大家好,我是轩辕。
我们知道,我们平时编程写的高级语言,是经过编译器编译以后,变成了CPU可以执行的机器指令:
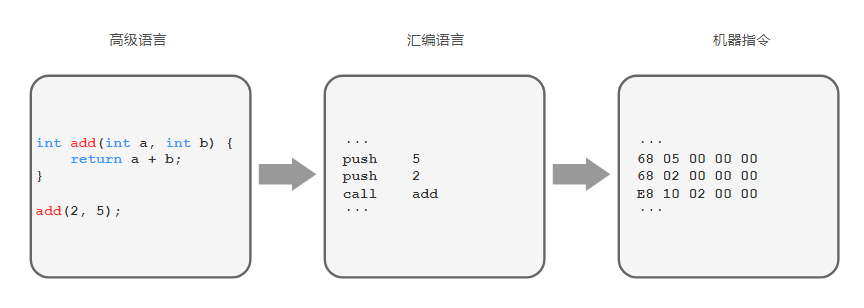
而CPU能支持的指令,都在它的指令集里面了。
很久以来,我都在思考一个问题:
CPU有没有未公开的指令?
或者说:
CPU有没有隐藏的指令?
为什么会有这个问题?
平常我们谈论网络安全问题的时候,大多数时候都是在软件层面。谈应用程序的漏洞、后端服务的漏洞、第三方开源组件的漏洞乃至操作系统的漏洞。
但很少有机会去触及硬件,前几年爆发的熔断和幽灵系列漏洞,就告诉我们,CPU也不是可信任的。
要是CPU隐藏有某些不为人知的指令,这是一件非常可怕的事情。
如果某一天,某些国家或者某些团体组织出于某种需要,利用这些隐藏的指令来发动攻击,后果不堪设想。
虽然想到过这个问题,但我一直没有付诸实践去认真的研究。
直到前段时间,极客时间的一位老师分享了一份PDF给我,解答了我的疑惑。
这份PDF内容是2017年顶级黑客大会Black Hat上的一篇报告:《us-17-Domas-Breaking-The-x86-ISA》,作者是大神:@xoreaxeaxeax,熟悉汇编的同学知道这名字是什么意思吗?

这份PDF深度研究了x86架构CPU中隐藏的指令,原报告因为是英文,看起来有些晦涩,这篇文章,我尝试用大家易懂的语言来给大家分享一下这篇非常有意思的干货。
有些人会问:真的会有隐藏指令的存在吗,CPU的指令集不是都写在指令手册里了吗?
我们以单字节指令为例,单字节的范围是0x00-0XFF,总共256种组合,Intel的指令手册中是这样介绍单字节指令的:
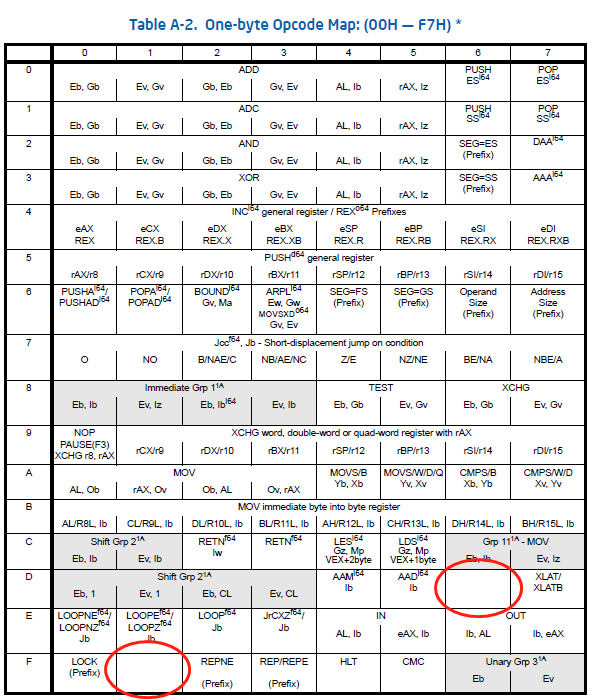
横向为单字节的高四位,纵向为单字节的低四位,顺着表格定位,可以找到每一个单字节指令的定义。比如我们常见的nop指令的机器码是0x90,就是行为9,列为0的那一格。
但是不知道你发现没有,这张表格中还有些单元格是空的,比如0xF1,那CPU拿到一个为0xF1的指令,会怎么执行呢?
指令手册没告诉你。
这篇报告的主要内容就是告诉你,如何去寻找这些隐藏的指令。
指令集的搜索空间想要找到隐藏的指令,得先明确一个问题:一条指令到底有多长,换句话说,有几个字节,我们应该在什么样的一个范围内去寻找隐藏指令。
如果指令长度是固定的,比如JVM那样的虚拟机,那问题好办,直接遍历就行了。
但问题难就难在,x86架构CPU的指令集属于复杂指令集CISC,它的指令不是固定长度的。
有单字节指令,比如:
90 nop
CC int 3
C3 ret
也有双字节指令,比如:
8B C8 mov ecx,eax
6A 20 push 20h
还有三四节、四字节、五字节···最长能有十几个字节,比如这条指令:
指令:lock add qword cs:[eax + 4 * eax + 07e06df23h], 0efcdab89h
机器码:2e 67 f0 48 818480 23df067e 89abcdef
一个字节、两个字节,甚至三个四个遍历都还能接受,4个字节最多也就42亿多种组合,对于计算机来说,也还能接受。
但越往后,容量是呈指数型增长,这种情况再去遍历,显然是不现实的。
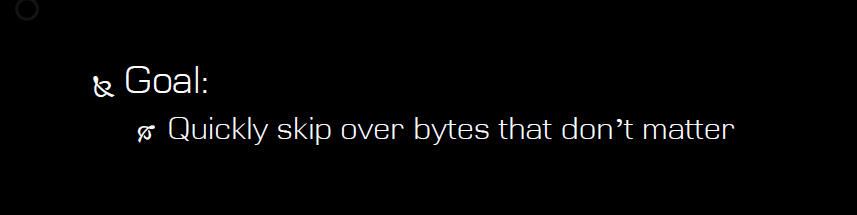
指令搜索算法这份报告中提出了一种深度优先的搜索算法:

该算法的指导思想在于:快速跳过指令中无关紧要的字节。
怎么理解这句话?
比如压栈的指令push,下面几条虽然字节序列不同,但变化的只是数据,其实都是压栈指令,对于这类指令,就没必要花费时间去遍历:
- 68 6F 72 6C 64 push 646C726Fh
- 68 6F 2C 20 77 push 77202C6Fh
- 68 68 65 6C 6C push 6C6C6568h
第一个字节68就是关键字节,后面的四个字节都是压入栈中的数据,就属于无关紧要的字节。
如果能识别出这类,快速跳过,将能够大面积减少需要遍历的搜索空间。
(PS:本文来自公众号:编程技术宇宙)
上面只是一个例子,如何能够系统化的过滤掉这类指令呢?报告中提出了一个方案:

观察指令中的有意义的字节,它们对指令的长度和异常表现会产生冲击。
又该怎么理解这句话?
还是上面那个例子,当尝试修改第一个字节68的时候,这一段二进制序列可能就完全变成了别的指令,甚至指令长度都会发生变化(比如把68改成90,那就变成了一个字节的nop指令),那么就认为这第一个字节是一个有意义的字节,修改了它会对指令的长度产生重要影响。
反之,如果修改后面字节的数据,会发现这仍然是一条5个字节的压栈指令,长度没变化,也没有其他异常行为表现与之前不同,那么就认为后面几个字节是无关紧要的字节。
在这个指导思想下,我们来看一个例子:
从下面这一段数据开始出发:

我们从两个字节的指令开始遍历:
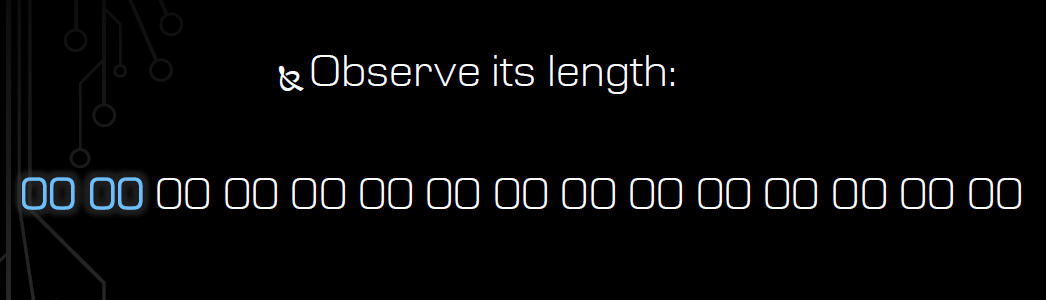
把最后那个字节的内容+1,尝试去执行它:

发现指令长度没有变化(具体怎么判断指令长度变没变,下一节会重点讨论),那就继续+1,再次尝试执行它:

一直这样加下去,直到发现加到4的时候,指令长度发生了变化,长度超过了2(但具体是多少还不知道,后文会解释):
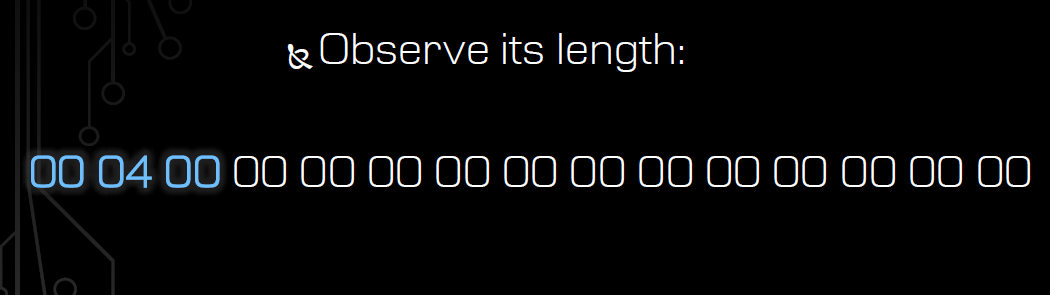
那么在这个基础上,长度增加1位,以指令长度为3的指令来继续上面的探索过程:从最后一位开始+1做起。

随着分析的深入,梳理一下指令搜索的路径图:

当某一条的最后一个字节遍历至FF时,开始往回走(就像递归,不能一直往下,总有回去的时候):

往回走一个字节,将其+1,继续再来:

按照这个思路,整个要搜索的指令空间压缩到可以接受遍历的程度:

如何判定指令长度
现在来解答前面遗留的一个问题。
上面这个算法能够工作的一个重要前提是:
我们得知道,给末尾字节+1后,有没有影响指令的长度。
要判断某个字节是不是关键字节,就得知道这个字节的内容变化,会不会影响到指令长度,所以如果无法判断长度有没有变化,那上面的算法就无从谈起了。
所以如何知道长度有没有变化呢?报告中用到了一个非常巧妙的方法。
假设我们要评估下面这一串数据,前面开头到底多少个字节是一条完整指令。

可能第一个字节0F就是一条指令。
也可能前面两个字节0F 6A是一条指令。
还可能前面五个字节0F 6A 60 6A 79 6D是一条指令。
到底是什么情况,我们不知道,让我们用程序来尝试推导出来。
准备两个连续的内存页面,前面一个拥有可执行的权限,后面一个不能执行。

记住:当CPU发现指令位于不可执行的页面中时,它会抛异常!
现在,在内存中这样放置上面的数据流:第一个字节放在第一个页面的末尾位置,后面在字节放在第二个不可执行的页面上。

然后JMP到这条指令的地址,尝试去执行它,CPU中的译码器开始译码:

译码器译码发现是0F,不是单字节指令,还需要继续分析后面的字节,继续取第二个字节:

但注意,第二个字节是位于不可执行的页面,CPU检查发现后会抛出页错误异常:

如果我们发现CPU抛了异常,并且异常的地址指向了第二个页面的地址,那么我们可以断定:这条指令的长度肯定不止一个字节。

既然不止一个字节,那就往前挪一下,放两个字节在可执行页面,从第三个字节开始放在不可执行页面,继续这个过程。

继续上面这个过程,放三个字节在可执行页面:

四个:

当放了四个字节在可执行页面之后,事情发生了变化:
指令可以执行了!虽然也抛了异常(因为天知道这是个什么指令,会抛什么异常),但页错误的地址不再是第二个页面的地址了!

有了这个信号,我们就知道,前面4个字节是一条完整的指令:

挖掘隐藏指令
现在核心算法和判断指令长度的方法都介绍完了,可以正式来开挖,挖出那些隐藏的指令了!
以一台Intel Core i7的CPU为目标,来挖一挖:

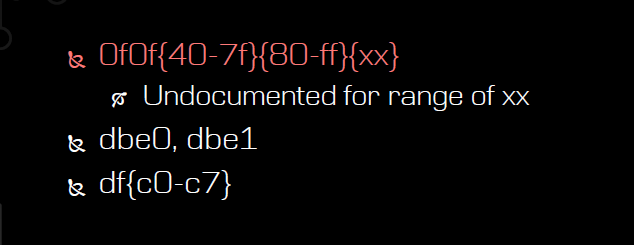
挖掘成果,收获颇丰:


这些都是Intel指令集手册中未交待,但CPU却能执行的指令。
然后是AMD Athon的CPU:

挖掘成果:
那这些隐藏的指令是做什么的呢?
有些已经被逆向工程分析了。
还有的就是毫无记录,只有Intel/AMD自己人知道了,谁知道它们用这些指令是来干嘛的?
软件即便是开源都能爆出各种各样的问题,何况是黑盒一样的硬件。
CPU作为计算机中的基石,它要是出了问题,那可是大问题。
我不是阴谋论,害人之心不可有,但防人之心不可无。
看完这些,我对国产、安全、自主可控这几个字的理解又加深了一层。
各位朋友,你对这些隐藏指令怎么看?欢迎评论区分享你的观点。