Citus 是一种 PostgreSQL 扩展,它允许数据库服务器(称为节点)在“无共享(shared nothing)”架构中相互协调。这些节点形成一个集群,允许 PostgreSQL 保存比单台计算机上更多的数据和使用更多的 CPU 内核。 这种架构还允许通过简单地向集群添加更多节点来扩展数据库。
- 扩展
- https://www.postgresql.org/docs/current/external-extensions.html
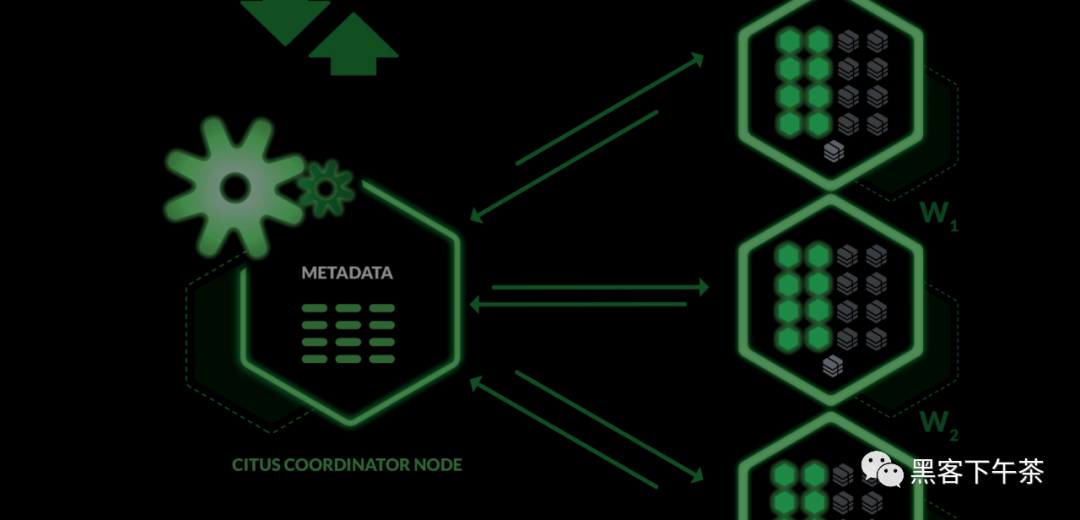
每个 cluster 都有一个称为 coordinator(协调器) 的特殊节点(其他节点称为 worker 节点)。应用程序将它们的查询发送到 coordinator 节点,coordinator 节点将其转发给相关的 worker 并累积结果。
对于每个查询,coordinator 要么将其路由到单个 worker 节点,要么将其并行化到多个节点,具体取决于所需数据是位于单个节点上还是多个节点上。coordinator 通过查阅其元数据表知道如何做到这一点。这些 Citus 特定表跟踪 worker 节点的 DNS 名称和运行状况,以及跨节点数据的分布情况。
Citus 集群中有三种类型的表,每种表都以不同方式存储在节点中,并且用于不同的目的。
第一种类型,也是最常见的,是分布式表。对于 SQL 语句而言,它们看似是普通的表,但在 worker 节点之间水平分区。
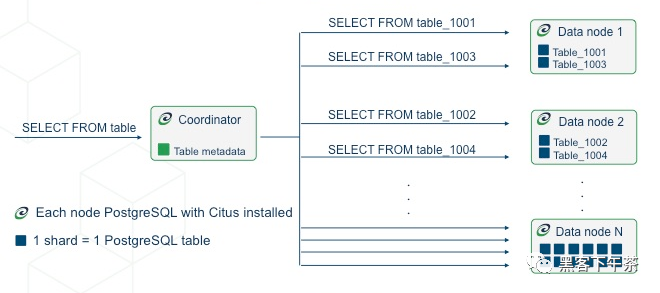
这里 table 的行存储在 worker 的表 table_1001、table_1002 等中。 组件 worker 表称为分片(shards)。
分布列
Citus 使用使用分片算法将行分配到分片。基于表列(称为分布列(distribution column))的值执行分配,此分配具有确定性。集群管理员在分布表时必须指定此列。做出正确的选择,这一点对于性能和功能有重要影响。
引用表 是一种分布式表,其全部内容都集中到单个分片中,并在每个 worker 上复制。因此,对任何 worker 的查询都可以在本地访问 引用 信息,无需从另一个节点请求行,因此也不会产生此类网络开销。引用表没有分布列,因为无需区分每行的各个分片。
引用表 通常很小,用于存储与在任何工作节点上运行的查询相关的数据。例如,订单状态或产品类别等枚举值。
当与 引用表 交互时,我们会自动对事务执行两阶段提交 (2PC)。 这意味着 Citus 确保您的数据始终处于一致状态,无论您是在写入、修改还是删除它。
- 2PC
- https://en.wikipedia.org/wiki/Two-phase_commit_protocol
当您使用 Citus 时,您连接并与之交互的 coordinator 节点是安装了 Citus 扩展的常规 PostgreSQL 数据库。 因此,您可以创建普通表并选择不对其进行分片。 这对于不参与连接查询的小型管理表很有用。 一个示例是用于应用程序登录和身份验证的用户表。
创建标准 PostgreSQL 表很容易,因为它是默认值。这是你运行 CREATE TABLE 时得到的。在几乎每个 Citus 部署中,我们都会看到标准 PostgreSQL 表与 distributed 和 reference 表共存。事实上,如前所述,Citus 本身使用本地表来保存集群元数据。
上一节将分片描述为在 worker 节点内的较小表中包含分布式表的行的子集。本节详细介绍了技术细节。
协调器上的 pg_dist_shard 元数据表包含系统中每个分布式表的每个分片的行。该行与分片 ID 相匹配,分片 ID 的范围是一组哈希整数 (shardminvalue, shardmaxvalue)。
SELECT * from pg_dist_shard;
logicalrelid | shardid | shardstorage | shardminvalue | shardmaxvalue
---------------+---------+--------------+---------------+---------------
github_events | 102026 | t | 268435456 | 402653183
github_events | 102027 | t | 402653184 | 536870911
github_events | 102028 | t | 536870912 | 671088639
github_events | 102029 | t | 671088640 | 805306367
(4 rows)
如果 coordinator 节点要确定哪个分片包含 github_events 行,它将对行中分布列的值执行哈希算法。然后此节点检查哪个分片的范围包含此哈希值。 定义范围后,哈希函数的image(图像)就是两者的并查。
假设分片 102027 与相应的行关联。在某个 worker 中的 github_events_102027 表中读取或写入此行。是哪个 worker?这完全由元数据表确定。分片映射到 worker 的过程称为分片放置(shard placement)。
coordinator 节点将查询重写为引用特定表(例如 github_events_102027)的片段,并对相应 worker 运行这些片段。 下面的查询示例在后台运行,旨在查找分片 ID 为 102027 的节点。
SELECT
shardid,
node.nodename,
node.nodeport
FROM pg_dist_placement placement
JOIN pg_dist_node node
ON placement.groupid = node.groupid
AND node.noderole = 'primary'::noderole
WHERE shardid = 102027;
┌─────────┬───────────┬──────────┐
│ shardid │ nodename │ nodeport │
├─────────┼───────────┼──────────┤
│ 102027 │ localhost │ 5433 │
└─────────┴───────────┴──────────┘
在 github_events 示例中,有四个分片。每个表的分片数量在其在集群中分布时是可配置的。
最后请注意,Citus 允许复制分片以防止数据丢失。有两种复制“模式”:Citus 复制和流复制。前者创建额外的备份分片放置并针对所有更新它们的所有它们运行查询。后者效率更高,利用 PostgreSQL 的流式复制将每个节点的整个数据库备份到一个 follower 数据库。这是透明的,不需要 Citus 元数据表的参与。
由于可以根据需要将分片及其副本放置在节点上,因此将包含相关表的相关行的分片放在同一节点上是有意义的。 这样,它们之间的连接查询可以避免通过网络发送尽可能多的信息,并且可以在单个 Citus 节点内执行。
一个示例是包含商店、产品和购买的数据库。如果所有三个表都包含 - 并且由 - store_id 列分布,那么限制在单个存储中的所有查询都可以在单个工作节点上高效运行。即使查询涉及这些表的任意组合也是如此。
跨多台机器分散查询允许一次运行更多查询,并允许通过向集群添加新机器来扩展处理速度。此外,如上一节所述,将单个查询拆分为片段可以提高专用于它的处理能力。 后一种情况实现了最大的并行性,这意味着 CPU 内核的利用率。
读取或影响均匀分布在多个节点上的分片的查询能够以“实时”速度运行。 请注意,查询的结果仍然需要通过协调器节点传回,因此当最终结果紧凑时(例如计数和描述性统计等聚合函数),加速效果最为明显。
在执行多分片查询时,Citus 必须平衡并行性的收益与数据库连接的开销(网络延迟和工作节点资源使用)。要配置 Citus 的查询执行以获得最佳的数据库工作负载结果,它有助于了解 Citus 如何管理和保存协调节点和工作节点之间的数据库连接。
Citus 将每个传入的多分片查询会话转换为称为任务的每个分片查询。 它将任务排队,并在能够获得与相关工作节点的连接时运行它们。对于分布式表 foo 和 bar 的查询,下面是连接管理图:

coordinator 节点为每个会话都有一个连接池。每个查询(例如图中的 SELECT * FROM foo)仅限于为每个 worker 的任务打开最多 citus.max_adaptive_executor_pool_size(整数)个同时连接。 该设置可在会话级别进行配置,以进行优先级管理。
在同一连接上按顺序执行短任务比为它们并行建立新连接更快。 另一方面,长时间运行的任务受益于更直接的并行性。
为了平衡短任务和长任务的需求,Citus 使用 citus.executor_slow_start_interval(整数)。 该设置指定多分片查询中任务的连接尝试之间的延迟。 当查询首先对任务进行排队时,这些任务只能获取一个连接。 在每个有待处理连接的时间间隔结束时,Citus 会增加它将打开的同时连接数。通过将 GUC 设置为 0,可以完全禁用慢启动行为。
当任务完成使用连接时,会话池将保持连接打开以供以后使用。缓存连接避免了 coordinator 和 worker 之间重新建立连接的开销。但是,每个池一次打开的空闲连接不超过 citus.max_cached_conns_per_worker(整数)个,以限制 worker 中空闲连接资源的使用。
最后,设置 citus.max_shared_pool_size (integer) 充当故障保险。它限制了所有任务之间每个 worker 的总连接数。
- Citus 简介,将 Postgres 转换为分布式数据库