文章翻译自Scylla官方文档:https://www.scylladb.com/2019/08/20/best-practices-for-data-modeling/
转载请注明出处:https://www.cnblogs.com/morningli/p/16202131.html
在我们最新的夏季技术讲座系列网络研讨会上,ScyllaDB 现场工程师 Juliana Oliveira 指导虚拟与会者了解了一系列有关 ScyllaDB 数据建模的最佳实践。她将演讲分为三个关键领域:
- 数据建模在 ScyllaDB 中的工作原理
- 数据存储如何工作以及如何压缩数据
- 如何查找和使用(或围绕)大型分区
Juliana 强调了掌握这些基础知识的重要性。“因为一旦我们有了正确的数据存储和分布概念模型,接下来的事情就会变得自然。”
对于那些具有 SQL 背景的人,Juliana 首先描述了该著名数据模型与ScyllaDB 使用的Cassandra 查询语言 (CQL)之间的主要区别。
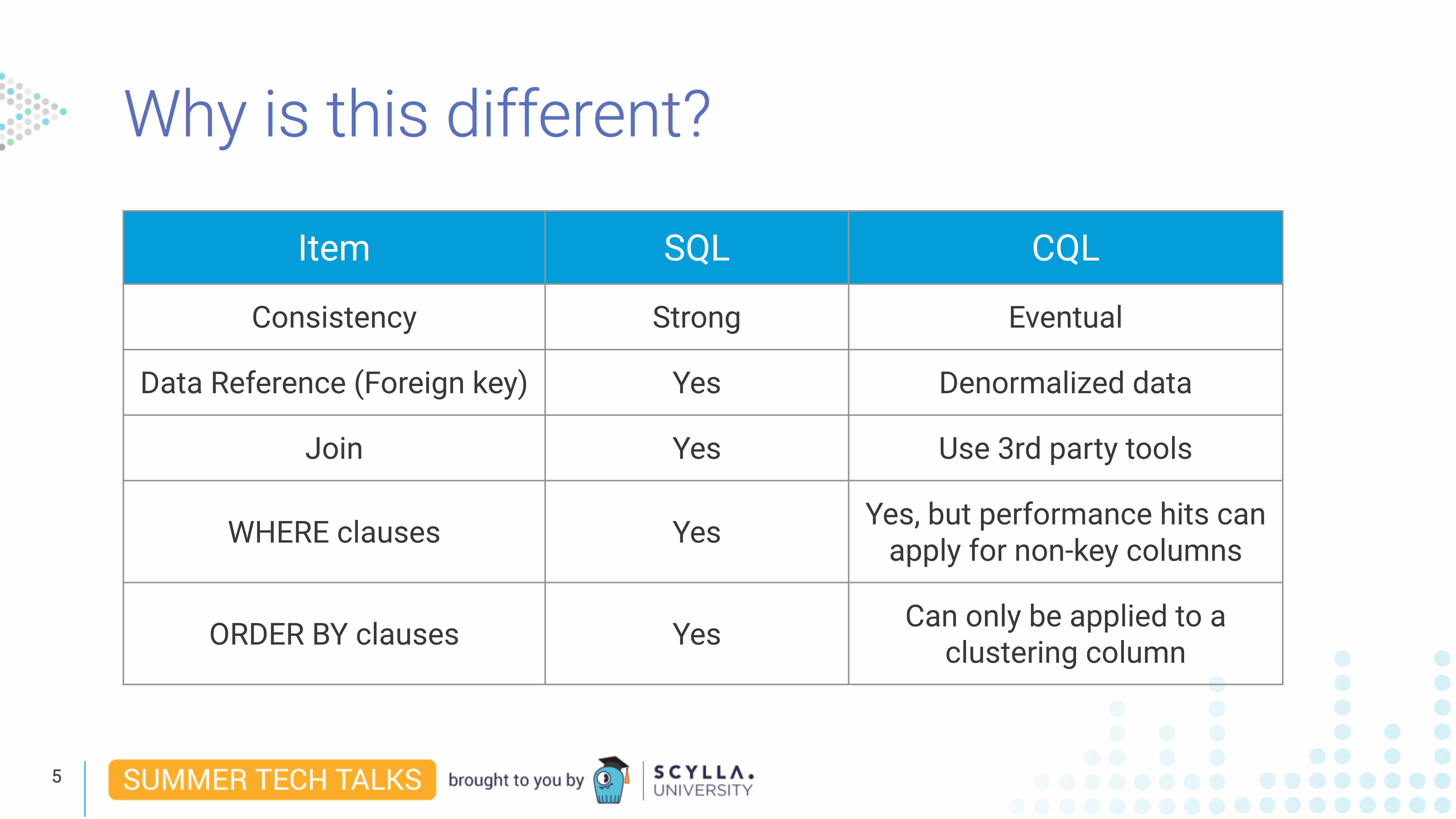
虽然这两种查询语言之间存在相似之处,但 Juliana 指出“SQL 数据建模不能完美地应用于 ScyllaDB。” 您没有相同的关系模型来避免数据重复。相反,在 ScyllaDB 中,所有数据都是非规范化的。您还希望根据您希望执行的查询来组织数据。例如,您希望将数据均匀地分布在集群中的每个节点上,以便每个节点都拥有大致相同数量的数据。还应该进行平衡以确保您没有“热分区”(经常访问的数据)并且数据均匀分布在集群的节点上。因此,确定您的分区键至关重要。
分区和行:兽医示例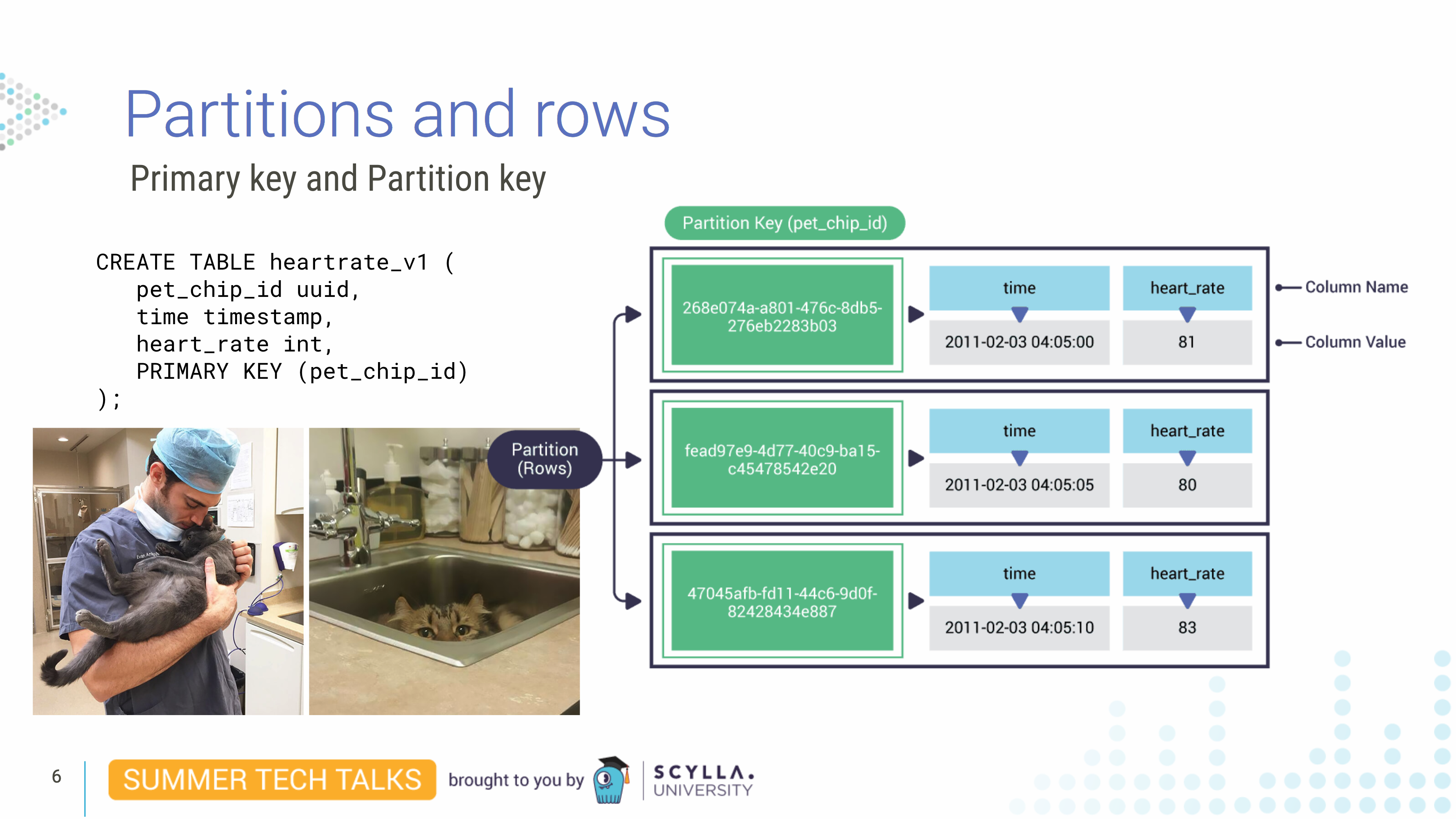
想象一下,您在一家兽医诊所工作。我们创建一个名为 的表heartrate_v1。在这个表中,我们有一个pet_chip_id列、一个时间列和一个heart_rate列。我们将 设置PRIMARY KEY为pet_chip_id。该表负责保存我们宠物患者的数据。想象一下,我们每五秒钟就会得到一个新的读数。在这种情况下,由于pet_chip_id是我们的主键,是 CQL 中行的唯一标识符,因此它是分区的唯一标识符。
分区是节点上数据的子集——排序行的集合,由唯一的主键或分区键标识。它跨节点复制。
在这种情况下,我们在主键字段中只有一列 - pet_chip_id. 但是由于我们每五秒读取一次数据,并且主键必须是唯一的,这当然不是理想的解决方案,因为如果读取是相同pet_chip_id的,它将覆盖现有记录。
现在我们发现由于我们的数据模型,我们不断地覆盖我们的数据,也许我们应该在主键中添加一个新的第二列。如果我们将time第二列添加到主键字段,这将用作集群键。集群键的作用是对分区内的每一行进行物理排序。
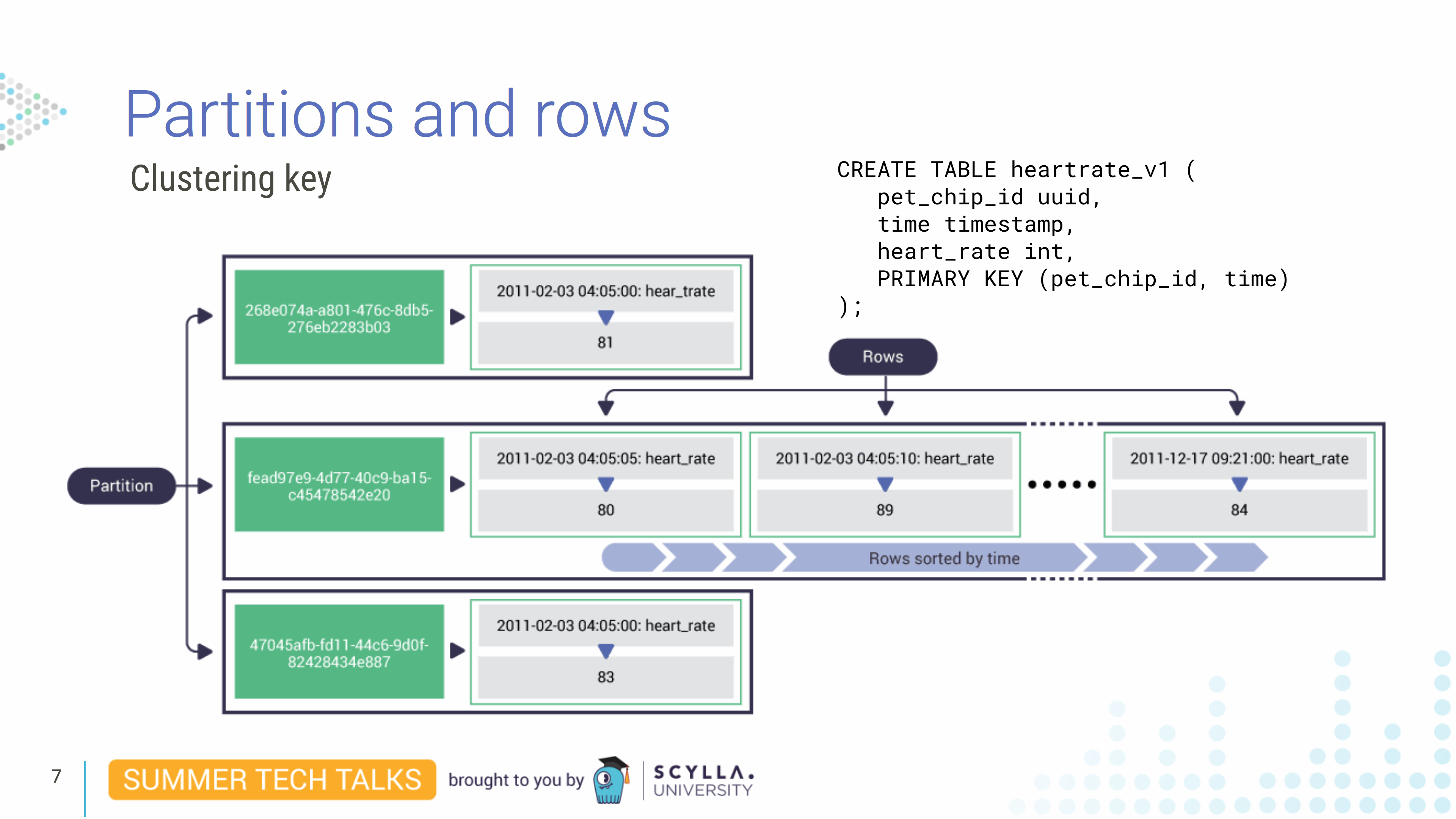
正如我们稍后将看到的,分区键被散列并分布在集群周围。这意味着查询总是需要用相等来指定分区键——因为散列会打乱它的自然排序。但是因为集群键没有散列,所以行为是不同的。
编写查询时,需要包含分区键,但可能会省略集群键,在这种情况下,查询会作用于整个分区,另外,由于集群键是在分区内排序的,因此您还可以运行等式查询和聚类键的不等式。
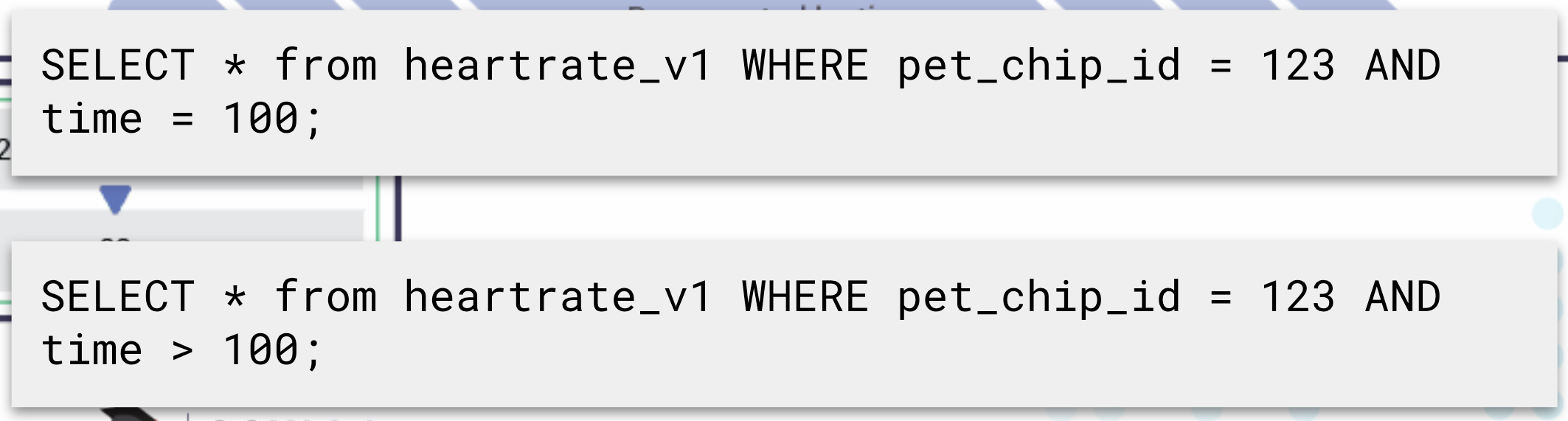
但是,如果您有两个聚类键,例如 byheart_trate和time,您将按聚类键顺序排序。首先它将按 排序time,然后按 排序heart_rate。我们不能编写指定心率而不是时间的查询,因为数据在物理上是按聚类键顺序排列的。所以这个查询会失败,因为它没有指定time; 它只指定heart_rate:

因此,知道集群键是如何工作的,并且知道我们heart_rate每五秒写入一次,很容易想象分区键会变得非常大。由于宠物可以在数周内受到监控,我们可以在同一个分区中有数千行。(例如,每 5 秒对宠物进行一周采样将导致单个分区中有 120,960 行。)拥有这么大的分区可能会导致性能问题,尤其是如果您不知道正在发生这种情况。
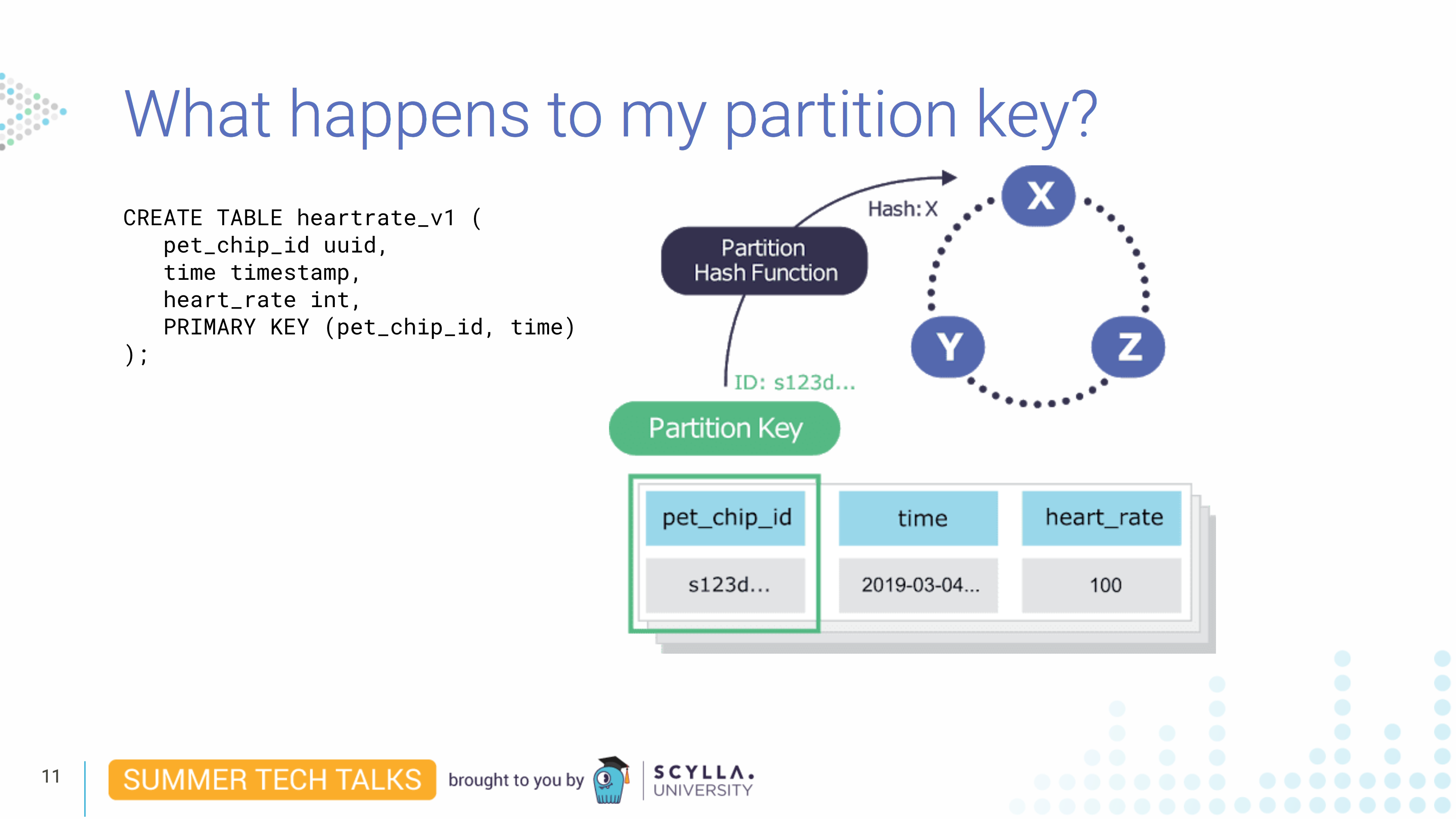
它去哪儿了?分区键,即pet_chip_id,将由我们的散列函数进行散列 - 我们使用murmur3,与 Cassandra 相同 - 生成 64 位散列。然后我们将为负责存储键的每个节点分配一个分区键范围。
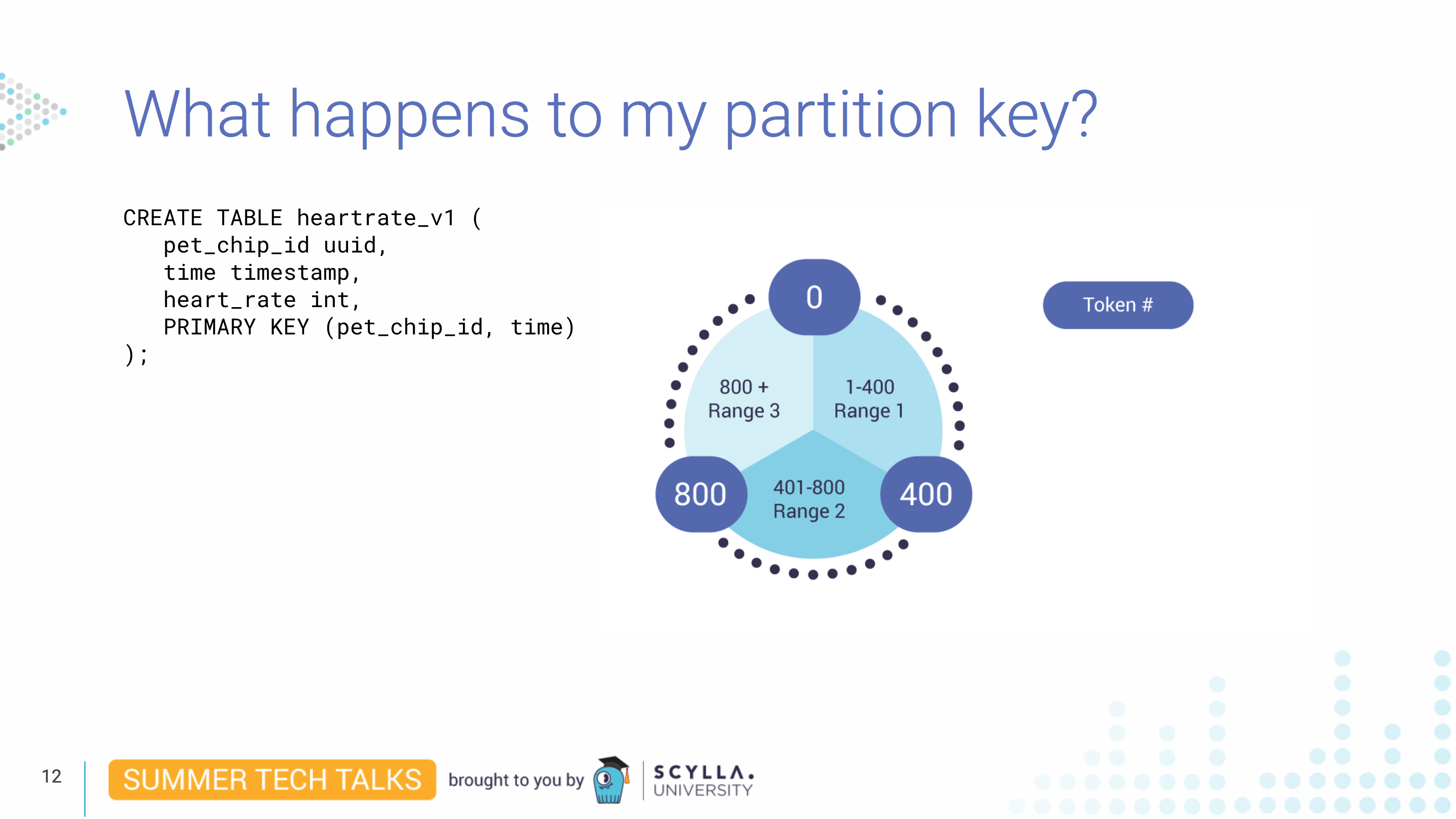
在此示例中,您有一个三节点集群,该集群放置的令牌范围为 0 到 1200。如果复制因子为 2,则每个节点都拥有两个范围。实际上发生的是 ScyllaDB 将数据拆分为 vNode。如果没有 vNode,并且复制因子为 2,则环将如下所示,其中每个节点将是一个分区键范围的主节点,并且将是第二个分区键范围的辅助节点:

使用 vNodes,这是 ScyllaDB 拆分数据的方式,其中每个物理节点将是四个范围的主要复制和其他四个范围的辅助复制:
 拥有 vNode 尤其可以提高集群重建流式传输时间。我们的分区键
拥有 vNode 尤其可以提高集群重建流式传输时间。我们的分区键 pet_chip_id将驻留在这些 vNode 范围之一(及其复制副本)中。由于散列函数,ScyllaDB 知道它在哪里。
存储
接下来 Juliana 转向研究 ScyllaDB 中的底层存储系统,因为这会影响数据建模。首先,重要的是要知道数据首先写入内存结构,即 memtable。而且,随着时间的推移,一些 memtable 更改将被刷新到名为 SSTable 的不可变(不更改)文件中的持久存储中。所以想象一下,在第一个 SSTable 1 中,我们写了一些“A = 1”的数据。

随着时间的推移,更多的数据被刷新到额外的 SSTables。想象一下,我们最终删除了“A”,并且在 memtable 刷新中,这个更新被写入了 SSTable 3。知道 SSTable 是不可变的,它会发生什么?我们不能从现有的 SSTable 中删除“A”。所以在这种情况下,“A”最终会在下一次压缩中被删除。

压缩是读取一组 SSTable 并将它们的数据组合以写入仅包含“实时”(当前)数据的新 SSTable 的操作。这是有效的,因为当 SSTable 被排序时,我们只读取一次,并且当从多个 SSTable(1+2+3)压缩数据时,会检查它们的最新值。因此,例如,“A”的最新值是“删除它”,它会从生成的 SSTable 1+2+3 压缩中删除。这就是为什么当我们删除数据时,在下一次压缩之前我们不会看到它反映在磁盘空间上。
有不同的策略,每种策略都与何时以及如何运行压缩的不同算法相关联。让我们在这里列出主要的:
- 默认情况下,ScyllaDB 使用size-tiered compaction strategy (STCS),非常高效。它将 SSTable 压缩到类似大小的桶中,因此所有 SSTable 的大小大致相同。但不利的一面是,如果您的 SSTable 太大,我们需要在写入之前读取,这可能会占用大量磁盘空间。(此压缩策略需要大约 50% 的可用磁盘空间来写出大型压缩。另请参阅此博客。)
- 时间窗口压缩策略(TWCS)也使用大小分层压缩;但有时间窗口桶。它设计用于时间序列数据。
- 分级压缩策略 (LCS)不需要一半的磁盘空间可用,并通过具有多个级别来分隔数据。然而,这需要更多的写入 I/O,因此对于写入繁重的工作负载来说效率很低。

大小分层压缩策略是 ScyllaDB 使用的默认策略,当系统有足够的大小相似的 SSTables 时触发。正如您在此图中看到的那样,它具有磁盘使用高峰。它们发生在 ScyllaDB 压缩所有 SSTable 时。例如,当我们认为记录占用了太多空间并且我们想通过运行 nodetool compact 来摆脱它们时,它会压缩所有 SSTables。因此,在我们完成输出 SSTable 的写入之前,无法删除输入 SSTable。在压缩结束之前,我们在磁盘上有两次数据,在输入 SSTables 和(压缩的)输出 SSTable 中。我们暂时需要磁盘空间是数据库中可用数据的两倍。因此,要使这种压缩策略起作用,我们需要磁盘始终处于半满状态。

在这种策略,Leveled Compaction Strategy (LCS) 中,大小均匀的 SSTable 被划分为级别。每次压缩都会生成一个小的 SSTable,它最终会进入下一个级别。由于每个小的 SSTable 没有重叠的键范围,它们可以并行压缩。而且因为它们很小,而且永远不必编写一个巨大的 SSTable,所以你不会遇到与大小分层压缩相同的空间问题。
该策略的缺点是因为我们需要在每次 SSTable 更改级别时重写相同的数据,这可能是 I/O 密集型的。
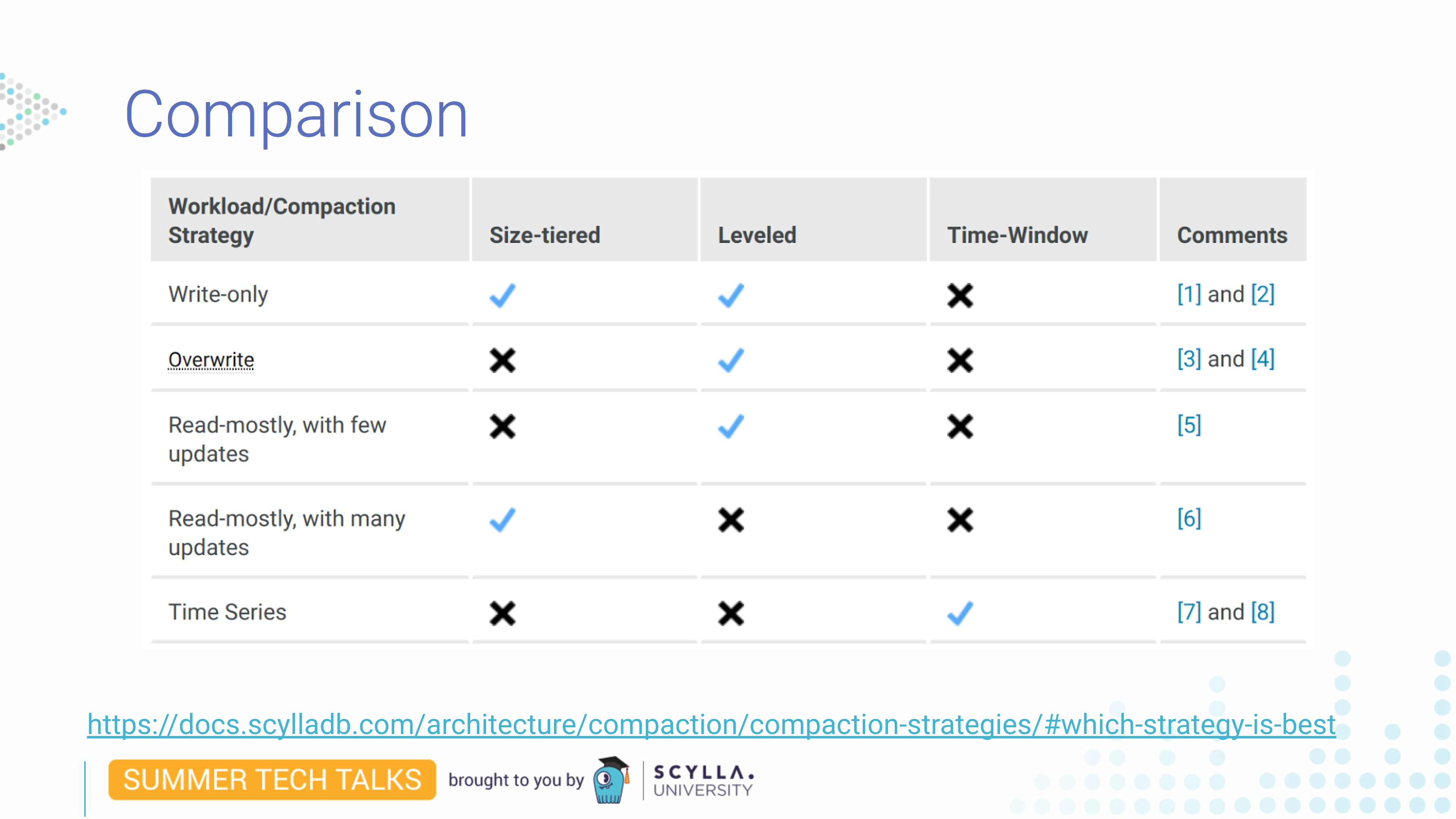
在这里我们可以看到各有各的优点。只写工作负载的大小分层和分级工作,但一个将占用两倍的磁盘空间,另一个将占用两倍的写入操作。Leveled 最适合覆盖数据,因为它不会像大小分层一样保留所有数据。对于许多更新,水平可能是一个问题,因为它也需要许多写入。
有很多事情需要考虑。如果您对最佳策略有任何疑问,您应该查看我们的文档。
大分区和热分区这些是什么?正如我们在讨论集群键时所看到的,我们可以在同一分区中的集群键下拥有大量值。导致分区中的行数惊人。这样的分区称为大分区,这是一个问题,因为当您读取它时,查询可能会更慢,因为 ScyllaDB 不索引分区内的行,并且还因为分区内的查询无法并行化。
这可能会变得更糟。您可能会遇到大分区问题和热分区问题。这是当其中一个分区比其他分区更容易访问时。这种热分区问题通常发生在数据分布不均时。例如,在宠物诊所,我们有一只总是生病的特定宠物。所以我们为这个宠物生成并标记数据。

我们有办法避免这种情况。首先,您需要了解您的数据及其行为方式。其次,通过向分区键添加更多列来增加粒度是很常见的。在这个例子中,我们有一个心率表,我们在主键中添加了日期。所以我们的分区不仅是 by pet_chip_id也是 by date。这使得分区更小,更易于管理。

为了跟踪大分区,我们保留了一个名为system.large_partitions. 每次将一个大分区写入磁盘时——这意味着,在它被从 memtable 中刷新之后——我们都会在这个表中添加一个条目。可以检测随着时间的推移生成了多少大分区,以便了解数据的行为方式并根据需要改进数据分布。请注意,此数据仅在数据写入磁盘后可用,之前不可用。

大分区检测阈值可以在scylla.yaml文件中用compaction_large_partion_warning_threshold_mb参数设置,默认为100M。您可以使用与您的用例相关的任何内容。每个大于此阈值的分区都将在大分区表中报告,并在日志中写入警告,因此您还可以在日志系统上设置警报。