环境准备:
hadoop版本:2.6.5
spark版本:2.3.0
hive版本:1.2.2
master主机:192.168.100.201
slave1主机:192.168.100.201
pom.xml依赖如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.spark</groupId>
<artifactId>spark_practice</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<spark.core.version>2.3.0</spark.core.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.core.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.core.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
</project>
注意:一定要将hive-site.xml配置文件放到工程resources目录下
hive-site.xml配置如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" rel="external nofollow" ?> <configuration> <!-- hive元数据服务url --> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.100.201:9083</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <property> <name>hive.zookeeper.quorum</name> <value>node01,node02,node03</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node01,node02,node03</value> </property> <!-- hive在hdfs上的存储路径 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!-- 集群hdfs访问url --> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.100.201:9000</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>datanucleus.autoCreateSchema</name> <value>true</value> </property> <property> <name>datanucleus.autoStartMechanism</name> <value>checked</value> </property> </configuration>
主类代码:
import org.apache.spark.sql.SparkSession
object SparksqlTest2 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder
.master("local[*]")
.appName("Java Spark Hive Example")
.enableHiveSupport
.getOrCreate
spark.sql("show databases").show()
spark.sql("show tables").show()
spark.sql("select * from person").show()
spark.stop()
}
}
前提:数据库访问的是default,表person中有三条数据。
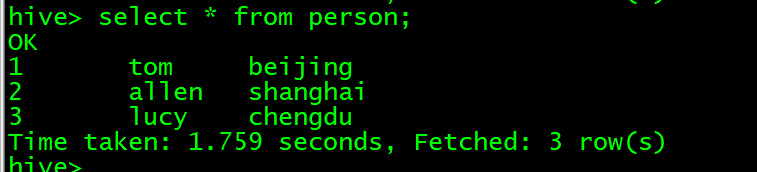
测试前先确保hadoop集群正常启动,然后需要启动hive的metastore服务。
./bin/hive --service metastore
运行,结果如下:
如果报错:
Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.io.IOException: (null) entry in command string: null chmod 0700 C:\Users\dell\AppData\Local\Temp\c530fb25-b267-4dd2-b24d-741727a6fbf3_resources;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:114)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:39)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog$lzycompute(HiveSessionStateBuilder.scala:54)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:52)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anon$1.<init>(HiveSessionStateBuilder.scala:69)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.analyzer(HiveSessionStateBuilder.scala:69)
at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.SessionState.analyzer$lzycompute(SessionState.scala:79)
at org.apache.spark.sql.internal.SessionState.analyzer(SessionState.scala:79)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:74)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:638)
at com.tongfang.learn.spark.hive.HiveTest.main(HiveTest.java:15)
解决:
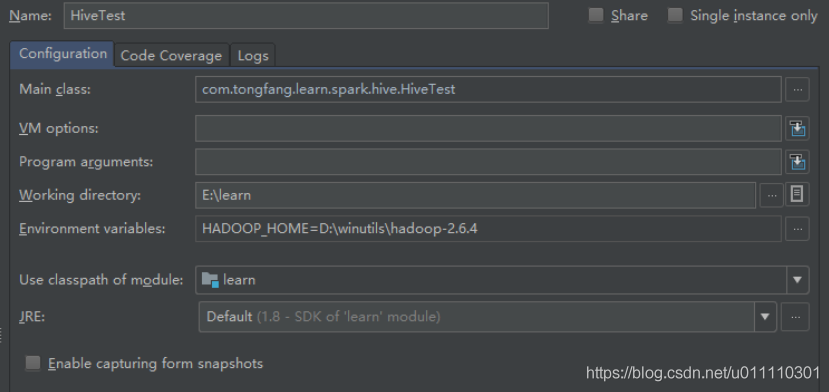
1.下载hadoop windows binary包,链接:https://github.com/steveloughran/winutils
2.在启动类的运行参数中设置环境变量,HADOOP_HOME=D:\winutils\hadoop-2.6.4,后面是hadoop windows 二进制包的目录。
到此这篇关于SparkSQL读取hive数据本地idea运行的方法详解的文章就介绍到这了,更多相关SparkSQL读取hive数据本地idea运行内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!