1、默认的分词器 关于分词器,前面的博客已经有介绍了,链接: ElasticSearch7.3 学习之倒排索引揭秘及初识分词器(Analyzer)。这里就只介绍默认的分词器 standard analyzer 2、 修改分词器的设
关于分词器,前面的博客已经有介绍了,链接:ElasticSearch7.3 学习之倒排索引揭秘及初识分词器(Analyzer)。这里就只介绍默认的分词器standard analyzer
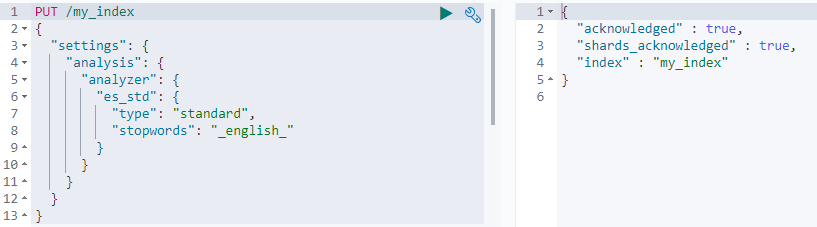
2、 修改分词器的设置首先自定义一个分词器es_std。启用english停用词token filter
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}返回:
接下来开始测试两种不同的分词器,首先是默认的分词器
GET /my_index/_analyze
{
"analyzer": "standard",
"text": "a dog is in the house"
}返回结果
{ "tokens" : [ { "token" : "a", "start_offset" : 0, "end_offset" : 1, "type" : "<ALPHANUM>", "position" : 0 }, { "token" : "dog", "start_offset" : 2, "end_offset" : 5, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "is", "start_offset" : 6, "end_offset" : 8, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "in", "start_offset" : 9, "end_offset" : 11, "type" : "<ALPHANUM>", "position" : 3 }, { "token" : "the", "start_offset" : 12, "end_offset" : 15, "type" : "<ALPHANUM>", "position" : 4 }, { "token" : "house", "start_offset" : 16, "end_offset" : 21, "type" : "<ALPHANUM>", "position" : 5 } ] }
可以看到就是简单的按单词进行拆分,在接下来测试上面自定义的一个分词器es_std
GET /my_index/_analyze
{
"analyzer": "es_std",
"text":"a dog is in the house"
}返回:
{
"tokens" : [
{
"token" : "dog",
"start_offset" : 2,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "house",
"start_offset" : 16,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 5
}
]
}可以看到结果只有两个单词了,把停用词都给去掉了。
3、定制化自己的分词器首先删除掉上面建立的索引
DELETE my_index然后运行下面的语句。简单说下下面的规则吧,首先去除html标签,把&转换成and,然后采用standard进行分词,最后转换成小写字母及去掉停用词a the,建议读者好好看看,下面我也会对这个分词器进行测试。
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [
"&=> and"
]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [
"the",
"a"
]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"&_to_and"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"my_stopwords"
]
}
}
}
}
}返回
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_index"
}老规矩,测试这个分词器
GET /my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "tom&jerry are a friend in the house, <a>, HAHA!!"
}结果如下:
{
"tokens" : [
{
"token" : "tomandjerry",
"start_offset" : 0,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "are",
"start_offset" : 10,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "friend",
"start_offset" : 16,
"end_offset" : 22,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "in",
"start_offset" : 23,
"end_offset" : 25,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "house",
"start_offset" : 30,
"end_offset" : 35,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "haha",
"start_offset" : 42,
"end_offset" : 46,
"type" : "<ALPHANUM>",
"position" : 7
}
]
}最后我们可以在实际使用时设置某个字段使用自定义分词器,语法如下:
PUT /my_index/_mapping/
{
"properties": {
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}