- 1、引言
- 2、研究方法
- 2.1本次综述的贡献
- 2.2综述方法
- 2.3与现有综述的比较
- 3、行人再识别基准数据集
- 3.1基于图像的再识别数据集
- 3.2基于视频的再识别数据集
- 4、基于图像的深度再识别贡献
- 4.1深度再识别架构
- 4.1.1再识别的分类模型
- 4.1.2再识别的验证模型
- 4.1.3基于Triplet的再识别模型
- 4.1.4基于部件的再识别模型
- 4.1.5基于注意力的再识别模型
- 4.2基于重识别挑战的方法
- 4.3基于模态的重识别方法
- 4.3.1基于可见图像的重识别方法
- 4.3.2跨模态重识别方法
- 4.4跨域重识别方法
- 4.5Re-Id的度量学习方法
- 4.1深度再识别架构
- 5、基于视频的深度再识别贡献
- 6、结论和未来方向
论文地址:https://arxiv.org/abs/2012.13318
摘要:近来,行人重识别受到了研究界的广泛关注。由于其在基于安全的应用程序中的重要作用,行人重识别是与跟踪抢劫、防止恐怖袭击和其他安全关键事件相关的研究的核心。虽然在过去十年中,re-id方法取得了巨大的增长,但很少有评论文献可以理解和总结这一进展。这篇评论涉及最新的基于深度学习的行人重识别方法。虽然少数现有的re-id综述工作从单一方面分析了re-id技术,但本次综述从多个深度学习方面评估了许多re-id技术,例如深度架构类型、常见的Re-Id挑战(姿势变化、光照、视图、缩放、部分或完全遮挡、背景杂乱)、多模态Re-Id、跨域Re-Id挑战、度量学习方法和视频Re-Id贡献。该评论还包括多年来收集的几个reid基准,描述了它们的特征、大小和在它们上获得的顶级reid结果。包含最新的深度重识别作品使得这对重识别文献做出了重大贡献。最后,包括结论和未来方向。
关键词:行人重识别、深度学习、卷积神经网络、特征提取与融合
近年来,计算机视觉中基于安全和监视的应用程序已经获得了极大的普及。目前,安全监控记录视频和图像,其分析需要人工交互。调查昨天的抢劫案可能具有挑战性,因为它需要人工搜索20小时的监控视频,这些视频由容易疲劳和出错的人进行。随着分析中记录媒体的时间跨度增加,该问题很快变得不可行。机器学习的发展以及后来的深度学习方法开辟了广泛的先进可能性,这些可能性可能会导致更安全的家庭、办公室、社区、公共汽车站、机场等。可以教机器识别感兴趣的个人的想法是迈向更安全的环境的有希望的一步。
行人重识别意味着从大量记录的图像和/或视频中找到对查询图像/视频感兴趣的人。虽然机器学习算法在早期发挥了至关重要的作用,但随着基于深度学习的系统[1]的兴起,重识别方法已经取得了重大改进。近年来提出的几种基于深度学习的方法提高了匹配精度结果,显着优于基于手工特征的机器学习算法[2]、[3]。由于深度学习模型需要大量的训练样本,近年来也见证了一些大中型reid数据集的收集,用于训练和测试不同的基于深度的re-id方法。
2、研究方法本节详细介绍了本次综述的主要贡献、准备本次综述所遵循的技术以及与一些现有的深度Re-Id综述/调查的比较。
2.1本次综述的贡献这篇综述研究了基于深度学习的行人重识别。虽然行人重识别在研究界并不是一个新话题,但基于深度学习的方法由于它们在各种计算机视觉领域的巨大成功而变得越来越流行。因此,与手工制作的基于特征的方法相比,基于深度学习的方法由于其优越的特征学习能力而在Re-Id问题上处于领先地位是很自然的。

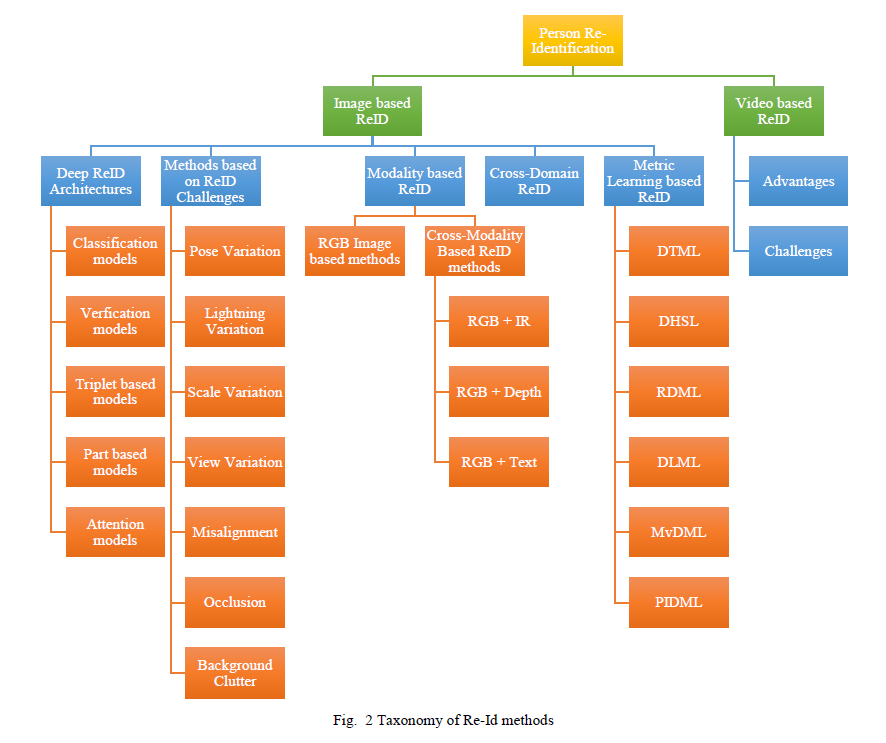
这篇综述的重点是对最近基于深度学习的Re-Id方法进行详尽的研究,指定各种基准数据集以及各种基于图像和视频的深度方法的分类,如图1所示,描述了这种方法的组织综述。近年来,基于深度学习的Re-Id方法的数量急剧增加,这篇评论引用了基于深度学习的Re-Id研究的最新进展。图2描述了本综述中基于深度学习的Re-Id方法的分类。Re-Id方法分为基于图像的方法和基于视频的方法。已经从多个方面探索了基于图像的贡献,例如所涉及的架构、常见的视觉挑战、特定于模态的方法、跨域方法和度量学习方法。
该评论的主要贡献如下:
- 对基于深度学习的行人重识别方法进行了全面的评论。
- 通过描述所提到的众多方法背后的“关键思想”,对深度Re-Id方法(表3-14)进行了详尽的研究。
- 由于深度学习方法近年来越来越受欢迎,这篇详尽的评论自动合并了对基于深度学习的Re-Id方法的最新贡献。
- 详细介绍了几个基于图像和基于视频的基准数据集,详细说明了它们的技术规格、样本带来的挑战以及报告的最佳结果。
- 从架构类型、损失函数、Re-Id挑战、数据模态、跨领域方法和度量学习方法等几个关键方面分析基于深度学习的方法,帮助读者从多个角度理解和欣赏深度Re-Id。
- 探索日益流行的基于视频的深度Re-Id方法,该方法将提供重要运动线索的时间数据与通常的视觉特征相结合。
- 这篇评论通过从架构、挑战、模式、跨领域方法、度量学习和基于视频的方法等众多角度对贡献进行分类分析,帮助读者全面而详尽地了解最近的深度Re-Id贡献。
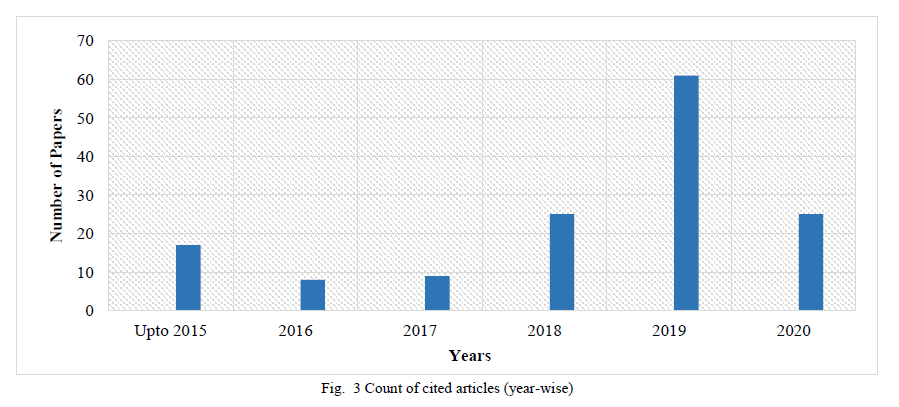
这篇评论包括来自几个知名存储库的期刊论文、会议和研讨会论文,包括IEEE Xplore、Science Direct、Springer、ACM和Google Scholar。用于搜索相关贡献的关键词包括“personre-identification”、“Re-Id”、“deep”、“deep learning”、“review”和“survey”。由于深度方法的日益普及,这一初步搜索产生了一份全面的贡献列表。IEEE Transactions、Pattern Recognition、Neurocomputing等高质量期刊和CVPR、ECCV和ICCV等顶级会议的出版物优先考虑。进行了单独的搜索以包括Re-Id数据集的贡献。最后,对包含的论文进行了分析,并制定了深度Re-Id方法的分类,如图2所示。图3显示了本评论中引用的逐年深度Re-Id贡献图表,清楚地描绘了高尺度的最近的深度Re-Id作品。
 2.3与现有综述的比较
2.3与现有综述的比较
尽管近年来深度Re-Id实施的数量呈指数级增长,但很少有评论/调查与深度Re-Id研究的增长保持同步。本节介绍了这篇评论与一些现有的基于深度学习的Re-Id调查的比较分析。与其他调查相比,本次综述包括最新的研究出版物(截至2020年)。表1展示了基于几个深度学习方面的Re-Id比较,例如架构类型、Re-Id数据集、挑战、模态、跨域方法和度量学习方法。绿色行表示存在理论分析,而橙色行表示存在表格信息。
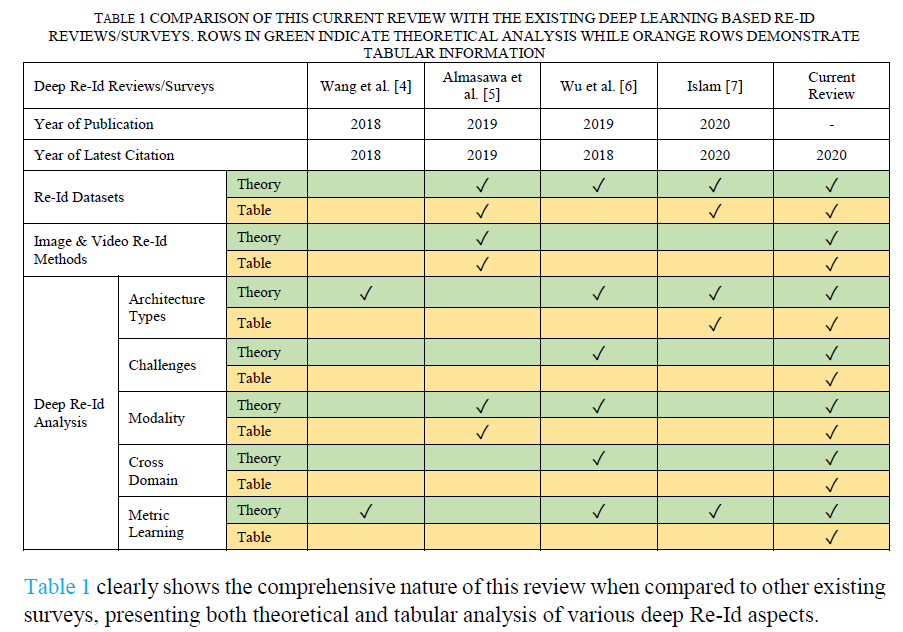
与其他现有调查相比,表1清楚地显示了本次综述的综合性质,对各种深度Re-Id方面进行了理论和表格分析。
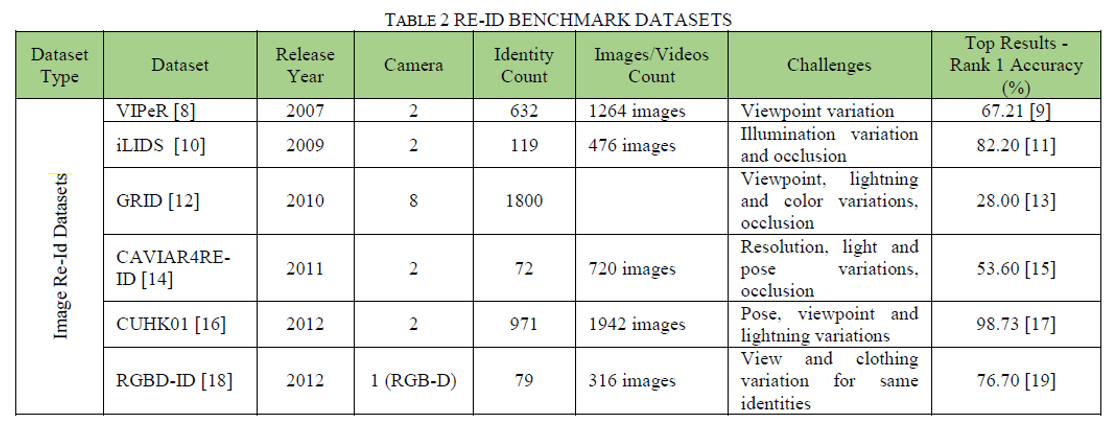
3、行人再识别基准数据集多年来已经收集了几个基准数据集来训练和测试行人重识别系统的稳健性。这些数据集可用于在识别准确性方面验证不同的重识别方法。表2.给出了关于各种re-id数据集的详细信息。

Re-Id数据集可以大致分为两种类型:基于图像的数据集和基于视频的数据集。
3.1基于图像的再识别数据集VIPeR[8]数据集已创建用于视点不变的行人识别。它包含从2个摄像头捕获的632个身份的1264张图像。iLIDS[10]数据集已在机场到达大厅获得,包含来自2个摄像头的19个身份的476张图像。GRID[12]数据集是从一个繁忙的地下火车站获取的,该火车站具有来自8个摄像头的800个身份的图像。CUHK03[21]是另一个大规模的re-id数据集,它包含使用2个摄像头收集的1360个身份的13164个图像。
Market-1501[22]、DukeMTMC-Re-Id[24]和CUHK02[20]等数据集分别使用了6,8和10个摄像头,从而增加了用于收集人物图像的摄像头视图数量。还存在一些多模式re-id数据集,例如基于RGB深度图像的RGBD-ID[18]、Kinect Re-Id[23]和同时包含RGB和红外的RegDB[25]、SYSU-MM01[27]图片。最大的基于图像的re-id数据集是从一个中型机场的6个摄像头收集的Airport[29],其中包含9651个身份的图像。图4显示了来自Market-1501数据集的一些示例图像。
 3.2基于视频的再识别数据集
3.2基于视频的再识别数据集
PRID2011[32]数据集包含从2个摄像头收集的983个身份。iLIDS-VID[36]包含来自2个摄像头的300人的600个视频。另一个流行的基于视频的re-id数据集是大规模数据集MARS[38],其中包含来自6个摄像机的1261个身份的20715个视频。视频re-id数据集的最新添加是DukeMTMC-Video Re-Id[40],包含1812个身份。
考虑到这些年来重识别数据集的增长,可以做出几个推论。首先,Re-Id数据集的数量和规模都在增长,这是一个很大的好处,因为深度模型需要大量样本才能进行有效训练。其次,这些数据集中的各种样本带来了许多重识别挑战,例如姿势、光照和规模的变化、遮挡、背景杂乱、同一个人穿着不同的衣服(大的类内差异)或不同的人穿着相似的衣服(小类间差异),从而允许深度模型学习有效的外观泛化。第三,很少有数据集是多模态的[23]、[18]导致过度依赖基于RGB图像和视频的方法。第四,在监督环境中,深度模型需要标记样本进行学习。随着数据集大小的增长,手动注释它们变得不那么可行。虽然上面讨论的大多数数据集都有手动注释的样本,但Market-1501或CUHK03等数据集使用可变形部件模型(DPM)[41]进行样本标记。
4、基于图像的深度再识别贡献本节详细介绍了最近基于图像的深度Re-Id贡献。这些贡献已根据以下方面进行分类:1)Re-Id的架构类型;2)Re-Id挑战;3)Re-Id的数据模态;4)跨域Re-Id;5)Re-Id的度量学习。这些类别不是排他性的,并且在各种实现中经常重叠,但每个类别都有不同的概念方面。
4.1深度再识别架构本节讨论用于基于深度学习的重识别的不同类型的架构。具体来说,Re-Id贡献被分类为1)分类模型2)验证模型3)基于三元组的模型4)基于部件的模型5)基于注意力的模型,如图5所示。
 4.1.1再识别的分类模型
4.1.1再识别的分类模型
分类模型(也称为识别模型)将Re-Id视为多类分类问题[42]。给定具有有限数量身份的数据集,并且每个身份都有多个样本,这些模型使用来自样本的身份标签进行训练。分类模型可以正式描述如下。让有一个