普通人:之前分享过一期HashMap的面试题,然后有个小伙伴私信我说,他遇到了一个ConcurrentHashMap的问题不知道怎么回答。
于是,就有了这一期的内容!!
我是Mic,一个工作了14年的Java程序员,今天我来分享关于 ”ConcurrentHashMap 底层实现原理“ 这个问题,
看看普通人和高手是如何回答的!
嗯.. ConcurrentHashMap是用数组和链表的方式来实现的,嗯… 在JDK1.8里面还引入了红黑树。然后链表和红黑树是解决hash冲突的。嗯……
高手:这个问题我从这三个方面来回答:
- ConcurrentHashMap的整体架构
- ConcurrentHashMap的基本功能
- ConcurrentHashMap在性能方面的优化
-
ConcurrentHashMap的整体架构
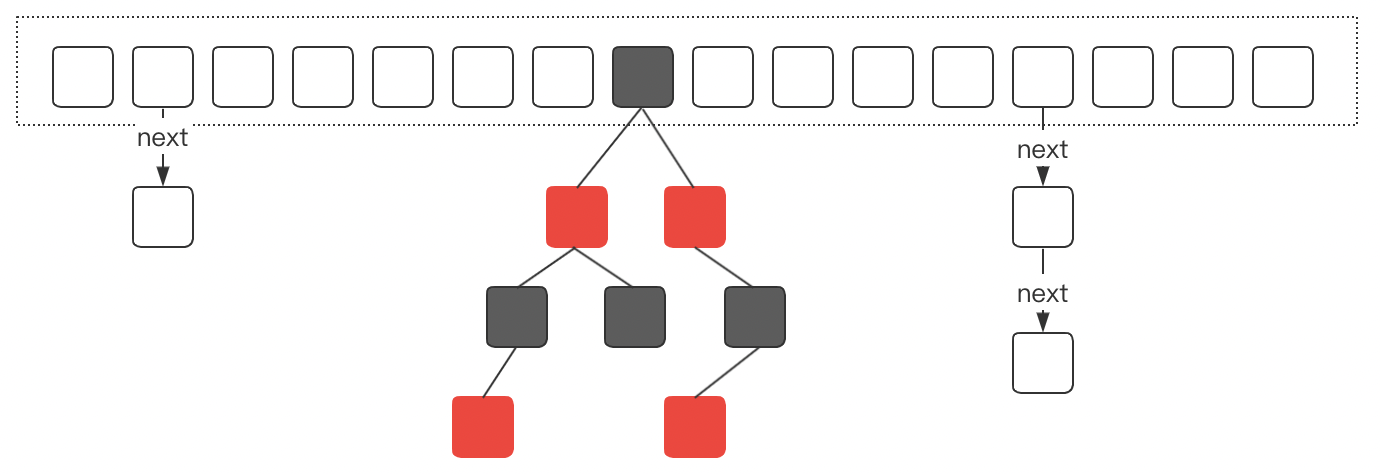
这个是ConcurrentHashMap在JDK1.8中的存储结构,它是由数组、单向链表、红黑树组成。当我们初始化一个ConcurrentHashMap实例时,默认会初始化一个长度为16的数组。由于ConcurrentHashMap它的核心仍然是hash表,所以必然会存在hash冲突问题。
ConcurrentHashMap采用链式寻址法来解决hash冲突。
当hash冲突比较多的时候,会造成链表长度较长,这种情况会使得ConcurrentHashMap中数据元素的查询复杂度变成O(n)。因此在JDK1.8中,引入了红黑树的机制。
当数组长度大于64并且链表长度大于等于8的时候,单项链表就会转换为红黑树。
另外,随着ConcurrentHashMap的动态扩容,一旦链表长度小于8,红黑树会退化成单向链表。
-
ConcurrentHashMap的基本功能
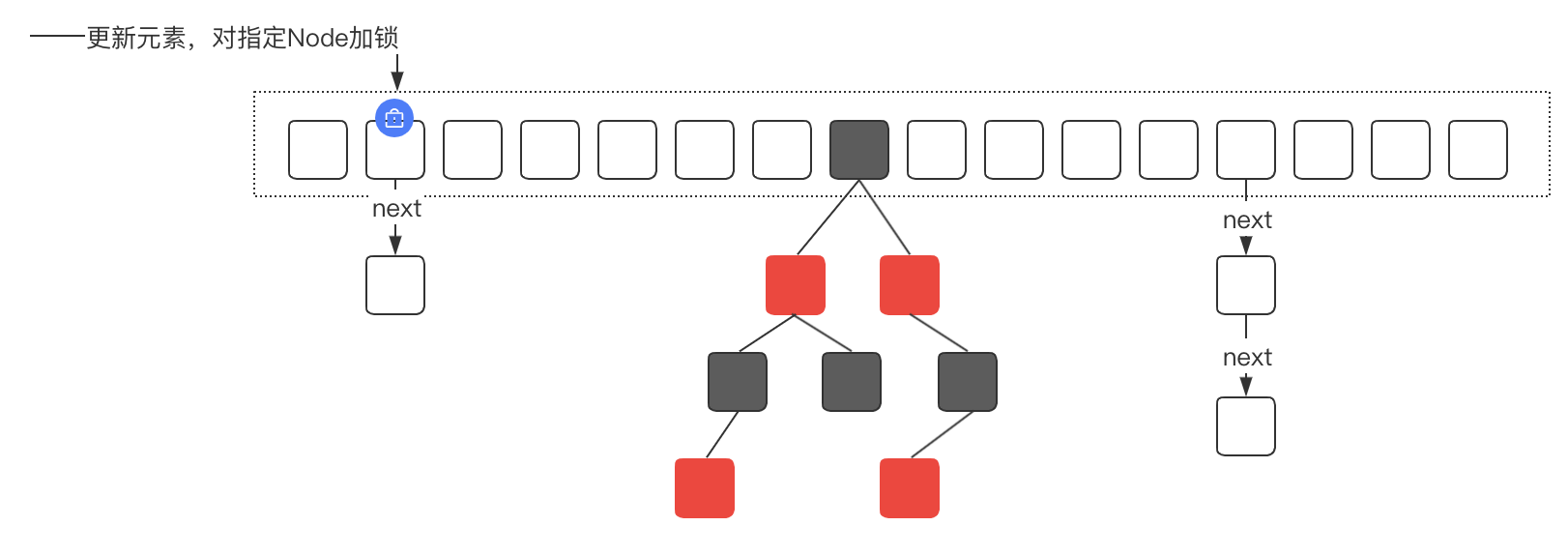
ConcurrentHashMap本质上是一个HashMap,因此功能和HashMap一样,但是ConcurrentHashMap在HashMap的基础上,提供了并发安全的实现。
并发安全的主要实现是通过对指定的Node节点加锁,来保证数据更新的安全性。
-
ConcurrentHashMap在性能方面做的优化
如果在并发性能和数据安全性之间做好平衡,在很多地方都有类似的设计,比如cpu的三级缓存、mysql的buffer_pool、Synchronized的锁升级等等。
ConcurrentHashMap也做了类似的优化,主要体现在以下几个方面:
-
在JDK1.8中,ConcurrentHashMap锁的粒度是数组中的某一个节点,而在JDK1.7,锁定的是Segment,锁的范围要更大,因此性能上会更低。
-
引入红黑树,降低了数据查询的时间复杂度,红黑树的时间复杂度是O(logn)。
-
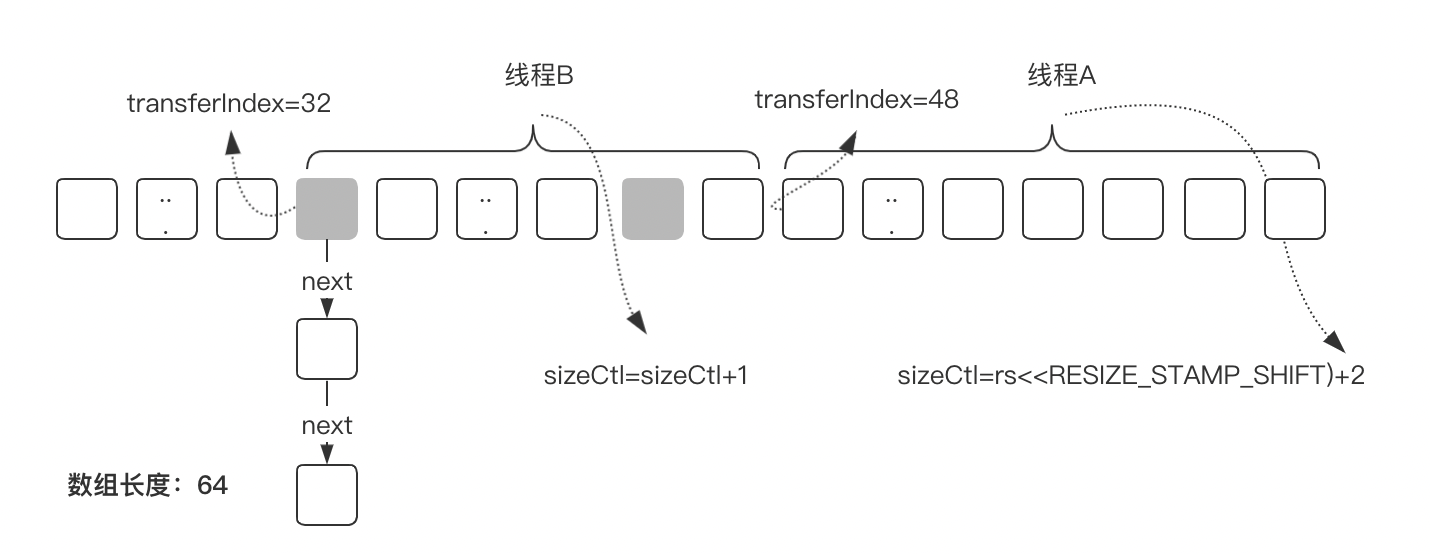
当数组长度不够时,ConcurrentHashMap需要对数组进行扩容,在扩容的实现上,ConcurrentHashMap引入了多线程并发扩容的机制,简单来说就是多个线程对原始数组进行分片后,每个线程负责一个分片的数据迁移,从而提升了扩容过程中数据迁移的效率。
-
ConcurrentHashMap中有一个size()方法来获取总的元素个数,而在多线程并发场景中,在保证原子性的前提下来实现元素个数的累加,性能是非常低的。ConcurrentHashMap在这个方面的优化主要体现在两个点:
- 当线程竞争不激烈时,直接采用CAS来实现元素个数的原子递增。
- 如果线程竞争激烈,使用一个数组来维护元素个数,如果要增加总的元素个数,则直接从数组中随机选择一个,再通过CAS实现原子递增。它的核心思想是引入了数组来实现对并发更新的负载。

-
以上就是我对这个问题的理解!
总结从高手的回答中可以看到,ConcurrentHashMap里面有很多设计思想值得学习和借鉴。
比如锁粒度控制、分段锁的设计等,它们都可以应用在实际业务场景中。
很多时候大家会认为这种面试题毫无价值,当你有足够的积累之后,你会发现从这些技术底层的设计思想中能够获得很多设计思路。
本期的普通人VS高手面试系列就到这里结束了,喜欢的朋友记得点赞收藏。
部分高手面试文档已整理,需要的小伙伴可以私信或者评论区留言。
另外,我也陆续收到了很多小伙伴的面试题,我会在后续的内容中逐步更新给到大家!
