大家都知道浏览器会把远端过来的html解析成dom模型,有了dom模型,html就变成了xml格式,否则的话就是一堆“杂乱无章”的string,这样的话没人知道是什么鸟东西,js也无法什么各种getElementById,所以当浏览器解析成dom结构后,浏览器才会很方便的根据css各种规则的选择器在dom结构中找到相应的位置,那下一个问题自然就严重了,那就是必须深入的理解dom模型。
一:理解Dom模型
首先我们看下面的代码。
复制代码代码如下:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
</head>
<body>
<p>有名的公司一栏</p>
<hr />
<ul>
<li>百度</li>
<li>新浪</li>
<li>阿里</li>
</ul>
</body>
</html>
用这个代码我们很容易的画出dom树。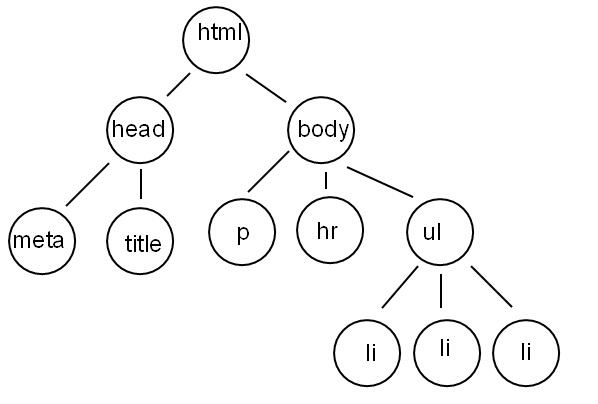
当你看到这个dom树的时候,是不是顿时感到信息量特别大,很简单,因为是树,所以就具有了一些树的特性,比如 “孩子节点”,“父亲节点”,
“兄弟节点”,“第一个左孩子”,“最后一个左孩子”等等,对应着后续我要说的各种情况,一起来看看html被脱了个精光的感觉是不是很爽~~~~
1:孩子节点
找孩子节点,本质上来说分两种,真的只找“孩子节点”,“找到所有孩子(包括子孙)“
<1> 后代选择器
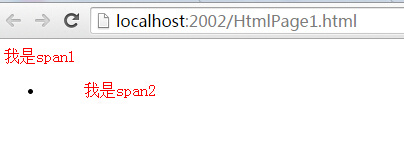
首先看下面的html,我想你可以轻而易举的绘制出dom树了,那下面的问题就是怎么将body中所有的后代span都绘上red。
复制代码代码如下:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
<style type="text/css">
body span {
color: red;
}
</style>
</head>
<body>
<span>我是span1</span>
<ul>
<li>
<ul><span>我是span2</span></ul>
</li>
</ul>
</body>
</html>
2. 孩子选择器
<1> ”>”玩法
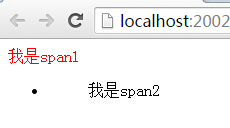
这个也是我说的第二种情况,真的只找孩子节点,在css中也很简单,用 > 号就可以了,是不是很有意思,跟jquery一样的玩法,对不对。
复制代码代码如下:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
<style type="text/css">
body > span {
color: red;
}
</style>
</head>
<body>
<span>我是span1</span>
<ul>
<li>
<ul><span>我是span2</span></ul>
</li>
</ul>
</body>
</html>
<2> ”伪选择器”玩法
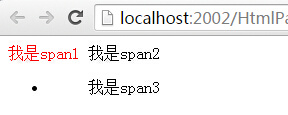
除了上面这种玩法,在css3中还可以使用”伪选择器”玩法,真tmd的强大,下一篇会专门来讲解,这里只介绍一个:nth-child用法,如果
你玩过jquery,一切都不是问题。
复制代码代码如下:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
<style type="text/css">
body > span:nth-child(1) {
color: red;
}
</style>
</head>
<body>
<span>我是span1</span>
<span>我是span2</span>
<ul>
<li>
<ul><span>我是span3</span></ul>
</li>
</ul>
</body>
</html>
3. 兄弟节点
兄弟节点也是很好理解的,在css中用 “+”就可以解决了,可以看到下面我成功将第二个p绘制成了红色。
复制代码代码如下:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
<style type="text/css">
.test + p {
color:red;
}
</style>
</head>
<body>
<p class="test">我是第一个段落</p>
<p>我是第二个段落</p>
</body>
</html> 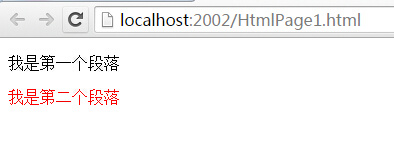
4. 属性选择器
如果玩过jquery,这个属性选择器我想非常清楚,首先看个例子,我想找到name=test的p元素,将其标红。
复制代码代码如下:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
<style type="text/css">
p[name='test'] {
color: red;
}
</style>
<script src="Scripts/jquery-1.10.2.js"></script>
</head>
<body>
<p name="test">我是第一个段落</p>
<p>我是第二个段落</p>
</body>
</html>
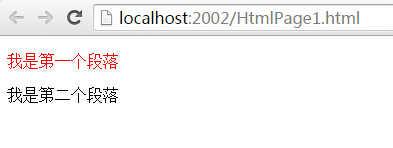
到现在为止,有没有感觉到和jquery的玩法一模一样,而且感觉越来越强烈,已经到了 ”你懂的“ 的境界。
二:css内部机制的猜测
文章开头也说了,浏览器会根据css中定义的”标签”,然后将这个标签的样式应用到dom中指定的”标签“上,就比如说,我在css中定义了一个
p样式,但浏览器怎么就能找到dom中的所有的p元素呢??? 因为闭源的原因,我们无法得知其内部机制,不过在jquery上面,或者我们可以窥知一
二,因为css能展示的选择器用法,在jquery中都能做得到,然后我就很迫不及待的去看看jquery如何提取我的各种选择器写法,下面我们看看源码。
复制代码代码如下:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
<style type="text/css">
p[name='test'] {
color: red;
}
</style>
<script src="Scripts/jquery-1.10.2.js"></script>
<script type="text/javascript">
$(document).ready(function () {
$("p[name='test']").hide();
});
</script>
</head>
<body>
<p name="test">我是第一个段落</p>
<p>我是第二个段落</p>
</body>
</html> 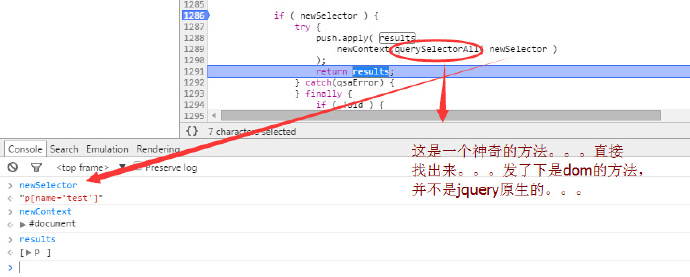
在jquery里面经过一番查找,最后可以看到仅仅是调用了queryselectorAll这个dom的原生方法,你也可以在console中清楚的看到,最后的
results就是找到的p元素,为了验证,我在taobao page下开一个console。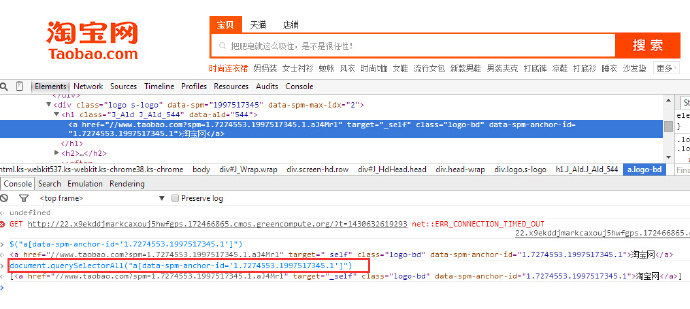
到现在,我大概粗略的猜测,也许至少在chrome浏览器下,浏览器为了找到dom中指定的元素,或许也是调用了queryselectAll方法。。。
好了,大概也就说这么多了,理解dom模型是关键,这样的话才能理解后续浏览器的渲染行为。