目录
- 1. 你知道JVM内存模型吗?
- 2. 你知道重排序是什么吗?
- 3. happens-before是什么,和as-if-serial有什么区别
- 总结
1. 你知道JVM内存模型吗?
在Java的并发中采用的就是JVM内存共享模型即JMM(Java Memory Model),它其实是是JVM规范中所定义的一种内存模型,跟计算机的CPU缓存内存模型类似,是基于CPU缓存内存模型来建立的,Java内存模型是标准化的,屏蔽掉了底层不同计算机的区别。
那我们先来讲下计算机的内存模型:
其实早期计算机中CPU和内存的速度是差不多的,但在现代计算机中,CPU的指令速度远超内存的存取速度,由于计算机的存储设备与处理器的运算速度有几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理器运算速度的高速缓存(Cache)来作为内存与处理器之间的缓冲。
将运算需要使用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步回内存之中,这样处理器就无须等待缓慢的内存读写了。
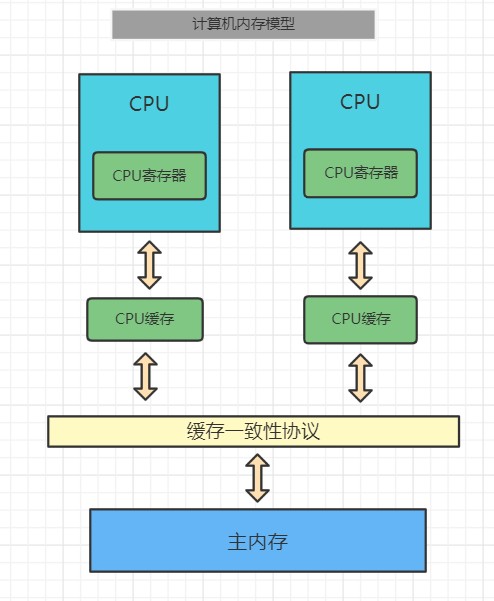
基于高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但是也为计算机系统带来更高的复杂度,因为它引入了一个新的问题:缓存一致性(CacheCoherence)。
在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存(MainMemory)。
而我们可以打开任务管理器,可以进入性能 --> CPU中可以看到L1缓存、L2缓存和L3缓存。
可以看到我们CPU跟我们计算机之间交互的高速缓存。一般的流程,就是计算机会先从硬盘从读取数据到主内存中,又会从主内存读取数据到高速缓存中,而CPU读取的数据就是高速缓存中的数。
我们现在再来看看JMM:
JMM是定义了线程和主内存之间的抽象关系:线程之间的共享变量存在主内存(MainMemory)中,每个线程都有一个私有的本地内存(LocalMemory)即共享变量副本,本地内存中存储了该线程以读、写共享变量的副本。本地内存是Java内存模型的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器等。
JMM模型图:
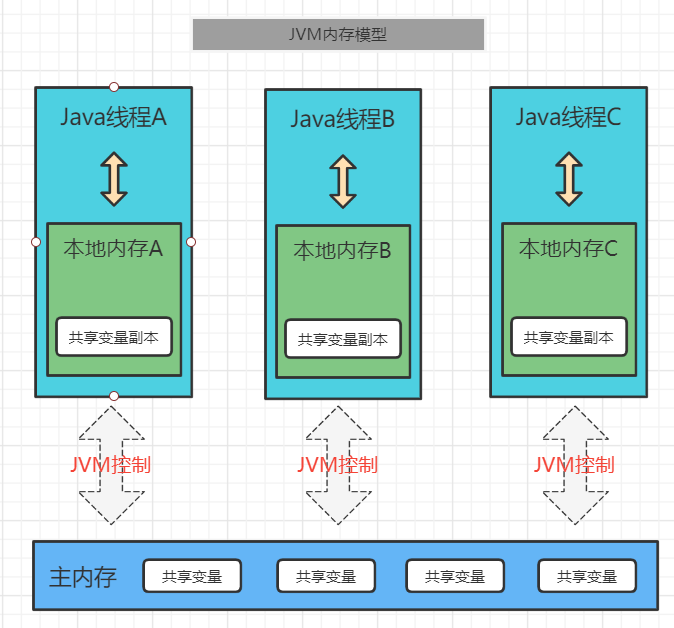
我们可以发现在JMM模型中:
- 所有的共享变量都存在主内存中。
- 每个线程都保存了一份该线程使用到的共享变量的副本。
- 线程A是无法直接访问到线程B的本地内存的,只能访问主内存。线
- 程对共享变量的所有操作都必须在自己的本地内存中进行,不能直接从主内存中读取。
- 并发的三要素:可见性、原子性、有序性,而JMM就主要体现在这三方面。
注意 :因为线程之间无法相互访问,而一旦某个线程将共享变量进行修改,而线程B是无法发现到这个更新值的,所以可能会出现可见性问题。而这里的可见性问题就是一个线程对共享变量的修改,另一个线程能够立刻看到,但此时无法看到更新后的内存,因为访问的是自己的共享变量副本。
解决方案有
- 加锁,加synchronized、Lock,保存一个线程只能等另一个线程结束后才能再访问变量。
- 对共享变量加上volatile关键字,保证了这个变量是可见的。
2. 你知道重排序是什么吗?
重排序是指计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排。
首先我们来看看为什么指令重排序可以提高性能?
每一个指令都会包含多个步骤,每个步骤可能使用不同的硬件,而现代处理器会设计为一个时钟周期完成一条执行时间最长的指令,为什么会这样呢?
主要原理就是可以指令1还没有执行完,就可以开始执行指令2,而不用等到指令1执行结束之后再执行指令2,这样就大大提高了效率。
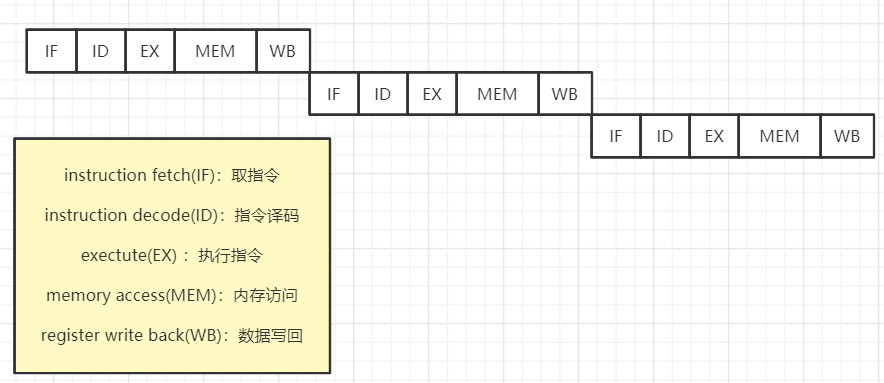
例如:每条指令拆分为五个阶段:
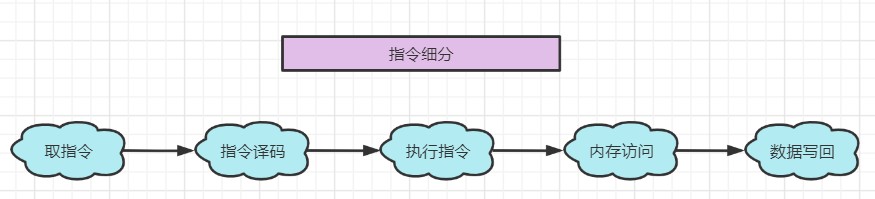
想这样如果是按顺序串行执行指令,那可能相对比较慢,因为需要等待上一条指令完成后,才能等待下一步执行:
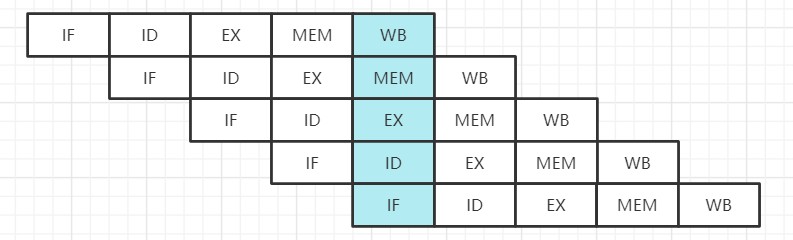
而如果发生指令重排序呢,实际上虽然不能缩短单条指令的执行时间,但是它变相地提高了指令的吞吐量,可以在一个时钟周期内同时运行五条指令的不同阶段。
我们来分析下代码的执行情况,并思考下:
a = b + c;
d = e - f ;
按原先的思路,会先加载b和c,再进行b+c操作赋值给a,接下来就会加载e和f,最后就是进行e-f操作赋值给d。
这里有什么优化的空间呢?我们在执行b+c操作赋值给a时,可能需要等待b和c加载结束,才能再进行一个求和操作,所以这里可能出现了一个停顿等待时间,依次后面的代码也可能会出现停顿等待时间,这降低了计算机的执行效率。
为了去减少这个停顿等待时间,我们可以先加载e和f,然后再去b+c操作赋值给a,这样做对程序(串行)是没有影响的,但却减少了停顿等待时间。既然b+c操作赋值给a需要停顿等待时间,那还不如去做一些有意义的事情。
总结:指令重排对于提高CPU处理性能十分必要。虽然由此带来了乱序的问题,但是这点牺牲是值得的。
重排序的类型有以下几种:
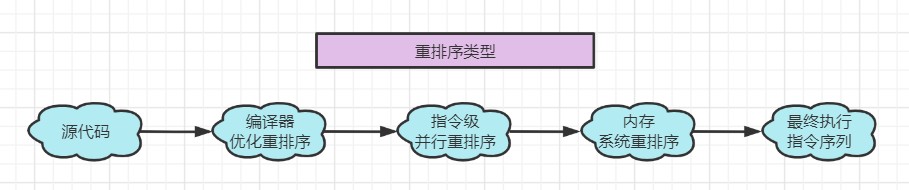
指令重排一般分为以下三种:
- 编译器优化重排
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令并行重排
现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序。
- 内存系统重排
由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
而在重排序中还需要一个概念的东西:as-if-serial
不管如何重排序,都必须保证代码在单线程下的运行正确,连单线程下都无法正确,更不用讨论多线程并发的情况,所以就提出了一个as-if-serial的概念。
as-if-serial语义的意思是:
- 不管怎么重排序,程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守
as-if-serial语义。 - 为了遵守
as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。(强调一下,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑)。但是,如果操作之间不存在数据依赖关系,这些操作依然可能被编译器和处理器重排序。
3. happens-before是什么,和as-if-serial有什么区别
happens-before的概念:
一方面,程序员需要JMM提供一个强的内存模型来编写代码;另一方面,编译器和处理器希望JMM对它们的束缚越少越好,这样它们就可以最可能多的做优化来提高性能,希望的是一个弱的内存模型。
JMM考虑了这两种需求,并且找到了平衡点,对编译器和处理器来说,只要不改变程序的执行结果(单线程程序和正确同步了的多线程程序),编译器和处理器怎么优化都行。
而对于程序员,JMM提供了happens-before规则(JSR-133规范),在JMM中,如果一个线程执行的结果需要对另一个操作进行可见,那么这两个操作直接必须存在happens-before关系。
JMM使用happens-before的概念来定制两个操作之间的执行顺序。这并不意味着前一个操作必须要在后一个操作之前执行!happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前 。
happens-before关系的定义如下:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么JMM也允许这样的重排序。
- happens-before关系保证正确同步的多线程程序的执行结果不被重排序改变。
在Java中,有以下天然的Happens-Before规则:
- 程序顺序规则:一个线程中的每一个操作,happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
- start规则:如果线程A执行操作ThreadB.start()启动线程B,那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作、
- join规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
- 线程中断规则:对线程interrupt()方法的调用happens-before于被中断线程的代码检测到中断事件的发生。
Happens-Before和as-if-serial的关系实质上是一回事。
- as-if-serial语义保证单线程内重排序后的执行结果和程序代码本身应有的结果是一致的,happens-before关系保证正确同步的多线程程序的执行结果不被重排序改变。
- as-if-serial语义和happens-before这么做的目的,都是为了在不改变程序执行结果的前提下,尽可能地提高程序执行的并行度。
总结
这篇文章就到这里了,如果这篇文章对你也有所帮助,希望您能多多关注自由互联的更多内容!