- 摘要
- 1、引言
- 2、提出的方法
- 2.1 CentroidTripletloss
- 2.2 聚合表示
- 3、实验
- 3.1 数据集
- 3.2 应用细节
- 3.3 Fashion检索结果
- 3.4 行人再识别结果
- 3.5 内存使用和推理时间
- 4、总结
论文地址:https://openaccess.thecvf.com/content/ICCV2021/html/Wong_Persistent_Homology_Based_Graph_Convolution_Network_for_Fine-Grained_3D_Shape_ICCV_2021_paper.html
代码:https://github.com/mikwieczorek/centroids-reid 摘要
图像检索任务包括从一组图库(数据库)图像中找到与查询图像相似的图像。这样的系统用于各种应用,例如行人重新识别(ReID)或视觉产品搜索。尽管检索模型正在积极发展,但它仍然是一项具有挑战性的任务,主要是由于视角、光照、背景杂波或遮挡的变化引起的类内方差大,而类间方差可能相对较低。当前的大部分研究都集中在创建更强大的特征和修改目标函数上,通常基于TripletLoss。一些作品尝试使用类的质心/代理表示来缓解与TripletLoss一起使用的计算速度和硬样本挖掘问题。然而,这些方法仅用于训练并在检索阶段被丢弃。在本文中,我们建议在训练和检索期间都使用平均质心表示。这种聚合表示对异常值更稳健,并确保更稳定的特征。由于每个类都由单个嵌入类质心表示-检索时间和存储需求都显着减少。由于减少了候选目标向量的数量,聚合多个嵌入导致搜索空间显着减少,这使得该方法特别适用于生产部署。在两个ReID和时尚检索数据集上进行的综合实验证明了我们的方法的有效性,它优于当前最先进的方法。我们建议将质心训练和检索作为时尚检索和ReID应用程序的可行方法。
1、引言实例检索是将查询图像中的对象与画廊集中的图像表示的对象进行匹配的问题。检索系统的应用涵盖行人/车辆重新识别、人脸识别、视频监控、显式内容过滤、医学诊断和时尚检索。
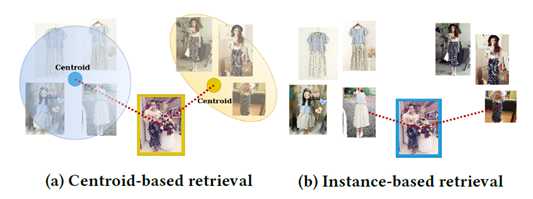 图1:基于质心和基于实例的检索的比较。虚线表示查询图像(彩色框)与每个类别的最近邻之间的距离。a)质心计算为属于每个类别的所有样本(阴影图像)的平均值。查询被分配了最近质心的类,这是正确的“黄金”类。b)计算所有样本与查询之间的距离。它被错误地分配了“蓝色”类,因为蓝色类样本是它最近的邻居。
图1:基于质心和基于实例的检索的比较。虚线表示查询图像(彩色框)与每个类别的最近邻之间的距离。a)质心计算为属于每个类别的所有样本(阴影图像)的平均值。查询被分配了最近质心的类,这是正确的“黄金”类。b)计算所有样本与查询之间的距离。它被错误地分配了“蓝色”类,因为蓝色类样本是它最近的邻居。
大多数现有的实例检索解决方案都使用深度度量学习方法[1,3,6,7,13,16],其中训练深度学习模型将图像转换为向量表示,以便来自同一类的样本接近彼此。在检索阶段,查询嵌入对所有图库嵌入进行评分,并返回最相似的嵌入。直到最近,很多工作都使用分类损失来训练检索模型[8,14,15,17,20]。目前大多数作品都使用comparative/ranking losses,而TripletLoss是最广泛使用的方法之一。然而,最先进的解决方案通常将比较损失与辅助损失(如分类或中心损失)结合起来[5、7、12、13、16]。
尽管TripletLoss优于大多数其他方法,但它存在许多工作[2,16,18,21]表明的问题:1)硬负采样是创建训练批次的主要方法,该批次中仅包含信息量大的三元组,但它可能会导致局部最小值不佳并阻止模型达到最佳性能[2,18];2)硬负采样计算量大,因为需要计算批次中所有样本之间的距离[2,16];3)TripletLoss由于硬负采样和点对点损失的性质而容易出现异常值和噪声标签[16,18]
为了缓解TripletLoss的点对点性质引起的问题,提出了point-to-set/point-to-centroid公式,其中测量样本和代表类的原型/质心之间的距离。质心是每个项目的多个表示的聚合。质心方法导致每个项目嵌入一个,从而降低内存和存储需求。有许多方法可以研究原型/质心公式,它们的主要优点如下:1)更低的计算成本[2,16],甚至是线性复杂度而不是三次[2];2)对异常值和噪声标签具有更高的鲁棒性[16,18];3)更快的训练[11];4)与标准点对点三元组损失相当或更好的性能[5,11,16]。
我们建议更进一步,使用基于质心的方法进行训练和推理,并将其应用于时尚检索和人员重新识别。我们通过使用我们称为CentroidTripletLoss的新损失函数来增强当前最先进的时尚检索模型[13]来实现我们的基于质心的模型。基线模型有许多同时优化的损失,它们解释了检索问题的各个方面。因此,可以很容易地添加一个额外的基于质心的损失,以修正一个反复出现的问题:对对象画廊的可变性缺乏鲁棒性。质心是通过对图像表示的简单平均来计算的。我们表明,这种简单的模型修正可以降低请求的延迟并降低基础设施成本,同时在各种评估协议、数据集和域中产生新的最先进的结果。我们还讨论了为什么与标准的基于图像的方法相比,这种检索问题的表述是可行和有利的。
这项工作的贡献有四个:
•我们引入了CentroidTripletLoss-一种用于实例检索任务的新损失函数•我们建议在检索过程中使用类质心作为表示。
•我们通过彻底的实验表明,基于质心的方法在不同的数据集和领域(时尚检索和人员重新识别)中建立了新的最先进的结果。
•我们表明,与标准实例级方法相比,基于质心的检索任务方法可显着加快推理速度并节省存储空间。
图像检索任务旨在找到与查询图像最相似的对象。在时尚检索和人物重新识别中,它通常是在实例级别的基础上完成的:每个查询图像都针对图库中的所有图像进行评分。如果一个对象分配了多个图像(例如,在可变照明条件下来自多个视点的照片),则每个图像都被单独处理。因此,同一对象可能会在排名结果中出现多次。这样的协议可能是有益的,因为它允许匹配在类似情况下以类似角度拍摄的图像,描绘对象的相同部分或特写细节。另一方面,优势很容易变成劣势,因为完全不同对象的细节照片可能与查询图像中的细节相似,从而导致错误匹配。
我们建议使用所有可用样本的聚合项目表示。这种方法产生了一个鲁棒的表示,它不太容易受到单图像错误匹配的影响。使用聚合表示,每个项目由单个嵌入表示,从而显着减少搜索空间,节省内存并显着减少检索时间。除了在检索过程中计算效率更高之外,与非基于质心的方法相比,基于质心的方法还改善了检索结果。请注意,在基于质心的设置中训练模型不会将评估协议限制为仅质心评估,而且还改进了实例级评估的典型设置中的结果。
2.1 CentroidTripletlossTripletLoss最初适用于锚图像