目录 Java Tess4J实现图像识别 首先,下载Tess4J的相关资源(一个压缩包) 项目的的目录如下 lib中的文件如下(tess4J.jar也在该目录下) 再在eclipse中打开项目 Tess4J的代码比较简洁 效果如
目录
- Java Tess4J实现图像识别
- 首先,下载Tess4J的相关资源(一个压缩包)
- 项目的的目录如下
- lib中的文件如下(tess4J.jar也在该目录下)
- 再在eclipse中打开项目
- Tess4J的代码比较简洁
- 效果如下
Java Tess4J实现图像识别
最近需要用Java做一个图像识别的东西,查了一些资料,在此写一个基于Tess4J的教程,方便其他人参考和使用。
其实做图像识别,也可以使用TESSERACT-OCR来实现,但是该方式需要下载软件,在电脑上安装环境,移植性不高,使用Tess4J只需要下载相关Jar包,导入项目,再把项目封装好就可以处处运行了。
首先,下载Tess4J的相关资源(一个压缩包)
官网:http://tess4j.sourceforge.net/codesample.html
解压,其中的目录结构如下:
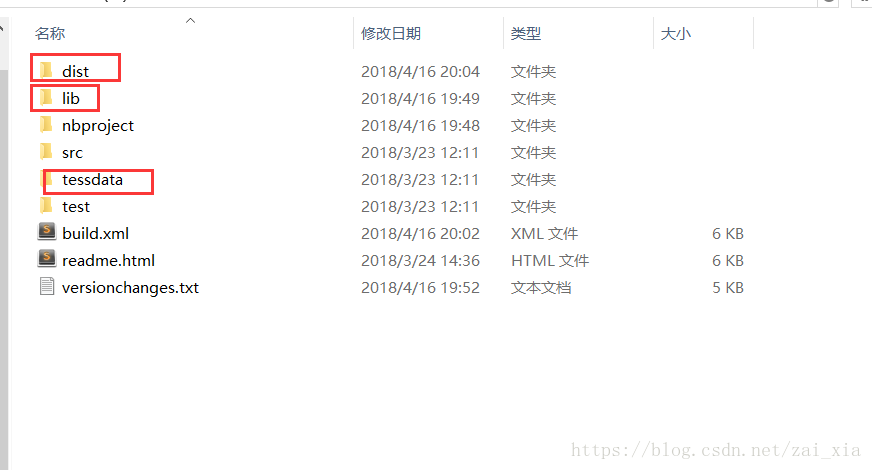
需要用到其中圈起来的三个文件夹中的东西。lib文件夹下放的是需要用到的Jar包,tessdata下放的是语言库,默认的有英语库,中文库需要另外下载,下载地址:https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata。
新建一个Java项目,将lib文件夹和tessdata文件夹复制到项目的根目录下,找到dist文件夹下的tess4j.jar(名字可能有版本号),将该文件也复制到项目根目录下的lib文件夹下。
项目的的目录如下

lib中的文件如下(tess4J.jar也在该目录下)
再在eclipse中打开项目
在项目中导入lib文件夹中所有的jar包(Build path --> configure build path),导入后的结果如下:

这样前期准备工作就完成了,下面就剩下代码了。
Tess4J的代码比较简洁
如下:
Tess4JTest.java
package ocr;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import net.sourceforge.tess4j.util.LoadLibs;
import java.io.File;
import java.io.IOException;
/**
* Tess4J测试类
*/
public class Tess4JTest {
public static void main(String[] args){
String path = "D://Java//Tess4J";//我的项目存放路径
File file = new File(path + "//photo.jpg");
ITesseract instance = new Tesseract();
/**
* 获取项目根路径,例如: D:\IDEAWorkSpace\tess4J
*/
File directory = new File(path);
String courseFile = null;
try {
courseFile = directory.getCanonicalPath();
} catch (IOException e) {
e.printStackTrace();
}
//设置训练库的位置
instance.setDatapath(courseFile + "//tessdata");
instance.setLanguage("eng");//chi_sim :简体中文, eng 根据需求选择语言库
String result = null;
try {
long startTime = System.currentTimeMillis();
result = instance.doOCR(file);
long endTime = System.currentTimeMillis();
System.out.println("Time is:" + (endTime - startTime) + " 毫秒");
} catch (TesseractException e) {
e.printStackTrace();
}
System.out.println("result: ");
System.out.println(result);
}
}
这样就搞定了。
效果如下
原图:

读取结果:

从结果来看准确率还有待提高,l 和 1分不清,0 和 O 也没有分清,汉字的准确率还要低一些,大家可以自行训练字体库优化。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自由互联。