首先说一句,如果比较忙顺路点进来的,可以先收藏,有时间或用到了再看也行;
我相信很多人会有一个困惑,这个困惑和我之前一样,就是线程池这个玩意儿,感觉很高大上,用起来很fashion,本地环境测试环境调试毫无问题,但是一上线就出问题。
然后百度一大堆资料,发现都在讲线程池要自定义,以及各种配置参数,看完之后点了点头原来如此,果断配置,结果线上还是出问题。
归根究底,还是对自定义线程池的配置参数不了解造成的,本篇就通过一个很简单的案例给大家梳理清楚线程池的配置,以及线上环境到底该如何配置。
二、案例 1、编写案例
自定义一个线程池,并加上初始配置。
核心线程数10,最大线程数50,队列大小200,自定义线程池名称前缀为my-executor-,以及线程池拒绝策略为AbortPolicy,也是默认策略,表示直接放弃任务。
package com.example.executor.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
import java.util.concurrent.ThreadPoolExecutor;
@Configuration
@EnableAsync
@EnableScheduling
@Slf4j
public class AsyncConfiguration {
/**
* 自定义线程池
*/
@Bean(name = "myExecutor")
public Executor getNetHospitalMsgAsyncExecutor() {
log.info("Creating myExecutor Async Task Executor");
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(200);
executor.setThreadNamePrefix("my-executor-");
// 拒绝策略:直接拒绝抛出异常
executor.setRejectedExecutionHandler(
new ThreadPoolExecutor.AbortPolicy());
return executor;
}
}
接下来,我们写一个异步服务,直接使用这个自定义线程池,并且模拟一个耗时5秒的发消息业务。
package com.example.executor.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
/**
* <p>
* 异步服务
* </p>
*
* @author 福隆苑居士,公众号:【Java分享客栈】
* @since 2022/4/30 11:41
*/
@Service
@Slf4j
public class AsyncService {
/**
* 模拟耗时的发消息业务
*/
@Async("myExecutor")
public void sendMsg() throws InterruptedException {
log.info("[AsyncService][sendMsg]>>>> 发消息....");
TimeUnit.SECONDS.sleep(5);
}
}
然后,我们写一个TestService,使用Hutools自带的并发工具来调用上面的发消息服务,并发数设置为200,也就是同时开启200个线程来执行业务。
package com.example.executor.service;
import cn.hutool.core.thread.ConcurrencyTester;
import cn.hutool.core.thread.ThreadUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
/**
* <p>
* 测试服务
* </p>
*
* @author 福隆苑居士,公众号:【Java分享客栈】
* @since 2022/4/30 11:45
*/
@Service
@Slf4j
public class TestService {
private final AsyncService asyncService;
public TestService(AsyncService asyncService) {
this.asyncService = asyncService;
}
/**
* 模拟并发
*/
public void test() {
ConcurrencyTester tester = ThreadUtil.concurrencyTest(200, () -> {
// 测试的逻辑内容
try {
asyncService.sendMsg();
} catch (InterruptedException e) {
log.error("[TestService][test]>>>> 发生异常: ", e);
}
});
// 获取总的执行时间,单位毫秒
log.info("总耗时:{}", tester.getInterval() + " ms");
}
}
最后,写一个测试接口。
package com.example.executor.controller;
import com.example.executor.service.TestService;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* <p>
* 测试接口
* </p>
*
* @author 福隆苑居士,公众号:【Java分享客栈】
* @since 2022/4/30 11:43
*/
@RestController
@RequestMapping("/api")
public class TestController {
private final TestService testService;
public TestController(TestService testService) {
this.testService = testService;
}
@GetMapping("/test")
public ResponseEntity<Void> test() {
testService.test();
return ResponseEntity.ok().build();
}
}
2、执行顺序
案例写完了,我们就要开始进行调用线程池的测试了,但在此之前,首先给大家讲明白自定义线程池的配置在运行过程中到底是怎么执行的,是个什么顺序,这个搞明白,后面调整参数就不会困惑了。
核心线程数(CorePoolSize) ---> (若全部被占用) ---> 放入队列(QueueCapacity) ---> (若全部被占用) ---> 根据最大线程数(MaxPoolSize)创建新线程 ---> (若超过最大线程数) ---> 开始执行拒绝策略(RejectedExecutionHandler)
连看三遍,然后就会了。
3、核心线程数怎么配
我们首先把程序跑起来,这里把上面案例的重要线索再理一遍给大家听。
1)、线程池核心线程数是10,最大线程数是50,队列是200;
2)、发消息业务是耗时5秒;
3)、并发工具执行线程数是200.
可以看到下图,200个线程都执行完了,左边的时间可以观测到,每5秒会执行10个线程,我这边的后台运行可以明显发现很慢才全部执行完200个线程。
由此可见,核心线程数先执行10个,剩下190个放到了队列,而我们的队列大小是200足够,所以最大线程数没起作用。
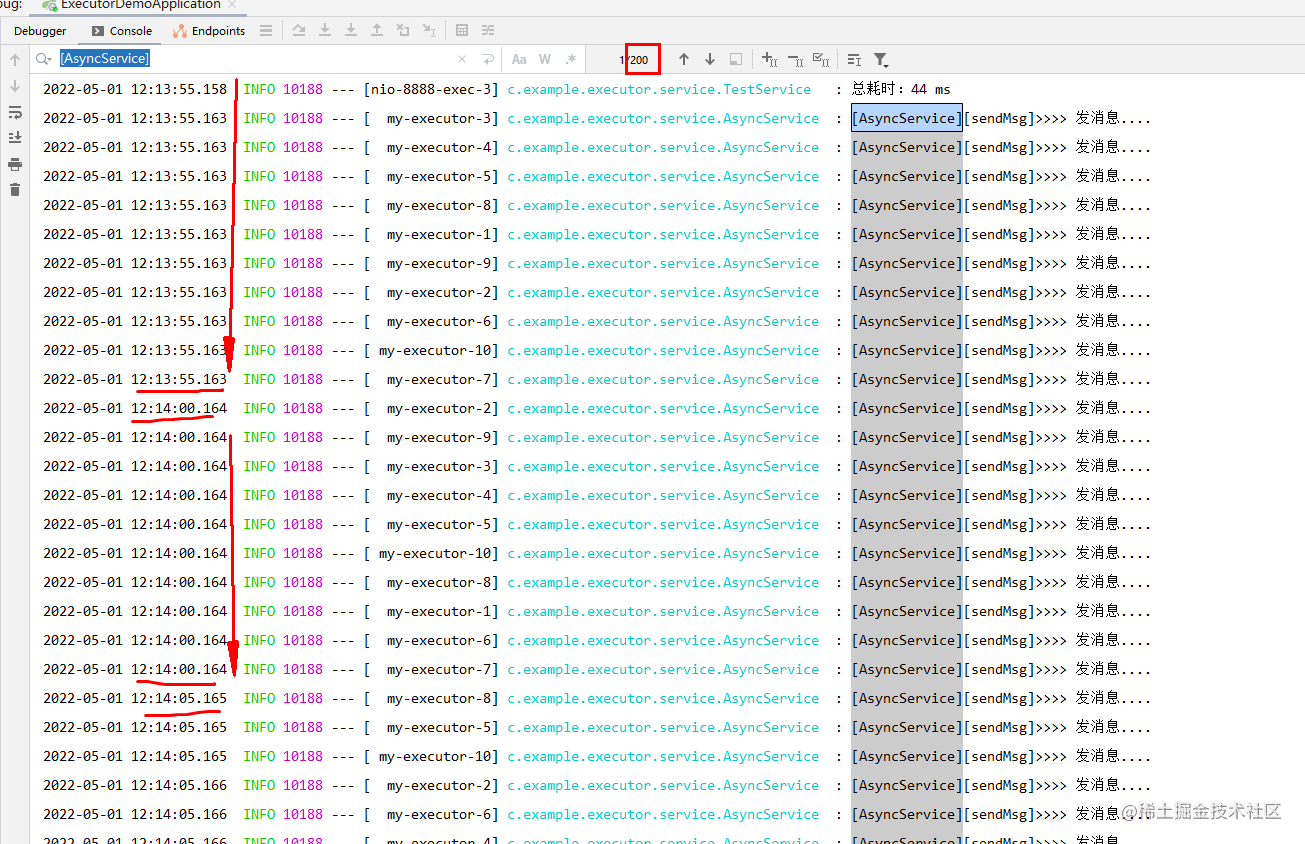
思考:怎么提高200个线程的执行效率?答案已经很明显了,因为我们的业务属于耗时业务花费了5秒,核心线程数配置少了就会导致全部200个线程数执行完会很慢,那么我们只需要增大核心线程数即可。
我们将核心线程数调到100
@Bean(name = "myExecutor")
public Executor getNetHospitalMsgAsyncExecutor() {
log.info("Creating myExecutor Async Task Executor");
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(100);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(200);
executor.setThreadNamePrefix("my-executor-");
// 拒绝策略:直接拒绝抛出异常
executor.setRejectedExecutionHandler(
new ThreadPoolExecutor.AbortPolicy());
// 拒绝策略:调用者线程执行
// executor.setRejectedExecutionHandler(
// new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
看效果:咦?报错了?
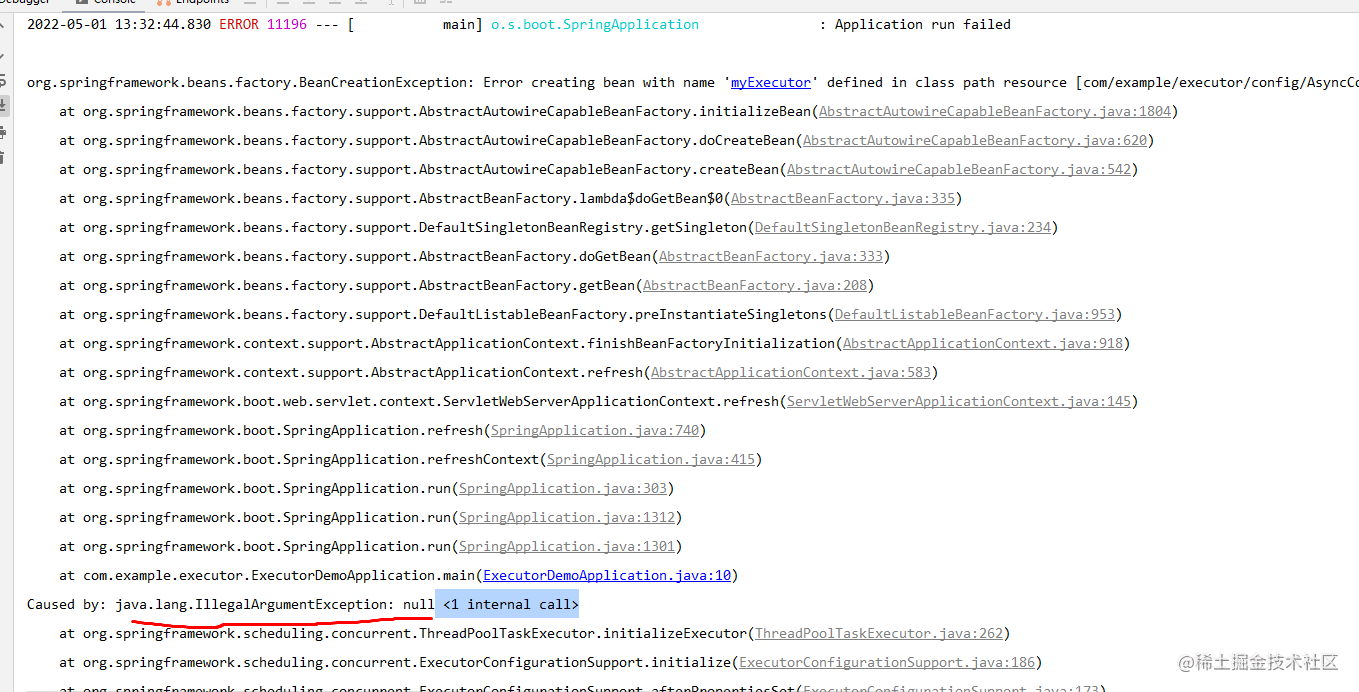
为什么,看源码就知道了。
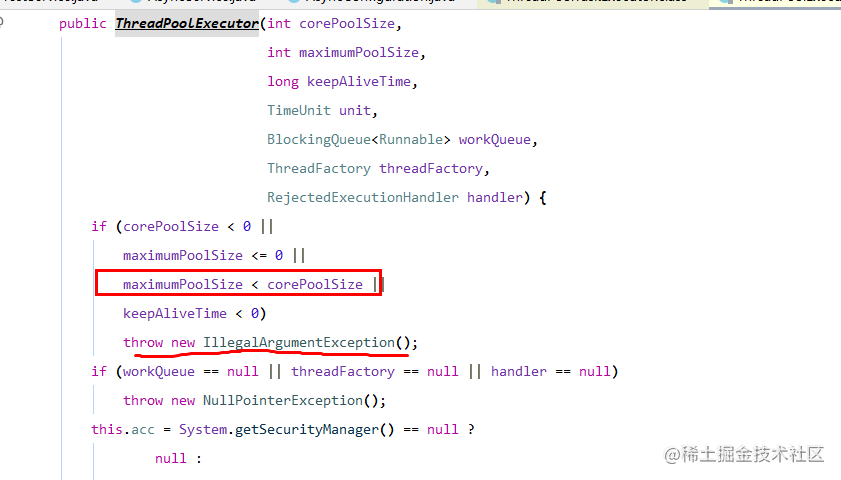
原来,线程池初始化时,内部有做判断,最大线程数若小于核心线程数就会抛出这个异常,所以我们设置时要特别注意,至少核心线程数要大于等于最大线程数。
我们修改下配置:核心线程数和最大线程数都设置为100.
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(100);
executor.setMaxPoolSize(100);
executor.setQueueCapacity(200);
executor.setThreadNamePrefix("my-executor-");
看效果:后台运行过程中可以发现,运行速度非常快,至少和之前相比提升了10倍,200个线程一会儿就跑完了。
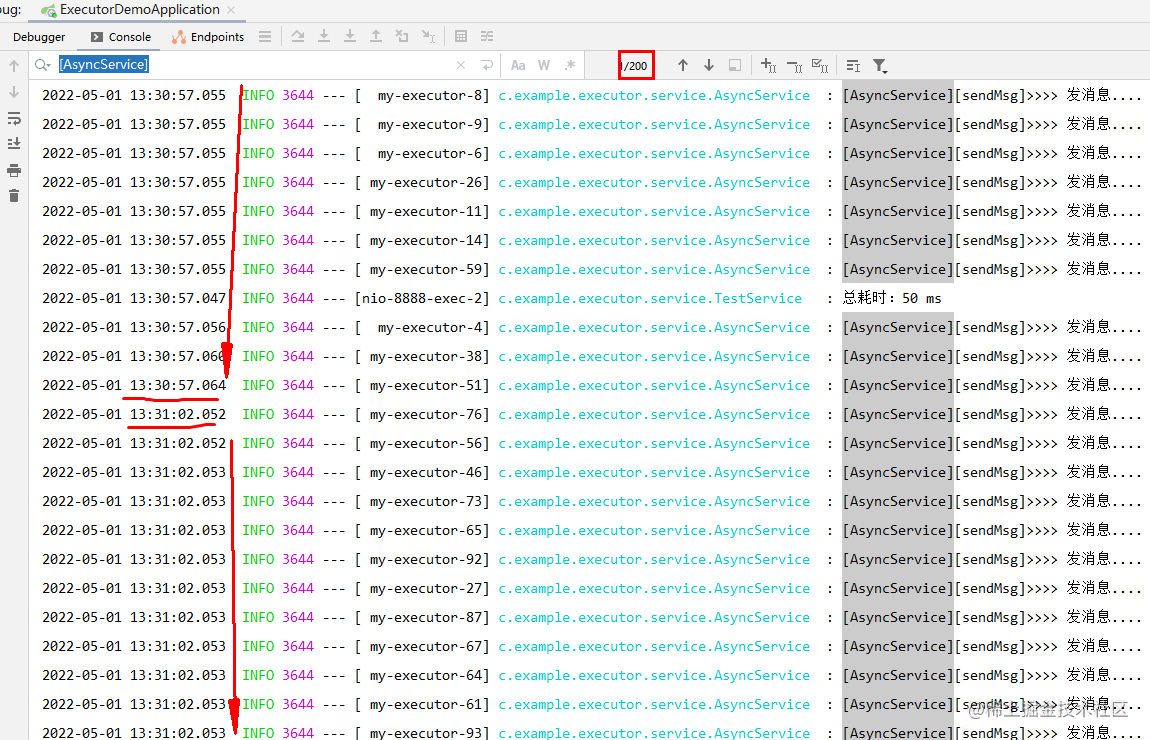
原因:我们设定的是耗时业务5秒,核心线程数只有10,那么放入队列等待的线程都会分批执行该耗时业务,每批次次5秒就会很慢,当我们把核心线程数调大后,相当于只执行了一两个批次就完成了这5秒业务,速度自然成倍提升。
这里我们就可以得出第一个结论:
如果你的业务是耗时业务,线程池配置中的核心线程数就要调大。
思考一下:
什么样的业务适合配置较小的核心线程数和较大的队列?
4、最大线程数怎么配
接下来,我们来看看最大线程数是怎么回事,这个就有意思了,网上一大堆资料都是错的。
还是之前的案例,为了更清晰,我们调整一下配置参数:核心线程数4个,最大线程数8个,队列就1个。
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(8);
executor.setQueueCapacity(1);
executor.setThreadNamePrefix("my-executor-");
然后我们把并发测试的数量改为10个。
ConcurrencyTester tester = ThreadUtil.concurrencyTest(10, () -> {
// 测试的逻辑内容
try {
asyncService.sendMsg();
} catch (InterruptedException e) {
log.error("[TestService][test]>>>> 发生异常: ", e);
}
});
启动,测试:
惊喜发现,咦?10个并发数,怎么只有9个执行了,还有1个跑哪儿去啦?
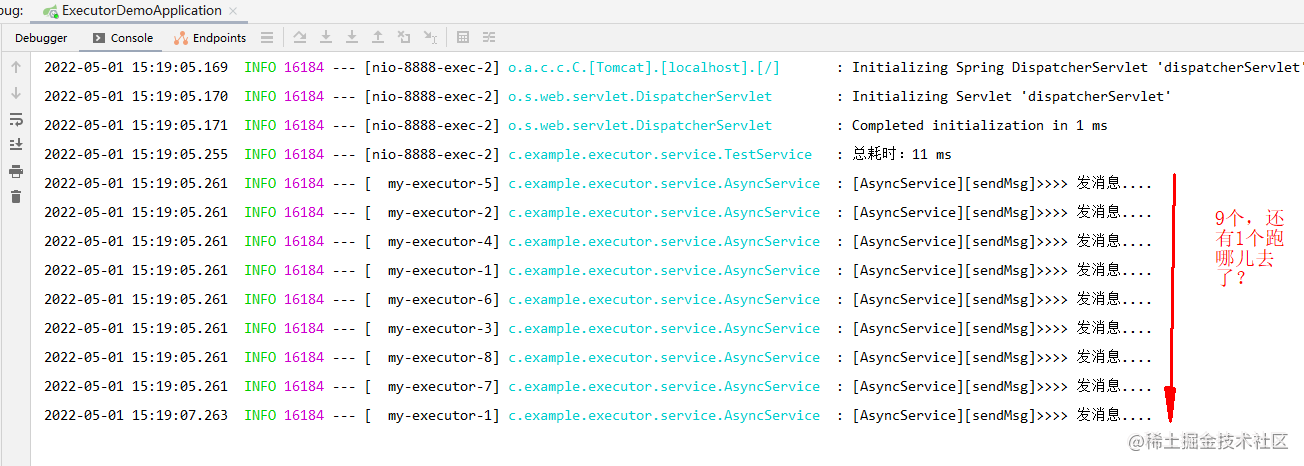
我们把最大线程数改为7个再试试
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(7);
executor.setQueueCapacity(1);
executor.setThreadNamePrefix("my-executor-");
再看看,发现竟然只执行了8个,这下好了,竟然有2个都不翼而飞了……
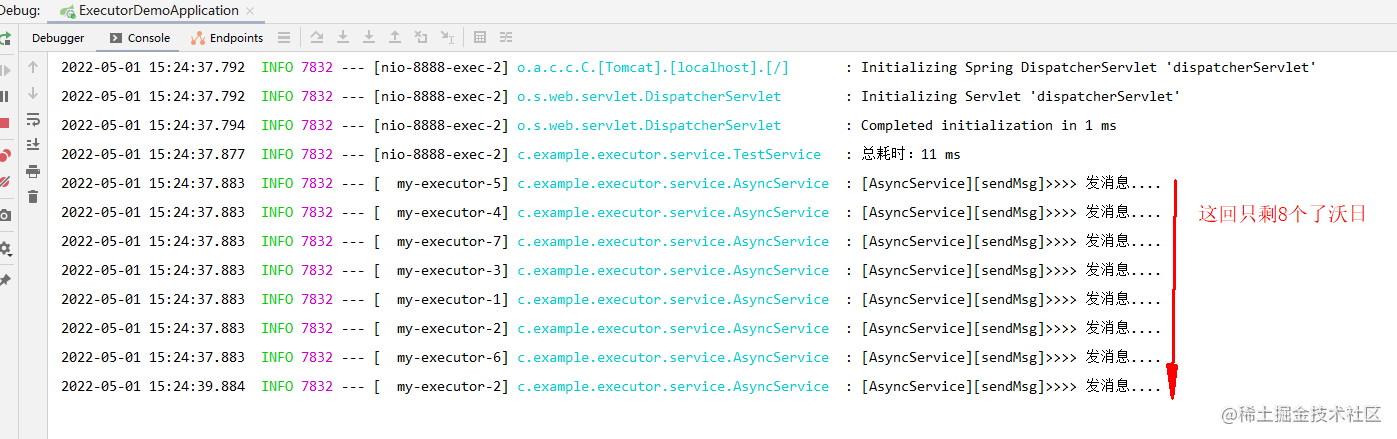
为什么呢,具体演示效果我会在下面的拒绝策略那里一起演示出来,这里我先直接告诉大家结论:
最大线程数究竟在线程池中是什么意思,没错,就是字面意思。当核心线程数满了,队列也满了,剩下的线程走最大线程数创建的新线程执行任务,这个流程一开始给大家梳理过。
但是听好了,因为是最大线程数,所以执行线程怎么样都不会超过这个数字,超过就被拒绝策略拒绝了。
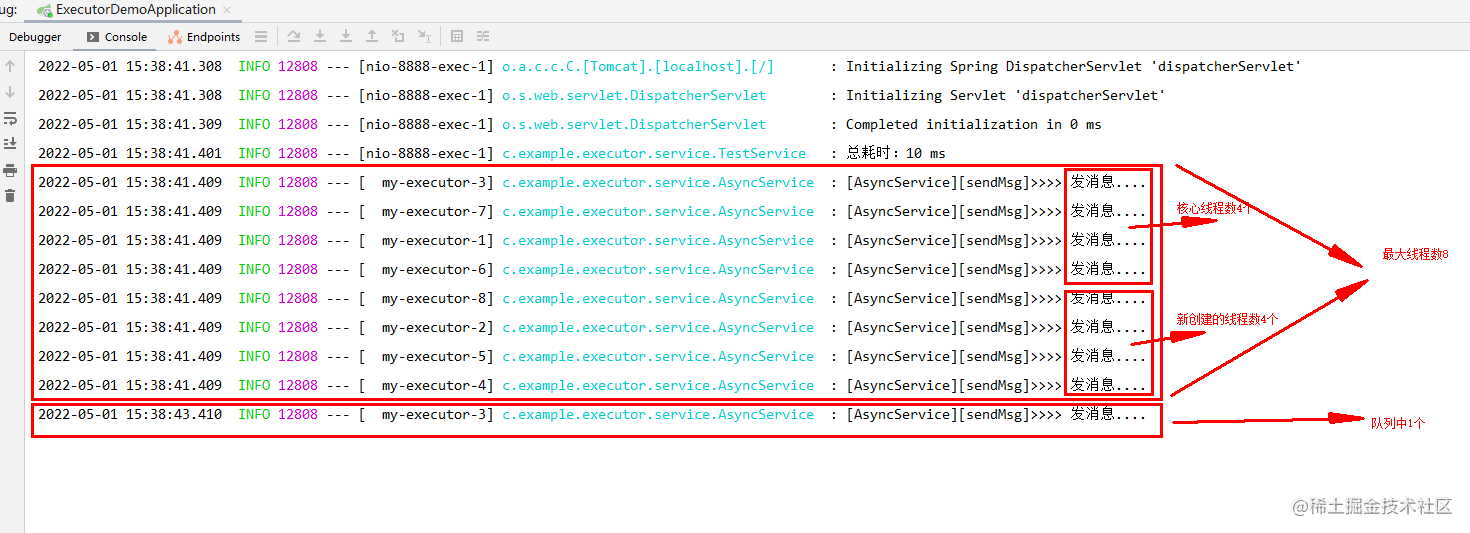
现在我们再根据本节刚开始的配置参数来梳理一遍,10个并发数,4个占用了核心线程数,1个进入队列,最大线程数配置是8,在当前这2秒的业务时间内,活动线程一共是:
核心线程数(4) + 新创建线程数(?) = 最大线程数(8)
可见,因为最大线程数配置的是8,所以核心线程数和队列都打满之后,新创建的线程数只能是8-4=4个,因此最终执行的就是:
核心线程数(4) + 新创建的线程数(4) + 队列中的线程(1) = 9
一点问题都没有,剩下的一个超出最大线程数8所以被拒绝策略拒绝了。
最后,一张图给你整的明明白白,注意看左边的时间,就知道最后那个是队列里面2秒后执行的线程。
这里,我们也可以得出第二个结论:
最大线程数就是字面意思,当前活动线程不能超过这个限制,超过了就会被拒绝策略给拒绝掉。
5、队列大小怎么配
前面两个理解了,队列大小其实一个简单的测试就能明白。
我们修改下之前的线程池配置:
核心线程数50,最大线程数50,队列100,业务耗时时间改为1秒方便测试.
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(50);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("my-executor-");
并发数设为200
ConcurrencyTester tester = ThreadUtil.concurrencyTest(200, () -> {
// 测试的逻辑内容
try {
asyncService.sendMsg();
} catch (InterruptedException e) {
log.error("[TestService][test]>>>> 发生异常: ", e);
}
});
测试下效果:可以看到,200个并发数,最终只执行了150个,具体算法上一节最大线程数已经讲过不再赘述了。
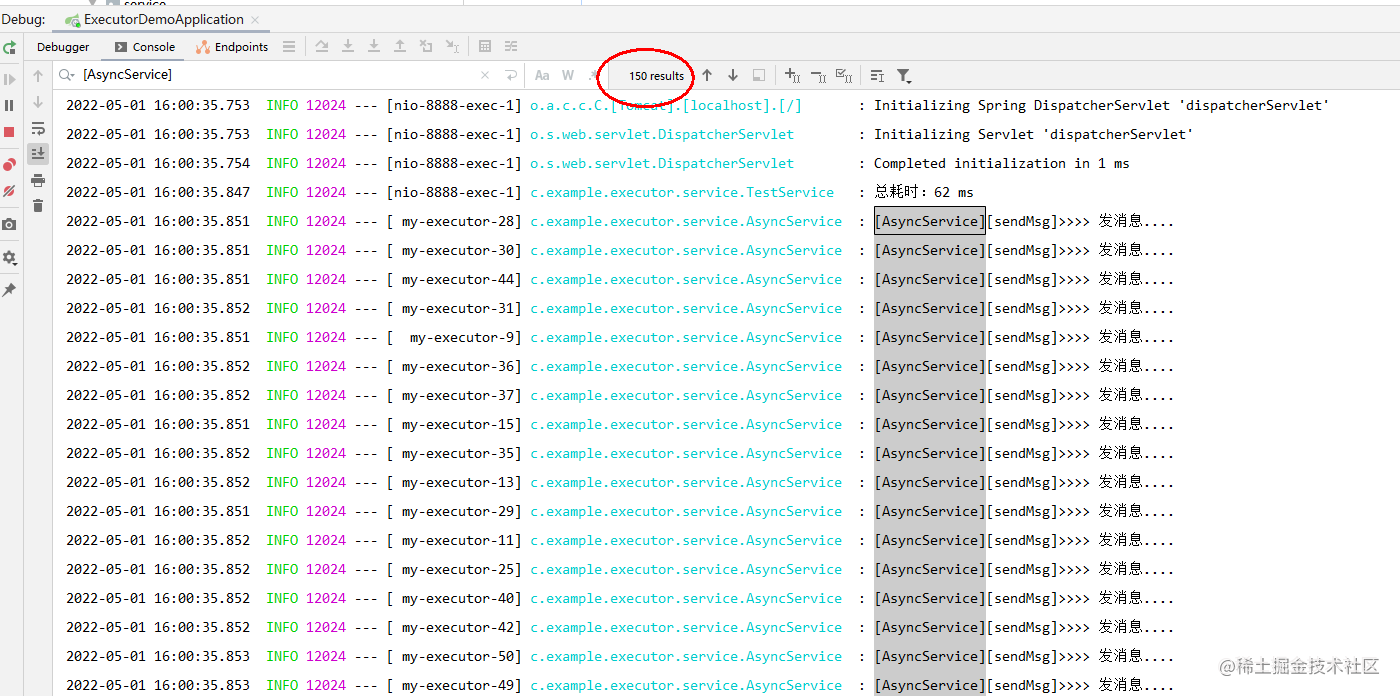
这里我们主要明确一点,就是当前线程数超过队列大小后,会走最大线程数去计算后创建新线程来执行业务,那么我们不妨想一下,是不是把队列设置大一点就可以了,这样就不会再走最大线程数。
我们把队列大小从100调成500看看
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(50);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(500);
executor.setThreadNamePrefix("my-executor-");
测试效果:可以看到,200个都执行完了,说明我们的设想是正确的。
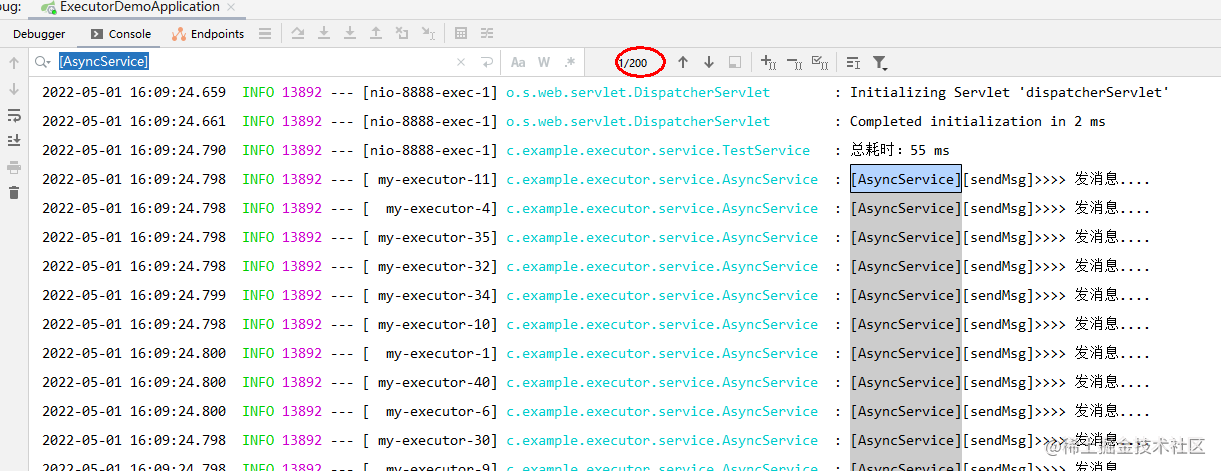
这里可以得出第三个结论:
队列大小设置合理,就不需要走最大线程数造成额外开销,所以配置线程池的最佳方式是核心线程数搭配队列大小。
6、拒绝策略怎么配
前面最大线程数如何配置的小节中,经过测试可以发现,超过最大线程数后一部分线程直接被拒绝了,因为我们一开始有配置拒绝策略,这个策略是线程池默认策略,表示直接拒绝。
// 拒绝策略:直接拒绝抛出异常
executor.setRejectedExecutionHandler(
new ThreadPoolExecutor.AbortPolicy());
那么我们怎么知道这些线程确实是被拒绝了呢,这里我们恢复最大线程数小节中的参数配置。
然后,把默认策略改为另一个策略:CallerRunsPolicy,表示拒绝后由调用者线程继续执行。
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(7);
executor.setQueueCapacity(1);
executor.setThreadNamePrefix("my-executor-");
// 拒绝策略:调用者线程执行
executor.setRejectedExecutionHandler(
new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
并发数改为10个
ConcurrencyTester tester = ThreadUtil.concurrencyTest(10, () -> {
// 测试的逻辑内容
try {
asyncService.sendMsg();
} catch (InterruptedException e) {
log.error("[TestService][test]>>>> 发生异常: ", e);
}
});
测试效果:
可以看到10个并发数都执行完了,而最大线程数小节中我们测试时是有2个线程被默认策略拒绝掉的,因为现在策略改成了由调用者线程继续执行任务,所以那2个虽然被拒绝了但还是由调用者线程执行完了。
可以看到图中红线的两个线程,名称和自定义线程的名称是有明显区别的,这就是调用者线程去执行了。
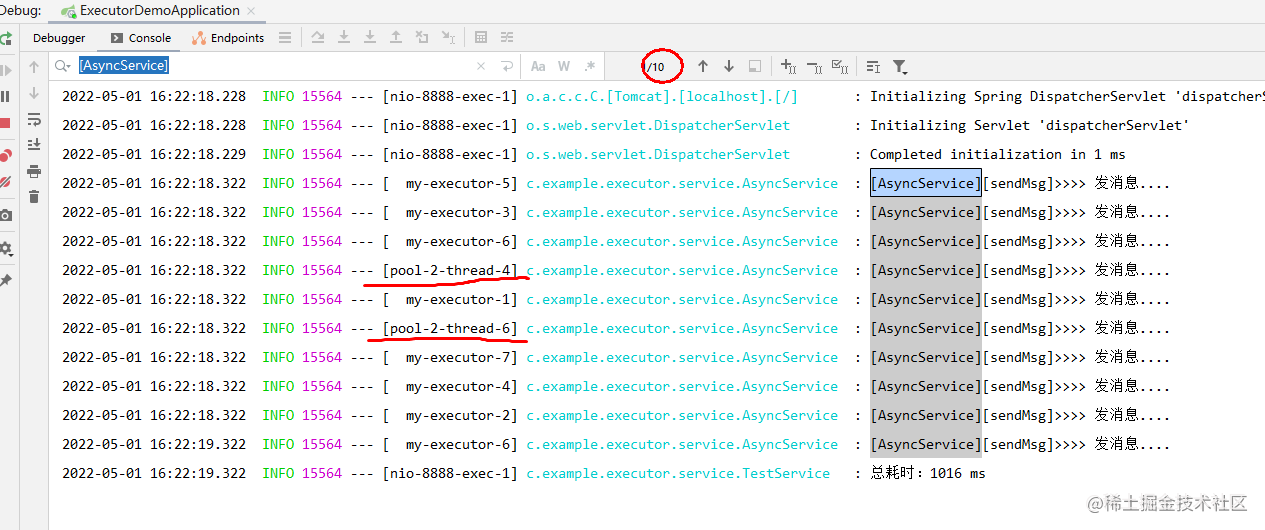
那么,这种策略这么人性化,一定是好的吗?
NO!这种策略反而不可控,如果是互联网项目,在线上很容易出问题,道理很简单。
线程池占用的不是主线程,是一种异步操作来执行任务,这种策略实际上是把拒绝的线程重新交给了主线程去执行,等于把异步改为了同步,你试想一下,在高峰流量阶段,如果大量异步线程因为这个策略走了主线程是什么后果,很可能导致你主线程的程序崩溃,继而形成服务雪崩。
展示一下线程池提供的4种策略:
1)、AbortPolicy:默认策略,直接拒绝并会抛出一个RejectedExecutionException异常;
2)、CallerRunsPolicy:调用者线程继续执行任务,一种简单的反馈机制策略;
3)、DiscardPolicy:直接抛弃任务,没有任何通知及反馈;
4)、DiscardOldestPolicy:抛弃一个老任务,通常是存活时间最长的那个。
不少人认为CallerRunsPolicy策略是最完善的,但我个人的观点,实际上生产环境中风险最低的还是默认策略,我们线上的项目倾向于优先保证安全。
讲到这里,结合案例基本上大家能明白这几个线程池参数的含义,那么还记得前面我发出的一个思考题吗,不记得了,因为大家都是鱼的记忆,思考题是:
什么样的业务适合配置较小的核心线程数和较大的队列?
答案:低耗时、高并发的场景非常适合,因为低耗时都属于毫秒级业务,这种业务走CPU和内存会更合适,高并发时需要队列缓冲,同时因为低耗时又不会在队列中长时间等待,核心线程数较大会一次性增加CPU过大的开销,所以配置较小的核心线程数和较大的队列就很适合这种场景。
题外话,用过云产品的就知道,你选购云服务器时,总会让你选什么CPU密集型和IO密集型之类的款型,如果你对线程池比较了解,就能知道什么意思,不同的项目需要搭配的服务器款型实际上是有考量的,上面的场景就显然要选CPU密集型的服务器,而本章前面的案例场景是高耗时的就适合IO密集型的服务器。
三、总结
这里面除了针对本章总结,还额外增加了几点,来源于我的工作经验。
1)、如果你的业务是耗时业务,线程池配置中的核心线程数就要调大,队列就要适当调小;
2)、如果你的业务是低耗时业务(毫秒级),同时流量较大,线程池配置中的核心线程数就要调小,队列就要适当调大;
3)、最大线程数就是字面意思,当前活动线程不能超过这个限制,超过了就会被拒绝策略给拒绝掉;
4)、队列大小设置合理,就不需要走最大线程数造成额外开销,所以配置线程池的最佳方式是核心线程数搭配队列大小;
5)、线程池拒绝策略尽量以默认为主,降低生产环境风险,非必要不改变;
6)、同一个服务器中部署的项目或微服务,全部加起来的线程池数量最好不要超过5个,否则生死有命富贵在天;
7)、线程池不要乱用,分清楚业务场景,尽量在可以延迟且不是特别重要的场景下使用,比如我这里的发消息,或者发订阅通知,或者做某个场景的日志记录等等,千万别在核心业务中轻易使用线程池;
8)、线程池不要混用,特定业务记得隔离,也就是自定义各自的线程池,不同的名称不同的参数,你可以试想一下你随手写了一个线程池,配置了自己那块业务合适的参数,结果被另一个同事拿去在并发量大的业务中使用了,到时候只能有难同当了;
9)、线程池配置不是请客吃饭,哪怕你很熟悉,请在上线前依然做一下压测,这是本人惨痛的教训;
10)、请一定要明确线程池的应用场景,切勿和高并发处理方案混淆在一起,这俩业务上针对的方向完全不同。
四、分享
最后,我再分享给大家一个我之前工作中使用过的公式,仅针对中小企业特定业务当前线程数千级以上的场景,毕竟哥没呆过大厂,能分享的经验有限,贵在真实可用。
以我公司为例,我们属于中小型互联网公司,用的华为云,线上服务器基本都是8核,我平常对于特定业务使用线程池都是以当前线程数2000来测试的,因为同一时间2000个并发线程在中小企业没大家想的那么容易出现。我公司服务于医院,一年也遇不到几次,除了这两年由于疫情做核酸数量激增的时候。
你自己可以试想一下,2000个线程同时处理某个业务,得有多少用户量,得是什么样的场景才会出现,关键你用的是线程池,你为什么会在这种场景使用线程池本身也是要反思的事情,有些类似的场景都是通过缓存及MQ来削峰的,这也是我总结中讲的不要和高并发处理方案混淆在一起的原因,你应该把线程池用在需要延迟处理又不太重要的业务中最合适。
我总结的公式可以从这里获取:
链接: https://pan.baidu.com/doc/share/TES95Wnsy3ztUp_Al1L~LQ-567189327526315
提取码: 2jjy
本人原创文章纯手打,觉得有一滴滴用处的话就请点个推荐吧。
不定期分享实际工作中的经验和趣事,感兴趣的话就请关注一下吧~
喜欢就点一下推荐吧~~