微信小程序开发教程栏目带大家学习如何优化小程序中的css treeshaking。

前言
em...我写这工具的原因就是为了上班多划水,少费脑,少犯错,一劳永逸!
每次局部改版老页面时,我不会去删除老的css。因为很麻烦,而且又害怕不小心删出了不可预估的样式错乱。
所以我基本上都是在css文件的最后一行去添加新的样式,然后......,css文件越来越大。所以为了解决这种手动删除css的问题,开发了一个小工具。
我们最终实现效果是通过终端命令去完成css treeshaking
// 到项目目录下cd Documents/xxx/xcx// 微信qts-lint css wx// 支付宝qts-lint css alipay复制代码
处理命令行
如何全局接收qts-lint命令
配置package.json文件的bin字段,全局安装后就可以识别qts-lint xxxx命令啦,是不是很简单
{ "name": "xxx", "version": "1.0.0", "description": "小程序代码", "bin": { "qts-lint": "./bin.js"
}
}复制代码如何接收命令行参数
使用commander接收命令,区分执行的是微信还是支付宝,再去执行对应的逻辑
关于commander我就不具体介绍了,大家可以自己看看文档
const program = require("commander");
program
.command("css <app-type>") // 参数
.description("格式化,css tree-shaking") // 描述
.action((type, command) => { // do something...
});复制代码获取css依赖关系
前面我们说了怎么去接收命令行命令,接下来我们就进入正题,如何对小程序css进行tree shaking。
目前我们使用插件purify-css来做tree shaking,所以就需要获取css的依赖关系来确定哪些css是页面没用到的。
获取小程序所有页面
小程序所有页面都在app.json中维护,app.json的格式都是如下所示
{ "pages": [ "pages/index/index", "pages/login/login",
...
], "subPackages": [
{ "root": "mine", "pages": [ "/index/index",
...
]
}
],
...
}复制代码所以为了获取主包和分包中的所有页面,就需要去循环pages和subPackages,特别需要注意的是subPackages的路由是由root+pages组合而成的,下方就是我们获取小程序中所有页面路由的方法
function readPages(json = {}, root) { let pages = (json.pages || []).map(p => path.join(root, p));
json.subPackages &&
json.subPackages.forEach(element => {
pages = pages.concat(element.pages.map(p => path.join(root, element.root, p)));
}); return pages;
}复制代码获取css的依赖关系
循环获取到的页面,获取每个页面对应的css,js,wxml,json。
保存得到的数据
{ "css url": ["js url", "wxml url", ...]
}复制代码但是页面还存在组件和引用,所以我们还需要
- 获取组件css,js,wxml,如果是组件则加入父页面数组的同时保存自身的键值对
- 解析wxml文件,获取引用,将引用路径添加到数组里
- 解析引用的文件,判断是否还存在引用文件,存在回到步骤1
- 解析json文件,存在组件回到步骤1
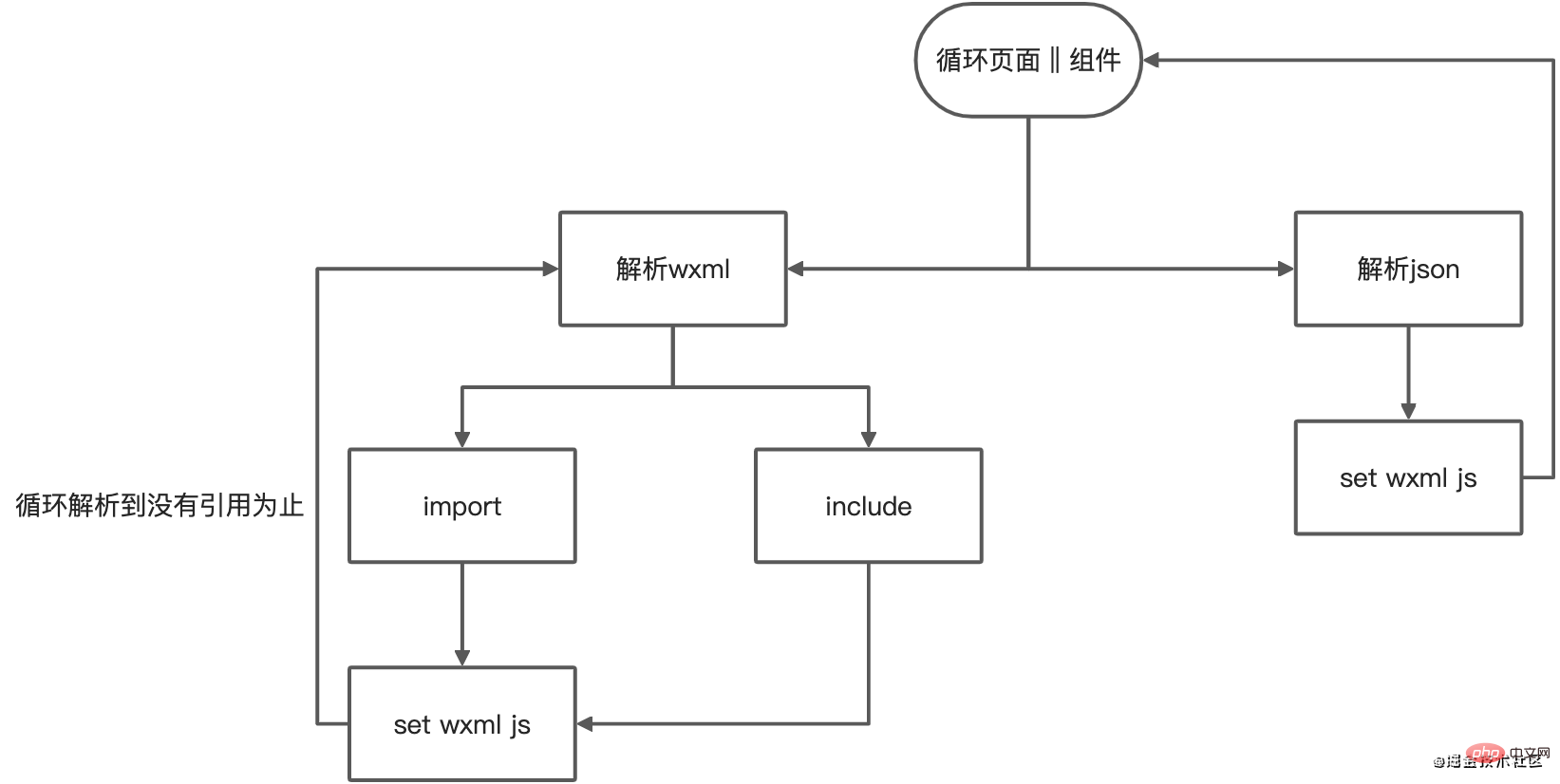
上面我们说到要解析wxml,那么我们该如何去解析wxml呢?
可以使用htmlparser2解析后循环节点,获取type是tag而且name等于import或include的标签,然后再拿到该标签的src,就可以获取到该页面的引用或引用里的引用了
这时就会得到一个像下面这样的css依赖关系结构(包括页面,组件,引用)
{ // 页面css
"/pages/index/index.css": [ // 页面
"/pages/index/index.js", "/pages/index/index.wxml", // 组件
"/pages/components/title/index.js", "/pages/components/title/index.wxml", // 引用模版
"/pages/template/index.wxml"
], // 组件css
"/pages/xxx/xxx.css":[ // 父页面
"/pages/index/index.js", "/pages/index/index.wxml", // 组件的页面
"/pages/index/index.js", "/pages/index/index.wxml",
...
],
...
}复制代码这里大家可能会有2个疑惑
为啥目前页面的css还要关联组件的wxml和js?
因为支付宝存在样式穿透,而我们项目是多人开发的,所以怕存在组件的样式在页面写了,组件就没写的情况,所以做了这种兼容
为啥目前组件的css也要关联页面的wxml和js?
可能存在页面传组件className,而样式枚举写在组件内的情况,那么只能关联页面才能拿到传入的className。这里可能存在样式多删的情况,比如样式里写里四种样式,但是实际用到的只有一种,那可能就会把其它3种删掉,这就不是我们想要的效果,目前的解决办法只有在js里加上枚举的className注释,purify-css检查到js里出现了需要的几个className的枚举后就不删除css里的样式了
删除css
上面我们获取到css依赖关系后,直接利用purify-css完成删除css的操作啦
purify('css url', [...], options)复制代码
弱小的我源码和其它插件放在一起,大家有兴趣可以看看哟
源码链接:www.npmjs.com/package/xcx…
npm 全局
$ npm i -g xcx-lint-qts复制代码
yarn 全局
$ yarn global add xcx-lint-qts复制代码
// 到项目目录下cd Documents/xxx/xcx// 微信qts-lint css wx// 支付宝qts-lint css alipay复制代码
推荐:微信小程序开发教程
以上就是来优化 小程序中的css treeshaking的详细内容,更多请关注自由互联其它相关文章!