最近一个学员去滴滴面试,在第二面的时候遇到了这个问题:
"请你简单说一下Kafka的零拷贝原理"
然后那个学员努力在大脑里检索了很久,没有回答上来。
那么今天,我们基于这个问题来看看,普通人和高手是如何回答的!
普通人的回答:
零拷贝是一种减少数据拷贝的机制,能够有效提升数据的效率
高手的回答:
在实际应用中,如果我们需要把磁盘中的某个文件内容发送到远程服务器上,如图
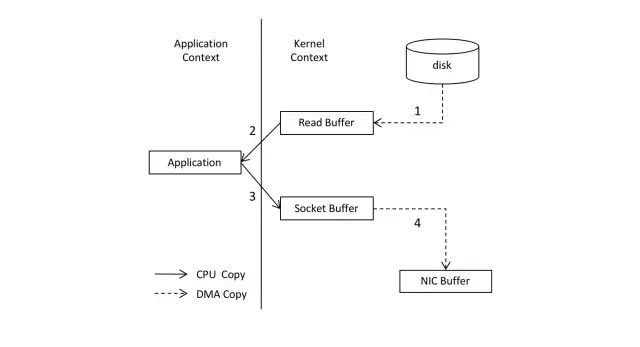
那么它必须要经过几个拷贝的过程:
- 从磁盘中读取目标文件内容拷贝到内核缓冲区
- CPU控制器再把内核缓冲区的数据赋值到用户空间的缓冲区中
- 接着在应用程序中,调用
write()方法,把用户空间缓冲区中的数据拷贝到内核下的Socket Buffer中。 - 最后,把在内核模式下的SocketBuffer中的数据赋值到网卡缓冲区(NIC Buffer)
- 网卡缓冲区再把数据传输到目标服务器上。
在这个过程中我们可以发现,数据从磁盘到最终发送出去,要经历4次拷贝,而在这四次拷贝过程中,有两次拷贝是浪费的,分别是:
- 从内核空间赋值到用户空间
- 从用户空间再次复制到内核空间
除此之外,由于用户空间和内核空间的切换会带来CPU的上线文切换,对于CPU性能也会造成性能影响。
而零拷贝,就是把这两次多于的拷贝省略掉,应用程序可以直接把磁盘中的数据从内核中直接传输给Socket,而不需要再经过应用程序所在的用户空间,如下图所示。
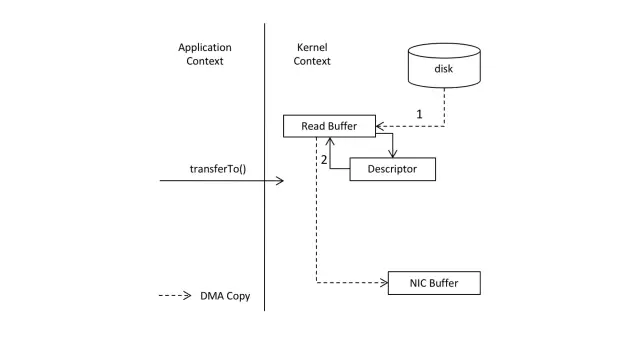
零拷贝通过DMA(Direct Memory Access)技术把文件内容复制到内核空间中的Read Buffer。
接着把包含数据位置和长度信息的文件描述符加载到Socket Buffer中,DMA引擎直接可以把数据从内核空间中传递给网卡设备。
在这个流程中,数据只经历了两次拷贝就发送到了网卡中,并且减少了2次cpu的上下文切换,对于效率有非常大的提高。
所以,所谓零拷贝,并不是完全没有数据赋值,只是相对于用户空间来说,不再需要进行数据拷贝。对于前面说的整个流程来说,零拷贝只是减少了不必要的拷贝次数而已。
在程序中如何实现零拷贝呢?
- 在Linux中,零拷贝技术依赖于底层的sendfile()方法实现
- 在Java中,FileChannal.transferTo() 方法的底层实现就是 sendfile() 方法。
除此之外,还有一个 mmap 的文件映射机制
它的原理是:将磁盘文件映射到内存, 用户通过修改内存就能修改磁盘文件。使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。
以上就是我对于Kafka中零拷贝原理的理解
总结
本期的普通人VS高手面试系列就到这里结束了。
本次的面试题涉及到一些计算机底层的原理,基本上也是业务程序员的知识盲区。
但我想提醒大家,做开发其实和建房子一样,要想楼层更高更稳,首先地基要打牢固。
另外,如果你有任何面试相关的疑问,欢迎评论区给我留言。
我是Mic,一个工作了14年的Java程序员,咱们下篇文章再见。