目录 一、第三方类库介绍 二、安转第三方类库 三、引用xlrd读取excel数据 四、引入openpyxl写入数据 总结 实验环境: 系统:win10 语言:python3.8 承载软件:pycharm2021.1.2(Professional Edition) 第
目录
- 一、第三方类库介绍
- 二、安转第三方类库
- 三、引用xlrd读取excel数据
- 四、引入openpyxl写入数据
- 总结
实验环境:
系统:win10
语言:python3.8
承载软件:pycharm2021.1.2 (Professional Edition)
第三方类库:openpyxl、xlrd
一、第三方类库介绍
xlrd库是一个很常用的读取excel文件的库,其对excel文件的读取可以实现比较精细的控制。
openpyxl是实现excel的写入操作的第三方类库
二、安转第三方类库
pip install xlrd==1.2.0 #此处一定要安转这个版本的xlrd,新版的xlrd可能会出现不兼容xlsx后缀文件的情况
pip install openpyxl
三、引用xlrd读取excel数据
首先我先来选取一个测试的数据,因为在之前写过Numpy和pandas的操作我们可以直接生成一个名为“test.xlsx”的文件。点击此处获取知识链接
因为工作中大部分人的excel并不像此处如此完美所以不可以直击使用pandas库进行操作,结合工作中的实际情况自行斟酌使用
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,90,size=[10,3]),columns=['日用户','日销售额','日成本'])
df.to_excel('test.xlsx')
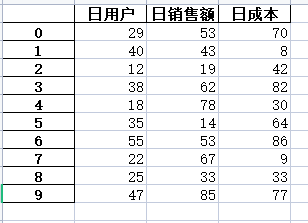
导入xlrd包并读取数据

import xlrd
#选中要读取的excel文件
test1 = xlrd.open_workbook('test.xlsx')
# 根据sheet索引获取sheet页 0表示1 1表示2 以此类推
sheet = test1.sheet_by_index(0)
# 根据sheet名称获取sheet页 0表示1 1表示2 以此类推
sheet1 = test1.sheet_by_name('Sheet1')
# 打印工作表的名称、行数和列数
print("打印工作表的名称、行数和列数:")
print('名称:',sheet.name, '行数:',sheet.nrows,'列数:', sheet.ncols)
# 选中列
col = sheet.col_values(2)
print('col',col)
# 选中行
row = sheet.row_values(2)
print('row',row)
# 根据行索引选定列 注意row()中以1开始 []中以0开始
print(sheet.row(1)[2].value)

四、引入openpyxl写入数据
import openpyxl
# 选中写入的excel文件
workbook=openpyxl.load_workbook('test.xlsx')
# 选中将要写入的sheet页
sheets = workbook["Sheet1"]
# 给第一个单元格写入数据;
sheets["A1"] = "黑龙江省"
# 设置字体为红色;字体大小;字体为粗体;字体为斜体
from openpyxl.styles import Font,colors
sheets["A1"].font = Font(color='981818',size = 15,bold = True,italic = True,)
# 获取第一个单元格的内容;
print(sheets["A1"].value)
# 给任意一个单元格赋值
sheets.cell(2,1,value = "江苏省")# 保存数据,如若名称存在就覆盖 否则新建文件
workbook.save('更改后输出.xlsx')
效果如图
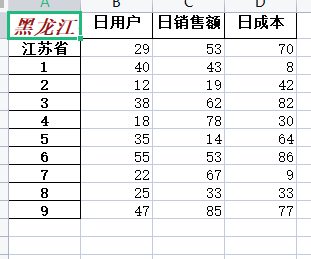
此处知识异常简单需要基本的语句操作练习即可可游刃有余。
下面推荐一个今天遇到的问题胡乱写了个demo
import openpyxl
import xlrd
# op选中文件
workbook1=openpyxl.load_workbook('test1.xlsx')
sheets=workbook1['Sheet1']
# xlrd选中文件
book = xlrd.open_workbook("test1.xlsx")
# 选中sheet1
sheet = book.sheet_by_index(0)
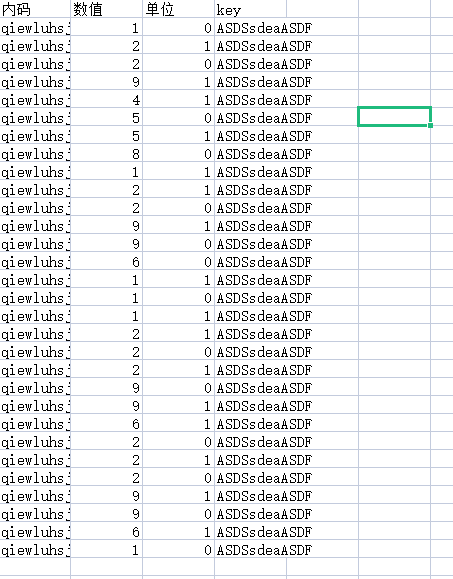
# 单位列
dw = sheet.col_values(2)
# 数量列
nb = sheet.col_values(1)
print(dw)
# 若单位为0则乘以10000否则不变
for i in range(len(dw)):
if dw[i]==0:
data = sheets.cell(i+1, 2).value=nb[i]*10000
else:
data = sheets.cell(i+1, 2).value = nb[i]
print(data)
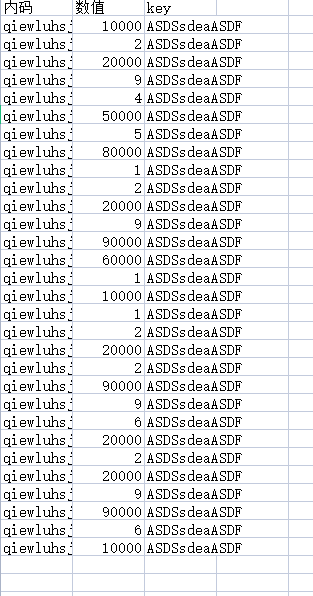
# 删除单位(第三)列
sheets.delete_cols(3)
# 覆盖保存原数据
workbook1.save('test1.xlsx')
操作前
操作后
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注易盾网络的更多内容!