目录 一、测试数据 二、创建DataFrame 方式一:DSL方式操作 方式二:SQL方式操作 一、测试数据 7369,SMITH,CLERK,7902,1980/12/17,800,20 7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30 7521,WARD,SALESMAN,7698,1981/2
目录
- 一、测试数据
- 二、创建DataFrame
- 方式一:DSL方式操作
- 方式二:SQL方式操作
一、测试数据
7369,SMITH,CLERK,7902,1980/12/17,800,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,20
7839,KING,PRESIDENT,1981/11/17,5000,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,20
7900,JAMES,CLERK,7698,1981/12/3,9500,30
7902,FORD,ANALYST,7566,1981/12/3,3000,20
7934,MILLER,CLERK,7782,1982/1/23,1300,10
二、创建DataFrame
方式一:DSL方式操作
- 实例化SparkContext和SparkSession对象
- 利用StructType类型构建schema,用于定义数据的结构信息
- 通过SparkContext对象读取文件,生成RDD
- 将RDD[String]转换成RDD[Row]
- 通过SparkSession对象创建dataframe
- 完整代码如下:
package com.scala.demo.sql
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
object Demo01 {
def main(args: Array[String]): Unit = {
// 1.创建SparkContext和SparkSession对象
val sc = new SparkContext(new SparkConf().setAppName("Demo01").setMaster("local[2]"))
val sparkSession = SparkSession.builder().getOrCreate()
// 2. 使用StructType来定义Schema
val mySchema = StructType(List(
StructField("empno", DataTypes.IntegerType, false),
StructField("ename", DataTypes.StringType, false),
StructField("job", DataTypes.StringType, false),
StructField("mgr", DataTypes.StringType, false),
StructField("hiredate", DataTypes.StringType, false),
StructField("sal", DataTypes.IntegerType, false),
StructField("comm", DataTypes.StringType, false),
StructField("deptno", DataTypes.IntegerType, false)
))
// 3. 读取数据
val empRDD = sc.textFile("file:///D:\\TestDatas\\emp.csv")
// 4. 将其映射成ROW对象
val rowRDD = empRDD.map(line => {
val strings = line.split(",")
Row(strings(0).toInt, strings(1), strings(2), strings(3), strings(4), strings(5).toInt,strings(6), strings(7).toInt)
})
// 5. 创建DataFrame
val dataFrame = sparkSession.createDataFrame(rowRDD, mySchema)
// 6. 展示内容 DSL
dataFrame.groupBy("deptno").sum("sal").as("result").sort("sum(sal)").show()
}
}
结果如下:
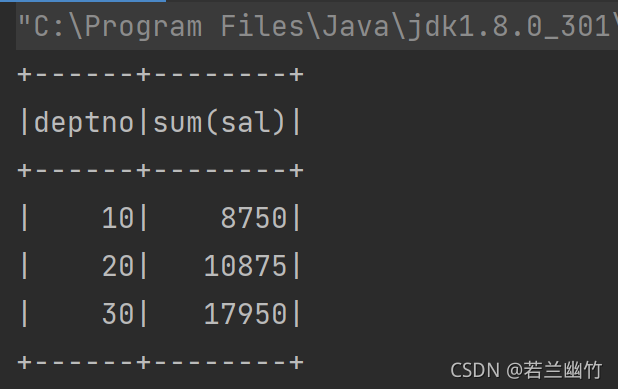
方式二:SQL方式操作
- 实例化SparkContext和SparkSession对象
- 创建case class Emp样例类,用于定义数据的结构信息
- 通过SparkContext对象读取文件,生成RDD[String]
- 将RDD[String]转换成RDD[Emp]
- 引入spark隐式转换函数(必须引入)
- 将RDD[Emp]转换成DataFrame
- 将DataFrame注册成一张视图或者临时表
- 通过调用SparkSession对象的sql函数,编写sql语句
- 停止资源
- 具体代码如下:
package com.scala.demo.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
// 0. 数据分析
// 7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
// 1. 定义Emp样例类
case class Emp(empNo:Int,empName:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptNo:Int)
object Demo02 {
def main(args: Array[String]): Unit = {
// 2. 读取数据将其映射成Row对象
val sc = new SparkContext(new SparkConf().setMaster("local[2]").setAppName("Demo02"))
val mapRdd = sc.textFile("file:///D:\\TestDatas\\emp.csv")
.map(_.split(","))
val rowRDD:RDD[Emp] = mapRdd.map(line => Emp(line(0).toInt, line(1), line(2), line(3), line(4), line(5).toInt, line(6), line(7).toInt))
// 3。创建dataframe
val spark = SparkSession.builder().getOrCreate()
// 引入spark隐式转换函数
import spark.implicits._
// 将RDD转成Dataframe
val dataFrame = rowRDD.toDF
// 4.2 sql语句操作
// 1、将dataframe注册成一张临时表
dataFrame.createOrReplaceTempView("emp")
// 2. 编写sql语句进行操作
spark.sql("select deptNo,sum(sal) as total from emp group by deptNo order by total desc").show()
// 关闭资源
spark.stop()
sc.stop()
}
}
结果如下:
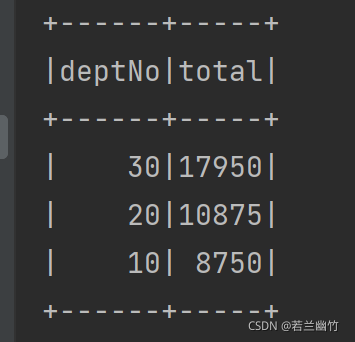
到此这篇关于Spark SQL 2.4.8 操作 Dataframe的两种方式的文章就介绍到这了,更多相关Spark SQL 操作 Dataframe内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!