大家好,我是【架构摆渡人】,一只十年的程序猿。这是消息队列的第一篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。
今天跟大家聊聊如何用数据库来做消息的存储,这样就可以将消息队列的整体复杂度进行降低,如果后续你们需要自己造更贴近公司业务的轮子,我觉得可以用数据库来存储。
容量设计假设你们的业务消息量每天是10亿条,数据存储最近7天的量,也就是70亿条。我们以单表2000W条数据作为上限,1个库放10张表,那么总共需要40个库来承载这些数据量。
当然这40个库可以不用40个单独的数据库实例,这样成本有点高,当然主要还是取决于你们消息的读写并发有多高,如果很高的话数据库实例越多,性能肯定越好。不多的话就5个数据库实例,每个实例上建8个库即可。(根据消息读取和写入的量结合数据库规格的性能进行评估)
数据归档因为我们总共也就能存放80亿条的数据,如果数据量多了必然会影响查询性能或者磁盘空间不够的问题,而且对于已消费的消息,其实后面就没有业务价值了。
所以我们还需要每天进行数据的归档操作,归档你可以将这些数据移到Nosql中,也可以进行删除,看业务场景决定。有了归档,这样就能保持当前的数据库集群能够承载每日的消息容量。
存储设计接下来聊聊最重要的存储设计,就是我要用数据库来存,我的表该怎么设计?
前面我们也讲到了,我们大概需要400张表来存储这些数据。我们对某个Topic进行消息发送,那么数据必然要落到这400张表中的某一张表里面,所以我们很自然的想以某个字段来分表就行了呗,比如Topic,每个Topic写入的数据必定在同一张表里面。
这样也没啥问题,但是在实际的业务中,必定是有的Topic消息量会很大,有的会很少。对于消息量很大的,可能几个小时就突破2000W的量了,那么这个表必定越来越大。所以我们在设计数据存储的时候一定要考虑到如何将某个Topic下的数据均匀的存储到多张表里面去。

可能有人就会说了,既然不能固定按Topic进行分表,那么就对总的表数量取模好啦,这样数据就会分布在每张表里面。但是这样对于consumer在消费的时候就有影响了,因为consumer压根就不知道自己要消费Topic的数据存在哪,必须得从所有的库表里面进行查询才能拿到数据,性能不太好。
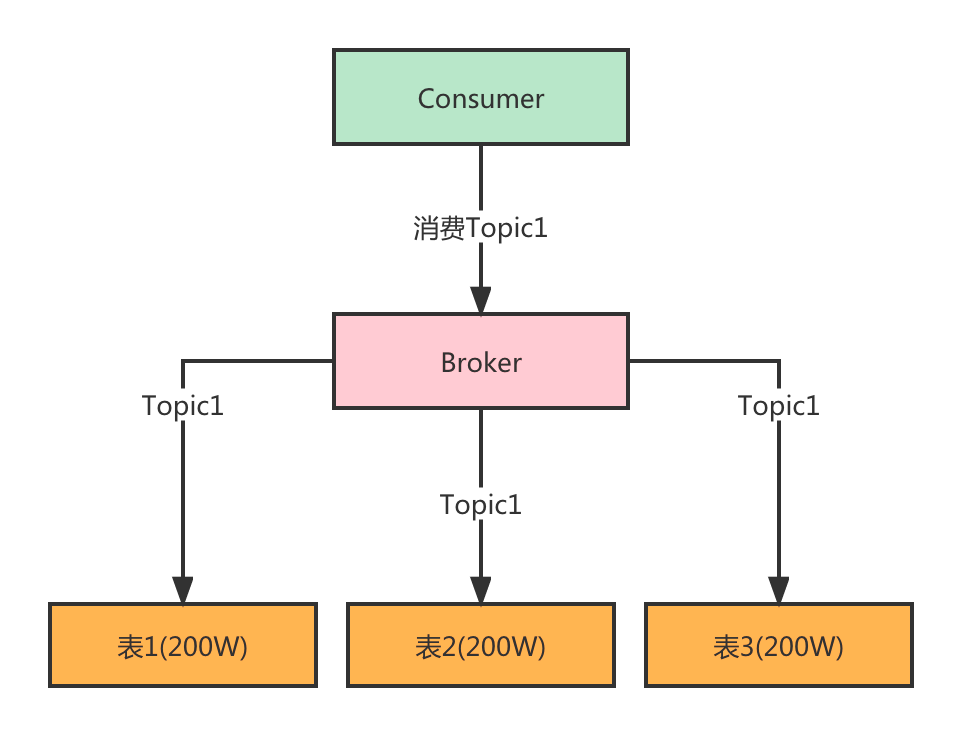
要解决这个问题,我们先回顾下开源的MQ是怎么设计的,以RocketMQ来说,一个Topic下的消息会存储到多个Queue中(也就相当于kafka中的partition),也就是每个Topic下的Queue并不是一定的数量,而是可以在创建Topic时进行指定,所以我们在用表做存储的时候,也可以参考这个设计,本来每个Topic对应的消息量就不同。
所以一张表也就相当于一个Queue,用于存储消息内容。我们可以记录Topic和Queue之间的关系,记录后有如下的作用:
- 往某个Topic写入消息的时候,就知道这个Topic对应哪些Queue(数据表),可以轮询的写入这些表,这样数据就比较平均。
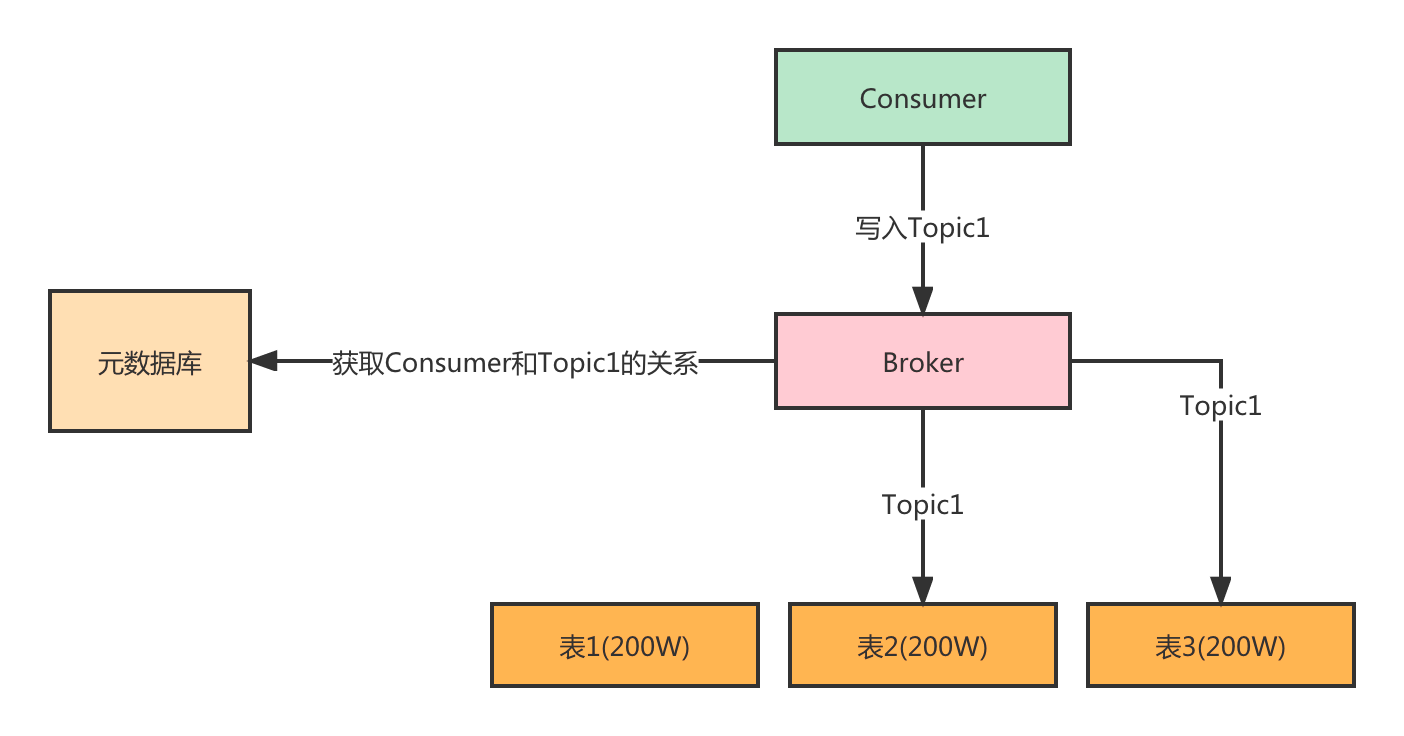
- 创建Topic的时候要预估一下数据量,然后指定分配多少个Queue用于存储。(后续也能在线修改Queue的数量)
- Consumer消费某个Topic消息的时候,同样也知道对应哪些Queue,在Consumer初始化的时候就会分配好哪个Consumer消费哪个Queue,这样每个Consumer只会去固定的一个表中查询数据,性能也非常好。如果后面Consumer增加或者减少,Queue增加或者减少就需要重新分配了,这就是消息队列中经常提到的重平衡的一个概念。
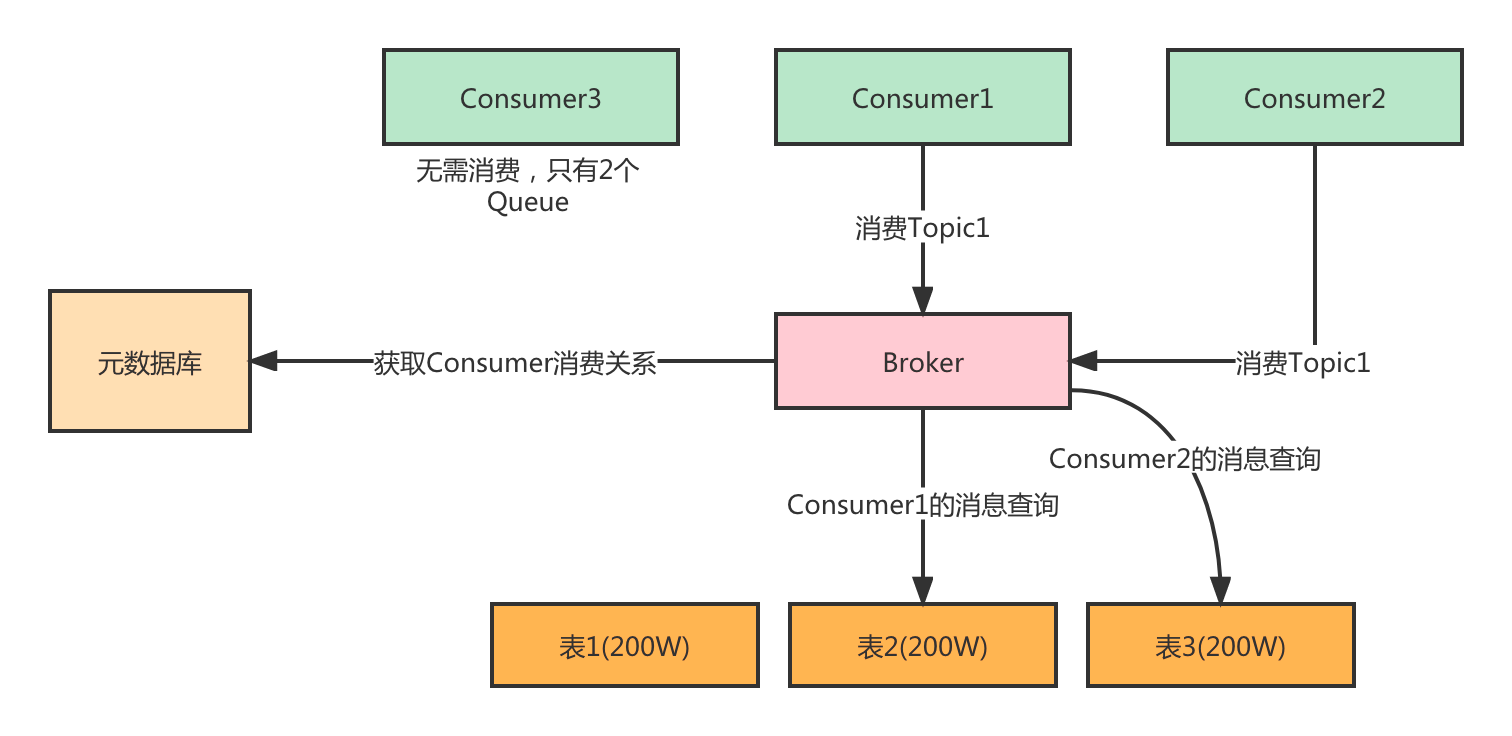
当然这里只是说了整体的设计,还有很多细节需要去完善,比如Topic消息量小的如何处理,就算是只分配一个表,但是我们总的表数量是有限的,所以还会涉及到多Topic共用一个表的情况。
大概的我们可能会有下面的一些表:
- consumer: 消费者,记录当前消费者的信息,比如ip, 进程ID, 应用类型,启动时间等等。
- consumerGroup: 消费组信息。
- topic:主题表。
- queue: 消息表,记录消息内容,对应的Topic等等。
- topicQueue: Topic和queue的关系。
- queueOffset: 队列消费偏移量,记录consumer的消费信息。
不同的场景可以选择不同的技术方案,用数据库作为MQ的存储也是一种不错的思路。但为什么开源的都是自己写磁盘呢?其实这也跟架构有关系,因为一旦依赖外部存储,也就是整个架构会比较复杂。而且MQ这种本来就是用来扛大流量的,所以要对底层进行优化,用三方的也就意味着性能其实依赖了三方。
通过数据库来存储MQ的数据,相对来说技术难点会比写磁盘要简单点,大家也可以按照这个思路,自己去设计实现一款MQ。
原创:架构摆渡人(公众号ID:jiagoubaiduren),欢迎分享,转载请保留出处。
推荐一款开源的mock框架:https://github.com/yinjihuan/fox-mock 基于Java Agent实现的自测,联调Mock利器
【本文转自:韩国服务器 http://www.558idc.com/kt.html提供,感谢支持】