 线程池中维护多个线程,当收到调度任务时可以避免创建线程直接执行,并以此降低服务资源的消耗,把相对不确定的并发任务管理在相对确定的线程池中,提高系统服务的稳定性。
一、线程池简介
1、池化思想
线程池中维护多个线程,当收到调度任务时可以避免创建线程直接执行,并以此降低服务资源的消耗,把相对不确定的并发任务管理在相对确定的线程池中,提高系统服务的稳定性。
一、线程池简介
1、池化思想
在项目工程中,基于池化思想的技术应用很多,例如基于线程池的任务并发执行,中间件服务的连接池配置,通过对共享资源的管理,降低资源的占用消耗,提升效率和服务性能。
池化思想从直观感觉上理解,既有作为容器的存储能力(持续性的承接),也要具备维持一定量的储备能力(初始化的提供),同时作为容器又必然有大小的限制,下面通过这个基础逻辑来详细分析Java中的线程池原理。
2、线程池首先熟悉JVM执行周期的都知道,在内存中频繁的创建和销毁对象是很影响性能的,而线程作为进程中运行的基本单位,通过线程池的方式重复使用已创建的线程,在任务执行动作上避免或减少线程的频繁创建动作。
线程池中维护多个线程,当收到调度任务时可以避免创建线程直接执行,并以此降低服务资源的消耗,把相对不确定的并发任务管理在相对确定的线程池中,提高系统服务的稳定性。下文基于JDK1.8围绕ThreadPoolExecutor类深入分析。

- Executor 接口
源码注释解读:将来会执行命令,任务提交和执行两个动作会被解耦,传入Runnable任务对象即可,线程池会执行相应调度和任务处理。Executor虽然是ThreadPoolExecutor线程池的顶层接口,但是其本身只是抽象了任务的处理思想。
- ExecutorService 接口
扩展Executor接口,单个或批量的给任务的执行结果生成Future,并增添任务中断或终止的管理方法。
- AbstractExecutorService 抽象类
提供对ExecutorService接口定义的任务执行方法(submit,invokeAll)等默认实现,提供newTaskFor方法用于构建RunnableFuture对象。
- ThreadPoolExecutor 类
维护线程池生命周期,管理线程和任务,通过相应调度机制实现任务的并发执行。
2、基本案例示例中创建了一个简单的butte-pool线程池,设置4个核心线程执行任务,队列容器设置256大小;在实际业务中,对于参数设定需要考量任务执行时间,服务配置,测试数据等。
public class ThrPool implements Runnable {
private static final Logger logger = LoggerFactory.getLogger(ThrPool.class) ;
/**
* 线程池管理,ThreadFactoryBuilder出自Guava工具库
*/
private static final ThreadPoolExecutor DEV_POOL;
static {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("butte-pool-%d").build();
DEV_POOL = new ThreadPoolExecutor(0, 8,60L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(256),threadFactory, new ThreadPoolExecutor.AbortPolicy());
DEV_POOL.allowCoreThreadTimeOut(true);
}
/**
* 任务方法
*/
@Override
public void run() {
try {
logger.info("Print...Job...Run...;queue_size:{}",DEV_POOL.getQueue().size());
Thread.sleep(5000);
} catch (Exception e){
e.printStackTrace();
}
}
}
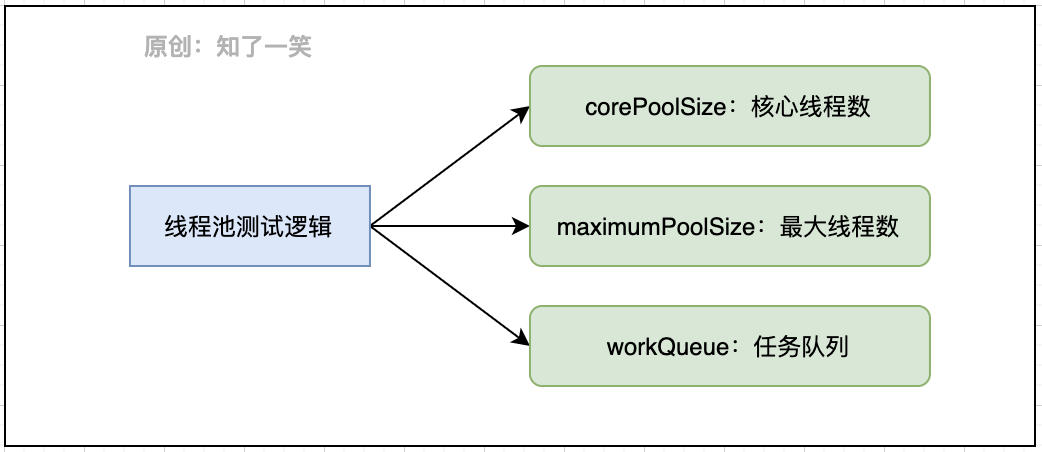
通过对上述线程池核心参数的不断调整,以及控制任务执行时间的长短,尤其可以设置一些参数的极端值,观察任务执行的效果,可以初步感知线程池的运行特点,下面围绕该案例展开详细的分析。
3、构造方法在ThreadPoolExecutor类中提供多个构造方法,以满足不同场景下线程池的构造需求,这里需要描述几个注意事项:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory)
- 从构造方法的判断中,corePoolSize的大小允许设置为0,在分析任务执行时再细说影响;
- 线程池创建后,不会立即启动核心线程,通常会等到任务提交的时候再去启动;或者主动执行
prestartCoreThread||prestartAllCoreThreads方法; - 在当前版本的JDK中,CoreThread核心线程也是允许超时终止掉的,避免线程长时间闲置;
- 如果允许核心线程超时终止,该方法会校验keepAliveTime必须大于0,否则抛出异常;
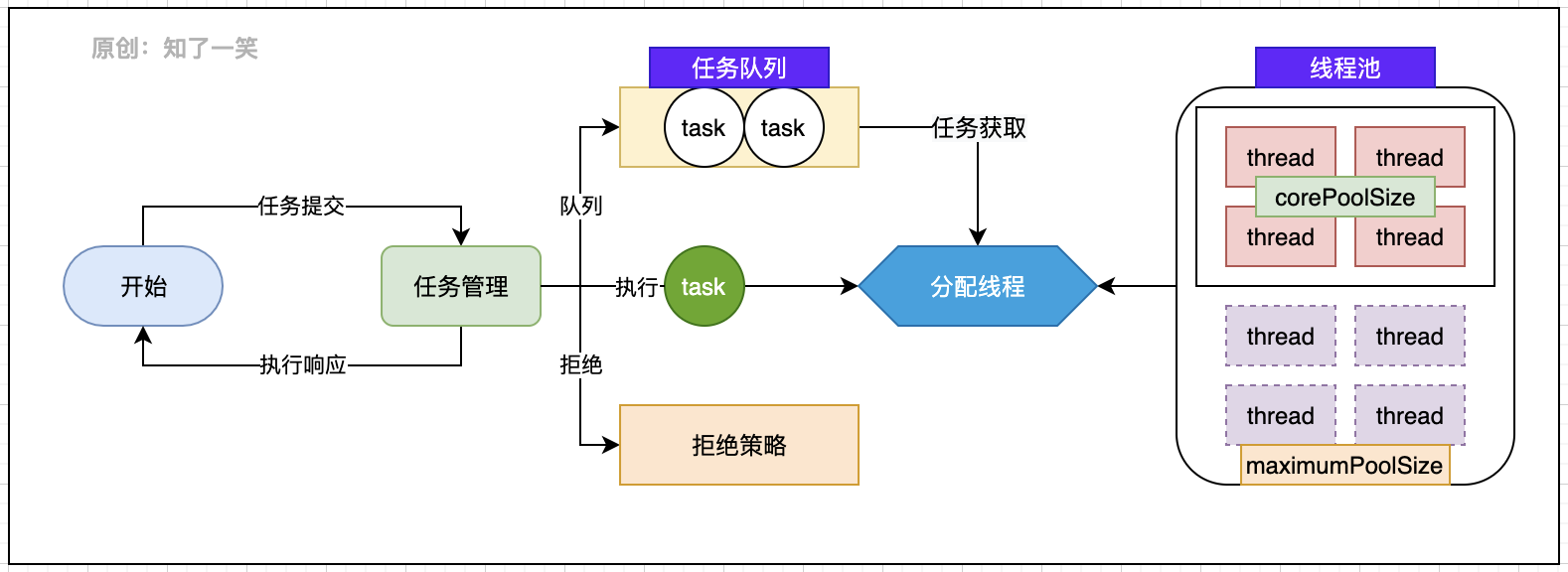
线程池的基本运行逻辑,任务提交之后有三种处理方式:直接分配线程执行;或者被放入任务队列,等待执行;如果直接被拒绝,会返回异常;任务的提交和执行被解耦,构成一个生产消费的模型。
5、生命周期这里从源码开始逐步分析线程池的核心逻辑,首先看看对于生命周期的状态描述,涉及如下几个核心字段:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 状态描述
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
ctl控制线程池的状态,包含两个概念字段:workerCount线程池内有效线程数,runState运行状态,具体的运行有5种状态描述:
- RUNNING:接受新任务,处理阻塞队列中的任务;
- SHUTDOWN:不接受新任务,处理阻塞队列中已存在的任务;
- STOP:不接受新任务,不处理阻塞队列中的任务,中断正在进行的任务;
- TIDYING:所有任务都已终止,workerCount=0,线程池进入该状态后会执行
terminated()方法; - TERMINATED: 执行
terminated()方法完后进入该状态;
状态之间的转换逻辑如下:
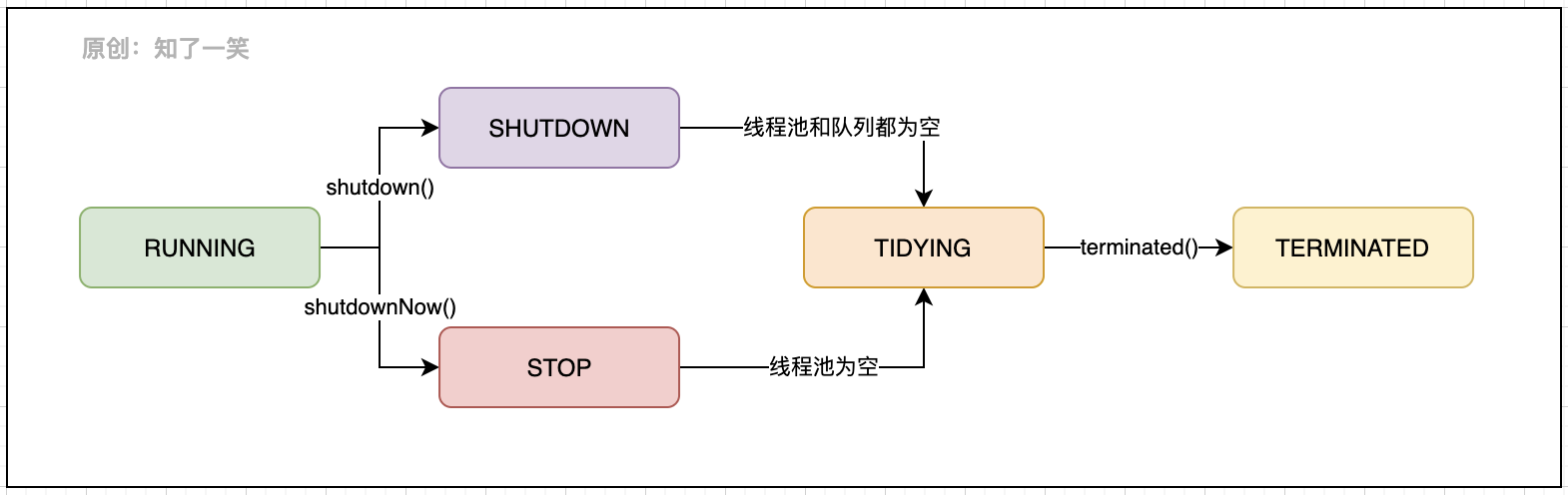
通过runStateOf()方法可以计算当前的运行状态,这里对于线程池生命周期的定义,以及状态的转换逻辑在ctl字段的源码注释中,更多细节可以参考该处描述文档。
从上面对线程池有整体的了解之后,现在从任务提交和执行这个核心流程入手,对源码和逻辑进行深入分析。任务调度作为线程池的核心能力,可以直接从execute(task)方法切入。
public void execute(Runnable command) {
// 上文描述的workerCount与runState
int c = ctl.get();
// 核心线程池
if (workerCountOf(c) < corePoolSize){}
// 任务队列
if (isRunning(c) && workQueue.offer(command)){}
// 拒绝策略
else if (!addWorker(command, false)) reject(command);
}
从整体上看,任务调度被放在三个分支步骤中判断,即:核心线程池、任务队列、拒绝策略,下面再细看每个分支的处理逻辑;
1.1 核心线程池
// 如果有效线程数小于核心线程数,新建线程并绑定当前任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
}
1.2 任务队列
// 如果线程池是运行状态,并且任务添加队列成功
if (isRunning(c) && workQueue.offer(command)) {
// 二次校验如果是非运行状态,则移除该任务,执行拒绝策略
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果有效线程数是0,执行addWorker添加方法
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
1.3 拒绝策略
// 再次执行addWorker方法,如果失败则拒绝该任务
else if (!addWorker(command, false)) reject(command);
这样execute方法执行逻辑,任务调度的流程如下:
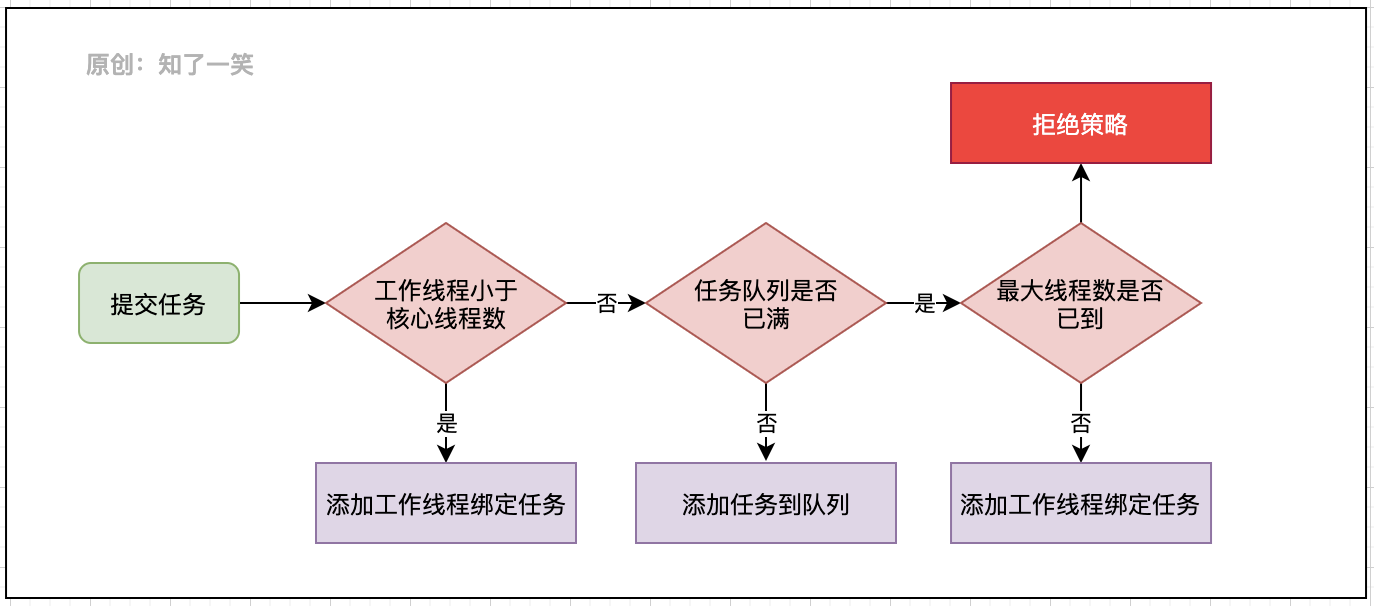
如上图任务被提交到线程池后的核心调度逻辑,任务既然提交自然是希望被执行的,源码中也多处调用addWorker方法添加工作线程。
线程池内工作线程被封装在Worker类中,继承AQS并实现Runnable接口,维护线程的创建和任务的执行:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread; // 持有线程
Runnable firstTask; // 初始化任务
}
2.1 addWorker 方法
既然添加工作线程,意味有任务需要执行:
- firstTask:新创建的线程第一个执行的任务,允许为空或者null;
- core:传true,新增线程时判断当前线程数是否小于corePoolSize;传false,新增线程时判断当前线程数是否小于maximumPoolSize;
private final HashSet<Worker> workers = new HashSet<Worker>();
private final BlockingQueue<Runnable> workQueue;
private boolean addWorker(Runnable firstTask, boolean core) ;
通过对该方法的源码分析,执行逻辑流程如下:
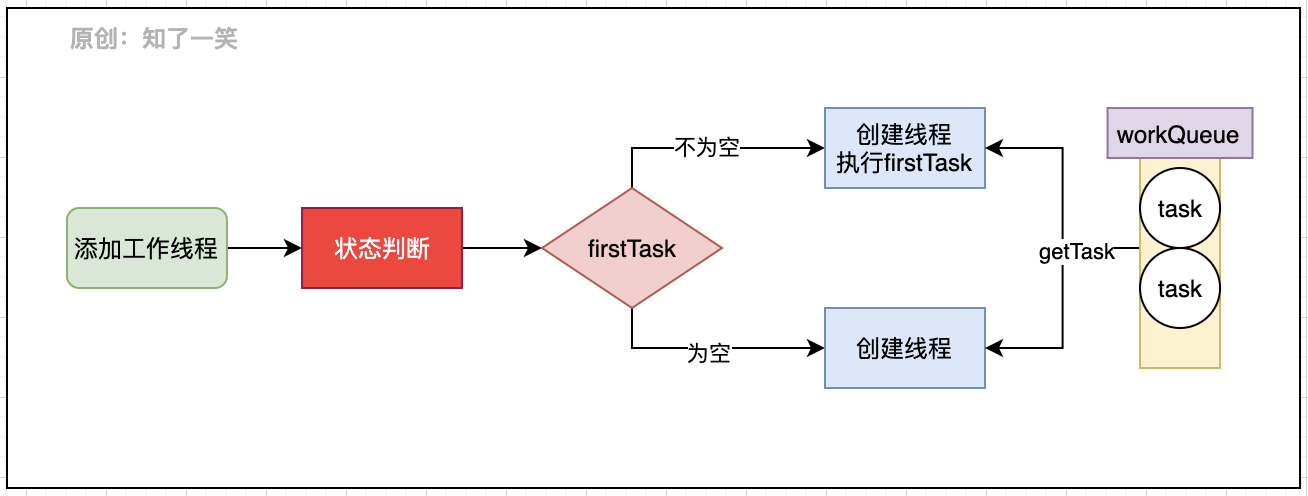
工作线程创建之后,在HashSet中维护和持有线程的引用,这样就可以对线程池做相应的put或者remove操作,进而对生命周期进行管理。
2.2 runWorker 方法
在Worker类中对于run方法的实现,实际上是委托给runWorker方法,用来周期性执行具体的线程任务,同样分析其执行逻辑:
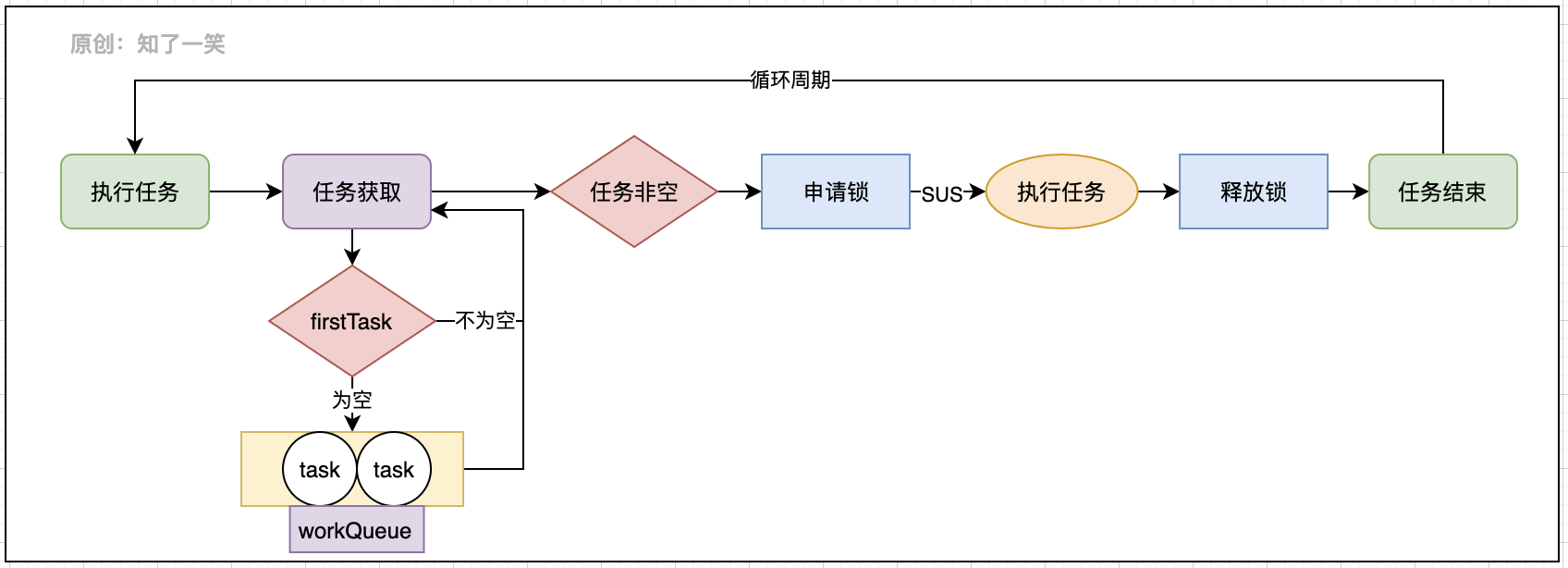
整个执行流程通过while循环不断获取任务并执行任务,整个过程也需要不断的校验线程池状态,及时的中断线程执行,该方法执行完成后会请求线程销毁动作。
3、任务队列线程池两大核心能力线程和任务的管理,并且对二者解耦,通过队列中任务的管理构建生产消费模式,不同的队列类型有各自的存取政策;LinkedBlockingQueue创建链表结构的队列,默认的Integer.MAX_VALUE容量过度,需要指定队列大小,按照先进先出的原则管理;
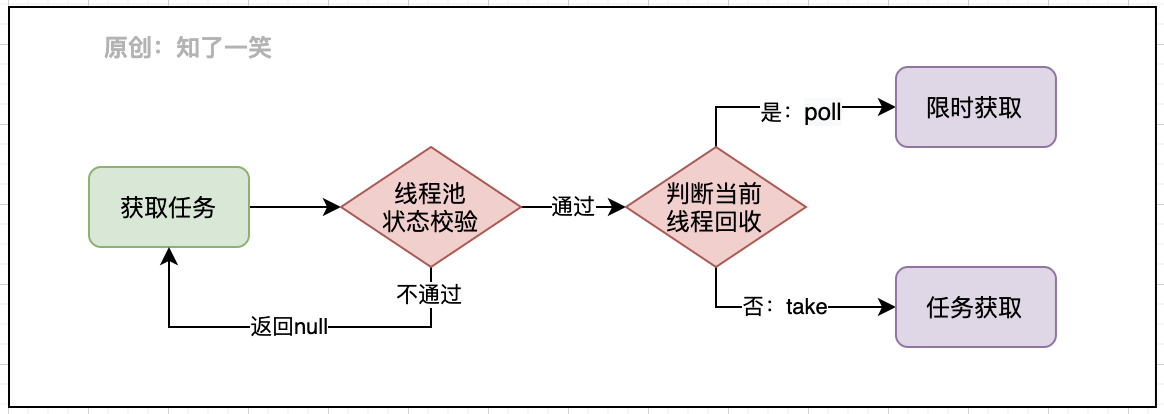
3.1 getTask 方法
在获取任务时,除了必要的线程池状态判断,就是要校验当前任务的线程是否需要超时回收,上面已经提过即使核心线程池也可以设置超时时效,如果没有获取到任务,则认为runWorker方法执行完成:
3.2 reject 方法
不管是线程池还是任务队列,都有容量的边界,当容量达到上限时,就需要拒绝新提交的任务,在上述案例中采用的是ThreadPoolExecutor.AbortPolicy丢弃任务并抛出异常,还有其他几种策略按需选择即可。
四、监控与配置在大部分的项目中,对于线程池都是直接定义好相关参数,如果需要调整,也基本都需要服务重启来完成,实际上线程池有一些放开的参数调整与查询的方法:
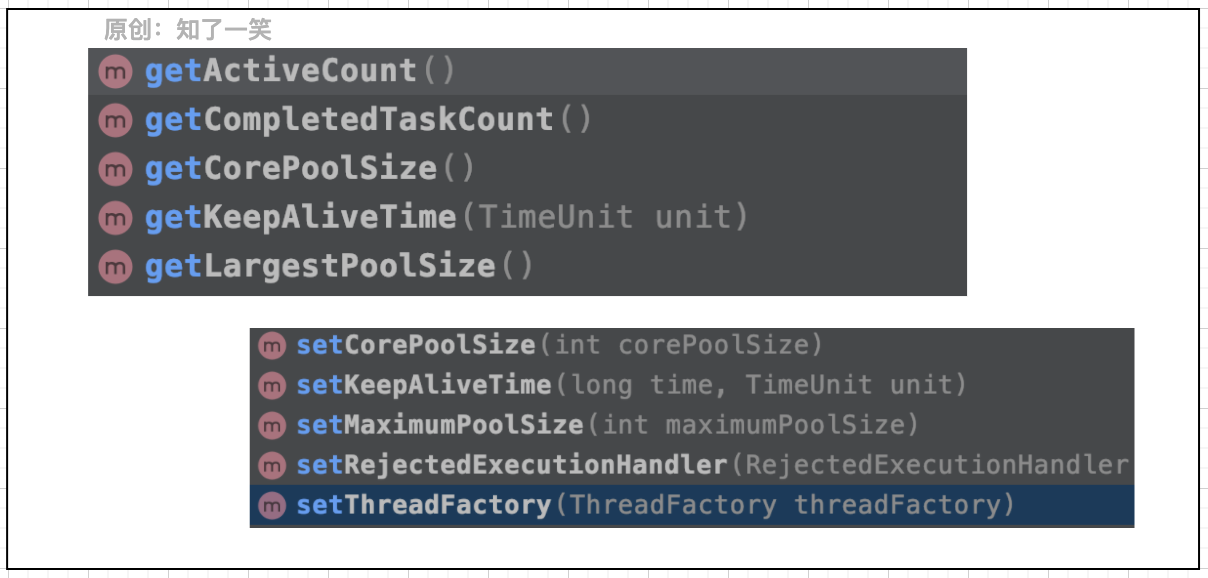
setCorePoolSize 方法
在方法内部经过一系列的逻辑校验,保证线程池平稳的过渡,整个流程严谨且复杂,结合线程池参数获取方法,就可以进行动态化的参数配置与监控,从而实现可控的线程池管理:
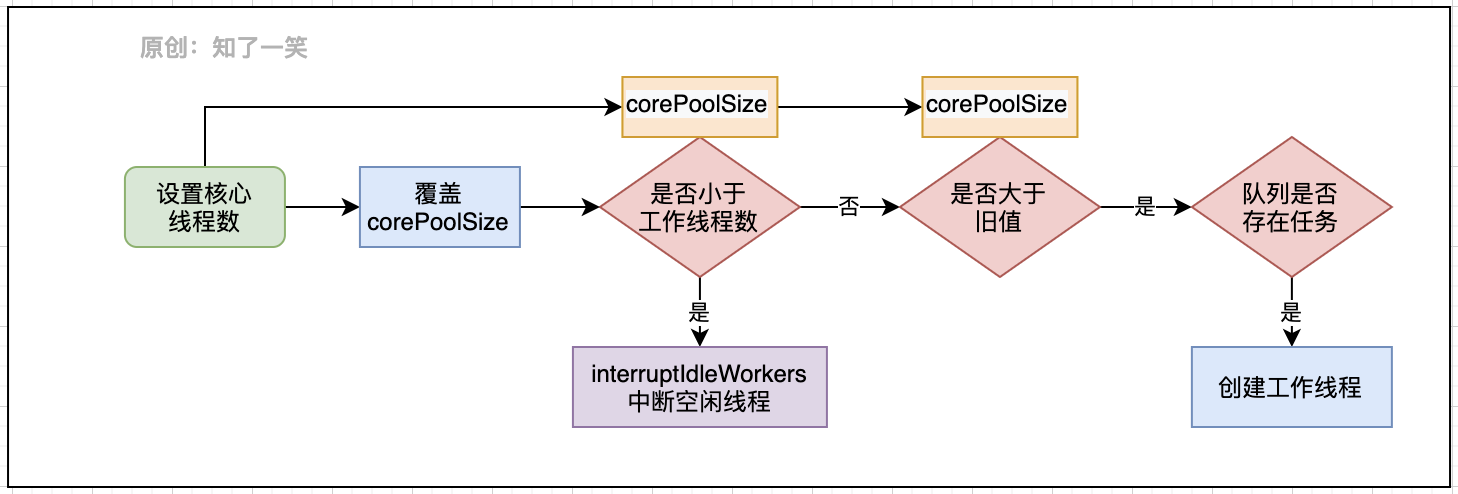
最后关于更多线程池的细节问题,可以多阅读源码文档,并结合案例进行实践;线程池的原理在很多组件中都有应用,例如各种连接池,并行计算等,同样值得深入学习和总结。
五、参考源码应用仓库:
https://gitee.com/cicadasmile/butte-flyer-parent
组件封装:
https://gitee.com/cicadasmile/butte-frame-parent
