置
rm -rf ~/.ssh #删除ssh
五.安装Java环境
先寻找Java下载的镜像网站
如华为,清华等
再输入相应的代码进行下载
wget https://repo.huaweicloud.com/java/jdk/8u171-b11/jdk-8u171-linux-x64.tar.gz
之后输入以下指令进行解压
cd /usr/lib sudo mkdir jvm #创建/uer/lib/jvm 目录存放JDK文件 cd sudo tar -zxvf ./jdk-8u171-linux-x64.tar.gz -C /usr/lib/jvm #解压到/usr/lib/jvm目录中 cd ~ vim ~/.bashrc #环境变量配置文件
添加以下内容到第一行
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
退出后使命令立即生效
source ~/bashrc java -version #查看是否安装成功
六.安装Hadoop
和安装Java类似,搜索镜像并下载
下载完成后将Hadoop安装至/usr/lib中
sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中 cd /usr/local/ sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop sudo chown -R hadoop ./hadoop # 修改文件权限
cd /usr/local/hadoop ./bin/hadoop version #检查版本信息
七.Hadoop伪分布配置
1.配置文件
cd /usr/loca/hadoop/etc/hadoop/ gedit ./etc/hadoop/core-site.xml #修改core-site.xml的配置
将其中的
<configuration> </configuration>
改为
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同理将hdfs-site.xml中的改为
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行NameNode的格式化:
cd /usr/local/hadoop ./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
2.开启NameNode 和 DataNode 守护进程
cd /usr/local/hadoop ./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
若出现ssh提示,输入yes 出现WARN提示可以忽略启动 Hadoop 时提示 Could not resolve hostname ,输入
vim ~/.bashrc
添加环境变量
export HADOOP_HOME=/usr/local/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
完成后执行
soure ~/.bashrc #使变量生效 ./sbin.start-dfs.sh #启动Hadoop jps #查看是否启动成功,若有NameNode ,DataNode,SecondaryNameNode则成功启动
若DataNode无法启动
cd /usr/local/hadoop ./sbin/stop-dfs.sh # 关闭 rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据,慎用 ./bin/hdfs namenode -format # 重新格式化 NameNode ./sbin/start-dfs.sh # 重启
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
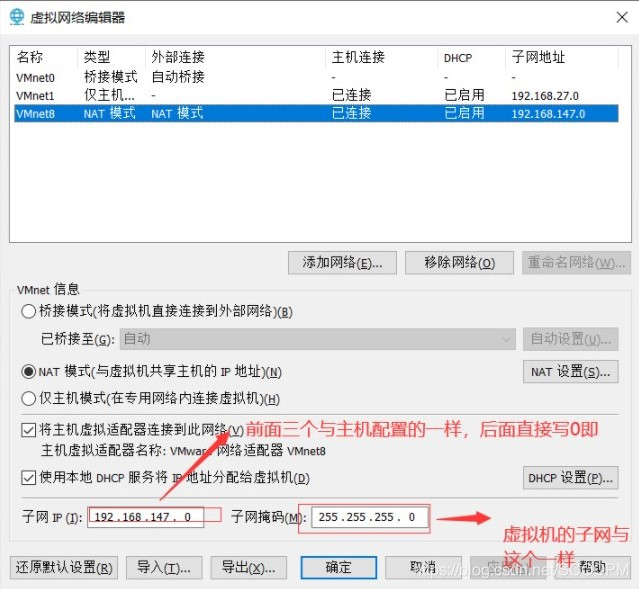
八.Hadoop集群搭建
按图调整网络设置

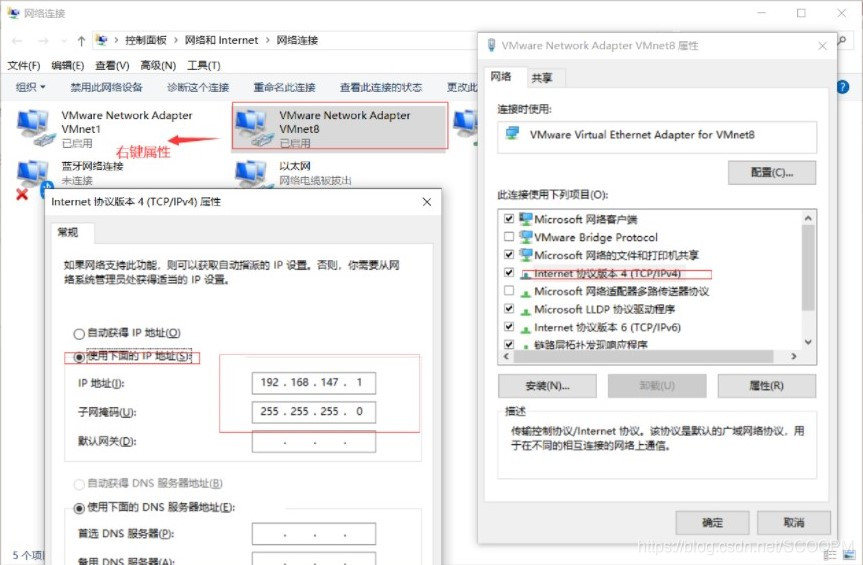
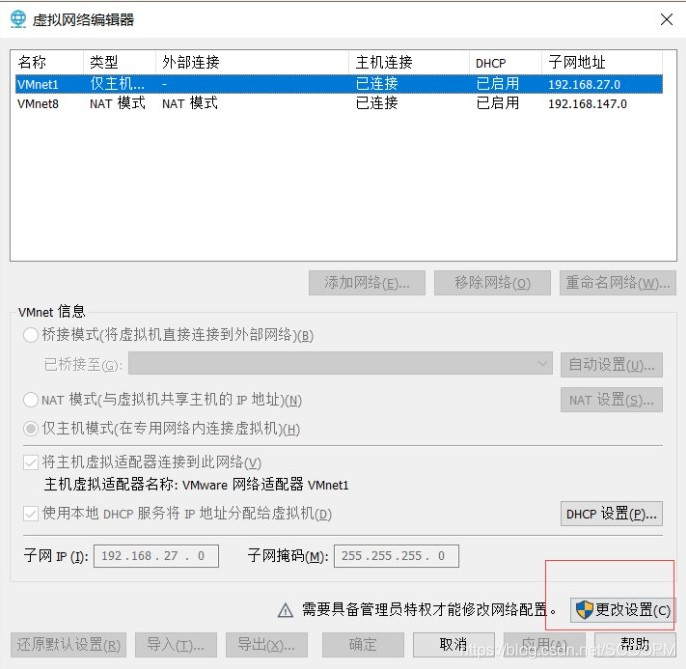
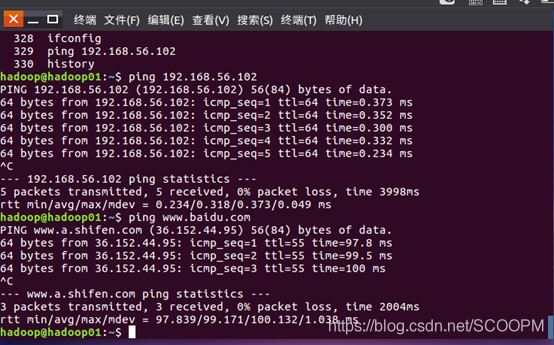
ping 通则说明成功
总结
本篇文章就到这里了,希望能给您带来帮助,也希望您能够多多关注自由互联的更多内容!