- 堪比JMeter的.Net压测工具 - Crank 入门篇
- 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml
- 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识bombardier
- 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识wrk、wrk2
- 堪比JMeter的.Net压测工具 - Crank 实战篇 - 接口以及场景压测
- 堪比JMeter的.Net压测工具 - Crank 实战篇 - 收集诊断跟踪信息与如何分析瓶颈
- 堪比JMeter的.Net压测工具 - Crank 总结篇 - crank带来了什么
上面我们已经做到了接口以及场景压测,通过控制台输出结果,我们只需要将结果收集整理下来,最后汇总到excel上,此次压测报告就可以完成了,但收集报告也挺麻烦的,交给谁呢……
找了一圈、没找到愿意接手的人,该怎么办呢……思考了会儿还是决定看看能否通过程序解决我们的难题吧,毕竟整理表格太累╯﹏╰
2. 收集结果通过查阅官方文档,我们发现官方提供了把数据保存成Json、csv、以及数据库三种方式,甚至还有小伙伴积极的对接要把数据保存到Es中,那选个最简单的吧!
要不选择Json吧,不需要依赖外部存储,很简单,我觉得应该可是,试一下看看:输入命令:
crank --config load.benchmarks.yml --scenario api --load.framework net5.0 --application.framework net5.0 --json 1.json --profile local --profile crankAgent1 --description "wrk2-获取用户详情" --profile defaultParamLocal
最后得到结果:
{
"returnCode": 0,
"jobResults": {
"jobs": {
"load": {
"results": {
"http/firstrequest": 85.0,
"wrk2/latency/mean": 1.81,
"wrk2/latency/max": 1.81,
"wrk2/requests": 2.0,
"wrk2/errors/badresponses": 0.0,
"wrk2/errors/socketerrors": 0.0,
"wrk2/latency/50": 1.81,
"wrk2/latency/distribution": [
[
{
"latency_us": 1.812,
"count": 1.0,
"percentile": 0.0
},
{
"latency_us": 1.812,
"count": 1.0,
"percentile": 1.0
}
]
]
}
}
}
}
}
完整的导出结果
好吧,数据有点少,好像数据不太够吧,这些信息怎么处理能做成报表呢,再说了数据不对吧,QPS、延迟呢?好吧,被看出来了,因为信息太多,我删了一点点(也就1000多行指标信息吧),看来这个不行,用json的话还得配合个程序好难……
csv不用再试了,如果也是单个文本的话,也是这样,还得配个程序,都不能单干,干啥都得搭伴,那试试数据库如何
crank --config load.benchmarks.yml --scenario api --load.framework net5.0 --application.framework net5.0 --sql "Server=localhost;DataBase=crank;uid=sa;pwd=P@ssw0rd;" --table "local" --profile local --profile crankAgent1 --description "wrk2-获取用户详情" --profile defaultParamLocal
我们根据压测环境,把不同的压测指标存储到不同的数据库的表中,当前是本地环境,即 table = local
最后我们把数据保存到了数据库中,那这样做回头需要报告的时候,我查询下数据库搞出来就好了,终于松了一口气,但好景不长,发现数据库存储也有个坑,之前json中看到的结果竟然在一个字段中存储,不过幸好SqlServer 2016之后支持了json,可以通过json解析搞定,但其中参数名有/等特殊字符,sql server处理不了,难道又得写个网站才能展示这些数据了吗??真的绕不开搭伴干活这个坑吗?
微软不会就做出个这么鸡肋的东西,还必须要配个前端才能清楚的搞出来指标吧……还得用vue、好吧,我知道虽然现在有blazer,可以用C#开发,但还是希望不那么麻烦,又仔细查找了一番,发现Crank可以对结果做二次处理,可以通过script,不错的东西,既然sql server数据库无法支持特殊字符,那我加些新参数取消特殊字符不就好了,新建scripts.profiles.yml
scripts:
changeTarget: |
benchmarks.jobs.load.results["cpu"] = benchmarks.jobs.load.results["benchmarks/cpu"]
benchmarks.jobs.load.results["cpuRaw"] = benchmarks.jobs.load.results["benchmarks/cpu/raw"]
benchmarks.jobs.load.results["workingSet"] = benchmarks.jobs.load.results["benchmarks/working-set"]
benchmarks.jobs.load.results["privateMemory"] = benchmarks.jobs.load.results["benchmarks/private-memory"]
benchmarks.jobs.load.results["totalRequests"] = benchmarks.jobs.load.results["bombardier/requests;http/requests"]
benchmarks.jobs.load.results["badResponses"] = benchmarks.jobs.load.results["bombardier/badresponses;http/requests/badresponses"]
benchmarks.jobs.load.results["requestSec"] = benchmarks.jobs.load.results["bombardier/rps/mean;http/rps/mean"]
benchmarks.jobs.load.results["requestSecMax"] = benchmarks.jobs.load.results["bombardier/rps/max;http/rps/max"]
benchmarks.jobs.load.results["latencyMean"] = benchmarks.jobs.load.results["bombardier/latency/mean;http/latency/mean"]
benchmarks.jobs.load.results["latencyMax"] = benchmarks.jobs.load.results["bombardier/latency/max;http/latency/max"]
benchmarks.jobs.load.results["bombardierRaw"] = benchmarks.jobs.load.results["bombardier/raw"]
以上处理的数据是基于bombardier的,同理大家可以完成对wrk或者其他的数据处理
通过以上操作,我们成功的把特殊字符的参数改成了没有特殊字符的参数,那接下来执行查询sql就可以了。
SELECT Description as '场景',
JSON_VALUE (Document,'$.jobs.load.results.cpu') AS 'CPU使用率(%)',
JSON_VALUE (Document,'$.jobs.load.results.cpuRaw') AS '多核CPU使用率(%)',
JSON_VALUE (Document,'$.jobs.load.results.workingSet') AS '内存使用(MB)',
JSON_VALUE (Document,'$.jobs.load.results.privateMemory') AS '进程使用的私有内存量(MB)',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.totalRequests'),0) AS '总发送请求数',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.badResponses'),0) AS '异常请求数',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.requestSec'),0) AS '每秒支持请求数',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.requestSecMax'),0) AS '每秒最大支持请求数',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.latencyMean'),0) AS '平均延迟时间(us)',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.latencyMax'),0) AS '最大延迟时间(us)',
CONVERT(varchar(100),DATEADD(HOUR, 8, DateTimeUtc),20) as '时间'
FROM dev;
通过上面的操作,我们已经可以轻松的完成对场景的压测,并能快速生成相对应的报表信息,那正题来了,可以模拟高并发场景,那如何分析瓶颈呢?毕竟报告只是为了知晓当前的系统指标,而我们更希望的是知道当前系统的瓶颈是多少,怎么打破瓶颈,完成突破呢……
首先我们要先了解我们当前的应用的架构,比如我们现在使用的是微服务架构,那么
- 应用拆分为几个服务?了解清楚每个服务的作用
- 服务之间的调用关系
- 各服务依赖的基础服务有哪些、基础服务基本的信息情况
举例我们当前的微服务架构如下:
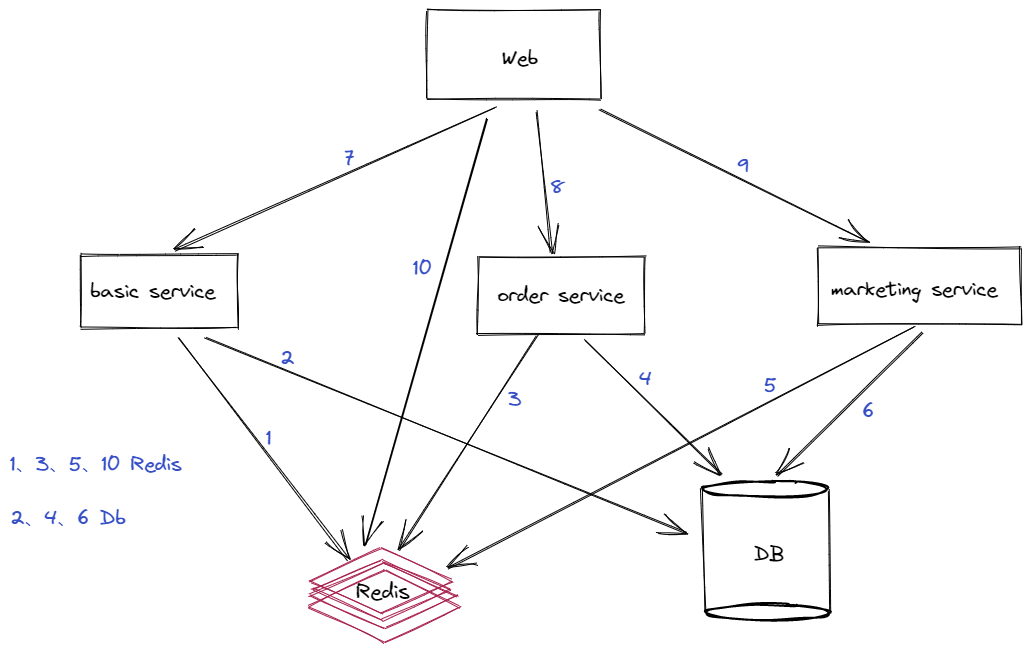
通过架构图可以快速了解到项目结构,我们可以看到用户访问web端,web端根据请求对应去查询redis或者通过http、grpc调用服务获取数据、各服务又通过redis、db获取数据。
首先我们先通过crank把当前的数据指标保存入库。调出其中不太理想的接口开始分析。
在这里我们拿两个压测接口举例:
- 获取首页Banner、QPS:3800 /s (Get)
- 下单、QPS:8 /s (Post)
通过单测首页banner的接口,QPS是3800多不到4000这样,虽然这个指标还不错,但我们仍然觉得很慢,毕竟首页banner就是很简单几个图片+标题组合的数据,数据量不大,并且是直连Redis,仅在Redis不存在时才查询对应服务获取banner数据,这样的QPS实在不应该,并且这个还是仅压测单独的banner,如果首页同时压测十几个接口,那其性能会暴降十倍不止,这样肯定是不行的
我们又压测了一次首页banner接口,发现有几个疑点:
- redis请求数徘徊在3800左右的样子,网络带宽占用1M的样子,无法继续上涨
- 查看web服务,发现时不时的会有调用服务超时出错的问题,Db的访问量有上涨,但不明显,很快就下去了
思考: Redis的请求数与最后的压测结果差不多,最后倒也对上了,但为什么redis的请求数这么低呢?难道是带宽限制!!
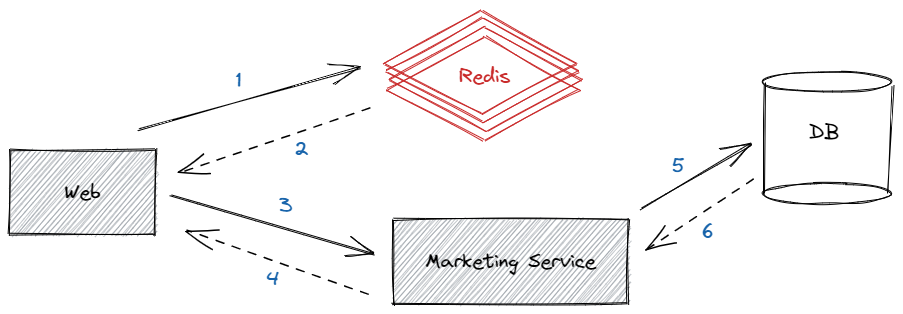
虽然是单机redis,但4000也绝对不可能是它的瓶颈,怀疑是带宽被限制了,应该就是带宽被限制了,后来跟运维一番切磋后,得到结论是redis没限制带宽……
那为什么不行呢,这么奇怪,redis不可能就这么点并发就不行了,算了还是写个程序试一下吧,看看是不是真的测试环境不给力,redis配置太差了,一番操作后发现,同一个redis数据,redis读可以到6万8,不到7万、带宽占用10M,redis终于洗清了它的嫌疑,此接口的QPS不行与Redis无关,但这么简单的一个结构为什么QPS就上不去呢……,如果不是redis的问题,那会不会是因为请求就没到redis上,是因为压测机的强度不够,导致请求没到redis……当时冒出来这个有点愚蠢的想法,那就增加压测机的数量,通过更改负载压测机配置,1台压测机升到了3台,但可惜的是单台压测机的指标不升反降,最后所有压测机的指标加到一起正好与之前一台压测机的压测结果差不多一样,那说明QPS低与压测机无关,后来想到试试通过增加多副本来提升QPS,后来web副本由1台提升到了3台,之前提到的服务调用报错的情况更加严重,之前只是偶尔有一个错误,但提升web副本后,看到一大片的错误
- 提示Thread is busy,很多线程开始等待
- 大量的服务调用超时,DB查询缓慢
最后QPS 1000多一点,有几千个失败的错误,这盲目的提升副本貌似不大有效,之前尽管Qps不高,但起码也在4000,DB也没事,这波神操作后QPS直降4分之3,DB还差点崩了,思想滑坡了,做了负优化……
继续思考,为何提升副本,QPS不升反降,为何出现大量的调用超时、为何DB会差点被干崩,我只是查询个redis,跟DB有毛关系啊!奇了怪了,看看代码怎么写的吧……烧脑
public async Task<List<BannerResponse>> GetListAsync()
{
List<BannerResponse> result = new List<BannerResponse>();
try
{
var cacheKey = "banner_all";
var cacheResult = await _redisClient.GetAsync<List<BannerResponse>>(cacheKey);
if (cacheResult == null)
{
result = this.GetListServiceAsync().Result;
_redisClient.SetAsync(cacheKey, result, new()
{
DistributedCacheEntryOptions = new()
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromDays(5)
}
}).Wait();
}
else
{
result = cacheResult;
}
}
catch (Exception e)
{
result = await this.GetListServiceAsync();
}
return result;
}
看了代码后发现,仅当Reids查询不到的时候,会调用对应服务查询数据,对应服务再查询DB获取数据,另外查询异常时,会再次调用服务查询结果,确保返回结果一定是正确的,看似没问题,但为何压测会出现上面那些奇怪现象呢……
请求超时、大量等待,那就是正好redis不存在,穿透到对应的服务查询DB了,然后压测同一时刻数据量过大,同一时刻查询到的Reids都是没有数据,最后导致调用服务的数量急剧上升,导致响应缓慢,超时加剧,线程因超时释放不及时,又导致可用线程较少。
这块我们查找到对应的日志显示以下信息
System.TimeoutException: Timeout performing GET MyKey, inst: 2, mgr: Inactive, queue: 6, qu: 0, qs: 6, qc: 0, wr: 0, wq: 0, in: 0, ar: 0,
IOCP: (Busy=6,Free=994,Min=8,Max=1000),
WORKER: (Busy=152,Free=816,Min=8,Max=32767)
- 那么我们可以调整Startup.cs:
public void ConfigureServices(IServiceCollection services)
{
ThreadPool.GetMinThreads(out int workerThreads, out int completionPortThreads);
ThreadPool.SetMinThreads(1000, completionPortThreads);//根据情况调整最小工作线程,避免因创建线程导致的耗时操作
……………………………………………………………此处省略…………………………………………………………………………………………………………
}
- web服务调用底层服务太慢,那么提升底层服务的响应速度(优化代码)或者提高处理能力(提升副本)
- 防止高并发情况下全部穿透到下层,增加底层服务的压力
前两点也是一个好的办法,但不是最好的解决办法,最好还是不要穿透到底层服务,如果reids不存在,就放一个请求过去是最好的,拿到数据就持久化到redis,不要总穿透到下层服务,那么怎么做呢,最简单的办法就是使用加锁,但加锁会影响性能,但这个我们能接受,后来调整加锁测试,穿透到底层服务的情况没有了,但很可惜,请求数确实会随着副本的增加而增加,但是实在是有点不好看,后来又测试了下另外一个获取缓存数据的结果,结果QPS:1000多一点,比banner还要低的多,两边明明都使用的是Reids,性能为何还有这么大的差别,为何我们写的redis的demo就能到6万多的QPS,两边都是拿的一个缓存,差距有这么大?难道是封装redis的sdk有问题?后来仔细对比了后来写的redis的demo与banner调用redis的接口发现,一个是直接查询的redis的字符串,一个是封装redis的sdk,多了一个反序列化的过程,最后经过测试,反序列化之后性能降低了十几倍,好吧看来只能提升副本了……但为何另外的接口也是从redis获取,性能跟banner的接口不一样呢!!
经过仔细对比发现,差别是信息量,QPS更低的接口的数据量更大,那结果就有了,随着数据量的增加,QPS会进一步降低,那这样一来的话,增加副本的作用不大啊,谁知道会不会有一个接口的数据量很大,那性能岂不是差的要死,那还怎么玩,能不能提升反序列化的性能或者不反序列化呢,经过认真思考,想到了二级缓存,如果用到了二级缓存,内存中有就不需要查询redis,也不需要再反序列化,那么性能应该有所提升,最后的结构如下图:
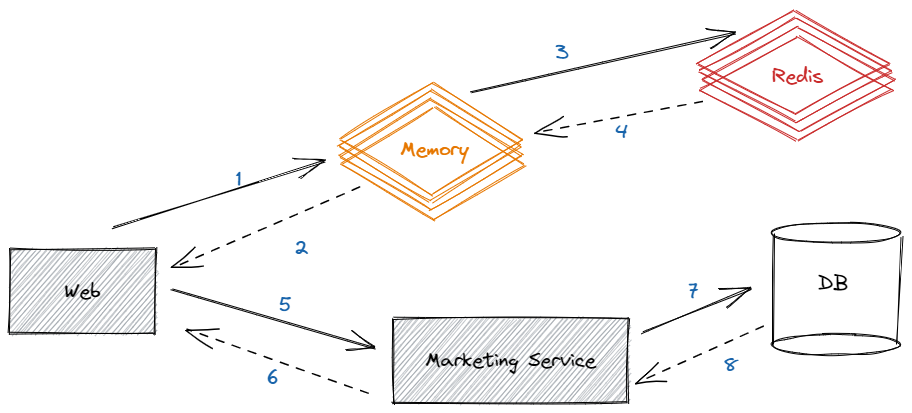
最后经过压测发现,单副本QPS接近50000,比最开始提升12倍,并且也不会出现服务调用超时,DB崩溃等问题、且内存使用平稳
此次压测发现其banner这类场景的性能瓶颈在反序列化,而非Redis、DB,如果按照一开始不清楚其工作原理、盲目的调整副本数,可能最后会加剧系统的雪崩,而如果我们把DB资源、Redis资源盲目上调、并不会对最后的结果有太大帮助,最多也只是延缓崩溃的时间而已
3.2. 下单下单的QPS是8,这样的QPS已经无法忍受了,每秒只有十个请求可以下单成功,如果中间再出现一个库存不足、账户余额不足、活动资格不够等等,实际能下单的人用一个手可以数过来,真的就这么惨……虽然下单确实很费性能,不过确实不至于这么低吧,先看下下单流程吧
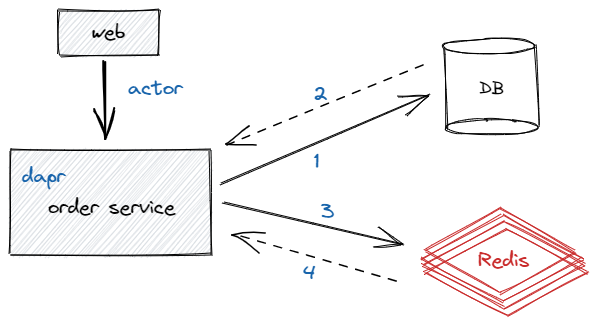
简化后的下单流程就这么简单,web通过dapr的actor服务调用order service,然后就是漫长的查询db、操作redis操作,因涉及业务代码、具体代码就不再放出,但可以简单说一下其中做的事情,检查账户余额、反复的增加redis库存确保库存安全、检查是否满足活动、为推荐人计算待结算佣金等等一系列操作,整个看下来把人看懵了,常常是刚看了上面的,看下面代码的时候忘记上面具体干了什么事,代码太多了,一个方法数千行,其中再调用一些数百行的代码,真的吐血了,不免感叹我司的开发小哥哥是真的强大,这么复杂的业务居然能这么"顺畅"的跑起来,后面还有N个需求等待加到下单上,果然不是一般人
不过话说回来,虽然是业务是真的多,也真的乱,不过这样搞也不至于QPS才只有8这么可怜吧,服务器的处理能力可不是二十几年前的电脑可以比拟的,单副本8核16G的配置不支持这么拉胯吧,再看一下究竟谁才是真正的幕后黑手……
但究竟哪里性能瓶颈在哪里,这块就要出杀手锏了
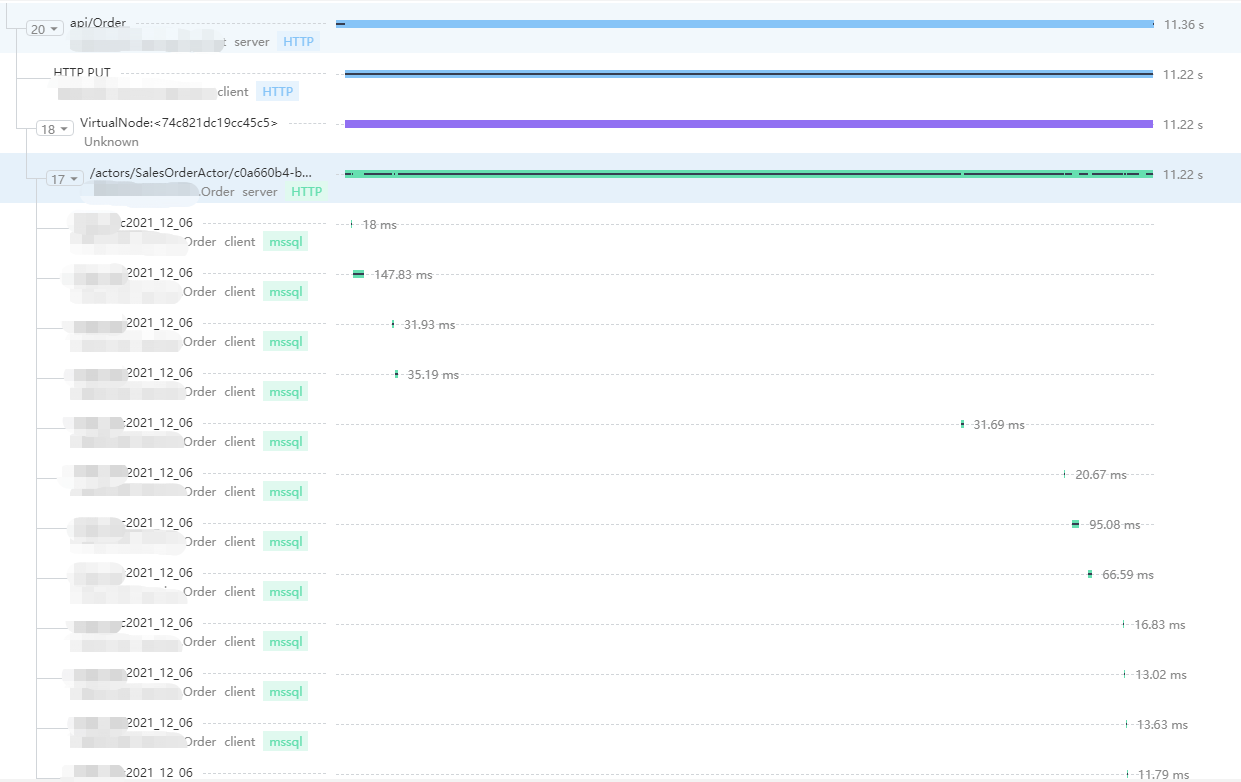
通过Tracing可以很清楚的看到各节点的耗时情况,这将对我们分析瓶颈提供了非常大的帮助、我们看到了虽然有几十次的查询DB操作,但DB还挺给力,基本也再很短时间内就给出了响应,那剩余时间耗费到了哪里呢?我们看到整体耗时11s、但查询Db加起来也仅仅不到1s,那么剩余操作都在哪里?要知道哪怕我们优化DB查询性能,减少DB查询,那提升的性能对现在的结果也是微乎其微
结合Tracing以及下单流程图,我们发现从Web到Order Service是通过actor来实现的,那会不是这里耗时影响的呢?
但dapr是个新知识、开发的小哥哥速度真快,这么快就用上dapr了(ˇˍˇ)不知道小哥哥的头发还有多少……
快速去找到下单使用actor的地方,如下:
[HttpPost]
[Authorize]
public async Task<CreateOrderResponse> CreeateOrder([FromBody] CreateOrderModel request)
{
string actionType = "SalesOrderActor";
var salesOrderActor = ActorProxy.Create<ISalesOrderActor>(new ActorId(request.SkuList.OrderBy(sku => sku.Sku).FirstOrDefault().Sku), actionType);
request.AccountId = Account.Id;
var result = await salesOrderActor.CreateOrderAsync(request);
return new Mapping<ParentSalesOrderListViewModel, CreateOrderResponse>().Map(result);
}
我们看到了这边代码十分简单,获取商品信息的第一个sku编号作为actor的actorid使用,然后得到下单的actor,之后调用actor中的创建订单方法最后得到下单结果,这边的代码太简单了,让人心情愉快,那这块会不会有可能影响下单速度呢?它是不是那个性能瓶颈最大的幕后黑手?
首先这块我们就需要了解下什么是Dapr、Actor又是什么,不了解这些知识我们只能靠抓阄来猜这块是不是瓶颈了……
Dapr 全称是Distributed Application Runtime,分布式应用运行时,并于今年加入了 CNCF 的孵化项目,目前Github的star高达16k,相关的学习文档在文档底部可以找到,我也是看着下面的文档了解dapr
通过了解actor,我们发现用sku作为actorid是极不明智的选择,像秒杀这类商品不就是抢的指定规格的商品吗?如果这样一来,这不是在压测actor吗?这块我们跟对应的开发小哥哥沟通了下,通过调整actorid顺利将Qps提升到了60作用,后面又通过优化减少db查询、调整业务规则的顺序等操作顺利将QPS提升到了不到一倍,虽然还是很低,不过接下来的优化工作就需要再深层次的调整业务代码了……
4. 总结通过实战我们总结出分析瓶颈从以下几步走:
- 通过第一轮的压测获取性能差的接口以及指标
- 通过与开发沟通或者自己查看源码的方式梳理接口流程
- 通过分析其项目所占用资源情况、依赖第三方基础占用资源情况以及Tracing更进一步的确定瓶颈大概的点在哪几块
- 通过反复测试调整确定性能瓶颈的最大黑手
- 将最后的结论与相关开发、运维人员沟通,确保都知晓瓶颈在哪里,最后优化瓶颈
知识点:
- Dapr
- 手把手教你学Dapr系列
- Tracing
- OpenTracing 简介、关于OpenTracing后续我们也会开源,可以提前关注我们的开源项目
- Masa.BuildingBlocks
- Masa.Contrib
- OpenTracing 简介、关于OpenTracing后续我们也会开源,可以提前关注我们的开源项目
MASA.BuildingBlocks:https://github.com/masastack/MASA.BuildingBlocks
MASA.Contrib:https://github.com/masastack/MASA.Contrib
MASA.Utils:https://github.com/masastack/MASA.Utils
MASA.EShop:https://github.com/masalabs/MASA.EShop
MASA.Blazor:https://github.com/BlazorComponent/MASA.Blazor
如果你对我们的 MASA Framework 感兴趣,无论是代码贡献、使用、提 Issue,欢迎联系我们

自动签名
欢迎加入技术交流群:

招.Net中/高级开发工程师:坐标杭州下沙,联系方式进群找群主,薪资范围16-30K,有住房补贴