目录
- 1 项目背景
- 1.1Python的优势
- 1.2网络爬虫
- 1.3数据可视化
- 1.4Python环境介绍
- 1.4.1简介
- 1.4.2特点
- 1.5扩展库介绍
- 1.5.1安装模块
- 1.5.2主要模块介绍
- 2需求分析
- 2.1 网络爬虫需求
- 2.2 数据可视化需求
- 3总体设计
- 3.1 网页分析
- 3.2 数据可视化设计
- 4方案实施
- 4.1网络爬虫代码
- 4.2 数据可视化代码
- 5 效果展示
- 5.1 网络爬虫
- 5.1.1 爬取近五年主要城市数据
- 5.1.2 爬取2019年各省GDP
- 5.1.3 爬取豆瓣电影Top250
- 5.2 数据可视化
- 5.2.1条形图
- 5.2.2 散点图
- 5.2.3 饼图
- 5.2.4 箱线图
- 5.2.5 树地图
- 5.2.6 玫瑰图
- 5.2.7 词云
- 6 总结
- 7参考文献
1 项目背景
1.1Python的优势
Python有成熟的程序包资源库和活跃的社区 Python以PYPI为技术支撑,资源丰富,可被灵活调用。还有一些其他优势,比如跨平台且开源、成本小;可方便快捷实现数据可视化,像2D图表和一些基本的3D 图表可以借matplotlib和 seaborn等等一些专属库,只需要编写简单的Python代码就可输出可视化结果,方便快捷[1]。
1.2网络爬虫
网络爬虫(Web Crawler)是依照一定规则主动抓取网页的程序,是搜索引擎获得信息的渠道之一。通常根据给定 URL 种子爬取网页,得到新的 URL 存放至待爬行 URL中,当满足一定条件时停止爬行。网络爬虫一般分为通用网络爬虫、深度网络爬虫和主题网络爬虫 3 类。 主题网络爬虫通常给定 URL 种子集,依照预先规定的主题,由特定的分析算法算出爬行网页的主题相关度,并过滤与主题无关的网页,优先抓取相关度高的网页,当满足一定条件时停止。主题网络爬虫根据主题对 Web 进行分块采集并整合采集结果,从而提高 Web 页面利用率[2]。
1.3数据可视化
在计算机学科的分类中,利用人眼的感知能力对数据进行交互的可视化表达以增强认知的技术,称为可视化。16 世纪,天体和地理的测量技术得到发展, 通过三角测量等技术可精确绘制地图,数据可视化开始萌芽。20 世纪 60 年代计算机的发展使得数据可视化加速发展,通过计算机图像处理等技术,新的可视化方法和技术迎来爆炸性增长。数据可视化将相对复杂、冗杂的大数据经过挖掘、转化,提炼出结构化数据内容,并通过可视的方式以用户更易理解的形式 展示出来,清晰表达数据内在的信息和规律[3]。
1.4Python环境介绍
1.4.1简介
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。
此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。同时支持Google App Engine,PyCharm支持IronPython。这些功能在先进代码分析程序的支持下,使 PyCharm 成为 Python 专业开发人员和刚起步人员使用的有力工具。
1.4.2特点
首先,PyCharm拥有一般IDE具备的功能,比如, 调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制
另外,PyCharm还提供了一些很好的功能用于Django开发,同时支持Google App Engine,更酷的是,PyCharm支持IronPython主要功能
1.5扩展库介绍
1.5.1安装模块
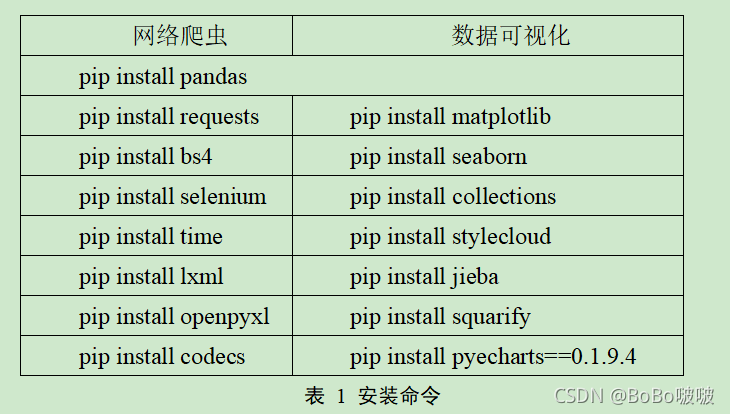
1.5.2主要模块介绍
① pandas模块
pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。它纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,提供了大量能使我们快速便捷地处理数据的函数和方法[4]。
pandas中常见的数据结构有两种:
Series DateFrame
类似一维数组的对象, 类似多维数组/表格数组;每列数据可以是不同的类型;索引包括列索引和行索引。

② requests模块
requests是一常用的http请求库,它使用python语言编写,可以方便地发送http请求,以及方便地处理响应结果。
③ bs4模块
BS4 (beautiful soup 4)是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
④ selenium模块
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
⑤ matplotlib模块
matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。它可与Numpy一起使用,提供一种有效的MATLAB开源替代方案;它也可以和图形工具包一起使用,让用户很轻松地将数据图形化;同时它还提供多样的输出格式。
⑥ seaborn模块
seaborn是一个在Python中制作有吸引力和丰富信息的统计图形的库。它构建在MatPultLB的顶部,与PyDATA栈紧密集成,包括对SIMPY和BANDA数据结构的支持以及SISPY和STATSMODEL的统计例程。
seaborn 其实是在matplotlib的基础上进行了更高级的 API 封装,从而使得作图更加容易 在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充。Seabn是基于MatPultLB的Python可视化库。它为绘制有吸引力的统计图形提供了一个高级接口。
⑦ pyecharts模块
pyecharts 是一个用于生成 Echarts 图表的类库。echarts 是百度开源的一个数据可视化 JS 库,主要用于数据可视化。pyecharts 是一个用于生成 Echarts 图表的类库。实际上就是 Echarts 与 Python 的对接。使用 pyecharts 可以生成独立的网页,也可以在 flask , Django 中集成使用。
2需求分析
2.1 网络爬虫需求
通过对爬取网页的html分析,爬取网页的数据,将爬取的数据保存到文件,用于对数据进行可视化。
2.2 数据可视化需求
使爬取网站的数据用更直观的效果展示,当数据获取完成,我们使用相关模块对数据进行清洗处理,并对数据做可视化分析,并理解每一个图标所代表意义;
3总体设计
3.1 网页分析
在爬取国家统计局网站上的数据,需要用到WebDriver,先安装chromdriver。安装的Chromedriver要与自己电脑上的谷歌版本号对应,将下载的chromedriver.exe放到如图 1图 2所示路径下,放到安装谷歌和安装python路径下,用来调用这个可执行文件。还将这两个路径添加环境变量。
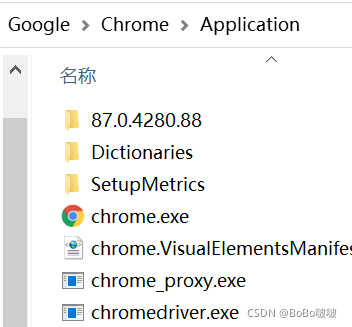
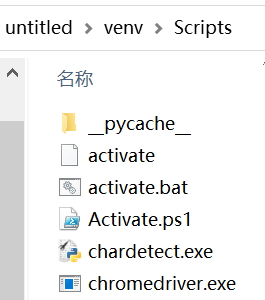
驱动浏览器,用webdriver的对象对网页进行点击等操作,找到想要爬取的网站。
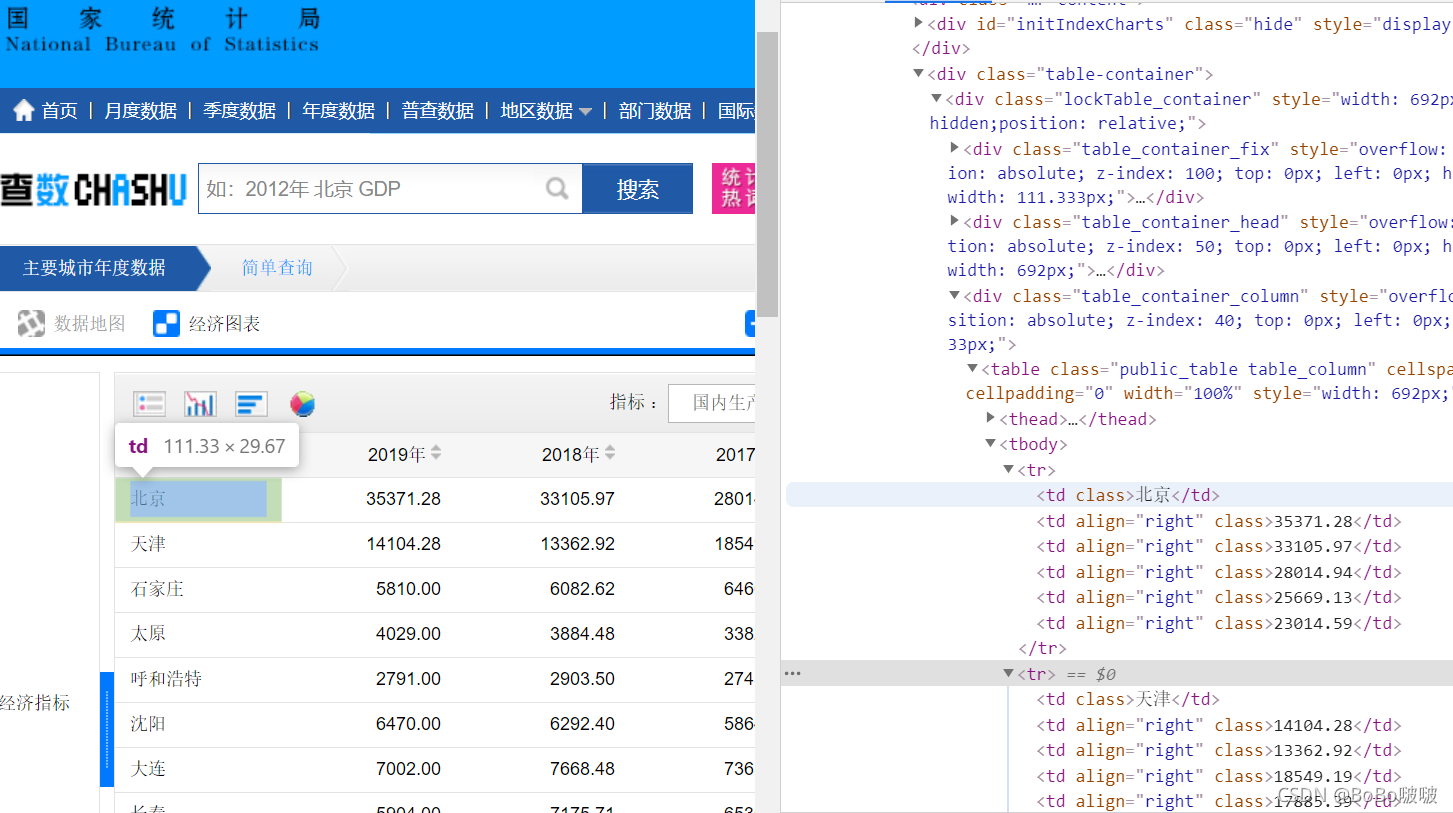
通过对网页html分析,通过路径一层层找到自己想要获取的数据。如图 3所示,将数据追加到列表中,保存到文件。
爬取豆瓣电影Top250,翻页查看url变化规律:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第十页:https://movie.douban.com/top250?start=225&filter=
分析可得页面url的规律:
url_list = [“https://movie.douban.com/top250?start={}&filter=”.format(x * 25) for x in range(10)]
对网页进行分析,如图 4所示,每个li标签里都包含每个电影的基本信息,例如:“排名”, “电影名”, "导演和主演"等等。将这些信息追加到列表中,保存到movie.xlsx文件中。
3.2 数据可视化设计
将爬取的数据用多种图表的显示。例如:条形图,饼图,散点图,箱线图,玫瑰图,词云等形式。利用python的pandas模块将数据文件读入。导入matplotlib, pyecharts等模块,调用模块画图的相应函数。进行数据可视化,并将可视化结果保存为图片。
4方案实施
4.1网络爬虫代码
import pandas as pd
import requests
from bs4 import BeautifulSoup
import time
import re
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import lxml
import openpyxl
import codecs
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"
}
url1 = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
url2 = "http://data.stats.gov.cn"
'''爬取近五年主要城市数据'''
def driver1(url1):
driver = webdriver.Chrome()
driver.get(url1)
time.sleep(3)
xRdata = '//*[@id="details-button"]' # 点击高级
ActionChains(driver).click(driver.find_element_by_xpath(xRdata)).perform()
xRdata = '//*[@id="proceed-link"]' # 点击
ActionChains(driver).click(driver.find_element_by_xpath(xRdata)).perform()
time.sleep(3)
time.sleep(4) # 加载页面,停留时间长一些
xTable = '//*[@class="table-container"]/div/div[3]/table/tbody' # 主要城市年度数据表
table = driver.find_element_by_xpath(xTable).get_attribute('innerHTML')
soup = BeautifulSoup(table, 'html.parser') # 解析表单
tb = soup.find_all('tr') # 查找表内tr标签
tb_p = [] # 各城市名字
tb_ = []
tb_1 = [[], [], [], [], []]
for row in tb:
row_text = row.text
# 查找第一个数字的索引
ret1 = re.search('\d', row_text).start()
# 将各个城市写入列表中
tb_p.append(row_text[:ret1])
# 截断至第一个数字
row_text = row_text[ret1:]
for i in range(5):
try:
# 顺序查找点
ret = row_text.find('.')
# 将第一年年数据保存到列表中
tb_.append(row_text[:ret + 3])
# 删去第一年的数据
row_text = row_text[ret + 3:]
except:
break
for i in range(5):
for j in range(i, len(tb_), 5):
try:
tb_1[i].append(tb_[j])
except:
break
data = {'地区': tb_p,
'2019年': tb_1[0],
'2018年': tb_1[1],
'2017年': tb_1[2],
'2016年': tb_1[3],
'2015年': tb_1[4],
}
dataframe = pd.DataFrame(data)
dataframe.to_csv('City_data.csv', index=False, sep=',', encoding='utf-8-sig')
driver.close()
'''爬取2019年各省GDP'''
def driver2(url2):
driver = webdriver.Chrome()
driver.get(url2)
time.sleep(3)
xRdata = '//*[@id="details-button"]' # 点击高级
ActionChains(driver).click(driver.find_element_by_xpath(xRdata)).perform()
xRdata = '//*[@id="proceed-link"]' # 点击
ActionChains(driver).click(driver.find_element_by_xpath(xRdata)).perform()
time.sleep(3)
xRdata = '//*[@id="nav"]/ul/li[6]/a' # 地区数据
ActionChains(driver).click(driver.find_element_by_xpath(xRdata)).perform()
time.sleep(3)
xPdata = '//*[@id="menuE01"]/li[3]/a' # 分省年度数据
ActionChains(driver).click(driver.find_element_by_xpath(xPdata)).perform()
time.sleep(4) # 加载页面,停留时间长一些
xTable = '//*[@class="table-container"]/div/div[3]/table/tbody' # 数据表
table = driver.find_element_by_xpath(xTable).get_attribute('innerHTML')
soup = BeautifulSoup(table, 'html.parser') # 解析表单
tb = soup.find_all('tr') # 查找表内tr标签
tb_p = [] # 各省市名字
tb_ = []
tb_1 = [[], [], [], [], [], [], [], [], [], []]
for row in tb:
row_text = row.text
# 查找第一个数字的索引
ret1 = re.search('\d', row_text).start()
# 将各个省份写入列表中
tb_p.append(row_text[:ret1])
# 截断至第一个数字
row_text = row_text[ret1:]
for i in range(1):
try:
# 顺序查找点
ret = row_text.find('.')
# 将第一年年数据保存到列表中
tb_.append(row_text[:ret + 3])
# 删去第一年的数据
row_text = row_text[ret + 3:]
except:
break
for i in range(1):
for j in range(i, len(tb_), 1):
try:
tb_1[i].append(tb_[j])
except:
break
data = {'Province': tb_p,
'GDP': tb_1[0],
}
dataframe = pd.DataFrame(data)
dataframe.to_csv('2019_Province_GDP.csv', index=False, sep=',', encoding='utf-8-sig')
driver.close()
'''爬取豆瓣电影Top250'''
wb = openpyxl.Workbook() # 创建工作簿对象
sheet = wb.active # 获取工作簿的活动表
sheet.title = "movie" # 工作簿重命名
sheet.append(["排名", "电影名", "导演和主演", "上映时间", "上映地区", "电影类型", "评分", "评价人数", "引言"])
def get_movie(urls):
rank = 1
for url in urls:
res = requests.get(url, headers=headers).text
html = lxml.etree.HTML(res)
# 先xpath定位提取到每个页面的所有li标签
lis = html.xpath('//*[@id="content"]/div/div[1]/ol/li')
# 每个li标签里有每部电影的基本信息
for li in lis:
name = li.xpath('.//div[@class="hd"]/a/span[1]/text()')[0]
director_actor = li.xpath('.//div[@class="bd"]/p/text()')[0].strip()
info = li.xpath('.//div[@class="bd"]/p/text()')[1].strip()
# 按"/"切割成列表
_info = info.split("/")
# 得到 上映时间 上映地区 电影类型信息 去除两端多余空格
time, area, genres = _info[0].strip(), _info[1].strip(), _info[2].strip()
# print(time, area, genres)
rating_score = li.xpath('.//div[@class="star"]/span[2]/text()')[0]
rating_num = li.xpath('.//div[@class="star"]/span[4]/text()')[0]
quote = li.xpath('.//p[@class="quote"]/span/text()')
# 最后一页有部电影 九品芝麻官 没有一句话引言 加条件判断 防止报错
if len(quote) == 0:
quote = None
else:
quote = quote[0]
sheet.append([rank, name, director_actor, time, area, genres, rating_score, rating_num, quote])
rank += 1
# 保存到文件
wb.save("movie.xlsx")
'''豆瓣电影Top250'''
index_url = 'https://movie.douban.com/top250'
def get_html(url):
html = requests.get(url, headers=headers).text
return html
def create_list(html):
soup = BeautifulSoup(html, 'lxml')
movie_names = []
movie_info = []
for t in soup.find_all('div', 'hd'):
name = t.find('span', 'title').get_text()
movie_names.append(name)
for t in soup.find_all('div', 'info'):
info = t.find('p').get_text().replace(' ','')
movie_info.append(info)
next_page = soup.find('span', 'next').find('a')
if next_page:
return movie_names, movie_info, index_url + next_page['href']
else:
return movie_names, movie_info, None
def main():
order = 1
url = index_url
with codecs.open('top250.txt', 'wb', encoding='utf-8') as f:
while url:
html = get_html(url)
names, info, url = create_list(html)
for n in range(25):
f.write('Top ' + str(order) + ' ' + names[n] + '\r\n')
f.write(info[n] + '\r\n')
order = order+1
if __name__ == "__main__":
# 列表推导式得到url列表 10页的电影信息 Top250
url_list = ["https://movie.douban.com/top250?start={}&filter=".format(i * 25) for i in range(10)]
driver1(url1)
driver2(url2)
get_movie(url_list)
main()
4.2 数据可视化代码
import pandas as pd
import re
import matplotlib.pyplot as plt
import collections
import seaborn as sns
from stylecloud import gen_stylecloud
import jieba
import squarify
from pyecharts import Pie
sns.set() #恢复seaborn的默认主题
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
'''条形图'''
GDP = pd.read_csv('2019_Province_GDP.csv')
# 设置绘图风格
plt.style.use('ggplot')
# 绘制条形图
plt.bar(x= range(GDP.shape[0]), # 指定条形图x轴的刻度值
height = GDP.GDP, # 指定条形图y轴的数值
tick_label = GDP.Province, # 指定条形图x轴的刻度标签
color = 'steelblue', # 指定条形图的填充色
)
# 添加y轴的标签
plt.ylabel('GDP(万亿)')
# 添加条形图的标题
plt.title('2019年各省份GDP分布')
# 为每个条形图添加数值标签
for x,y in enumerate(GDP.GDP):
plt.text(x,y+0.1,'%s' %round(y,1),ha='center')
# 显示图形
plt.savefig('test1.png')
plt.show()
'''饼图'''
# 构造数据
edu = [0.2515,0.3724,0.3336,0.0368,0.0057]
labels = ['中专','大专','本科','硕士','其他']
explode = [0,0.1,0,0,0] # 生成数据,用于突出显示大专学历人群
colors=['#9999ff','#ff9999','#7777aa','#2442aa','#dd5555'] # 自定义颜色
# 将横、纵坐标轴标准化处理,确保饼图是一个正圆,否则为椭圆
plt.axes(aspect='equal')
# 绘制饼图
plt.pie(x = edu, # 绘图数据
explode=explode, # 突出显示大专人群
labels=labels, # 添加教育水平标签
colors=colors, # 设置饼图的自定义填充色
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
pctdistance=0.8, # 设置百分比标签与圆心的距离
labeldistance = 1.1, # 设置教育水平标签与圆心的距离
startangle = 180, # 设置饼图的初始角度
radius = 1.2, # 设置饼图的半径
counterclock = False, # 是否逆时针,这里设置为顺时针方向
wedgeprops = {'linewidth': 1.5, 'edgecolor':'green'},# 设置饼图内外边界的属性值
textprops = {'fontsize':10, 'color':'black'}, # 设置文本标签的属性值
)
# 添加图标题
plt.title('失信用户的受教育水平分布')
# 显示图形
plt.savefig('test2.png')
plt.show()
'''箱线图'''
data=pd.read_csv('City_data.csv')
#箱线图
data.boxplot()
plt.savefig('test3.png')
plt.show()
'''树地图'''
# 创建数据
name = ['国内增值税', '国内消费税', '企业所得税', '个人所得税',
'进口增值税、消费税', '出口退税', '城市维护建设税',
'车辆购置税', '印花税', '资源税', '土地和房税', '车船税烟叶税等']
income = [3908, 856, 801, 868, 1361, 1042, 320, 291, 175, 111, 414, 63]
# 绘图
colors = ['steelblue', '#9999ff', 'red', 'indianred',
'green', 'yellow', 'orange']
plot = squarify.plot(sizes=income, # 指定绘图数据
label=name, # 指定标签
color=colors, # 指定自定义颜色
alpha=0.6, # 指定透明度
value=income, # 添加数值标签
edgecolor='white', # 设置边界框为白色
linewidth=3 # 设置边框宽度为3
)
# 设置标签大小
plt.rc('font', size=8)
# 设置标题大小
plot.set_title('2020年12月中央财政收支情况', fontdict={'fontsize': 15})
# 去除坐标轴
plt.axis('off')
# 去除上边框和右边框刻度
plt.tick_params(top='off', right='off')
# 显示图形
plt.savefig('test4.png')
plt.show()
'''玫瑰图'''
attr =["碳酸饮料", "其他", "绿茶", "矿泉水", "果汁"]
v1 =[6, 2, 7, 6,1]
v2 =[9, 6, 4, 4,5]
pie =Pie("玫瑰图", title_pos='center', width=800)
pie.add("男", attr, v1, center=[25, 50], is_random=True, radius=[20, 50], rosetype='radius')
pie.add("女", attr, v2, center=[75, 50], is_random=True, radius=[20, 50], rosetype='area',
is_legend_show=False, is_label_show=True)
pie.show_config()
pie.render('玫瑰图.html')
# 读取数据
df = pd.read_excel("movie.xlsx",engine='openpyxl')
# print(type(df)) # <class 'pandas.core.frame.DataFrame'>
'''上映高分电影数量最多的年份Top10'''
show_time = list(df["上映时间"])
# 有上映时间数据是1961(中国大陆)这样的 处理一下 字符串切片
show_time = [s[:4] for s in show_time]
show_time_count = collections.Counter(show_time)
# 取数量最多的前10 得到一个列表 里面每个元素是元组
# (年份, 数量)
show_time_count = show_time_count.most_common(10)
# 字典推导式
show_time_dic = {k: v for k, v in show_time_count}
# 按年份排序
show_time = sorted(show_time_dic)
# 年份对应高分电影数量
counts = [show_time_dic[k] for k in show_time]
plt.figure(figsize=(9, 6), dpi=100)
# 绘制条形图
plt.bar(show_time, counts, width=0.5, color="cyan")
# y轴刻度重新设置一下
plt.yticks(range(0, 16, 2))
# 添加描述信息
plt.xlabel("年份")
plt.ylabel("高分电影数量")
plt.title("上映高分电影数量最多的年份Top10", fontsize=15)
# 添加网格 网格的透明度 线条样式
plt.grid(alpha=0.2, linestyle=":")
plt.savefig('test5.png')
plt.show()
'''国家或地区上榜电影数量最多的Top10'''
area = list(df['上映地区'])
sum_area = []
for x in area:
x = x.split(" ")
for i in x:
sum_area.append(i)
area_count = collections.Counter(sum_area)
area_dic = dict(area_count)
area_count = [(k, v) for k, v in list(area_dic.items())]
# 按国家或地区上榜电影数量排序
area_count.sort(key=lambda k: k[1])
# 取国家或地区上榜电影数量最多的前十
area = [m[0] for m in area_count[-10:]]
nums = [m[1] for m in area_count[-10:]]
plt.figure(figsize=(9, 6), dpi=100)
# 绘制横着的条形图
plt.barh(area, nums, color='red')
# 添加描述信息
plt.xlabel('电影数量')
plt.title('国家或地区上榜电影数量最多的Top10')
plt.savefig('test6.png')
plt.show()
'''豆瓣电影Top250-评价人数Top10'''
name = list(df['电影名'])
ranting_num = list(df['评价人数'])
# (电影名, 评价人数)
info = [(m, int(n.split('人')[0])) for m, n in list(zip(name, ranting_num))]
# 按评价人数排序
info.sort(key=lambda x: x[1])
# print(info)
name = [x[0] for x in info[-10:]]
ranting_num = [x[1] for x in info[-10:]]
plt.figure(figsize=(12, 6), dpi=100)
# 绘制横着的条形图
plt.barh(name, ranting_num, color='cyan', height=0.4)
# 添加描述信息
plt.xlabel('评价人数')
plt.title('豆瓣电影Top250-评价人数Top10')
plt.savefig('test7.png')
plt.show()
'''豆瓣电影Top250评分-排名的散点分布'''
# 豆瓣电影Top250 排名 评分 散点图 描述关系
rating = list(df["排名"])
rating_score = list(df["评分"])
plt.figure(figsize=(9, 6), dpi=100)
# 绘制散点图 设置点的颜色
plt.scatter(rating_score, rating, c='r')
# 添加描述信息 设置字体大小
plt.xlabel("评分", fontsize=12)
plt.ylabel("排名", fontsize=12)
plt.title("豆瓣电影Top250评分-排名的散点分布", fontsize=15)
# 添加网格 网格的透明度 线条样式
plt.grid(alpha=0.5, linestyle=":")
plt.savefig('test8.png')
plt.show()
'''豆瓣电影Top250词云'''
# 读取数据
with open('top250.txt', encoding='utf-8') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=False)
result_list = []
with open('top250.txt', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
gen_stylecloud(
text=' '.join(result_list),
size=500,
collocations=False,
font_path=r'C:\Windows\Fonts\msyh.ttc',
output_name='test9.png',
icon_name='fas fa-video',
palette='colorbrewer.qualitative.Dark2_7'
)
5 效果展示
5.1 网络爬虫
5.1.1 爬取近五年主要城市数据
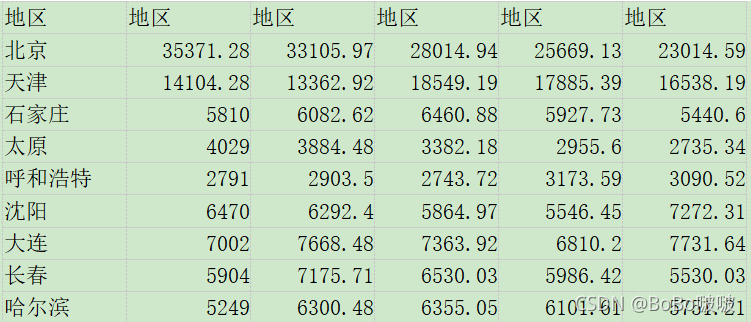
5.1.2 爬取2019年各省GDP
Province GDP
北京市 35371.28
天津市 14104.28
河北省 35104.52
山西省 17026.68
内蒙古自治区 17212.53
辽宁省 24909.45
吉林省 11726.82
黑龙江省 13612.68
上海市 38155.32
表 4 2019_Province_GDP.csv部分数据
5.1.3 爬取豆瓣电影Top250

5.2 数据可视化
5.2.1条形图
2019年各省GDP,这个条形图效果不是很好,可以对数据处理一下,可以一个图里面少点省份。
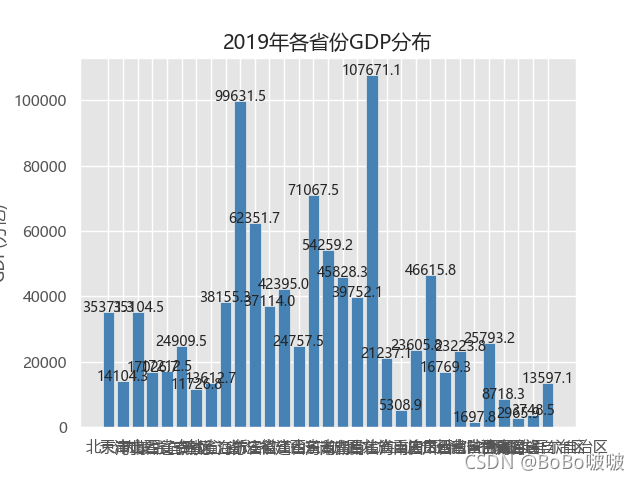
通过减少图中数据,下面这几个条形图效果较好。
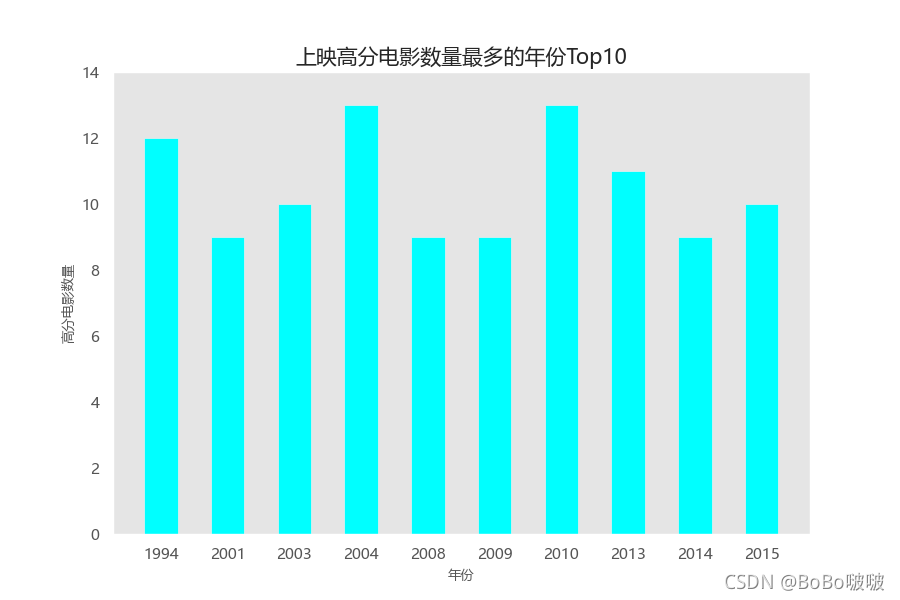
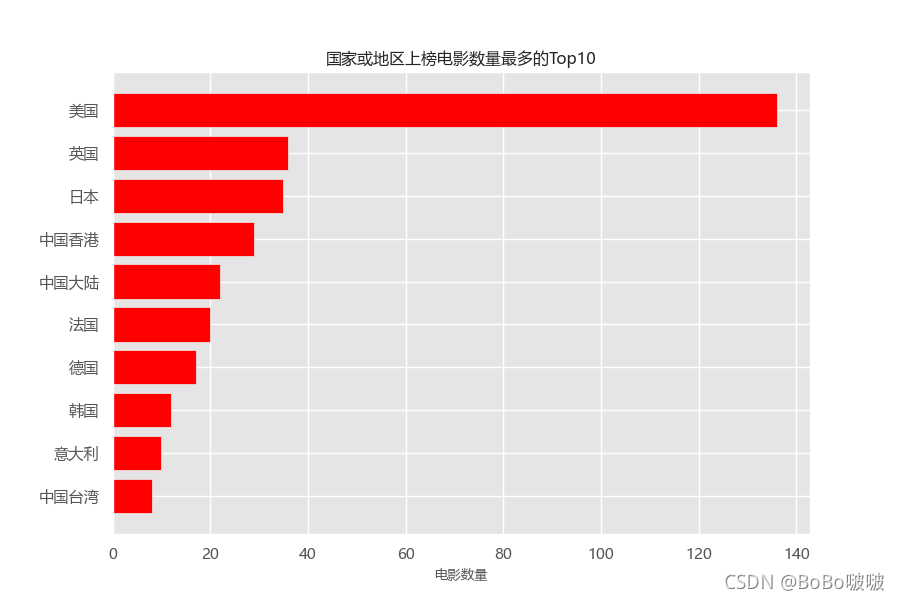
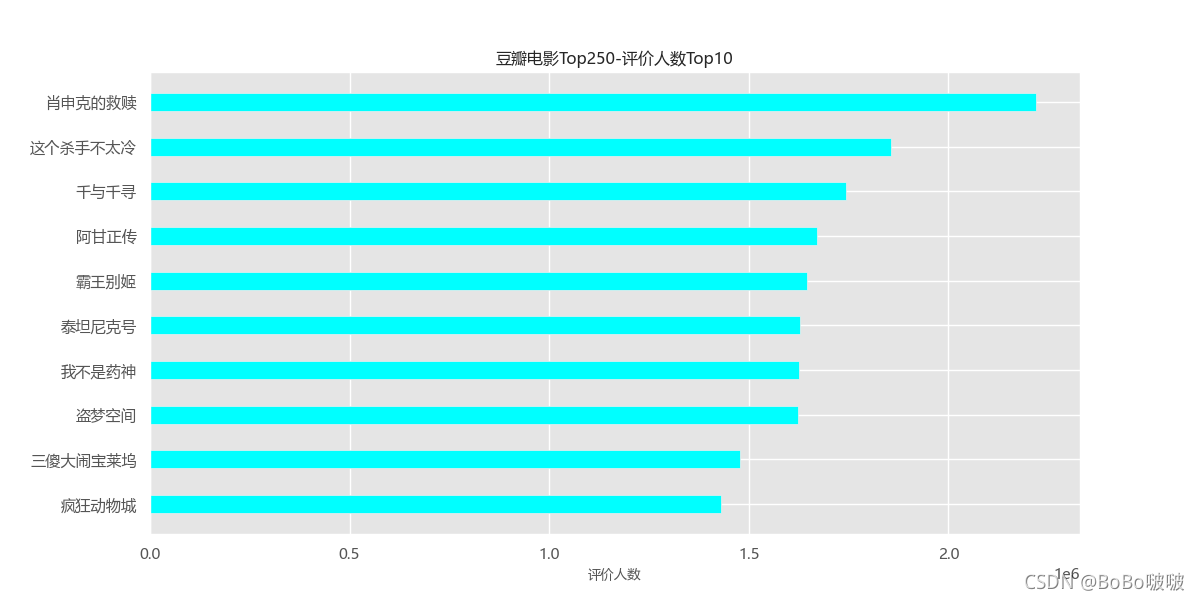
5.2.2 散点图
豆瓣电影Top250散点分别,可以更直观的看到不同评分所处的排名。
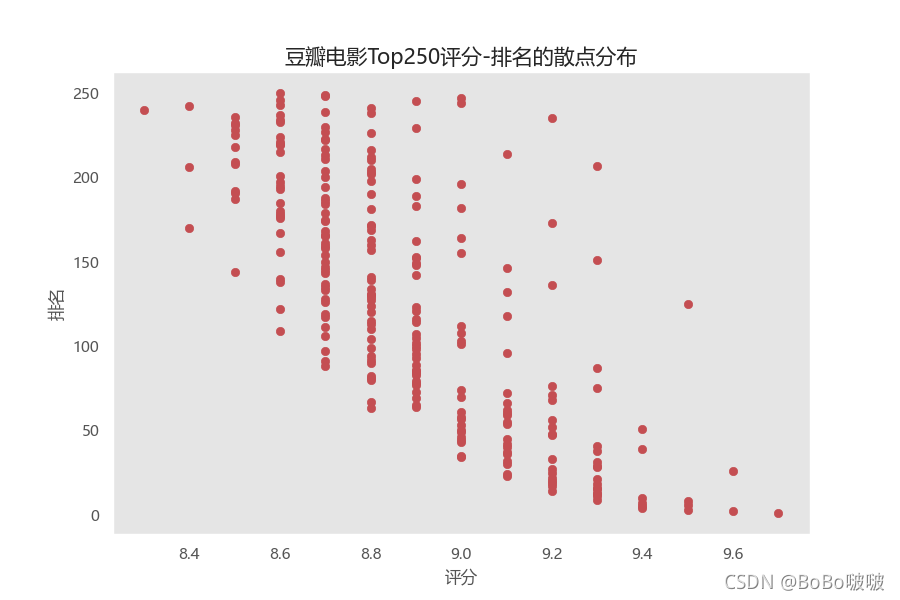
5.2.3 饼图
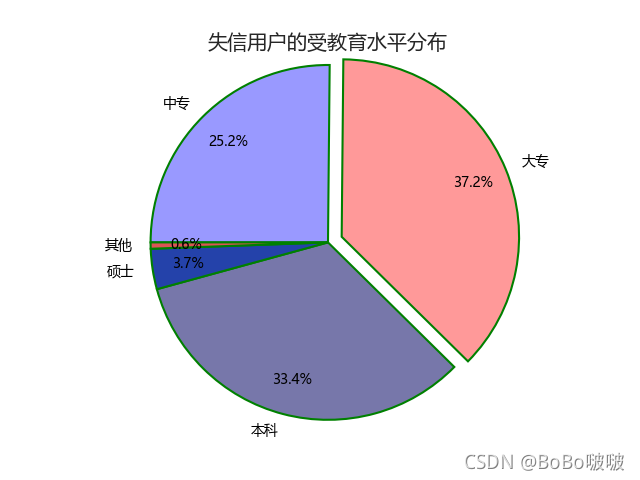
5.2.4 箱线图
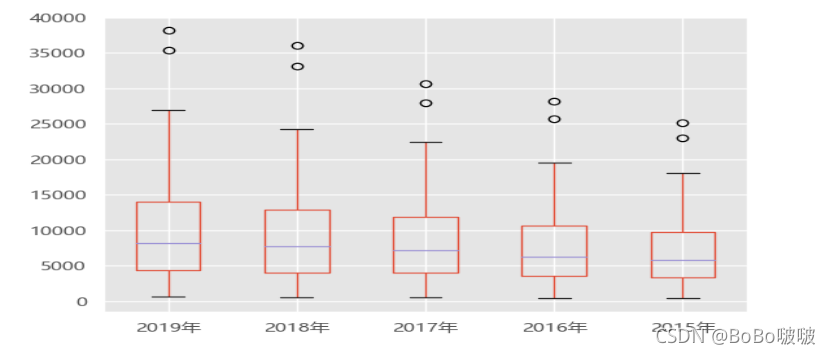
5.2.5 树地图
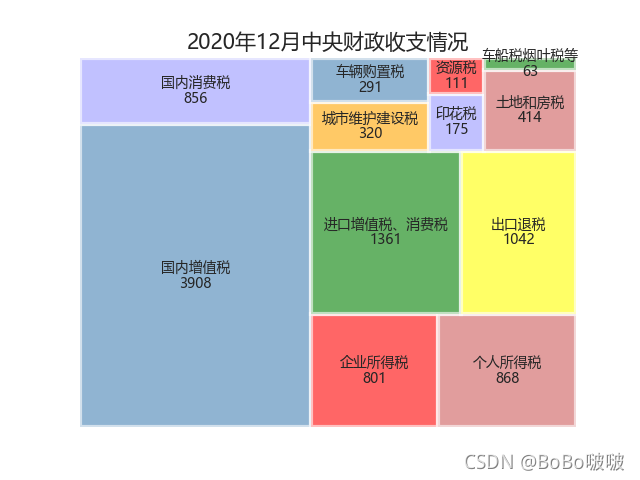
5.2.6 玫瑰图
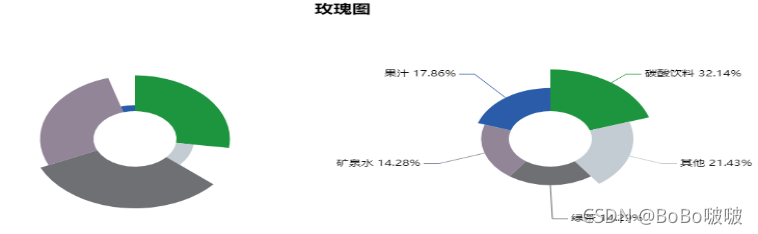
5.2.7 词云

6 总结
通过对Python爬虫以及数据可视化的学习,在这过程中查阅了许多的资料。主要实现了爬取2019年各省数据和主要城市近五年,还有豆瓣电影top250,用图表等可视化方式更直观的看数据。对Python常用模块和函数的使用方法有了进一步的了解。
由于时间有限,项目还有许多不足,对于爬取的同一个网站不同页面。爬取的代码部分有重复,代码就有点长。代码质量不高。有的对数据没有处理,直接拿过来用。第一个条形图看起来效果很差,不能很好的展现数据信息。仍需继续改进。
7参考文献
[1]杨露,葛文谦. 基于Python的制造业数据分析可视化平台设计[J]. 《信息化研究》,2018年10月第44卷第5期.
[2]左薇,张熹,董红娟. 主题网络爬虫研究综述[J]. 《软件导刊》,2020年2月第19卷第2期.
[3]孙远波,闻芷艺,徐瑞格. 新型冠状病毒肺炎疫情数据可视化设计综述 [J]. 《包装工程》,2020年4月第41卷第8期.
[4]董付国,Python程序设计基础(第2版).清华大学出版社,2018.
以上就是python教程网络爬虫及数据可视化原理解析的详细内容,更多关于python网络爬虫及数据可视化的资料请关注易盾网络其它相关文章!