有关事务的内容,在前面我们已经不只谈过一次,没办法,这是一个绕不开的话题。你敢说你在开发中不用到它?最起码聚合进行序列化的时候得启动一个本地事务吧。当然了,如果你用的是NoSQL,则另当别论,咱也就别抬那个杠了。你必须承认的事实就是无论现在的NoSQL数据库怎么发展,关系型的数据库仍然是业务系统中的主流,最起码在业务数据存储的时候大部分公司都用到比如MySQL、SQL Server等。我们都知道的一个常识是在非特殊的业务系统中,读操作的频率肯定要大于写的。那么特殊的是什么呢?比如普罗米修斯这种时序数据库,用于日志汇聚的Elasticsearch这种文档型数据库,大多数情况下写的频率要多于查询。回到一般性场景中,NoSQL作为关系型数据库的补充其存在往往在读场景中比例会更重,而只读的话基本上也就不用考虑事务了。
本系列文章学术味道很淡,真要按严谨的学术形式来写那就没完了。讨论一个事务都先从其起源、相关的著作开始,且不说我个人是否有这个能力,您肯定也不喜欢看。所以咱就糙一点,能说明问题即可。首先,我们先对事务做个简单的分类:本地事务、全局事务和分布式事务。下面的内容我会基于这三个分类进行展开并着重说明实践中需要注意的事项。
一、本地事务本地事务几乎每个工程师都去用或至少用过,如果你是Spring的客户相信应该经常使用这样的注解“@Transactional”。没错,当后面的数据库是关系型的时候Spring已经将事务的使用方式进行了极大的简化,程序员只需要关心业务代码即可。这样好也不好,优点不提,不好的方面就是它把事务的执行方式进行了隐藏。我估计很多人都不知道如何使用编码的方式实现一个事务。想当年我写.NET的时候,早期的ADO.NET版本也没有什么如“TransactionScope”这种关键字,都是通过调用SDK手写事务。虽然麻烦了点,但是可以帮助理解书本中所涉及的有关事务的部分,最起码有了较多的感性认识。
不小心透露出了年龄,谁没年轻过啊。回归正文,本地事务讲究四个特性:原子性、一致性、隔离性和持久性,简称ACID。这些其实开发人员也不用特别关心,数据库全帮您实现了。这些特性的实现方式涉及到MVCC、Un Log、Redo Log等底层原理不在咱们这系列文章范围内,需要的话请自行百度之。我们要说是在DDD落地时如何以及何时使用本地事务。看过前面文章的筒子们应该可以把答案脱口而出:聚合的存储。实际使用的时候看您所在项目的技术层级,有条件的话搞一个工作单元,没条件的话直接使用“@Transactional”就挺好。不要人家说什么什么模式好您就不加考虑的使用,那些都是有成本的,尤其是后续的运营成本,工程师写代码的时候爽了真遇到问题就傻眼。总而言之一句话,不论您的聚合的规模是大是小,都必须在持久化的时候使用事务。一个对象的完整性需要在两个方面共同进行保障:一是在业务层面,不论是聚合对象的创建还是在执行完各种动作后,其不变特性要始终进行维护。我们前面讲过的工厂、验证和聚合相关的内容都是为干这个事情的。另一方面自然就是在数据的层次上面,在领域层费了半天的劲您却在数据的层面不进行完整性保障,这不是搞笑呢吗?我本人就见过很多人写代码的时候只图快,不论是面向对象还是面向过程,从不使用事务,相当的自信。
对上面的内容总结一下:1)本地事务适用于关系型数据库;2)聚合的存储与变更场景必须使用事务进行保障;3)事务由数据库自身进行实现,可使用框架提供的方法来简化使用。这里特别提醒一下:使用Spring的工程师请务必注意使用事务的方式,有的时候你在方法上加的注解并不一定会生效,比如下面的代码就是比较典型的错误。具体细节还请找一些文章进行详细了解。
@Service public class OrderService { @Transactional(propagation = Propagation.REQUIRED) public void pay(Long orderId, Money cost) { try { Order order = this.orderRepository.findBy(orderId); this.order.pay(cost); } catch (Exception e) { //(1)手动捕获异常 logger.error(e.getMessage); } } public void pay2(Long orderId, Money cost) { Order order = this.orderRepository.findBy(orderId); if (order == null) { logger.error("no order"); return; } this.pay(order, cost); //(2)公有方法无事务声明 } @Transactional(propagation = Propagation.REQUIRED) private void pay(Order order, Money cost) { order.pay(cost); } }二、全局事务
本地事务一般是一个应用一个数据库,假如出现一个应用多个数据库的情况那就是全局事务该干的事情了。请务必注意一点:理论上的全局事务并没有所谓“一个应用”的限制,理论上可以支持多服务多数据源的情况。之所以这么写是因为咱们只讲现实,理论太复杂扯扯就远了。一般我们说的全局事务其实是特指基于XA协议的“两段式提交”(2 Phase Commit,2PC)以及其增强版本“三段提交(3PC)”。具体的原理已经脱离了我们的讲述范围,就个人的经验来看因为“一个应用多个数据源”在微服务时代已经很少见,再加上全局事务的低效率以及无法应对CAP问题,现在几乎很少用。人们看到了本地事务优秀的ACID特性也期望在分布式环境中可以通过全局事务来实现同样的效果,具体的结论与应用广泛度相信您也看到了,如果兴趣的话可以找一些开源的框架玩玩儿,别轻易在线上系统上使用。真实的项目中我有一个同事曾经偷偷着在项目中用过,但在上线前让我直接打回并强制他使用基于消息队列的最终一致性。
三、分布式事务第三类事务叫作分布式事务。随着微服务架构大行其道,事务也从原本简单的在只需要在数据库层面上的实现功能转移到架构乃至业务层面,种类也变得繁多起来。工程师无脑编程的难度度大大增加,这应该也是进入微服务时代后给人带来的一种负面效果。常用的分布式事务闭着眼都能说上好几种:TCC、Saga、本地消息表、可靠消息队列最终一致性……。反正是一堆堆的技术,十分考验程序员的记性力尤其是打算换工作的时候。虽然说种类不少,可您也别乱用,这些都有适合自己的场景的。
1、分布式事务特性有人认为基于XA协议的2PC也属于一类分布式事务,不过一般并不这么定义。严格的分布式事务是指多个服务同时访问多个数据源时的事务处理机制。既然是分布式你就不能忽略CAP理论所提及的问题。事务讲究ACID,而CAP理论则直接告诉你想在分布式环境下保障ACID根本没戏,直接死了这个心更好。CAP的理论咱们不去证明,其正确性大家都知道的。我想告诉您的是在分布式系统中弱化C而保障AP是一种主流选择,毕竟P是一种客观存在问题你想忽略也不行。假如你当前做的系统是分布式的,您就得在前期仔细琢磨琢磨其面向的目标是业务的可用性还是数据的一致性。一般的电商平台、娱乐网站、甚至是公司内部的一些系统都以AP为目标,你能想像因为网络分区造成了淘宝不能用吗?它一定是先满足用户可使用再说出现数据不一致时怎么进行业务补偿;类似银行、支付平台这种系统则宁愿中断服务也不能出现不一致的情况,不过并不代表说类似支付宝这种平台会中断服务,而是在要求一致性的同时通过使用其它一些手段来保障其可用性,大于99.999%这种程度让用户根本感觉不到系统的中断。基于CP的系统不仅会牺牲其可用性还会有一个比较典型的问题:节点越多可用性越差。Zookeeper是一种典型的基于CP的系统,选主的时候可能会高达几十至上百秒的时间内系统不可用,放到大部分主流电商系统中就是事故了。
弱化C是大部分分布式系统的主流选择,虽然无奈但我们仍有一些方法能保障弱一致性,不过叫“弱一致性”不好听,人们都愿意称之为“最终一致性”。这种方式允许数据存在短暂的不一致性,最后在交付或输出阶段数据可以被及时修正过来。如果ACID的事务是“刚性事务”,那最终一致性的事务就被称之为“柔性事务”。由于CAP问题,针对分布式事务的特性有人给总结出三点:基本可用(Basically Available)、柔性可用(Soft State)和最终一致性(Eventual Consistency),三点的含义您可在网络上查找相关的文章。把三点的首字母取来是“BASE”,在英文中有“碱”的意思; 而ACID在英文中是“酸”的意思。所以你在设计业务系统的时候要在酸碱中去寻找平衡,别不论什么情况都追求ACID。客户和需求他们不懂技术,开发人员要主动思考到底在落地时使用什么机制来实现事务,这东西搞不好就会有巨大的性能问题。
2、常用分布式事务上一段我们列举了几个常被使用的分布式事务,但他们要怎么用以及适用什么场景呢?既然讲到这儿了我们就大概说明一下,万一平常用到了呢?DDD中最常被使用的事务是基于领域事件的Saga式事务,不过不代表您只能使用它,选择多一点才有利于我们日常的设计。
2.1 TCC(Try-Confirm-Cancel)熟悉2PC的您应该大概知道其工作原理,简单来说就是每一个事务参与者在执行完事务后并不提交,死等着事务管理器下令才能做提交操作,在此期间资源只能进行锁定。这种机制放在高并发的系统中其性能之低您都不用看什么数据报告,用脚指头都能想出来。TCC的概念其很简单,我们不进行资源的锁定。现在的问题不就是当某个事务出现问题后无法把其它已经完成的事务进行回滚吗?那我们就在业务代码的层次让每一个事务参与者都实现一些接口。Try:让事务参与者尝试执行业务,一般使用数据库的事务,执行完成后就提交不做任何等待与锁定。不过由于整个业务并没有完成,所以在“Try”的阶段一般会把数据变成一种中间状态。比如在电商购物的业务中,常见的操作是下单后对库存进行扣减。在使用了TCC后,库存服务的“Try”操作就把库存数减1,冻结的库存数加1,使用“冻结”作为中间态而不是直接对库存进行扣减。“Confirm”:让事务参与者执行业务确认,上例中就是把冻结的库存-1。“Cancel”:当某个事务参与者的“Try”失败后执行回滚操作,上例中就是库存数加1,冻结的库数减1。当然了,原理是这样的,实际在使用TCC的时候有很多的限制,比如“Confirm”操作不能失败,必须支持幂等操作等。
通过对于TCC的解释,相信您能想像得到这个机制其实真的挺麻烦的,各种的协调不说对业务的入侵也比较强(我认为是分布式事务中入侵性最强的)。所以您最好别自己写代码开搞,这里面需要考虑很多的事情,最起码三个场景的来回调度就够您喝一壶了更别提什么比“空回滚”、“悬挂”等问题。这个时代要求快速加载需求就不能总是从头造轮子了。再说了,这么有名的模式一定有现成的框架可用比如Seata,大厂出品质量还是可以的,但在系统的架构上你需要额外部署一两套Seata服务才能成事; 写代码的时候你只需要找个地方把业务进行统一的组织就行了,所有的调度以及上述提及的各类问题都有Seata这个碎催来解决。以上面的案例来说,您只要在比如订单服务的某个方法中对“订单下单的T”和“库存减一的T”进行调用而不用操心另外两个“C”的执行,完全是自动的。这里的“某个方法”有个名称:全局事务发起方法。
既然谈到了Seata框架,里面还有一种AT模式,具体原理您自行网上查找 。这东西用起来其实也非常的简单,不过他的事务回滚是基于数据库的,通过拦截SQL生成Undo Log和Redo Log,如果某事务参与者用的是NoSQL,那这种方式就不适合了。而TCC是基于用户逻辑进行事务的提交与回滚,就相对要灵活很多,完全可以针对非关系型数据库做支撑。还是那句话,强大也是有代价的,TCC对业务的入侵比较重,你得仔细考虑TCC中的每个方法,代码写得多测试也麻烦,不像AT模式加个注解就可以放飞自我了。DDD落地的时候使用AT或TCC其实都行,前提是您已经知道了两种模式在技术上的主要区别。另外,请务必注意在使用DDD的时候把这些框架的应该点放在应用服务层,包括“TCC”各方法的实现。
2.2 本地消息表通过翻阅网上的各类资料都谈到了“本地消息表”的创造者为eBay的Dan Pritchett。但个人对此保留意见,一是本方案其实并无任何的技术难度与其说是Dan Pritchett首创不如说是一种实践。二是通过不断重试的方式促进一个事务的完成在计算机领域中早已经是一个被广泛使用的模式,有个专门的名称——“最大努力交付”。
假设有如下图的一个业务:应用A在完成本地事务后通过消息的方式通知应用B进行自己的本地事务。观察一下步骤1和2,很可能出现两类情况:1)按图的顺序操作,本地事务提交成功但写入消息队列失败造成应用B无法得到通知;2)先写入消息队列再执行本地事务,把两步骤的顺序交换一下,虽然能保证消息被发送至队列但有可能本地事务失败。应用B端收到了一个错误消息,最为致命的是它还无法判断消息是错误的。
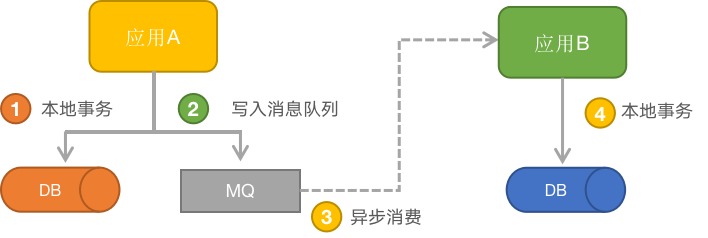
本地消息表的思想是:你不就是怕本地事务和发送消息无法同时成功吗?那我们就在写本地的事务的时候把消息同业务数据放到同一个事务中并一起存到数据库中。反正只要本地的事务可以提交成功,那么基于ACID中的“D”理论,消息也会被持久化。此时的消息有一个状态是“未发送”,我们可以在生产者侧开启一个后台线程把“未发送”状态的数据发送到MQ中。这种机制能保证消息在生产端不会丢失,而消费者可以在消费成功后再通知生产者更新一下消息的状态为“已处理”。假如应用A与消息队列失联,发送消息必然不会成功,但因为我们的后端任务是不间断的进行发送重试的,所以只要消息队列状态恢复自然可把消息投递到队列中;假如应用B处理后未能通知到应用A更新消息的状态,那应用A肯定还会把同一个消息投递给它的。
通过上面的流程,你应该可以看到在实践中使用本地消息表需要考虑两个问题:1)应用A的后台线程在进行消息发送重试的时候需要加一个限制,不能无限制的重发以减少应用的负担;2)应用B也就是消费者需要保证消息的幂等。
实践中使用本地消息表的场景其实已经不多,具体原因有两个:1)开发进度过于紧张,没人考虑消息丢的问题,先上线再说,谁家的系统不得有点BUG;2)很多的消息队列中间件已经提供了类似的机制比如RockMQ的事务消息,把本地消息表的这种机制作到了MQ中,工程师只要提供相应的回调接口MQ就能实现上面提到的“后台线程”所达到的效果。仍然以上图为例,假如应用A在步骤1和2执行成功后直接宕掉,RockMQ强大到可以对应用A的另外实例进行回调以检查事务是否完成。另外一个被广泛使用的消息队列RabbitMQ也提供了类似的“Confirm”机制,通过使用异步回调接口的方式给工程师提供发送重试机制,以可以将未成功发送或路由的消息写入到数据库或日志中,为实现人工干预提供了切入点。
针对上述的案例有一个问题我们要考虑一下:假如步骤1执行成功后突然宕机会出现什么结果?也许消息日志是解决此问题的一人方向。
2.3 Saga1987年普林斯顿大学的Hector Garcia-Molina和Kenneth Salem在ACM发表了一篇署名为“SAGAS”的论文首次提出了这个概念,旨在解决“长时间事务”效率问题。早期Saga主要是为了解决大事务长时间锁数据库的问题,直到近几年才发展成作为分布式环境中的事务来使用。1987年啊,30几年的东西也能迸发出新生,那个时候中国有几台PC?看来还是思想才能经得起时间的考验。
Saga的原理其实很简单,把一个大的事务分成若干的小事务,每个事务都是一种原子行为,因此并不会长久的锁定数据库;同时,还需要为每个小事务提供对应的补偿行为以用于处理回滚操作。把Saga比喻成走路更形象一点,比如您想从A地走到B地一段距离10米的路程,如果中途遇到障碍就退回原点。走的时候一步肯定没戏所以就分成10步走,这10步就是10个小事务。当走了5步遇到障碍后,我再一步一步的后退5步回来,这里的后退5步就是补偿行为。这里需要注意一点,我们前进虽然不能把步子跨大了但回退则可以是一步能搞定的事情,具体要看业务的处理策略。
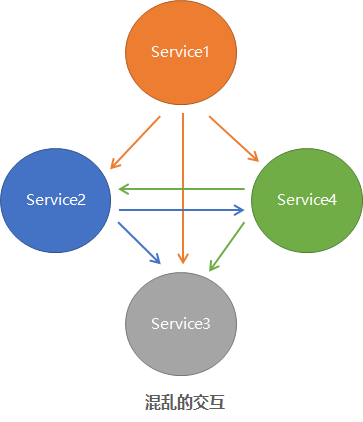
通过前面的TCC详解我们可以看到案例中引入的所谓“冻结”状态其实是一种资源预留的操作,但资源预留的操作并不是仅使用“冻结”这种模式,这个读者需要明白。回到正题,与TCC相比Saga则不需要提前预留什么资源,对应的补偿操作也就简单得多。不过实际使用的时候也需要考虑很多的元素比如Saga的故障恢复、事务的编排。此外,你还要重点考虑隔离性问题,否则很容易引入难以排查的错误;另外,Saga其实并不是仅仅是分布式事务那么简单,您可以想像这样一个场景:一个业务需要四个服务共同协调才能完成,可能的调用关系也许如下图一样的混乱。这种模式很明显的问题是服务间相互依赖严重及业务调度链路复杂。这还仅是4个服务,涉及到8个、10个,相信没人愿意维护这种复杂的调用关系,尽管使用了DDD方式进行了系统落地但却没有在其中获益。
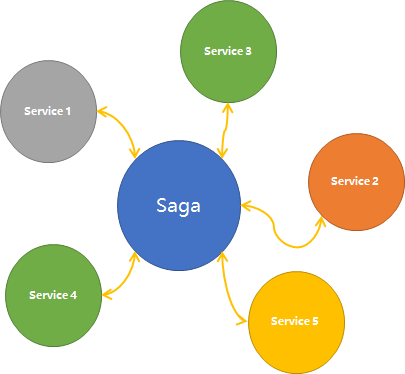
 而在引入Saga后类似的调用关系则会变成下面这样,各服务间所产生的依赖将不复存在而转而依赖于Saga,它所带来的优势一目了然无需过多解释。另外呢,我们使用上图所示的业务调试方式,肯定需要有一个全局事务发起方法用于编写调度代码。在采用了Saga后我们将可以责任进行转移,让它承担事务调度者也称之为业务指挥官的角色,来协调各事务参与者执行业务事务或回滚操作,到了下一章我们手写一个Saga的基础类库,您可以见识一下它在事务之外所带来的其它收益。
而在引入Saga后类似的调用关系则会变成下面这样,各服务间所产生的依赖将不复存在而转而依赖于Saga,它所带来的优势一目了然无需过多解释。另外呢,我们使用上图所示的业务调试方式,肯定需要有一个全局事务发起方法用于编写调度代码。在采用了Saga后我们将可以责任进行转移,让它承担事务调度者也称之为业务指挥官的角色,来协调各事务参与者执行业务事务或回滚操作,到了下一章我们手写一个Saga的基础类库,您可以见识一下它在事务之外所带来的其它收益。
纵然Saga有千分的好,其所带来的负作用也不能小觑:1)灵活性低,你需要详细考虑每一个正向和反向的处理步骤。此外,一旦流程固化其后续的调整就会比较麻烦,至少需要把整个流程进行一次完整的走查。因为一般情况下我们可能会使用一些状态信息来决策流程的走向,而当业务有了变化我们需要加入新的状态结点的时候,可能需要调整整个流程。此外,通常情况下我们会借助于消息队列来串联各子事务,如果消息结构产生变化那可能需要调整多个事务参与者;2)成本高,设计成Seata中那种独立的Saga管理器模式固然很好,可是需要花费大力气并投入很多的精力和成本,有的时候是得不偿失的。所以在实践中要不您就直接使用现成的Saga框架比如:Seata、ServiceComb Saga、Axon等;要不您就和我一样手写一个简单的,以较小的投入换取最大的收益。千万别把目标定得太大,非得和某某框架对标,那些框架都是团队产物而您一个人是无法与他们抗衡的;3)隔离性与原子性差,这两上属性基本上可以不考虑了,您又想处理长事务又想保障ACID,世界上没那么好的事儿。事务的隔离性必须通过业务状态判定或业务规则来限制,Saga框架没有提供解决方案;原子性几乎也不用考虑,可以想象得到在某个事务的执行过程中您是可以读取到部分成功的数据的。综上所述,工程师在使用Saga的时候需要考虑上述的各类问题才能减少运营时的问题。
总结本章重点说明了事务的种类以及我们经常使用的场景,技术性很强看似与DDD或领域模型关系不大。但你不能孤立的看待DDD,它仅仅是系统建设过程中的一个部分,优秀的系统是方方面面都优秀才行,从战略设计到系统建设再到投入运营。事务、分布式锁等技术性问题是在DDD实践中不可或缺的,请绷紧脑子中的那个弦继续我们的学习之旅。下一章我们手写一个Saga,敬请期待。