目录
- 一、前情提要
- 为什么要使用Scrapy 框架?
- 二、Scrapy框架的概念
- 三、Scrapy安装
- 四、Scrapy实战运用
- 这一串代码干了什么?
- 五、Scrapy的css选择器教学
- 按标签名选择
- 按 class 选择
- 按 id 选择
- 按层级关系选择
- 取元素中的文本
- 取元素的属性
一、前情提要
为什么要使用Scrapy 框架?
前两篇深造篇介绍了多线程这个概念和实战
多线程网页爬取
多线程爬取网页项目实战
经过之前的学习,我们基本掌握了分析页面、分析动态请求、抓取内容,也学会使用多线程来并发爬取网页提高效率。这些技能点已经足够我们写出各式各样符合我们要求的爬虫了。
但我们还有一个没解决的问题,那就是工程化。工程化可以让我们写代码的过程从「想一段写一段」中解脱出来,变得有秩序、风格统一、不写重复的东西。
而Scrapy 就是爬虫框架中的佼佼者。它为我们提前想好了很多步骤和要处理的边边角角的问题,而使用者可以专心于处理解析页面、分析请求这种最核心的事情。
二、Scrapy框架的概念
Scrapy 是一个纯 Python 实现的、流行的网络爬虫框架,它使用了一些高级功能来简化网页的抓取,能让我们的爬虫更加的规范、高效。
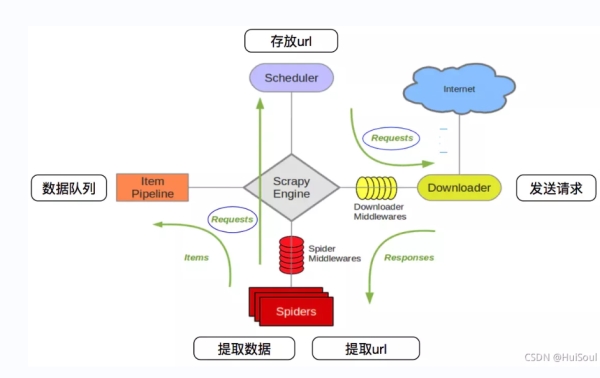
它可以分为如下几个部分
Scrapy 中数据流的过程如下
三、Scrapy安装
Win + R打开运行,点击确定
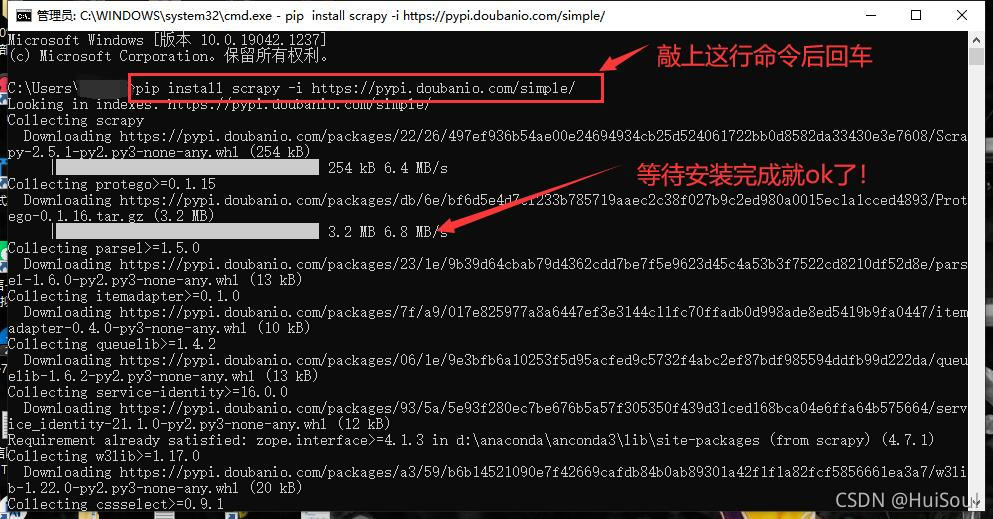
然后在命令行上敲上
pip install scrapy -i https://pypi.doubanio.com/simple/ # 这句话后面 -i https://pypi.doubanio.com/simple/ 表示使用豆瓣的源,这样安装会更快
之后点击回车,等待它自己安装完成便可!
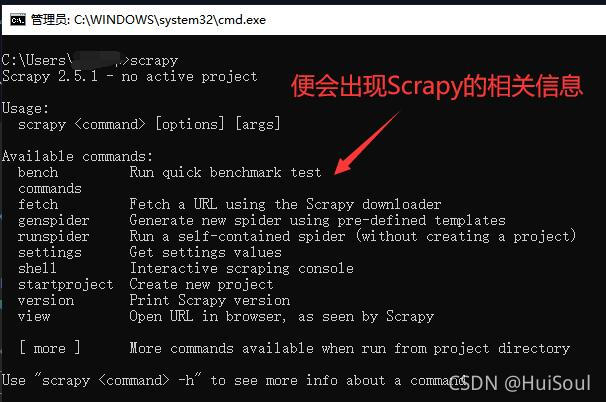
然后,我们在命令行上敲上scrapy,便会显示scrapy的信息,这样就代表安装成功啦!
注意!!再然后我们在命令行敲上 explorer . (Mac 中是 open .,注意 . 前面有个空格) 命令并回车,可以打开命令行当前所在的目录。下面,我们就要在这个目录里开始编写代码。
四、Scrapy实战运用
这次我们试着用Scrapy爬取的网站是:小众软件 https://www.appinn.com/category/windows/
在进行网页爬取前,我们先需要创建代码文件,然后利用Scrapy命令进行执行。
在上面我们利用 explorer . 命令打开了目录,在这个目录下我们创建一个 spider.py 的文件↓
方法:创建文本文件改后缀名即可

然后将爬虫代码放进去,现在大家先复制黏贴代码,进行尝试一下,之后我再来讲解代码的含义!

爬虫代码
import scrapy
# 定义一个类叫做 TitleSpider 继承自 scrapy.Spider
class TitleSpider(scrapy.Spider):
name = 'title-spider'
# 设定开始爬取的页面
start_urls = ['https://www.appinn.com/category/windows/']
def parse(self, response):
# 找到所有 article 标签
for article in response.css('article'):
# 解析 article 下面 a 标签里的链接和标题
a = article.css('h2.title a')
if a:
result = {
'title': a.attrib['title'],
'url': a.attrib['href'],
}
# 得到结果
yield result
# 解析下一页的链接
next_page = response.css('a.next::attr(href)').get()
if next_page is not None:
# 开始爬下一页,使用 parse 方法解析
yield response.follow(next_page, self.parse)
然后在命令行中执行 scrapy 的 runspider 命令
scrapy runspider spider.py -t csv -o apps.csv # spider.py 是刚刚写的爬虫代码的文件名 # -t 表示输出的文件格式,我们用 csv,方便用 Excel 等工具打开 # -o 表示输出的文件名,所以执行完会出现一个 apps.csv 的文件
敲完上面这句命令,稍等一下,你应该能看见很多的输出👇
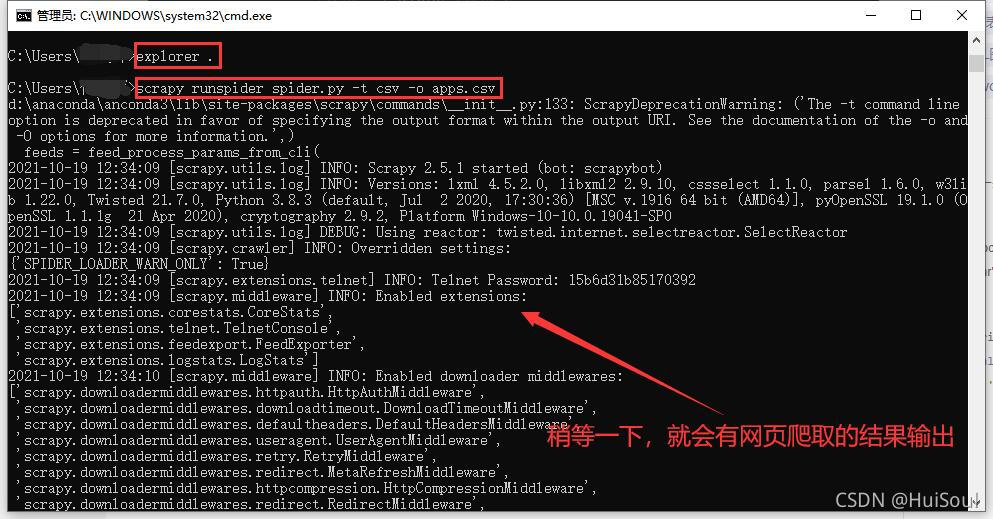
网页爬取结果
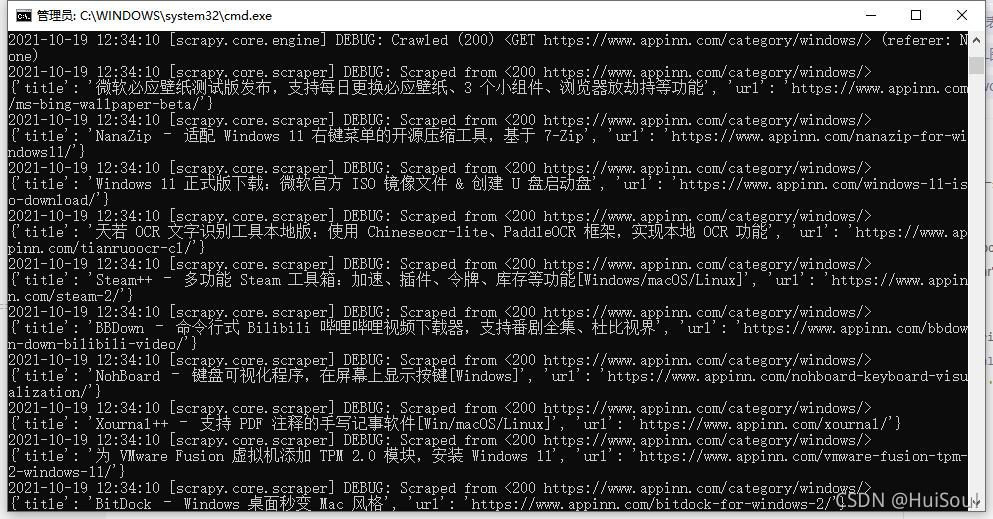
以及目录里多出来一个 apps.csv 文件。有 Excel 的同学可以用 Excel 打开 apps.csv,或者直接用记事本或者其他编辑器打开它。

打开后能看见 400 多篇小众软件的软件推荐文章的标题和链接👇
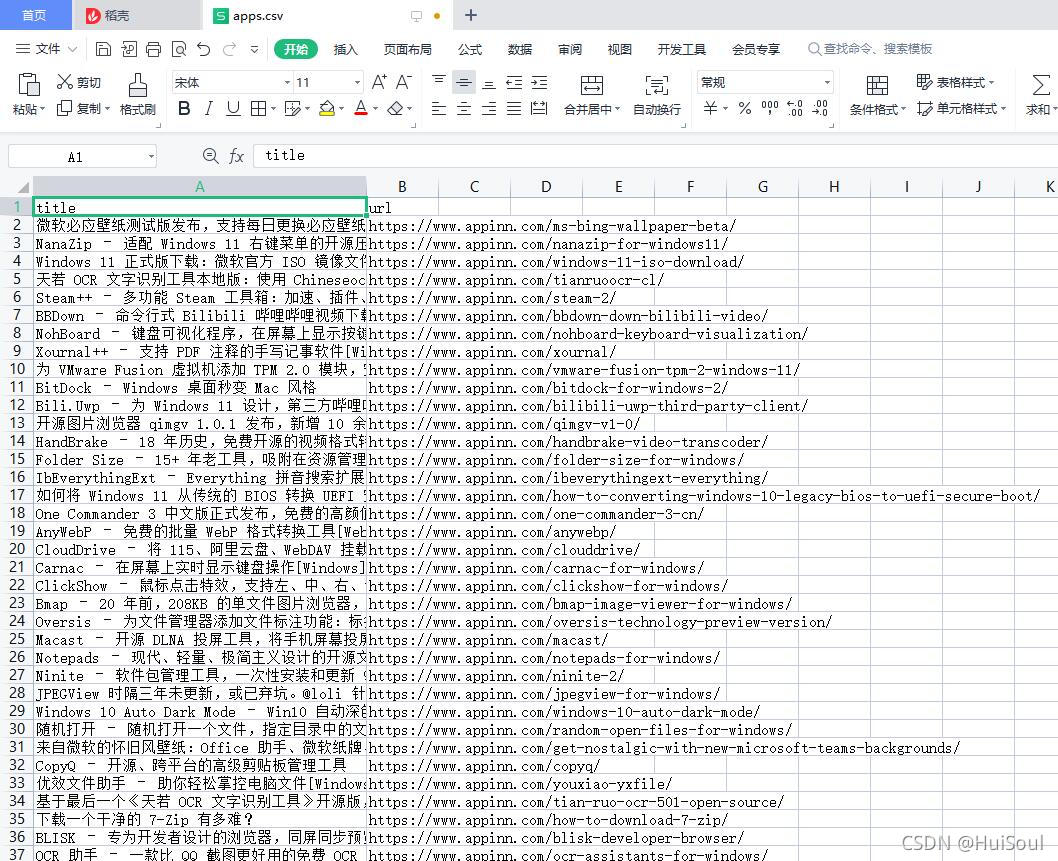
可是我们的代码里完全没有用到 requests、beautifulsoup、concurrent 以及文件相关的库,是怎么完成了一次快速的爬取并写到文件的呢?别急,让我为你慢慢讲解!
这一串代码干了什么?
上面用到的爬虫代码
import scrapy
# 定义一个类叫做 TitleSpider 继承自 scrapy.Spider
class TitleSpider(scrapy.Spider):
name = 'title-spider'
# 设定开始爬取的页面
start_urls = ['https://www.appinn.com/category/windows/']
def parse(self, response):
# 找到所有 article 标签
for article in response.css('article'):
# 解析 article 下面 a 标签里的链接和标题
a = article.css('h2.title a')
if a:
result = {
'title': a.attrib['title'],
'url': a.attrib['href'],
}
# 得到结果
yield result
# 解析下一页的链接
next_page = response.css('a.next::attr(href)').get()
if next_page is not None:
# 开始爬下一页,使用 parse 方法解析
yield response.follow(next_page, self.parse)
当运行scrapy runspider spider.py -t csv -o apps.csv时,Scrapy 会执行我们写在 spider.py里的爬虫,也就是上面那段完整的代码
1、首先,Scrapy 读到我们设定的启动页面 start_urls,开始请求这个页面,得到一个响应。
// An highlighted block start_urls = ['https://www.appinn.com/category/windows/']
2、之后,Scrapy 把这个响应交给 默认 的解析方法 parse 来处理。响应 response 就是 parse 的第一个参数
def parse(self, response):
3、在我们自己写的 parse 方法里,有两个部分:一是解析出页面里的 article 标签,得到标题和链接作为爬取的结果;二是解析 下一页 按钮这个位置,拿到下一页的链接,并同样继续请求、然后使用 parse 方法解析
# 把这条结果告诉 Scrapy yield result # 通知 Scrapy 开始爬下一页,使用 parse 方法解析 yield response.follow(next_page, self.parse)
yield 是 Python 中一个较高级的用法,在这里我们只需要知道,我们通过 yield 通知 Scrapy 两件事:我们拿到了结果,快去处理吧、我们拿到了下一个要爬的链接,快去爬取吧。
流程图
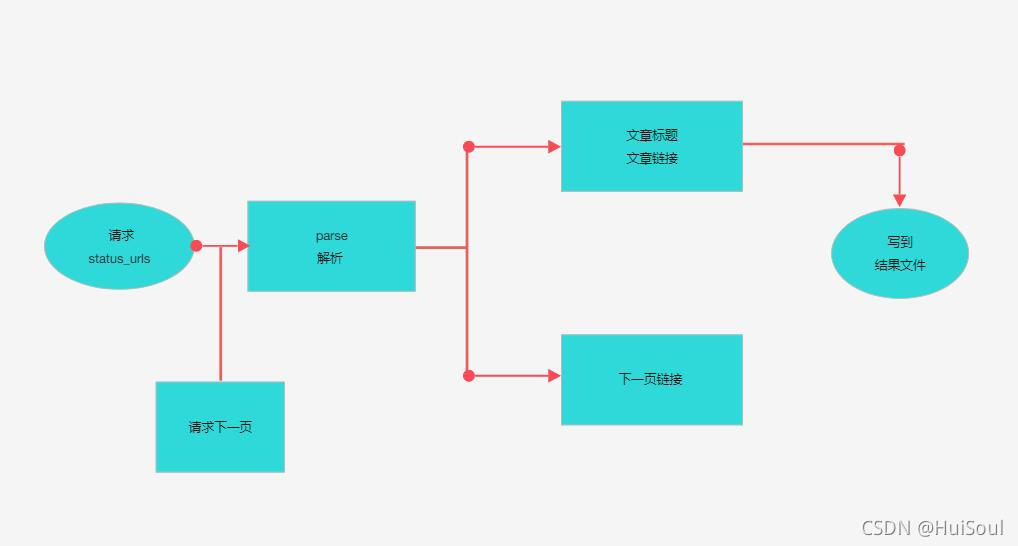
没错,除了解析想要的数据,其他的一切都是 Scrapy 替你完成的。这就是 Scrapy 的最大优势:
requests 去哪了?不需要,只要把链接交给 Scrapy 就会自动帮你完成请求;
concurrent 去哪了?不需要,Scrapy 会自动把全部的请求都变成并发的;
怎么把结果写到文件?不用实现写文件的代码,使用 yield 通知一下 Scrapy 结果即可自动写入文件;
怎么继续爬取下一个页面?使用 yield 通知 =Scrapy下一个页面的链接和处理方法就好;
BeautifulSoup 去哪了?可以不需要,Scrapy 提供了好用的 CSS 选择器。
解析数据这件事情还是值得我们关心的,即使 Scrapy 没有强制让我们使用什么,因此我们非要继续使用 BeautifulSoup也是可以的,只需在 parse() 方法里将 response.text 传递给 BeautifulSoup 进行解析、提取即可。
但是 Scrapy 提供了很好用的工具,叫做 CSS 选择器。CSS 选择器我们在 BeautifulSoup 中简单介绍过,你还有印象吗?
对BeautifulSoup这个库忘记了的同学,可以看看我之前写的一篇文章:requests库和BeautifulSoup库
Scrapy 中的 CSS 选择器语法和 BeautifulSoup 中的差不多,Scrapy 中的 CSS 选择器更加强大一些
# 从响应里解析出所有 article 标签
response.css('article')
# 从 article 里解析出 class 为 title 的 h2 标签 下面的 a 标签
article.css('h2.title a')
# 取出 a 里面的 href 属性值
a.attrib['href']
# 从响应里解析出 class 为 next 的 a 标签的 href 属性,并取出它的值
response.css('a.next::attr(href)').get()
scrapy 中的 CSS 选择器可以取代 beautifulsoup 的功能,我们直接用它就解析、提取获取到的数据。看到这里,再回头看上面的完整代码,试着结合流程图再理解一下就会有不错的了解了。
五、Scrapy的css选择器教学
我们还是打开之前爬取的网站:小众软件 https://www.appinn.com/category/windows/
用网页开发者工具选中 下一页↓
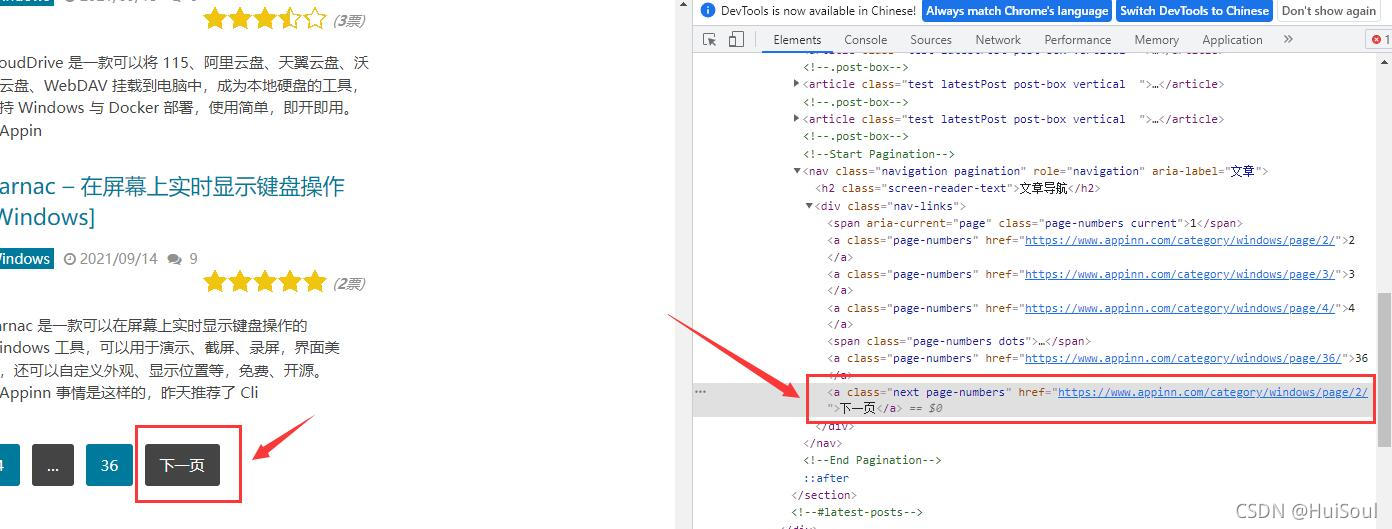
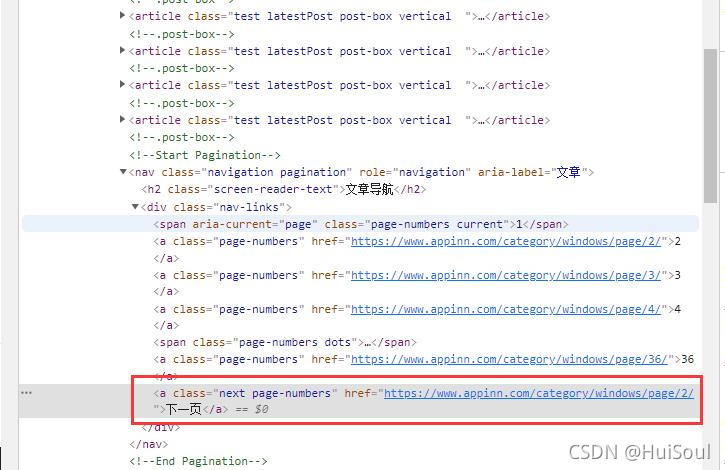
注意截图中被框住的部分,浏览器已经展示出来这个按钮的 CSS 选择方法是什么了。它告诉我们下一页按钮的选择方式是a.next.page-numbers。
开始css选择器教学前,我建议你使用 Scrapy 提供的互动工具来体验一下 CSS 选择器。方式是在命令行中输入以下命令并回车
scrapy shell "https://www.appinn.com/category/windows/"
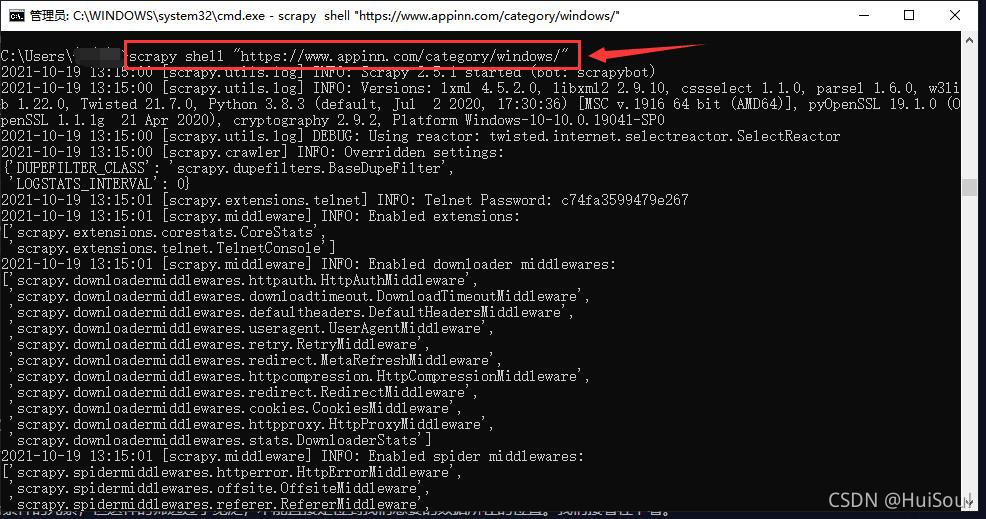
这时 Scrapy 已经访问了这个链接,并把获取到的结果记录了下来,你会进入到一个交互环境,我们可以在这个环境里写代码并一句一句执行。输入 response 并回车,你能看见类似下面的响应,这就是上面获取到的网页结果。
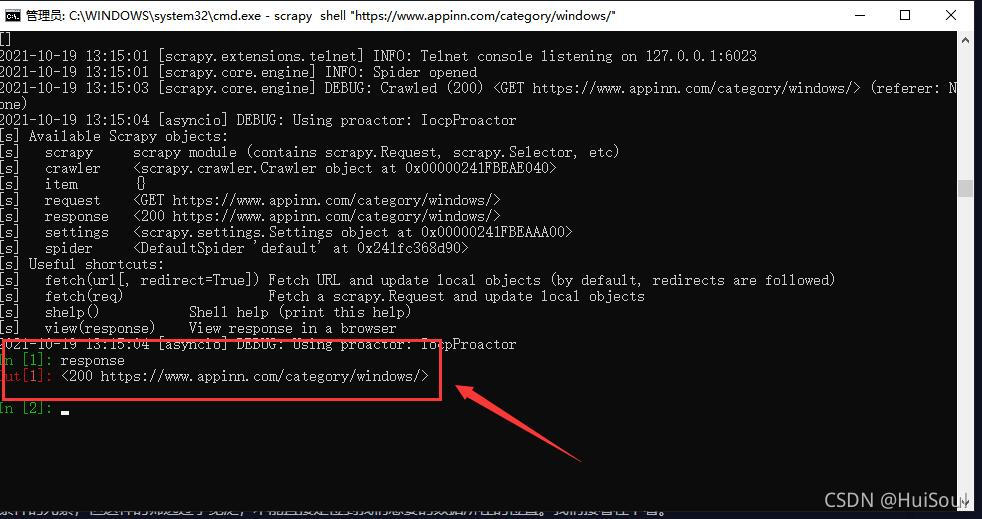
我之前有说过,输出的200其实就是一个响应状态码,意思就是请求成功了!
之前的文章:requests库和BeautifulSoup库
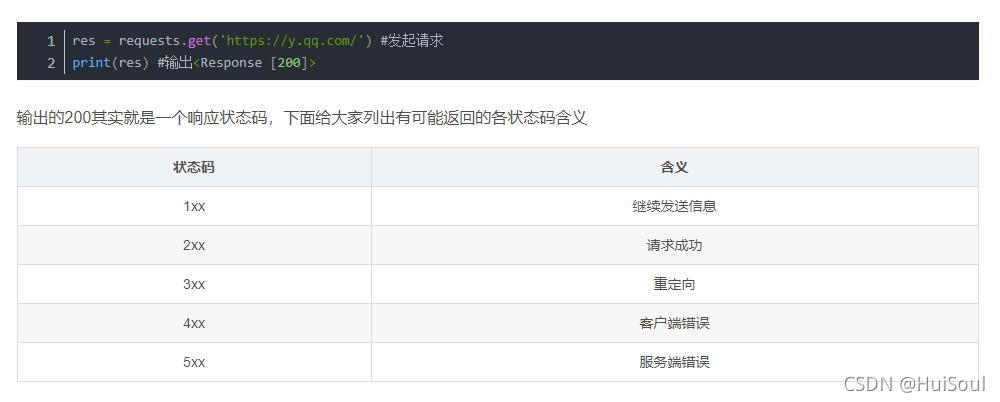
下面我们就来学习一下css选择器吧,我们以下图中“下一页”按钮为例子👇
按标签名选择
小众软件网站下一页按钮的选择方式是 a.next.page-numbers,其中的 a 是标签名。试着在互动环境中,输入 response.css(‘a'),可以看到页面上所有的 a 元素。其他元素也是一样,例如写 response.css(‘ul') 就可以选择出所有 ul 元素,response.css(‘div') 可以选择出 div 元素。
按 class 选择
a.next.page-numbers 中的.next 和 .page-numbers 表示 class的名字。当我们想要选择 class 包含 container 的 div 元素,我们可以写response.css(‘div.container')。
上面的选择器前面是标签名,. 表示 class,后面跟着 class 的名称。注意,它们是紧紧挨在一起的,中间不能有空格!
当要选择的元素有多个 class 时,比如下面这样的一个元素
<a class="next page-numbers" href="/windows/page/2/" rel="external nofollow" >下一页</a>
这个 a 元素有 next 和 page-number 两个 class,可以写多个 . 来选择:response.css(‘a.next.page-numbers')。表示选择 class 同时包含 next 和 page-numbers 的 a 元素,这里它们也必须紧挨在一起,之前不能有空格。
按 id 选择
除了 class 选择器外,同样也有 id 选择器,Scrapy 中也是用 # 代表 id。比如网页上的菜单按钮,我们看到它的 id 是 pull,class 是 toggle-mobile-menu。所以可以写 response.css(‘a#pull'),表示我们想选择一个 id 为 pull 的 a 元素。
当然,你也可以组合使用:response.css(‘a#pull.toggle-mobile-menu')。表示我们要选择 id 为 pull,并且 class 包含 toggle-mobile-menu 的 a 元素。
按层级关系选择
还是小众软件的这个页面,如果我们想用 CSS 选择器选中标题这个位置的 a 元素,使用 Chrome 选取之后发现这个 a 元素既没有 id 也没有 class,浏览器也只给我们提示一个 a👇
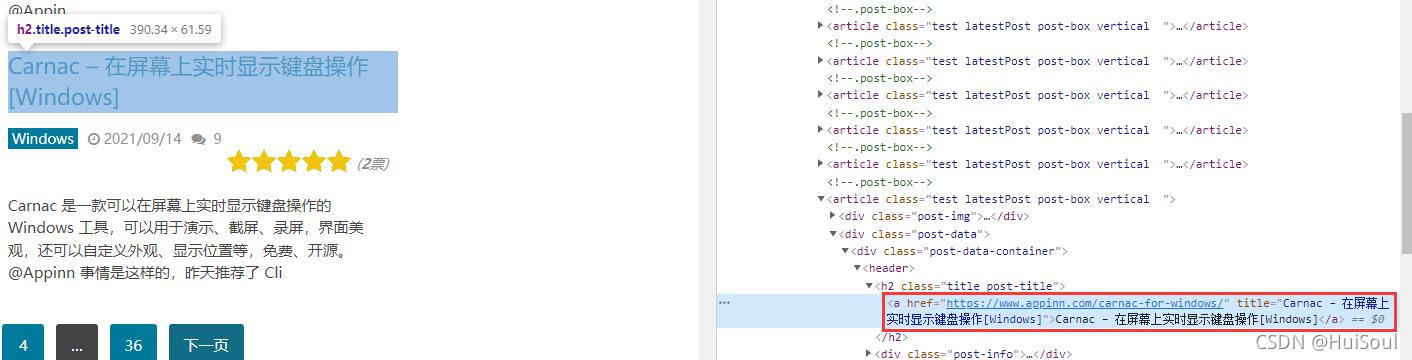
这时,我们就需要在该元素的父元素上找找线索,例如我们发现这个 a 元素在一个 h2 元素的下面,而这个 h2 元素是有 class 的,class 为 title 和 post-title。所以我们要做的是选择 class 为 title 和 post-title 的 h2 元素下面的 a 元素,用 CSS 选择器写作
response.css('h2.title.post-title a::text')
可以看到,title 和 post-title 的 h2 元素写作 h2.title.post-title,是紧紧连在一起的,而下面的 a 元素则在 a 前面加了一个空格。想起之前说过的规则了吗?规则便是:并列关系连在一起,层级关系用空格隔开。
.title 和 .post-title 紧跟在 h2 后面,它俩都是 h2 的筛选条件。而空格后面跟着的 a 表示符合 h2.title.post-title 条件元素的子元素中的所有 a 元素。
我们之前还说过,空格后面表示的是所有的子元素,不管是处于多少层的子元素。而如果只想要第一层的子元素则应该用 > 分隔开。这里的 a 元素就是第一层的子元素,所以 h2.title.post-title a 和 h2.title.post-title > a 这两种写法的效果是一样的。
取元素中的文本
我们拿到了标题位置的 a 元素,想要拿到其中的文本内容就需要在后面加上 ::text,代码如下
response.css('h2.title.post-title a::text')
在互动环境执行一下,会发现文本内容能获取到,但不是我们想要的纯文本,如果想拿到纯文本,还需要使用 get() 或者 getall() 方法,如下
# 取符合条件的第一条数据
response.css('h2.title.post-title a::text').get()
# 取符合条件的所有数据
response.css('h2.title.post-title a::text').getall()
取元素的属性
还是用这个 a 元素举例。如果我们想得到这个 a 元素的 href 属性,需要调用这个元素的 attrib 属性。在互动环境中执行下面两句代码
# 拿到符合选择器条件的第一个 a 标签
a = response.css('h2.title.post-title a')
a.attrib['href']
attrib 属性实际上是一个字典,里面存储了元素上的所有 HTML 属性。如果把第二句换成 a.attrib,你就能看到这个 a 元素上的所有属性。类似的,输入 a.attrib[‘title'],你可以得到它的 title 属性。
现在我们试试打印所有符合 h2.title.post-title a 这个条件的标签的 href 属性,就像下面这样
for a in response.css('h2.title.post-title a'):
print(a.attrib['href'])
或者另一种写法也可以取到 href 属性,就是加上 ::attr(href)
for href in response.css('h2.title.post-title a::attr(href)').getall():
print(href)
本次分享到此结束了,非常感谢大家阅读!!
有问题欢迎评论区留言!!
以上就是Python爬虫进阶Scrapy框架精文讲解的详细内容,更多关于Python爬虫Scrapy框架的资料请关注易盾网络其它相关文章!