正则表达式是查找和替换文本模式的一种简洁而灵活的表示法。 在“查找和替换”窗口中执行“快速查找”、“在文件中查找”、“快速替换”或“在文件中替换”操作时,可以在该窗口的“查找内容”和“替换为”字段中使用一组专用的正则表达式。
若要启用正则表达式,请在“查找和替换”窗口中展开“查找选项”,选择“使用”,然后选择“正则表达式”。“查找内容”和“替换为”字段旁的三角形“表达式生成器”按钮将变为可用。 单击此按钮可以列表显示最常用的正则表达式。 当单击列表上的某个正则表达式时,它将插入“查找内容”或“替换为”字段中的光标所在位置。 单击“表达式生成器”底部的“完整字符列表”时,会显示帮助主题。 主题内容涵盖 Visual Studio“查找和替换”功能可以识别的所有正则表达式。 您可以复制主题中的正则表达式,然后将其粘贴到“查找内容”或“替换为”字段中。
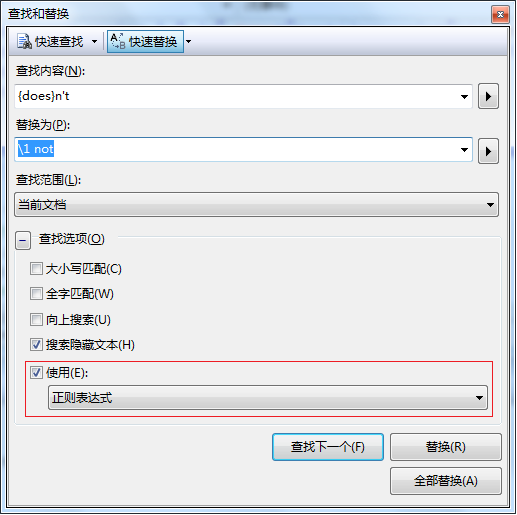
“查找内容”和“替换为”中可使用的正则表达式与 .NET Framework 编程中的有效正则表达式有许多语法上的区别。例如,在“查找和替换”窗口中,大括号 {} 用于标记的表达式的替换:将每次出现的 doesn't 改为 does not,你应该使用查找表达式 {does}n't 和替换表达式 \1 not。
用于“查找和替换”的正则表达式
“表达式生成器”中经常使用的正则表达式如下所示。
表达式
语法
说明
示例
任一字符
.
匹配除分行符外的任何一个字符。
a.o 匹配“around”中的“aro”和“about”中的“abo”,但不匹配“across”中的“acro”。
零个或
多个
*
不匹配上一表达式,或匹配多次,并生成所有可能的匹配。
a*b 匹配“bat”中的“b”和“about”中的“ab”。
e.*e 匹配单词“enterprise”。
一个或
更多个
+
匹配前面表达式的至少一个搜索项。
ac+ 匹配包含字母“a”和至少一个字母“c”的单词,如“race”和“ace”。
a.+s 匹配单词“access”。
行首
^
将匹配字符串锚定到行首。
^car 仅当单词“car”显示为编辑器行中的第一组字符时匹配该单词。
行尾
$
将匹配字符串锚定到行尾。
end$ 仅当单词“end”显示为可能位于编辑器中行尾的最后一组字符时匹配该单词。
词首
<
仅当单词在文本中以此开头时才匹配。
<in 匹配以字母组合“in”开头的单词,如“inside”和“into”。
词尾
>
仅当词在文本中的此位置结束时才匹配。
ss> 匹配以字母组合“ss”结尾的单词,如“across”和“loss”。
换行符
\n
匹配与操作系统无关的换行符。 在“替换”表达式中,插入换行符。
End\nBegin 仅当“End”是一行中的最后一个字符串和“Begin”是下一行中的第一个字符串时匹配单词“End”和“Begin”。
在“替换”表达式中,Begin\nEnd 使用“Begin”替换第一行中的单词“End”,插入换行符,然后使用单词“End”替换单词“Begin”。
集中的任何一个字符
[]
匹配 [] 内的任何一个字符。 若要指定字符的范围,请列出由短划线 (-) 分隔的起始字符和结束字符,如 [a-z]。
be[n-t] 匹配“between”中的“bet”、“beneath”中的“ben”和“beside”中的“bes”,但不匹配“below”中的“bel”。
集中没有的任何一个字符
[^...]
匹配未在跟随 ^ 的字符集中指定的任何字符。
be[^n-t] 匹配“before”中的“bef”、“behind”中的“beh”和“below”中的“bel”,但是不匹配“beneath”中的“ben”。
Or
|
匹配 OR 符号 (|) 之前或之后的表达式。 最常用在分组中。
(sponge|mud) bath 匹配“sponge bath”和“mud bath”。
转义符
\
按原义匹配反斜杠 (\) 之后的字符。 这使您可以查找正则表达式表示法中使用的字符,如 { 和 ^。
\^ 搜索 ^ 字符。
带标记的表达式(或反向引用)
{}
使用括号内的文本来标识要替换的文本的位置。
{does}n't 标识在替换字符串中的更换之前的文本,\1 not 更改出现的每个项。
C/C++ 标识符
:i
表达式 ([a-zA-Z_$][a-zA-Z0-9_$]*) 的简写形式。
匹配任何可能的 C/C++ 标识符。
带引号的字符串
:q
表达式 (("[^"]*")|('[^']*')) 的简写形式,它匹配用双引号或单引号括起来的所有字符,还匹配引号本身。
:q 匹配“测试引用”和‘测试引用',但不匹配“can't”中的“'t”。
空格或制表符
:b
匹配空格或制表符。
Public:bInterface 匹配文本中的短语“Public Interface”。
整数
:z
表达式 ([0-9]+) 的简写形式,它匹配数字字符的任何组合。
匹配任何整数,如“1”、“234”、“56”等等。
“查找”和“替换”操作中所有有效正则表达式的列表,比“表达式生成器”中可显示的列表长。尽管“表达式生成器”中没有显示下面的正则表达式,但您可以在“查找内容”或“替换为”字段中使用它们。
表达式
语法
说明
示例
最少、
零个或
更多个
@
匹配前面表达式的 0 个或更多搜索项,并匹配尽可能少的字符。
e.@ 匹配“enterprise”中的“ente”和“erprise”,但不匹配完整的单词“enterprise”。
最少、
一个或
更多个
#
匹配前面表达式的一个或更多搜索项,并匹配尽可能少的字符。
ac# 匹配包含字母“a”和至少一个字母“c”的单词,如“ace”。
a.#s 匹配单词“access”中的“acces”。
重复
n次
^n
匹配前面表达式的 n 次出现。
[0-9]^4 匹配任意 4 位数字的序列。
分组
()
允许将一组表达式组合在一起。 如果要在一次操作中搜索两个不同的表达式,可以使用分组表达式来组合这两个表达式。
如果要搜索(-[a-z][1-3]或-[0-9][a-z],应按如下方式组合这两个表达式:([a-z][1-3])|(-[0-9][a-z])。
第n个
带标记
的文本
\n
在“查找”或“替换”表达式中,指示第 n 个带标记的表达式所匹配的文本,其中 n是从 1 至 9 的数字。
在“替换”表达式中,\0 插入整个匹配的文本。
如果搜索a{[0-9]},并替换为\1,则“a”后跟数字的所有搜索项由跟随的数字替换。例如,“a1”由“1”替换,类似地,“a2”由“2”替换。
右对齐字段
\(w,n)
在“替换”表达式中,将字段中第 n 个带标记的表达式右对齐至少 w 字符宽。
如果搜索a{[0-9]},并替换为\(10,1),则“an”的搜索项由整数替换,并通过 10 个空格右对齐。
左对齐字段
\(-w,n)
在“替换”表达式中,将字段中第 n 个带标记的表达式左对齐至少 w 字符宽。
如果搜索a{[0-9]},并替换为\(-10,1),则“an”由整数替换,并通过 10 个空格左对齐。
禁止
匹配
~(X)
当 X 出现在表达式中的此位置时禁止匹配。
real~(ity)匹配“realty”和“really”中的“real”,但不匹配“reality”中的“real”。
字母
数字
字符
:a
匹配表达式 ([a-zA-Z0-9])。
匹配任何字母数字字符,如“a”、“A”、“w”、“W”、“5”等等。
字母
字符
:c
匹配表达式 ([a-zA-Z])。
匹配任何字母字符,如“a”、“A”、“w”、“W”等等。
十进制数字
:d
匹配表达式 ([0-9])。
匹配任何数字,如“4”和“6”。
十六进制数
:h
匹配表达式 ([0-9a-fA-F]+)。
匹配任何十六进制数,如“1A”、“ef”和“007”。
有理数
:n
匹配表达式 (([0-9]+.[0-9]*)|([0-9]*.[0-9]+)|([0-9]+))。
匹配任何有理数,如“2007”、“1.0”和“.9”。
字母字符串
:w
匹配表达式 ([a-zA-Z]+)。
匹配任何仅包含字母字符的字符串。
转义符
\e
Unicode U+001B。
匹配“转义”控制字符。
Bell
\g
Unicode U+0007。
匹配“Bell”控制字符。
Backspace
\h
Unicode U+0008。
匹配“Backspace”控制字符。
制表符
\t
Unicode U+0009。
制表符匹配。
Unicode 字符
\x#### 或 \u####
匹配 Unicode 值给定的字符,其中 #### 是十六进制数。 可以用 ISO 10646 代码点或两个提供代理项对的值的 Unicode 代码点指定基本多语种平面(即一个代理项)外的字符。
\u0065 匹配字符“e”。
下表列出了用于指定 Unicode 字符属性数据库中列出的通用类别的两个字母的缩写词。 您可以在正则表达式字符集中使用这些缩写词。 例如,表达式 [:Nd:Nl:No] 匹配任何类型的数字。
表达式
语法
说明
大写字母
:Lu
匹配任何一个大写字母。例如:
:Luhe匹配“The”但不匹配“the”。
小写字母
:Ll
匹配任何一个小写字母。例如:
:Llhe匹配“the”但不匹配“The”。
词首大写字母
:Lt
匹配将大写字母和小写字母结合的字符,例如,Nj 和 Dz。
修饰符字母
:Lm
匹配字母或标点符号,例如逗号、交叉重音符和双撇号,用于表示对前一字母的修饰。
其他字母
:Lo
匹配其他字母,如哥特体字母 ahsa。
十进制数字
:Nd
匹配十进制数(如 0-9)和它们的双字节等效数。
字母数字
:Nl
匹配字母数字,例如罗马数字和表意数字零。
其他数字
:No
匹配其他数字,如旧斜体数字一。
开始标点符号
:Ps
匹配开始标点符号,例如左方括号和左大括号。
结束标点符号
:Pe
匹配结束标点符号,例如右方括号和右大括号。
左引号
:Pi
匹配左双引号。
右引号
:Pf
匹配单引号和右双引号。
破折号
:Pd
匹配破折号标记。
连接符号
:Pc
匹配下划线标记。
其他标点符号
:Po
匹配 (,)、?、"、!、@、#、%、&、*、\、(:)、(;)、' 和 /。
空白分隔符
:Zs
匹配空白。
行分隔符
:Zl
匹配 Unicode 字符 U+2028。
段落分隔符
:Zp
匹配 Unicode 字符 U+2029。
无间隔标记
:Mn
匹配无间隔标记。
组合标记
:Mc
匹配组合标记。
封闭标记
:Me
匹配封闭标记。
数学符号
:Sm
匹配 +、=、~、|、< 和 >。
货币符号
:Sc
匹配 $ 和其他货币符号。
修饰符号
:Sk
匹配修饰符号,如抑扬音、抑音符号和长音符号。
其他符号
:So
匹配其他符号,如版权符号、段落标记和度数符号。
其他控制
:Cc
匹配类似 TAB 和 NEWLINE 这样的 Unicode 控制字符。
其他格式
:Cf
格式控制字符,例如双向控制字符。
代理项
:Cs
匹配代理项对的一半。
其他私用
:Co
匹配私用区域的任何字符。
其他未分配字符
:Cn
匹配未映射到 Unicode 字符的字符。
除标准 Unicode 字符属性外,还可以指定下列属性作为字符集的一部分。
表达式
语法
说明
Alpha
:Al
匹配任何一个字符。
例如,:Alhe匹配“The”、“then”、“reached”等单词。
数值
:Nu
匹配任何一个数或数字。
标点
:Pu
匹配任何一个标点符号,如 ?、@、' 等等。
空白
:Wh
匹配所有类型的空白,如印刷和表意文字的空白。
双向
:Bi
匹配诸如阿拉伯文和希伯来文这类从右向左书写的字符。
朝鲜文
:Ha
匹配朝鲜文和组合朝鲜文字母。
平假名
:Hi
匹配平假名字符。
片假名
:Ka
匹配片假名字符。
表意文字/汉字/日文汉字
:Id
匹配表意文字字符,如汉字和日文汉字。
用于“查找和替换”的通配符
以下是“表达式生成器”中可用的通配符。
表达式
语法
说明
任何单个字符
?
匹配任何一个字符。
任何一个数字
#
匹配任何一个数字。例如,7# 匹配包括 7 及其后接另一数字的数字,如 71,但不包括 17。
不在字符集中的字符
[! ]
匹配未在字符集中指定的任何一个字符。
转义符
\
按原义匹配反斜杠 (\) 之后的字符。这使您可以查找在通配符表示法中使用的字符,如 * 和 #。
一个或多个字符
*
匹配零个或多个字符。例如,new* 匹配包括“new”的任何文本,如 newfile.txt。
字符集
[ ]
匹配在字符集中指定的任何一个字符。