局部性原理
程序在访问数据时,都趋于聚集在一片连续的区域中,这被称为局部性原理。
按时间和空间划分为两类:
- 时间局部性:如果一个数据正在被访问,那么近期它很可能再次被访问。
- 空间局部性:如果某一个位置的数据被访问,那么这个问题附近的数据很可能被访问。
针对局部性原理,CPU和操作系统都有具体的实现。
本文主要总结梳理CPU和操作系统的局部性原理在Java后端中的影响与意义。
CPU空间局部性
如下图是Java的内存模型
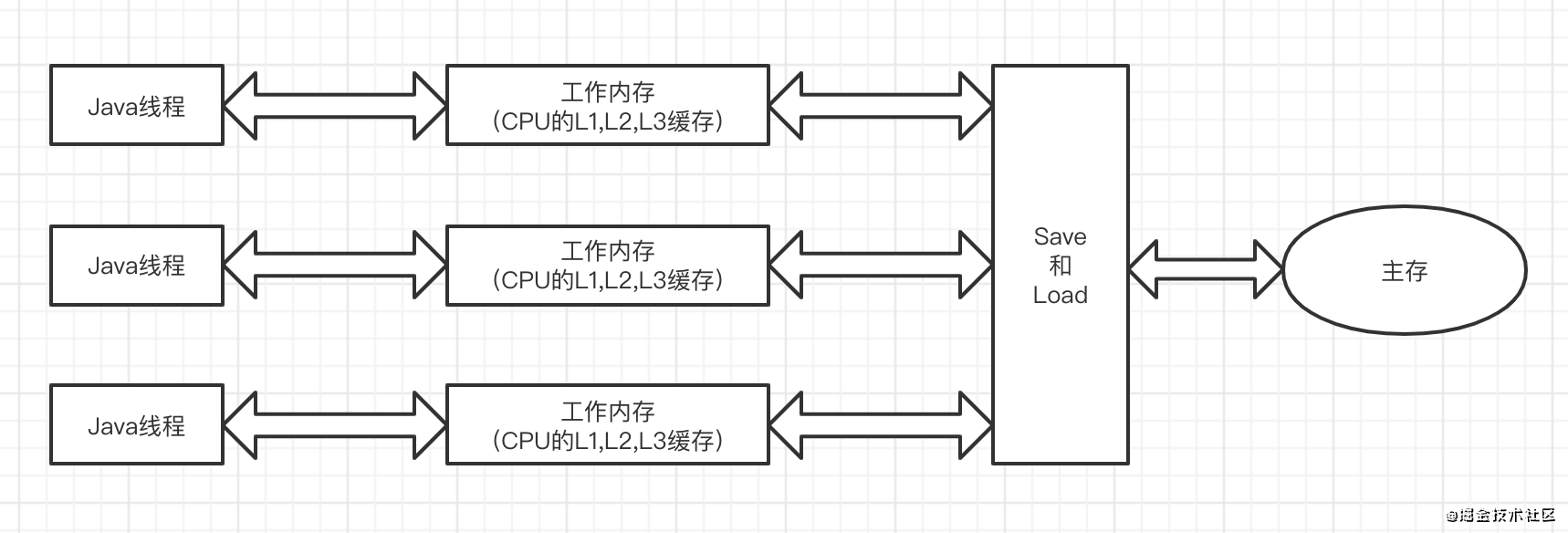
我们知道CPU为提高从内存中读数据的性能,有L1、L2、L3三个级别的高速缓存。
CPU利用局部性原理,在从内存读取数据项到缓存时,将该内存附近的数据块也一并读取到缓存中,这一过程称为预读。
即读取连续空间的内存要比内存随机访问的性能要高,这一点用Java程序可以证明。
public static void main(String[] args) {
int[][] arr = new int[10000][10000];
int sum = 0;
long startTime = System.currentTimeMillis();
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[0].length; j++) {
sum += arr[i][j];
}
}
System.out.println("数组顺序访问耗时:" + (System.currentTimeMillis() - startTime) + "ms");
sum = 0;
startTime = System.currentTimeMillis();
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[0].length; j++) {
sum += arr[j][i];
}
}
System.out.println("数组非顺序访问耗时:" + (System.currentTimeMillis() - startTime) + "ms");
}
这是一段对二维数组循环读取的代码。
程序的上半部分是按数组的第二维开始顺序读取,即二维数组逐行按内存连续空间顺序访问。
下半部分则是按数组的第一维按列读取,不是顺序访问。
分别经过10000*10000次的数组访问后,其运行结果如下:

由此可见,对内存的顺序访问性能优于随机访问。
磁盘空间局部性
在Java日常开发中,很多的中间件都需要跟磁盘文件打交道,这些磁盘数据的高性能访问也都依托于局部性原理,比如:
- MySql的日志文件
- MQ消息数据
我们知道MySql的数据最终都保存在磁盘中,为减少磁盘IO提高性能,InnoDB引擎底层依托BufferPoll+redo log机制来提高mySql读写性能(具体可参考MySql原理总结)。而针对redo log、undo log、binlog的读写避免不了磁盘IO,那么这里就利用操作系统的PageCache机制,对磁盘数据顺序读写,使得磁盘IO的性能近乎于内存性能。
我们常说kafka和rocketMQ是高性能的消息中间件,其中一部分高性能就依托于对磁盘文件的顺序读写。比如commit log的顺序写入,kafka中partition、rockerMQ中consumerQueue中消息的顺序读写。同样的也是利用操作系统的PageCache机制。
PageCache
页缓存(PageCache)是OS对文件的缓存,用于加速对文件的读写。一般来说,程序对文件进行顺序读写的速度几乎接近于内存的读写速度,主要原因就是由于OS使用PageCache机制对读写访问操作进行了性能优化,将一部分的内存用作PageCache。
对于数据的写入,OS会先写入至Cache内,随后通过异步的方式由pdflush内核线程将Cache内的数据刷盘至物理磁盘上。
对于数据的读取,如果一次读取文件时出现未命中PageCache的情况,OS从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行预读取。
而PageCache就是局部性原理的实现。
时间局部性
时间局部性可能在我们日常业务开发中体现得更明显。
类似LRU缓存都是其具体实现。
另外CPU的指令重排序也贴点边,比如对一个数据的访问计算,优先将于这数据有关的指令排在一起处理。
参考
- 知乎:如何理解操作系统中的局部性原理
- gitHub:RocketMQ设计文档
总结
到此这篇通过Java视角简单谈谈局部性原理的文章就介绍到这了,更多相关Java局部性原理内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!