目录 前言 GridFs介绍 什么时候使用GridFs GridFs的原理 环境 引入依赖和项目配置 使用GridFsTemplate操作GridFs 前言 这段时间在公司实习,安排给我一个任务,让在系统里实现一个知识库的模
目录
- 前言
- GridFs介绍
- 什么时候使用GridFs
- GridFs的原理
- 环境
- 引入依赖和项目配置
- 使用GridFsTemplate操作GridFs
前言
这段时间在公司实习,安排给我一个任务,让在系统里实现一个知识库的模块,产品说,就像百度网盘那样。。。我tm…,这不就是应了那句话,“这个需求很简单,怎么实现我不管”。
可是我google小能手怎么会认输呢,本来还说研究一下FastDFS啥的,但是因为我们项目用的Mongo作为数据库,了解到Mongo自带分布式文件系统GridFs,这简直天助我也。
GridFs介绍
什么时候使用GridFs
我们平时使用Mongo也可以直接把文件的二进制保存在Document中,就相当于mysql的blob格式,但是mongo限制Document最大为16MB,那我们超过16MB的文件可咋办呐,就可以利用GridFs来存储。
- 在某些情况下,在MongoDB数据库中存储大文件可能比在系统级文件系统上更高效。
- 如果文件系统限制目录中的文件数,则可以使用GridFS根据需要存储任意数量的文件。如果要从大型文件的各个部分访问信息而无需将整个文件加载到内存中,可以使用GridFS调用文件的各个部分,而无需将整个文件读入内存。
- 如果要保持文件和元数据在多个系统和设施中自动同步和部署,可以使用GridFS。使用地理位置分散的副本集时,MongoDB可以自动将文件及其元数据分发到多个 mongod实例和工具中。
GridFs的原理
GridFS不是将文件存储在单个文档中,而是将文件分成多个部分或块,并将每个块存储为单独的文档。
GridFS使用两个集合来存储文件。一个集合存储文件块,另一个存储文件元数据。
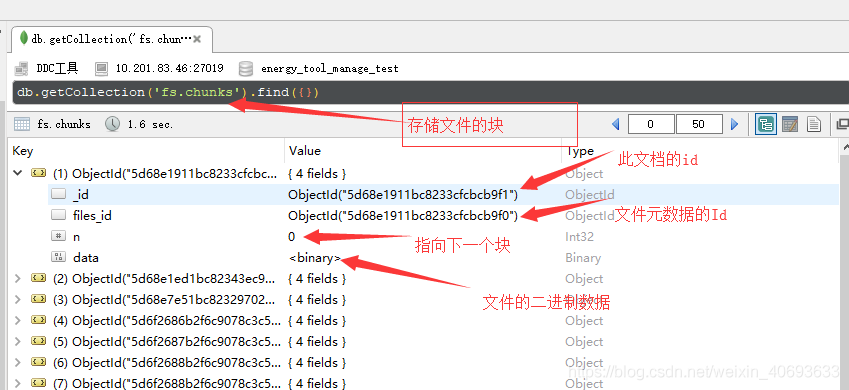
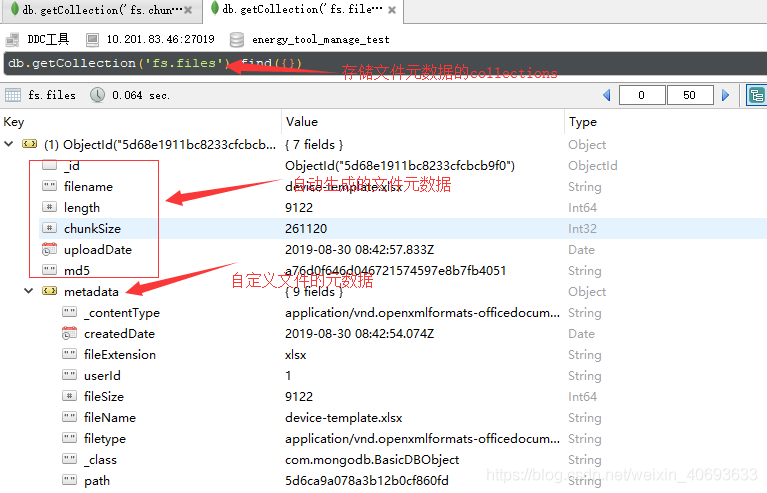
默认情况下,每一个块的大小为255kB; 但最后一个块除外。最后一个块只有必要的大小。类似地,不大于块大小的文件只有最终块,只使用所需的空间和一些额外的元数据。
当查询GridFS文件时,驱动程序将根据需要重新组装块。可以对通过GridFS存储的文件执行范围查询。还可以从文件的任意部分访问信息,例如“跳过”到视频或音频文件的中间。
环境
- Spring Boot 2.0.4
- Maven 3.5
- Java 1.8
- MongoDB 4.0
- Robo 1.3.1
引入依赖和项目配置
首先添加Mongo客户端的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
然后编写配置文件
spring:
application:
name: demo
data:
mongodb:
uri: mongodb://root:你的密码@localhost:27019
authentication-database: admin
database: 你的数据库
使用GridFsTemplate操作GridFs
GridFsTemplate是Spring提供的专门操作GridFs的客户端,提供了一系列开箱即用的方法
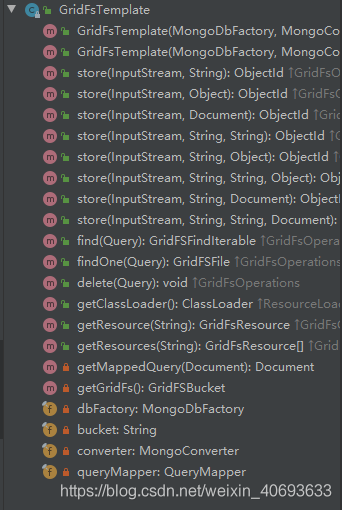
只要把它注入到我们的Conteoller中,就可以愉快的CRUD了,需要注意的是获取文件时要注入MongoDbFactory ,我们使用默认配置的话,直接注入就好。
import com.mongodb.Block;
import com.mongodb.MongoClient;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.gridfs.GridFSBucket;
import com.mongodb.client.gridfs.GridFSBuckets;
import com.mongodb.client.gridfs.model.GridFSFile;
import com.mongodb.client.gridfs.model.GridFSUploadOptions;
import com.mongodb.gridfs.GridFS;
import com.mongodb.gridfs.GridFSDBFile;
import org.bson.BsonValue;
import org.bson.Document;
import org.bson.types.ObjectId;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.util.*;
@RestController
@RequestMapping("/files")
public class FileController {
private Logger logger = LoggerFactory.getLogger(GridFsServiceImpl.class);
//匹配文件ID的正则
private static Pattern NUMBER_PATTERN = Pattern.compile("(?<==).*(?=})");
@Autowired
GridFsTemplate gridFsTemplate;
@Autowired
MongoDbFactory mongoDbFactory;
/**
* 上传文件
*
* @param file 文件
* @return 文件名和文件存储的fileId键值对的Map
*/
@RequestMapping(value = "/upload", method = RequestMethod.POST)
public Map<String, ObjectId> upload(@RequestParam(value = "file") MultipartFile file) {
if(pathId == null || fileType == null || pathId.equals("") || fileType.equals("")){
logger.debug("上传文件出错");
throw new RuntimeException("上传文件出错:pathId and fileType can not be null");
}
Map<String, String> map = new HashMap<>(1);
String fileName = file.getOriginalFilename();
//设置元数据
DBObject metaData = new BasicDBObject();
metaData.put("userId","1");
metaData.put("fileExtension",FilenameUtils.getExtension(file.getOriginalFilename()));
//存储文件的扩展名
try {
InputStream inputStream = file.getInputStream();
ObjectId fileId = gridFsTemplate.store(inputStream, fileName,metaData);
//这个getFileId是我自己封装的获取文件ID的方法
map.put(file.getOriginalFilename(),getFileId(fileId.toString()));
} catch (IOException e) {
logger.debug("上传文件失败: "+file);
throw new RuntimeException("上传文件失败:"+e.getMessage());
}
return map;
}
/**
* 通过文件fileId下载文件
*
* @param fileId 文件fileId
* @param response 文件输出流
*/
@RequestMapping(value = "/downLoadByFileId")
public void downLoadByFileId(@RequestParam(value = "fileId") ObjectId fileId, HttpServletResponse response) {
GridFSFile gridFsFile = gridFsTemplate.findOne(new Query().addCriteria(Criteria.where("_id").is(fileId)));
if (gridFsFile != null) {
// mongo-java-driver3.x以上的版本就变成了这种方式获取
GridFSBucket bucket = GridFSBuckets.create(mongoDbFactory.getDb());
GridFSDownloadStream gridFsDownloadStream = bucket.openDownloadStream(gridFsFile.getObjectId());
GridFsResource gridFsResource = new GridFsResource(gridFsFile,gridFsDownloadStream);
String fileName = gridFsFile.getFilename().replace(",", "");
//处理中文文件名乱码
if (request.getHeader("User-Agent").toUpperCase().contains("MSIE") ||
request.getHeader("User-Agent").toUpperCase().contains("TRIDENT")
|| request.getHeader("User-Agent").toUpperCase().contains("EDGE")) {
fileName = java.net.URLEncoder.encode(fileName, "UTF-8");
} else {
//非IE浏览器的处理:
fileName = new String(fileName.getBytes(StandardCharsets.UTF_8), StandardCharsets.ISO_8859_1);
}
response.setHeader("Content-Disposition", "inline;filename=\"" + fileName + "\"");
response.setContentType(application/octet-stream);
IOUtils.copy(gridFsResource.getInputStream(), response.getOutputStream());
}else {
logger.info("文件不存在");
}
}
/**
* 根据文件名查询文件列表
* @param fileName 文件名
* @return
*/
@RequestMapping("/search")
public List<Map<String,Object>> search(String filePath, String fileName) {
//这里返回的是一个List<Map<String,Object>>
//因为GridFSFindIterable 迭代出来的GridFSFile不能直接返回
GridFSFindIterable gridFSFiles = gridFsTemplate.find(new Query().addCriteria
(Criteria.where("filename").regex("^.*"+fileName+".*$")));
return getGridFSFiles(gridFSFiles);
}
/**
* 通过fileId删除文件
* @param fileId 文件ID
* @return 成功为true, 失败为false
*/
@RequestMapping("/deleteFilesByObjectId")
public boolean deleteFilesByObjectId(@RequestParam(value = "fileId") String fileId) {
try {
gridFsTemplate.delete(new Query().addCriteria(Criteria.where("_id").is(fileId)));
}catch (Exception e){
logger.debug("删除文件失败: fileId= "+fileId);
throw new RuntimeException("删除文件失败:"+e.getMessage());
}
}
/**
* 根据GridFSFiles迭代器返回文件列表,因为不能直接返回,所以写了这个工具方法
* @param gridFSFiles 从数据库取出的文件集合
* @return List<Map<String,Object>>
*/
private List<Map<String,Object>> getGridFSFiles(GridFSFindIterable gridFSFiles){
List<Map<String,Object>> result = new ArrayList<>();
for (GridFSFile file : gridFSFiles) {
HashMap<String,Object> map = new HashMap<>(6);
map.put("fileId",getFileId(file.getId().toString()));
map.put("fileName",file.getFilename());
map.put("fileExtension",file.getMetadata().get("fileExtension"));
map.put("fileSize",file.getLength()/1024);
map.put("uploadTime",file.getUploadDate());
map.put("user",file.getMetadata().get("userId"));
result.add(map);
}
return result;
}
/**
* 因为从mongo中获取的文件Id是BsonObjectId {value=5d7068bbcfaf962be4c7273f}的样子
* 需要字符串截取
* @param bsonObjectId 数据库文件的BsonObjectId
*/
private String getFileId(String bsonObjectId) {
Matcher m = NUMBER_PATTERN.matcher(bsonObjectId);
if(!m.find()){
return bsonObjectId;
}
return m.group();
}
}
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自由互联。