目录
- spring data jpa saveAll() 保存过慢
- 问题发现
- 解决方案1 此方案在第二天失效了
- 以上方案有问题,下面附上彻底解决的截图和记录
- JPA的saveAll方法执行效率很差
spring data jpa saveAll() 保存过慢
问题发现
今天在生产环境执行保存数据时 影响队列中其他程序的运行 随后加日志排查 发现 执行 4500条 insert操作时 耗时 9分钟 我类个去…
解决方案1 此方案在第二天失效了
废话不多说 直接上配置文件参数
application-prod.yml 部分参数如下
jpa:
show-sql: false
hibernate:
ddl-auto: none
properties:
hibernate:
jdbc:
#为spring data jpa saveAll方法提供批量插入操作 此处可以随时更改大小 建议500哦
batch_size: 500
batch_versioned_data: true
order_inserts: true
通过日志打印 执行结果如下
未开批处理 4507条 耗时: 227167ms
开启批处理 500/次 4507条 耗时: 29140ms
开启批处理 1000/次 4507条 耗时: 29631ms
以上方案有问题,下面附上彻底解决的截图和记录
后来发现在生产运行了一天 还是会导致保存阻塞的问题 100条保存耗时 9分钟!!!
数据库此时数据有300w条
于是分析 saveAll()的源代码
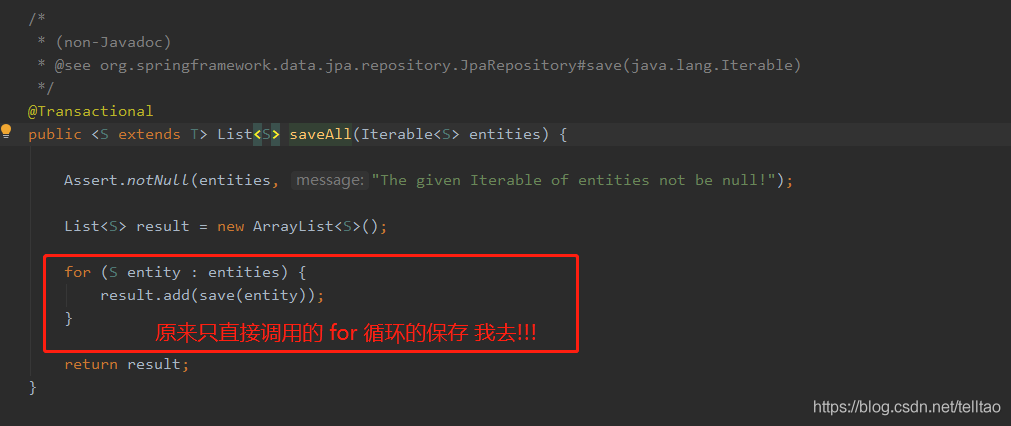
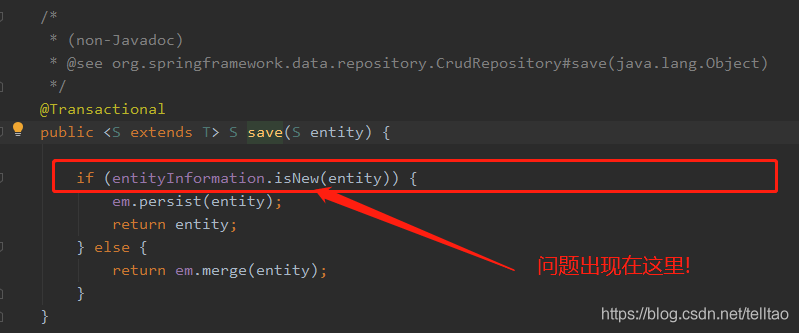
原来这个保存的时候 会去数据库查询这条数据是否存在 如果存在 则修改 不存在则直接添加 如下图

重写 saveAll() 的方法 就是仿照它 for循环里面直接调用 save()方法
@PersistenceContext() protected EntityManager em;
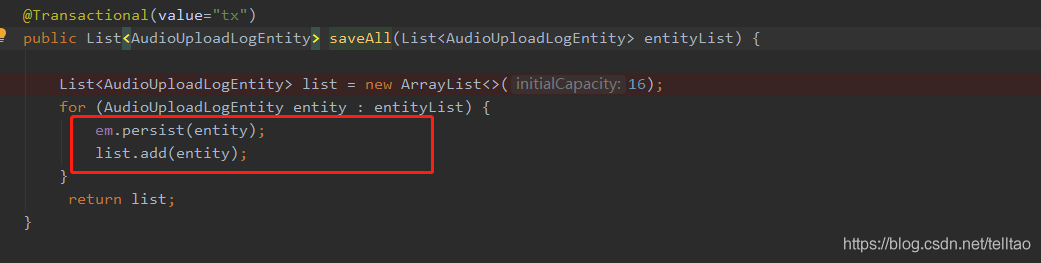
此处你们可以改成泛型的方式,提取公共类,封装一下即可。
JPA的saveAll方法执行效率很差
springboot项目中使用了SpringDataJpa的技术,很方便,省了很多dao层繁琐的步骤,但是有一个接口需要批量更新或者插入,数据量挺大,大概1-2w条,每条记录20-30个字段吧,对于刚工作不久的我还是比较大的。我开始使用的saveAll(),因为本地单元测试,也没考虑那么多(其实更早期更蠢,遍历再save,压根不去考虑数据库连接池的压力或者说每次遍历都要去连接数据库的时间损耗…),但是客户压力测试,我的接口就拉胯了。接口等待时间太久…诶
刚开始的思路想解决saveAll方法为什么这么慢的问题,因为saveAll是有则更新,无则新增,所以每条记录都要去比对该记录是否存在表中,效率比较差(我以后还是用JPA去适应数据量较小的吧,jpa可能还有什么别的路子后面可以配置进去也行)。
最后改用了mybatis的foreach方式,虽然比较老套而且肯定不是最快的办法,但是还是实用。
使用过程中,出现了这个报错:
Packet for query is too large (3227 > 1024). You can change this value on the server by setting the max_allowed_packet' variable.
应该是一下子丢进来的数据太大,超过了mysql的限制,有人说通过修改数据库的max_allowed_packet这个属性来修改,不过我这里是jenkins部署的服务器,能操作到数据库的只有navicat这个可视化工具,如果使用命令行修改这个属性,好像只能暂时起效。我只好类似分页,把18000条数据按照2000一次批量操作,分成9次,这样既不会报错,也会比savelAll快一些。后续再研究一下更快更高效的方法。
数据库配置加上allowMultiQueries=true才会支持foreach循环操作。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自由互联。