开讲资源库,这东西简单来说就是用于持久化或查询聚合的。注意!您需要与DAO分别:DAO操作的对象是数据实体;而资源仓库的目标是聚合(不存在通过资源库操作值对象的情况,值对象必须依赖于某个实体)。你完全可以把资源库想像成为一个盒子,想要存储聚合的时候直接放进去即可;想要修改只需要取出后再放进去,就能把原有的对象替换掉;想要删除也只需要随手从盒子取出扔掉即可,至于盒子本身如何实现存储,作用用户的你根本不必关心。当然了,作为程序员得关心,你得为了达到这样一个目的去实现代码。从技术的角度去看,您完全可以把资源库当成领域模型序列化和反序列化的外观模式。这里需要注意一点,一个对象如果被放入了两次,在资源仓库中也只存在一个,有点类似于Java中的Set集合。至于如何区分不同的实体,当然是ID喽,前面讲过一百万次了。
1、聚合接口的定义我们在使用资源库的时候需要注意把接口的声明与实现进行分离。主要是因为这两个组件分别属于不同层:接口定义属于业务模型层,这里我还是应该再强调一下:资源库不是DAO,您千万别使用错了,其操作的目标是聚合,不要啥啥都往里面放。资源库包含两类操作:领域模型新建或修改后肯定需要进行持久化,是为写操作,接收的参数应该是领域模型;涉及一些命令型的业务,肯定需要把领域模型查出来再操作,其返回值就应该是领域模型,此为读操作。至于说是否需要批量存储或需要根据什么特殊条件把领域模型搞出来,这完全是由业务规定的。总得来说,资源库关注的领域对象的操作。那么DAO呢?其只管数据模型的相关操作,它面向的是数据库表并提供CURD供能,反正是把数据给你了,至于你怎么用,是想将其转换成领域模型还是转换成视图模型发送给谁它也不会关心,所以DAO的设计其实简单,无脑的针对每一张表做类似的功能即可。此外,DAO中的方法也不是由业务驱动的,每张表都应该有插入、删除、更新等常规操作,代码生成器就可以根据表的定义完美生成DAO的代码。早期我经历过一个C#的项目,看DAO的代码写的那叫一个复杂,大量的匿名函数和Lamda表达式的使用,可你别看代码复杂却非常的规范。当时以为是哪个大神整出来的,后来发现这个大神是“Code Smith”。甲方爸爸哪懂得这些,他们看到的就是开发速度很快。这也从一方面引申出了一个问题,为什么现在很多的软件集成厂商混得不好了?为什么好多单位都强调自研?一方面是出于安全和全局的控制,总让别人抓住小辫子也不好;另外一方面,乙方的确做得太差劲,仗着别人不懂糊弄人,自已把自己的饭碗搞砸了。
针对资源库与DAO的区别,除了操作对象不一样外,数量也有明显的区别:资源库是一个聚合一个;DAO是一个数据库表一个。比如订单聚合,其包含订单实体与订单项值对象,使用MySQL作为持久化设施。资源库肯定是只有一个了,但表至少得两张吧?我相信聪明的您应该不会把订单与订单项放在同一张表里。
回归主题,由于资源库的目标是领域模型,其方法的定义也是由于业务来驱动的,我们曾经在前面的章节中举过例子,在此不再赘述,唯一需要注意的是你应该将其放到BO层中;而针对资源库的实现,毕竟他需要把领域模型进行序列化和反序列化,最终的实现不管是在仓库中直接调用数据库中间件组件还是通过DAO代理,肯定是涉及到了对于基础设施的依赖。您懂的,领域模型不能依赖于基础设施,所以资源库的实现需要和其接口进行分开。一般来说,我们都是将实现放到基础设施层,通过依赖注入的方式将其实现注入到应用服务中。
虽然说资源库接口的定义由业务来驱动,我们还是会给其一些通用的能力,毕竟多数情况下领域模型还是需要进行存储或根据ID查询,所以在实践中会在接口中声明如“添加”、“更新”和“根据ID查询”三类接口,这三类可以说是最基本的能力。至于删除嘛,其实就是更新聚合的状态,一般也很少会把数据做物理删除。我个人习惯会定义一个删除的接口,在实现的时候将实体的状态变成某个代表不可用的值,比如“-1”。除了这些基本能力外,还有哪些接口就看业务需要喽。说到此您应该可以想到资源库的接口其实应该分成两个对吧?一个是基本能力,一个是自定义附加能力,如下代码片段所示。
public interface Repository<TID extends Comparable, TEntity extends EntityModel> { /** * 根据ID返回领域模型 * @param id 领域模型ID * @return 领域模型 */ TEntity findBy(TID id) throws PersistenceException; /** * 删除领域实体 * @param entity 待删除的领域实体 */ void remove(TEntity entity); /** * 删除多个领域实体 * @param entities 待删除的领域实体列表 */ void remove(List<TEntity> entities); /** *将领域实体存储至资源仓库中 * @param entity 待存储的领域实体 */ void add(TEntity entity); /** * 将领域实体存储至资源仓库中 * @param entities 待存储的领域实体列表 */ void add(List<TEntity> entities); /** *更新领域实体 * @param entity 待更新的领域实体 */ void update(TEntity entity); /** *更新领域实体 * @param entities 待更新的领域实体列表 */ void update(List<TEntity> entities); }
其实上面这段代码在前面已经贴过了,不过我们既然专门讲到资源库,索引就再发一次。也不是为了水文字,免得您来回的翻多麻烦。再说了,都电子化时代了,又不废纸。这里面需要有两点进行说明:1)接口的返回值最好都是“void”,也有人说返回“布尔”更好。反下我是不喜欢,资源库执行出错后直接抛个异常多好,正好能触发事务的回滚,还顺便把错误信息带出来了。您使用“布尔”也只代表成功与否(也不一定是真的),错误原因带不出来,只能写日志,代码中充满了与业务无关的内容,代码乱不说,问题排查的过程也比较费劲。2)批量的方法,这个您看情况。有些情况下作批量的操作还是很有必要的,我们可以在基本能力中进行声明,至于用不用那就看需求了,又不麻烦,实现的时候想简单就循环调用对应的单对象操作方法或把批量的操作写到SQL中。有了上面的基本的接口,我们再看看与业务相关的接口要如何定义。其实就是从“Repository”接口继承一下,我还是拿订单业务来演示,具体背景为:订单有主子订单的概念,当用户将主订单取消时相应的子订单也需要进行取消。我们想像一下,取消操作大概需要三步:1)根据主订单查询子订单列表;2)执行业务逻辑;3)将订单信息进行存储。第二步我们暂时不管,第三步就是批量的更新,在资源库通用能力接口中已经定义了对应的方法。唯有第一步,一看就是需要定制的,那就新建一个订单相关的资源库,把接口的定义放到里面去,代码如下。
public interface OrderRepository extends Repository<Long, Order> { List<Order> queryByMasterOrderId(Long masterOrderId); }
还是需要说一下上面两段代码所处的位置。您还记得我说在进行DDD落地时需要写一些基本的类库吧?第一段代码就需要放到基本类库里,让每一个业务资源库接口都从其继承;第二段当然就是放到BO层中了。通过上例的演示您应该可以看到,其实资源库接口所包含的方法应该非常少,我所经历的项目中使用过的资源库不算通用能力,自定义的方法数量基本都不会超过3个。你定义的所有方法都是为了某一个命令型业务场景服务的,而很多的命令型业务所使用的资源库方法其实都可以映射为几种基本方法的组合,比如我们常见的电商下单业务:支付、取消、订单完成等其实就调用了两个方法:根据ID查询订单实体和更新订单实体。其实在早期进行DDD探索学习的时候我也曾经误用过,比如把所有的查询都放到资源库中,这种情况属于典型的费力不讨好。您想啊,把数据组装成聚合多慢啊,你为了保障其完整性一次需要查好几张表,结果大部分信息都用不上。另外,由于您把仅用于查询的方法也放到了资源库里,应用服务很容易就把领域模型直接泄露到外面。还有一点,您再想像一下查询的本质:其主要目标是为外部提供数据,这里外部可能是另外的服务也可能是前端系统,查询结果的结构应该是越简单越好,最好以一或二维的形式进行表现;而聚合的内部结构是立体的,各种对象相互关联,这种复杂的关联关系就决定了其内在的先天复杂性。面向对象的本质就是把责任尽量的细化,一个事情该由谁来干分工是非常明确的。所以领域实体更适合于命令型业务,应对查询不是大材小用而是它根本就不擅长。此外,针对查询的操作中你应该以追求执行速度为主,只要能保证数据的正确使用任何技术手段理论上来说都是允许的,而命令的操作则限制很多。
认识了资源库接口的设计后,相信您应该对其轮廓有个基本的感性认识了,那应该如何完成其实现呢?请继续读。
2、接口的实现资源库的接口定义与实现在DDD中通常会在代码层次上进行分离,定义部分我们上面已经说明,而实现部分由于其需要引入DAO或操作数据库的组件所以一般会将其放在基础设施层中。很多人在使用资源库的时候非常容易犯的错误是把资源库接口与实现放在一起包括我自己(曾经的我),纠其原因还是因为对于资源库的理解度不够,谁没年轻过啊。既然我们讲的是领域驱动设计,那就应该始终围绕着这个目标进行一切工作包括分析、设计和实施等系统建设的各个阶段所涉及的内容,资源库的设计也一样,你得分清什么是领域相关的什么是技术相关的。正常情况下一种对象只能属于二者中的一个,唯有资源库比较个性。实践上为方便起见,我通常会把资源库的实现放到一个名称为“repository”的包中,这样做只是为了更好的组织代码,逻辑上你仍然需要将其作为基础设施层的组件来看待。
同资源库接口,我们在进行资源库实现的时候并不是直接写一个从实体资源仓库接口如“OrderRepository”实现的类,而是首先会定义一个资源库基类并在其中使用一些手段来简化资源库的使用或增加一些额外能力的支撑比如事务管理、业务预警埋点等。在继续往下写之前我们还是需要讨论一下事务的问题,这东西在微服务架构+DDD中使用有一定的限制。首先一点关于事务的使用方式:分布式事务与传统事务。针对分布式系统虽然可用的事务选择相对比较多,但Saga已经成为事实上的标准,也就是通过事件的形式实现最终一致性,这里的最终一致性可以跨BC也可以在单个服务中使用;关于传统型事务,一般是指关系型数据库的强事务也叫作刚性事务。如果你使用了Spring,事务的开启非常简单,只需要搞一个注解即可。还有一种方式当然就是使用Spring的编程事务了,如果在项目中使用了“工作单元”则通常会搭配这个。Saga不是本节的重点,这东西对业务有一定的入侵性,还会涉及到比如隔离性等问题,是相对比较高级的主题,我们会放到独立的章节中进行讲解。针对数据库刚性事务,可以考虑将其下沉到资源库中实现,封装好后工程师不用每次都在应用服务中显示声明,万一记性不好忘了呢?这年头儿,正经的事情记不住;不正经的忘不了。通过使用工作单元(Unit of Work)模式,可以在代码中玩很多的花样比如记录日志、对领域模型进行最终验证等。这个模式太有名了,网上一搜一大堆,不过下面我也会给出案例,就是为了证明:咱也会。上面说到的资源库基类,我在使用的时候将其与工作单元进行了集成并将事务放到了工作单元中。
如果你在实现领域模型的时候使用了对象变更标记,比如当某个对象的属性变更后将其标记为“dirty”,持久化阶段发现对象有此标记时才真正的进行存储。这种模式对于提升系统的性能有一定的作用,按需持久化可以避免无效的数据库操作。由于需要细粒度的控制,所以使用工作单元会比较好。如果你并没有这样的标识或强烈的持久化性能要求,其实使用Spring的注解标记完全可以满足事务需求,并不需要再使用额外的模式。而我之所以在项目中使用它并不是由于应用了前面所说的变更标记也不是为了向世人展示“我会”,而是因为需要在工作单元中作业务级监控埋点和日志处理等工作,这些不放到工作单元的话就只能在应用服务中实现了,代码看起来让人非常不爽。
工作单元相关的理论不是本文的主要内容,建议在网上找一些相关的文章进行了解。我们先贴一些代码,展示如何将其与资源库进行集成。下面代码片段为工作单元接口的定义,不过模式就是模式,您别看定义了这么多接口方法其实并不会全部调用的,大多数用例只调用其中的某一个,因为我们根本不允许一个事务更新多个不同的聚合。
public interface UnitOfWorkRepository<TEntity extends EntityModel> { /** * 持久化新建的领域模型 * @param entity 待持久化的领域模型 */ void persistNewCreated(TEntity entity) throws PersistenceException; /** * 删除领域模型 * @param entity 待删除的领域模型 */ void persistDeleted(TEntity entity) throws PersistenceException; /** * 持久化已变化的领域模型 * @param entity 待持久化的领域模型 */ void persistChanged(TEntity entity) throws PersistenceException; }
下面代码为工作单元的基类,以“createdEntities”属性为例,是一个Map结构,键为聚合实例,值为用于执行新建操作的资源库实例。我们把所有待插入数据库的对象都放在这个属性中。键信息相对简单,值对象理解起来相对就会麻烦一点,简单来说就是根据这里的映射关系,来决定由哪个资源库实例来执行键所对应的实体的插入存储。还有一段意思的代码是“persistNewCreated”,他会循环“createdEntities”中的元素,依次执行领域模型插入到数据库的操作,其中插入方法由业务资源库实现。核心方法“commit”一看名字就知道其主要用于事务的提交,不过在当前的代码中并未开启事务,是因为我把它放到了工作单元具体类中。
public abstract class UnitOfWorkBase implements UnitOfWork { //包含了所有新建的领域模型 Map<EntityModel, UnitOfWorkRepository> createdEntities = new HashMap<>(); @Override public void registerNewCreated(EntityModel entity, UnitOfWorkRepository<? extends EntityModel> repository) { if (entity == null || repository == null) { return; } if(this.deletedEntities.containsKey(entity ) || this.updatedEntities.containsKey(entity)){ return; } if(!this.createdEntities.containsKey(entity)){ this.createdEntities.put(entity, repository); } } //提交事务 @Override public CommitHandlingResult commit() { CommitHandlingResult result = new CommitHandlingResult(); try { this.validate(); this.persist(); } catch(ValidationException e) { logger.error(e.getMessage(), e); result = new CommitHandlingResult(false, e.getMessage()); } catch(Exception e) { logger.error(e.getMessage(), e); result = new CommitHandlingResult(false, OperationMessages.COMMIT_FAILED);
//业务监控埋点 } finally { this.clear(); } return result; } //持久化对象 protected abstract void persist() throws PersistenceException; //持久化新建的对象 protected void persistNewCreated() throws PersistenceException{ Iterator<Map.Entry<EntityModel, UnitOfWorkRepository>> iterator = this.createdEntities.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<EntityModel,UnitOfWorkRepository> entry = iterator.next(); entry.getValue().persistNewCreated(entry.getKey()); } } }
上述代码展示了工作单元的基类,我们据此实现一个基于MySQL的工作单元,请参看下列代码。其实很简单,就是使用了Spring的编程事务。后续所有实体的持久化都会使用此工作单元完成,按此方法您如果有兴趣的话可以试试将其应用在NoSql上看是什么样的结果。
final public class SimpleUnitOfWork extends UnitOfWorkBase { @Override protected void persist() throws PersistenceException { TransactionTemplate transactionTemplate = ApplicationContextProvider.getBean(TransactionTemplate.class); transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_DEFAULT); transactionTemplate.setPropagationBehavior(Propagation.REQUIRES_NEW.value()); Exception exception = transactionTemplate.execute(transactionStatus -> { try { persistDeleted(); persistChanged(); persistNewCreated(); return null; } catch (Exception e) { transactionStatus.setRollbackOnly(); return e; } }); if (exception != null) { throw new PersistenceException(exception); } } }
到此为止,我们只是实现了工作单元,并未将其与资源库集成。具体集成的责任我给它放到了资源库抽象类“RepositoryBase”中,可参看如下代码片段。此抽象类同时实现了工作单元接口和资源库接口,我们可以认为每一个资源库都具备了工作单元的能力。这处代码有两处需要注意的:1)“unitOfWork”属性应该使用“ThreadLocal”以避免因并发产生问题,因为我们会使用Spring管理资源库实例,默认是单例的。而每一次聚合的变更或存储都需要声明一个新的工作单元实体,您如果不用“ThreadLocal”,线上的系统一定给你惊喜的。啊,多嘴一句,每次进行提交操作后您别忘了释放“unitOfWork”所引用的对象,我代码省略了不代表您也不写,虽然ThreadLocal本身也会处理这些,不过小心使得万年船;2)“add”方法将资源库实例存储在工作单元中。这段代码有点绕,需要结合“SimpleUnitOfWork”进行理解,其实就是工作单元与资源仓库之间有一个相互引用的关系。
public abstract class RepositoryBase<TID extends Comparable, TEntity extends EntityModel> implements Repository<TID, TEntity>, UnitOfWorkRepository<TEntity> { //工作单元 ThreadLocal<UnitOfWork> unitOfWork = new ThreadLocal<>(); /** * 将领域实体存储至资源仓库中 * @param entity 待存储的领域实体 */ @Override public void add(TEntity entity) { if (entity == null) { return; } this.unitOfWork.get().registerNewCreated(entity, this); } /** * 持久化新建的领域模型 * @param entity 待持久化的领域模型 */ @Override public abstract void persistNewCreated(TEntity entity) throws PersistenceException; }
到目前为止我们已经把资源库的抽象类和接口进行了说明,这些组件一般都会放到基本类库中免得每实现一个资源库的时候都再重新定义一次。接下来我们来演示如何在业务中使用资源库。前文中我为订单实体定义了一个资源库接口“OrderRepository”,位于BO层中。现在我们需要为这个接口做一个实现类,位于“repository”包中,再提醒一下,这个包属于基础设施层,代码片段如下。
@Repository("orderRepository")
public class OrderRepositoryImpl extends RepositoryBase<Long, Order>
implements OrderRepository {
@Resource
private OrderMapper orderMapper;
@Resource
private OrderEntryMapper orderEntryMapper;
@Override
public void persistNewCreated(Order oder) throws PersistenceException {
if (oder == null) {
throw new PersistenceException();
}
try {
OrderDataEntity orderDataEntity = this.ofOrderData(oder);
List<OrderEntryDataEntity> orderEntryDataEntities = this.ofOrderEntryData(oder);
this.orderMapper.save(orderDataEntity);
this.orderEntryMapper.save(orderEntryDataEntities);
} catch (Exception e) {
throw new PersistenceException(e.getMessage(), e);
}
}
}
在资源库的实现类中,我们其实只需要实现“persist*”模式的方法,这些方法最原始的定义在“UnitOfWorkRepository”中,在“RepositoryBase”进行了实现,只不过实现的时候使用了“abstract”修饰,表示你需要在具体类中进行实现。结合我们上面所有的代码,您会发现后续每次使用资源库的时候只需要写一个接口和接口的实现类即可,在实现类中也只需要实现3个“persist*”模式的方法。细心的您应该已经还发现了在资源库中引入了一个DAO对象“OrderMapper”,相当于访问数据库的操作由这个DAO来进行代理。当然,您也可以直接在资源库中写数据库访问相关的代码,不过这样一是会增加资源库的责任;二是你根本无法避免DAO的使用,因为针对查询的业务你还是会用到它,不然你把代码写在哪里?资源库中?违反了我们前面所说的资源库使用规则,那不是啪啪打脸吗?既然DAO无论如何都应该存在,那为什么不把所有数据库的操作都统一放到它里面呢?这种设计会让代码的责任更加单一,其中的好处不必多说,最起码看起来比较爽。
上述代码中,方法“ofOrderData”用于将领域模型转换成数据模型,这里面需要您做好分析。实体还好说,肯定是单独的表;值对象就复杂一点,是和实体放在一个表中还是单独使用一个表,既要从领域模型的角度考虑也要从数据操作的方便性方面进行考虑。这些虚话谁都会说,我其实想重点说一个有意思的场景即:数据库字段的冗余。比如在订单实体中我们有一个“客户详情”实体属性,在订单项中肯定就不需要了。但是,在存储的时候我们为了加速信息的查询,不仅在订单表,还需要在订单项表中加入这个“客户ID”字段作为冗余。虽然这种设计不太符合数据库范式的定义,但在当今大并发系统中的应用确非常普遍。查询的时候级连的表越多速度越慢,这事儿按理您比我懂,而通过一些冗余的手段确可以大大提升系统的性能,这叫什么来着?“空间换时间”。这种冗余的操作也可以在资源库实现,如下代码所示。
@Repository("orderRepository")
public class OrderRepositoryImpl extends RepositoryBase<Long, Order>
implements OrderRepository {
private List<OrderEntryDataEntity> ofOrderEntryData(Order oder) {
List<OrderEntryDataEntity> entites = new ArrayList(order.getEntries().count());
for(OrderEntry entry : order.getEntries()) {
OrderEntryDataEntity entity = new OrderEntryDataEntity();
entity.setCustomerId(order.getCustomer().getId());
entity.setOrderId(order.getId());
……
entites.add(entry);
}
return entites;
}
}
3、数据关联
这段内容其实属于友情提示,那提示的是什么呢?“数据关联”!我们先看一下示例。在具体资源库中需要实现三个方法,其中一个为“persistDeleted”,完整定义如下代码所示。这里面我标黑的代码标识了如何删除订单与订单项数据(注意:现实中一般不会进行数据的物理删除,这里只是用于演示)。有的工程师喜欢在数据库中设计级联删除,也就是在删除订单的时候将其关联的订单项也一并删除。当然,类似的操作还包含级联更新,通过这些数据库提供的能力在有些时候的确能减少开发的工作量,倒退个20-30年还是可以考虑的。但这些骚操作在现代分布式系统中基本上是明令禁止的,比如我们常常使用的《阿里巴巴开发手册》,其中也明确的标明了不可以使用级联操作。我们不说其它的,仅是对于性能的影响你就不应该拥有它。在应用层进行级联才是你的首选,更加的灵活也更好的控制是一方面,你的程序员兄弟在读代码的时候也可以很快的知道底层的数据处理逻辑到底是什么。
public void persistDeleted(Order order) throws PersistenceException { if (oder == null) { throw new PersistenceException(); } try { OrderDataEntity orderDataEntity = this.ofOrderData(oder); List<OrderEntryDataEntity> orderEntryDataEntities = this.ofOrderEntryData(oder); this.orderMapper.delete(orderDataEntity); this.orderEntryMapper.delete(orderEntryDataEntities); } catch (Exception e) { throw new PersistenceException(e.getMessage(), e); } }4、如何使用资源库
资源库定义好以后,我们一般会在应用服务中进行引用。注意:只能在应用服务中使用,千万不要将其注入到实体或领域服务中。这种代码我见过无数次,包括在一些体量非常庞大的系统中。架构师也的确使用了充血模型,结果是一个四不像。下代码的代码展示了如何正确使用资源库,请一键三连加关注。
@Service public class OrderService { @Resource private OrderRepository orderRepository; public void cancel(Long orderId) { Order order = this.orderRepository.findBy(orderId); order.cancel(); this.orderRepository.update(order); //(1) TransactionScope transactionScope = TransactionScope.create(orderRepository);//(2) transactionScope.commit(); } }
"(1)"处的代码比较简单,因为订单对象的属性变了,所以我将其作为待变更的对象看待。那么“(2)”处的是“TransactionScope”是什么鬼?其实这是一个自己定义的类,类的名称剽窃了C#的关键字,其实就是为了简化资源库的使用,我们贴一下这个类的定义。
final public class TransactionScope { private UnitOfWork unitOfWork; private RepositoryBase[] repositoryBases; private TransactionScope(UnitOfWork unitOfWork, RepositoryBase[] repositoryBases) { this.unitOfWork = unitOfWork; this.repositoryBases = repositoryBases; if (unitOfWork != null && repositoryBases != null) { for (RepositoryBase repositoryBase : repositoryBases) { repositoryBase.setUnitOfWork(unitOfWork);//(2) } } } public static TransactionScope create(RepositoryBase... repositoryBases) { UnitOfWork unitOfWork = new SimpleUnitOfWork();//(1) TransactionScope transactionScope = new TransactionScope(unitOfWork, repositoryBases); return transactionScope; } public CommitHandlingResult commit() throws CommitmentException { if (this.unitOfWork == null) { throw new CommitmentException(OperationMessages.COMMIT_FAILED); } CommitHandlingResult result = this.unitOfWork.commit();//(3) return result; } }
代码“(1)”处我们实例化一个工作单元对象,每调用“create”的方法的时候都会实例化一次。而“create”方法中会接收多个资源库对象,当你需要更新或插入这些聚合的时候会使用同一个事务。当然,这样做只表示有这个能力不代表您应该使用,因为一个事务只能更新一个聚合,这是一个硬性且应该随时遵守规则。代码“(2)”当然就是把工作单元注入到资源库中啦,您可以看看我们前面的代码,每个资源库都持有一个工作单元的引用。 代码“(3)”其实就是在开启事务后进行数据库的更新,由工作单元完成责任代理。此刻,实体的任何变化才会反应到数据库中。
5、多种方式持久化我上面的例子所面向的全是关系型理数据库,但实现中我们可能会使用多种存储比如MongoDB、Redis、ES等。如果只是单纯的把数据进行存储,其实只需要换一种方式实现“persist*”方法。比如MongoDB使用“MongoTemplate”;ES使用“Elasticsearchtemplate”,这些都比较方便。不过有的时候我们需要将数据同时写入两种不同的存储中间件中,比如MySQL+ES。此等情况下,最好在MySQL操作完成后在应用服务中发布一个领域事件,由领域事件的订阅方将数据放到ES中,这种一种简化的CQRS模式。请尽量不要在资源库中进行双写,因为你根本无法保证写入一定是成功,除非ES和MySQL可以支持同一个事务。我觉得您就不用对此报有什么期望了,明着告诉你“没戏!”。所以说算来算去,还是Saga比较香。
还有一情况是MySQL+Redis,毕竟有的时候的确需要进行双写的。有很多方式可使用,比如:1)在DAO进行Redis和MySQL双写;2)使用上面的领域事件的方式;3)使用MySQL日志拖尾等。一般来说,如果不是特别要求数据库与Redis的强一致性,其实方式1比较好,又简单又直观,Redis写入的速度快所以对性能影响也不大。
6、聚合的性能聚合包含有整体的概念即事务整体、操作整体和业务整体。所以不论是通过资源库进行查询还是变更,都必须以聚合为单位。保存或变更还好说,一般的程序员也知道聚合所关联的信息要同时写入到数据库中,主要是他不这么干也不行,少数据业务上肯定出BUG了。对于查询特别容易犯错,有些开发打着性能的名义,直接通过资源库查询聚合中的某个子实体或值对象。费了好大劲查出来的领域模型却是个残疾人,你说亏不亏?而且你都不知道他这么干的目的是什么。执行某个业务吗?那也不能略过聚合根直接开搞啊,这么干你还要聚合根干什么。单纯的用于查询操作?直接操作DAO多爽啊,资源库不干那种转发的活,丢不起那个人。但原则并不是一成不变的,某些情况下你必须要学会妥协否则很容易陷入教条中。当聚合所包含的值对象特别多的时候,比如一个人类的X染色体包含1亿+的碱基对,你想把这些都放到一个聚合中吗?你想一次把上亿条数据一次全查出来吗?此时您也就别考虑什么整体不整体的概念了,踏实的分开单独处理比什么都强,君子都是见机行事的。
7、聚合存在层级关系时的处理写作本文的时候,为了保证某些内容的正确性以及避免被记忆偏差所影响,又重新回顾了一下IDDD这本经典书籍,搞笑的是再次读的时候发现这本书比我相像中的要薄一点,说明当时看的时候可能心理是有抗拒的,即使是正常的书也会觉得厚。它在讲资源库的时候提到了层级关系的处理,而这个问题我的确也在真实的项目中遇到过。在真正讨论这个主题之前,我们需要先进行一下思考:当领域模型存在继承关系的时候,我们在子类中应该优先扩展什么内容?数据还是行为?我在早期学习的时候比较倾向于数据,而现在更加的倾向于行为。当然,也可能是与当前的工作内容有关,导致产生这种假象。即便如此,当仔细回首过去做的东西的时候还是觉得当时的设计有欠妥当,或者说是抽象的不够。以现在眼光来看,把行为扩展作为关注的重点的确会更好一点。实际上,这也是在做面向对象设计时非常值得注意的一点。
仔细考虑一下,所谓“领域驱动设计”,这里在“领域”到底是指的什么?我觉得可以分成三个方面:业务规则、业务场景和业务主体。简单来说就是“谁在什么场景下做了什么事情”,前两者的工作是对业务实体的识别,后面的业务规则则定义了实体如何实现其行为。通过这种定义我们可以看到:业务场景规定了行为的范围,属性对行为进行了支持,两者都很重要,下得了厨房但上不得厅堂。只有行为才真实的表达了需求,让系统嗨起来。想象一下我们使用过的软件是不是都在满足用户的行为?以Word为例,你可以插入字符、保存文档、修改字体颜色……所以作为设计师的您请务必不要过分的关注数据与数据的扩展,面向行为可以反向推断出行为所需要的数据反之则没戏,我给你一个表格的数据你能告诉我是由于什么行为产出的吗?这一段内容看似与资源库无关,但为后面的内容作了铺垫。重要的是您在实践OOP的时候要注意自身的重心在哪里。
有这样一个例子:某电商系统中存在账户概念,账户包含企业账户与个人账户。个人账号包含如“身份证号”、“真实姓名”等信息;企业账号包含“营业执照号”、“企业统一社会信用代码”两类特殊信息。当然,他们也有一些共同的属性,如登录名、邮箱、密码等。针对这样的场景,很多人下意识的就会想到建立一个包含继承关系的账户体系,也就是建立一个抽象的账户类,个人账号和企业账号分别从其继承,如下图所示。在领域模型中这样设计无可厚非,假如企业账户与个人账户的“实名认证”逻辑不一样,这样的设计会同时存在数据扩展及方法扩展的情形。虽然我上面说应该将行为扩展作为重点,但不代表完全不需要数据扩展,那不是太过于极端了?我们设计的基本原则是遵循中庸的思想,这是作为设计的终极追求。很自然的去设计,该有的时候也不用藏着。
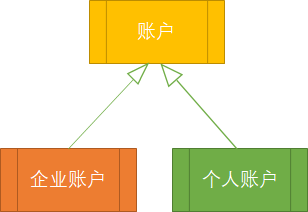
在这个案例中,BO层设计并不难,数据库层设计也有多种选择:你可以把企业账户和个人账户分别放到两张表中;也可以做一个账户基本表,再整两张扩展表分别用于企业与个人账号。最大的问题就是资源库的设计,您回看上面的代码,发现资源库接口在设计的时候需要传入领域模型类型作为泛型参数,那么在出现层级关系的时候应该传递什么类型作为泛型的参数?针对资源库这里又产生了两种选择:单一资源库和多重资源库。单一资源库是指针对账户的继承关系只设计一个资源库,直接将基类也就是上面的“账户”作为泛型类型;多重资源库就相对简单一点,针对每个子类都设计单独的资源库,将具体类型作为泛型参数。如果子类多的话,单一资源库当然要省很多的事儿,一个就搞定;相对的,多资源库就要多写好多的代码。如果您没在实际中遇到过这样的情形估计一定会优先选择A方案,是我也一样。不过现实其实很骨感的,我们来详细分析一下。
当只有一个资源库的时候,其针对的领域模型只能是账户这个抽象类。在资源库里面你需要根据某些标识符比如“账户类型”来决定到底要构建哪一种账户,这个好说,反正资源库就是干封装的事儿的。如果子类更多的是对父类行为的扩展,那在实现的时候就要简单很多,写一个通用的赋值方法即可搞定;如果涉及数据方面的不同,那没办法,你只能分别设置值了。单一资源库的复杂性还不在这里,当你需要使用资源库的返回值的时候才闹心呢。比如“findBy”方法,根据ID返回领域模型。单一资源库返回的是一个抽象类型,在使用的时候你需要分辨其具体类型到底是什么;既然是抽象类,你还需要将其强制转换成具体的类型,要不然你就没法获取到那些扩展的数据。当然,你也可以针对企业和个人账户在应用服务端分别建立对应的方法,这样也不就用过分的考虑领域模型的类型问题,不过强制转换还是有必要的。这种方式在一个人全栈开发的时候其实也可以,一旦涉及多人开发就恶心了,你需要把资源库的使用原则进行文档化或至少要进行一次培训,无形中增加了很多的工作量。毕竟来一个新人你就得培训一次,万一把你都干离职了,培训的事情能否继续传达下去也不好说。反正现在干开发的都这样,只要能完事儿就行,我死后还管他洪水滔天?再说了,项目不烂怎么能做重构?不重构怎么会有政绩?所以说您也别抱怨代码烂,烂一点吃亏的顶多是程序员,人家领导不关心那个。不过出现问题他可是找你,谁叫你写得这么烂的。
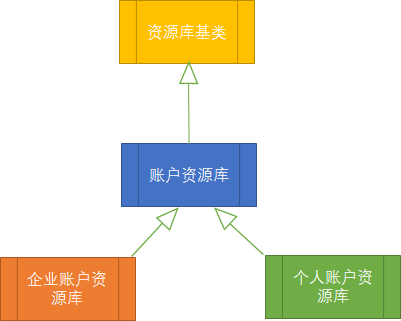
回归重点,多重资源库是我个从比较推荐的一种方式。虽然上面的案例中子类只有两个,即便是多个的时候我仍然这样坚持。虽然开发的时候工作量稍微多了一点,但用起来真的是简单啊。至少你不会遇到使用单一资源库时那种类型识别和强制转换的恶心事儿,代码也足够直观,单凭这两点我认为你就应该这么干。再说了,工作量也没多多少。不就是领域模型存在数据扩展的情况吗?我们在设计资源库的时候也设计成带继承的,如下图所示。代码写起来也灰常简单,你把共享数据的赋值过程放到账户资源库中,个性化的数据赋值操作放在两个扩展资源库中。虽然类多了那么一丢丢,但先天就能帮助你识别领域模型的类型。如果在应用服务端面把企业账户与个人账户的业务分开处理,写出的代码就更加直观了。
如果领域模型存在层级关系但并不会出现数据扩展的情况,在使用资源库的时候则不用那么费劲,一个就能搞定。客户端并不用刻意关注具体的类型到底是什么,因为子类都是对于行为的扩展,反正一个活儿只要有人干就行,领域模型的客户端其实并不需要关心谁做。这也印证了我在上面提出的观点:尽量的使用行为扩展,受益的不仅是BO层中的对象,与其有关系的底层设施也会简单很多。
总结本章干货比较多,代码量也不少。不过那些都是技术层面的东西,怎么写都行。重点你得学习资源库到底是干什么的,使用范围是什么,应当遵循哪些限制。大多数初学者都会将其作为DAO使用,目标不对会影响系统的整体结构。另外,针对面向对象设计的一些思想与实践,虽然上面写得不多,但那才是重点呢。纵观我写的一系列文章,总会时不时的穿插一些面向对象相关的内容,有时间的话再回味一下。我觉得思想要比技术更实际,后者发展太快,以我们有限的精力很难追得上,把思想整透了绝对是一种高效的学习方法。