大家好,我是【架构摆渡人】,一只十年的程序猿。这是分库分表系列的第一篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。
其实这个系列有录过视频给大家学习,但很多读者反馈说看视频太慢了。也不好沉淀为文档资料,希望能有一系列文字版本的讲解,要用的时候可以快速浏览关键的知识点。那么它就来了,我再花点时间写成几篇连续的文章供大家学习。
在实际业务实践过程中,垂直拆分和水平拆分都必须用才行。拆分之前我们先来了解有哪些常用的拆分方式。
分表算法这么多,我该怎么选? 时间按时间拆分,适合一些与归档数据的需求,然后查询的场景基本上都是最新的数据。如果说你的业务规模不是很固定,就会导致每个时间范围内的数据不一样,数据倾斜比较严重,那么查询比较麻烦,需要进行遍历多库多表才能拿到最终想要的结果。
时间拆可以以天,周,月,年等进行,具体采用哪种取决于你每天的数据量。假设我们一个月一张表,那么就可以创建 table_202201, table_202202, table_202203 等,插入的时候就根据当前时间匹配对应的表。
范围适用于数字类型的字段进行分表,一般像自增的主键ID。其实范围跟时间的拆分有点类似,比如id 1~10000的在table1, 10001~20000的在table2,依次类推下去。
取模用的比较多,直接用ID取模即可,比如 userId % 10=你的数据在哪个表,这样就可以将同一个用户的数据放在同一张表中,查询的时候就不用同时查询多个表获取结果。但是问题也很明显,就是会出现数据倾斜的问题,比如某个用户的数据就是很多。其次还会出现热点问题,比如某个用户的访问量就是很大,SQL就会一直落在某张表里面。
到底该怎么拆分呢? 多拆库,少拆表首先垂直拆分肯定是要的,要根据业务把对应的库拆出来,比如我们拆出了一个订单库。然后针对订单库进行水平拆分。
无论我们用上面讲的哪种拆分方式,都是把单库单表拆分成多库多表。假设我们将订单库的订单表拆分成5库5表,总共也就是50张订单表。如下图所示:
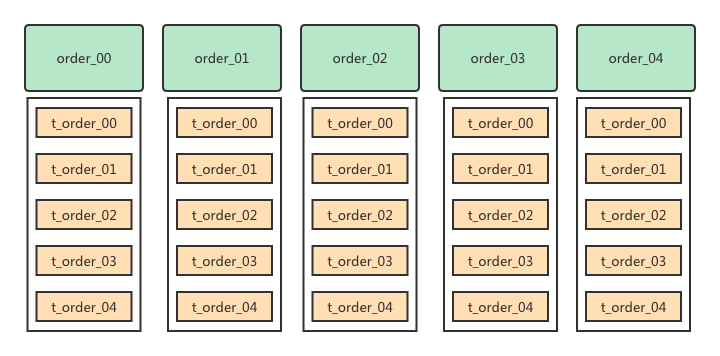
这里的5个数据库,你可以根据情况来决定是否需要5个独立的数据库实例。如果前期查询量没那么大,并且想节省成本的话,那么可以将order_00,order_01放在一个实例上。order_02,order_03,order_04放在一个实例上。这样你就只需要2个数据库实例。
假设过了一段时间,磁盘不够了,或者说查询压力太大了。那么你可以将其他的数据移到一个新的实例上面去,此时分库分表的算法是没有改变的,只需要程序中将数据库的链接地址改下就搞定了。
所以这里也得出一个比较有价值的经验:就是尽量多拆库,少拆表。因为表多了其实数据还是在一个服务器上面,请求量还是在一个服务器上面。但是你库拆的比较多,是可以变成独立的数据库实例,这个数据库部署在独立的服务器上,大家懂我意思了吧。
合理分类第二个经验值就是:合理分类,因为订单库里面还有一些表可能数据量没那么大,其实没必要拆分成这么多库和表。这种情况通常可以单独用一个库将这些表放在一起。在我们的应用中就需要配置2个数据源。
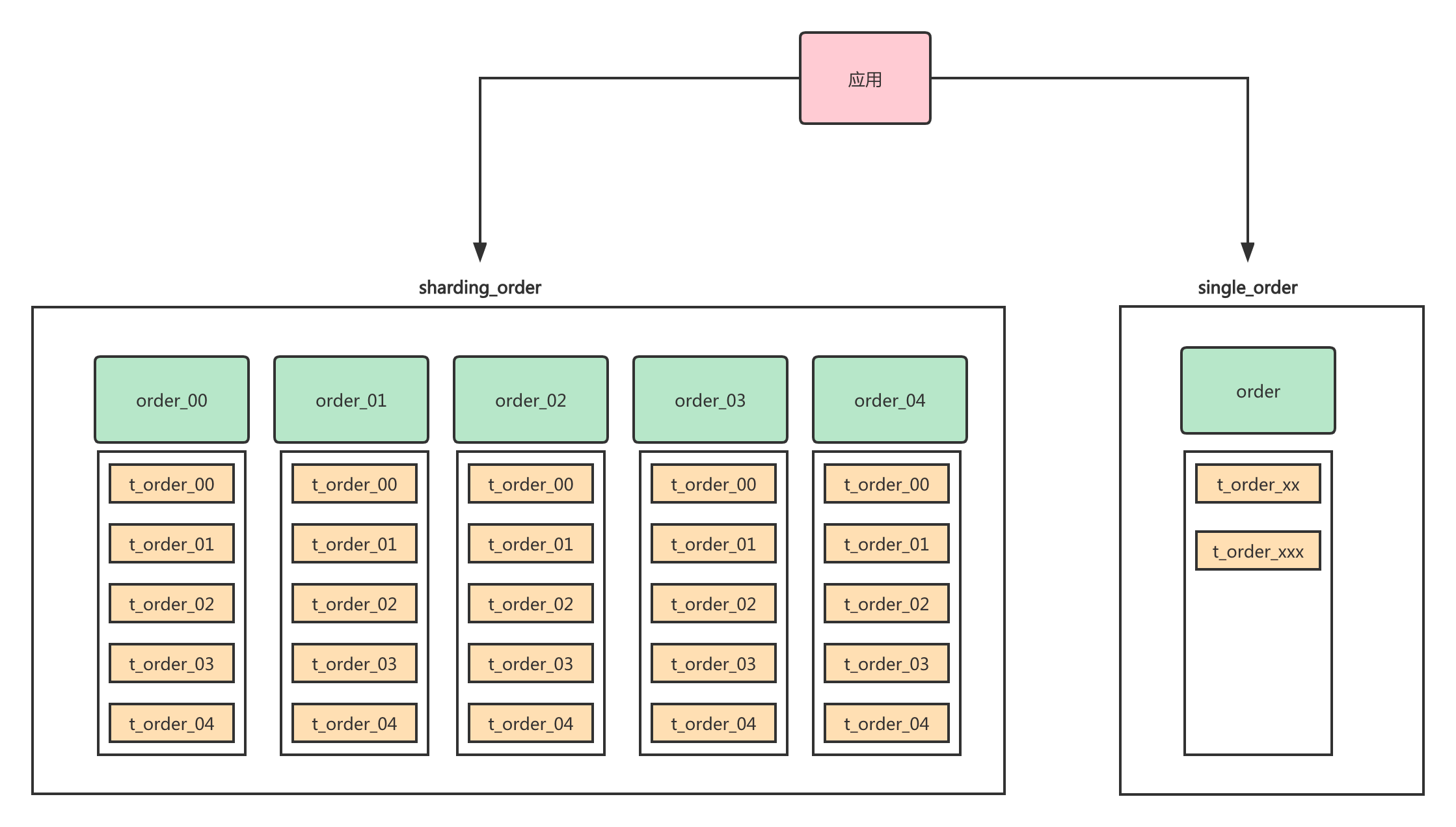
分类需要注意一点,除了表的数据量作为划分条件,另一个条件就是这个表跟分表的那些表是否会在一个事务中操作,如果有事务需求,也需要考虑进去。如果你放到单独的库中去了,就没办法用数据库的事务。
多数据源的配置一般我们在项目中都用一个数据源,而且现在用Spring Boot还都是自动装配的,突然要搞多个数据源好像不知道从何下手,这里给大家一点思路。
可以直接采用配置类的形式进行配置,无非就是配置多个DataSource,sqlSessionFactory,sqlSessionTemplate罢了。
我们举个例子:
@MapperScan(sqlSessionFactoryRef = "sqlSessionFactoryOrder", basePackages = {"jiagoubaiduren.mapper.order"})
@Configuration
public class OrderMybatisAutoConfiguration {
private static final ResourcePatternResolver resourceResolver = new PathMatchingResourcePatternResolver();
private final String[] MAPPER_XML_PATH = new String[] {"classpath*:ordermapper/*.xml"};
@Bean(name = "dataSourceOrder")
@Primary
@ConfigurationProperties("spring.datasource.order")
public DataSource dataSourceOrder(){
return DruidDataSourceBuilder.create().build();
}
@Bean(name = "sqlSessionFactoryOrder")
@Primary
public SqlSessionFactory sqlSessionFactoryOrder() throws Exception {
SqlSessionFactoryBean factory = new SqlSessionFactoryBean();
factory.setDataSource(dataSourceOrder());
factory.setVfs(SpringBootVFS.class);
factory.setMapperLocations(resolveMapperLocations());
return factory.getObject();
}
@Bean(name = "sqlSessionTemplateOrder")
@Primary
public SqlSessionTemplate sqlSessionTemplateOrder() throws Exception {
return new SqlSessionTemplate(sqlSessionFactoryOrder());
}
public Resource[] resolveMapperLocations() {
return Stream.of(Optional.ofNullable(MAPPER_XML_PATH).orElse(new String[0]))
.flatMap(location -> Stream.of(getResources(location))).toArray(Resource[]::new);
}
private Resource[] getResources(String location) {
try {
return resourceResolver.getResources(location);
} catch (IOException e) {
return new Resource[0];
}
}
}
里面其实指定了对应的mapper文件路径和包路径,如果要配置另一个数据源,复制一份,然后包路径改下就可以了。
总结分库分表主要是用于解决高并发,大数据量的场景,如果没达到这个条件,千万不要去做分库分表。这会使复杂度变高,成本变高,当然你是能够收货一些实战经验。
既然要分库分表,那么必然需要一个中间件来支撑,不可能通过硬编码的形式去进行SQL的路由,下篇文章将为你分析用什么形式的中间件来实现分库分表比较合适。
原创:架构摆渡人(公众号ID:jiagoubaiduren),欢迎分享,转载请保留出处。
本文已收录至学习网站 http://cxytiandi.com/ ,里面有Spring Boot, Spring Cloud,分库分表,微服务,面试等相关内容。