本文未经允许,严禁转载!违者必究!
本人未在CodingNote.cc发表任何文章,请CodingNote.cc尊重版权,尊重知识产权,不要粘贴复制他人文章为乐。
BGFX多线程渲染 1. 并发概念 1. 并发任务简介在多年以前,在手机、pc端、游戏机等,都是一个单核的CPU。这样,在硬件层面上,处理多个任务的时候,也是把一些任务切分成一些小任务。在某些时刻进行任务的切换,从A任务切换到B任务,在这个过程中,系统每一次切换任务,都是需要切换上下文的,这也就从侧面说明了一个问题,切换任务也是有时间开销。
有人会说为什么把大任务切割成小任务,在一个一个小任务进行切换那?其实这是一个客观存在的需求。举一个例子,如果大任务都是排着队执行,也不进行切割,如果打开一个app是一个任务,打开另外一个app也算是一个任务,如果点击A并在A中进行一些操作时,这个时候想打开B,很明显,如果这个不进行任务切割,那么我需要关闭A,在打开B,这样才可以。但是我又想回到A的操作的时刻,那对不起,只能重新打开。可能我举得的这个例子不是非常恰当,但是只是为了描述一个问题:即使是单核处理器,操作系统也是会把一些大任务切分成小任务,以满足刚才所说的这个实际需求,从一定程度上来达到并发的需求。
在当下这个时代,2000年之后,多核逐渐取代了单核处理器。传统的单核处理器在通过增加频率来提升处理器的性能明显已经走到了瓶颈,也就是摩尔定律。但是,对于当下的一些开发人员来说,所开发的软件工程还是大部分集中在一个任务中,虽然上文说到,单核CPU其实也是多任务的形式。这就让多核的硬件特性非常尴尬,常常是这种情况,主核CPU忙的要死,其它几个核心倒是在睡大觉。
2. 并发实现途径上节说到了其实无论是单核的硬件,或者是双核的硬件。我们的系统是把一些任务切分成了一个一个的小任务,在不停的去切换,并保护分割切换区域,把不同的小任务分门别类的封装一下。但是并没有介绍,是如何实现。
本节简单介绍一下实现并发的途径。简单来说,一种是基于线程的并发,一种是基于进程的并发;
备注: 部分c++编程指南中,并未区分并发与并行,只是统称为并发。在UE源码中是区分了两者的区别;部分 c++相关书籍指出,多核物理设备中,两个线程以上同时进行,不会进行协同称之为并行,如果有切换等待或者交换同步则称之为并发;具体区别,可自行查阅相关资料与书籍进行验证;本文将不区分并发与并行;可能对并发与并行描述并非科学严谨,欢迎有识之人讲解分析
-
线程与进程区别
-
进程
进程是并发执行过程中资源分配和管理的基本单位。进程可以理解为一个应用程序的执行过程,应用程序一旦执行,就是一个进程。每个进程都有自己独立的地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段
-
线程
线程是程序执行的最小单元,是CPU执行任务与切换的基本的单元,是依赖于进程,每个线程独占一个虚拟处理器,寄存器组,指令计数器,核处理器状态,多个线程共享当前进程的地址空间
-
区别联系
-
一个进程包含多个线程,当前进程中的线程共享本进程地址空间,不同进程之间的地址空间是独立的
-
独立的进程有自已的执行入口,执行顺序,线程不能独立运行,依托于进程由多线程控制机制控制
-
切换进程的开销大于切换线程的开销,进程创建销毁开销大,但是可靠性高,线程开销小,切换速度快,但是线程崩溃会导致进程崩溃,但是不会影响其它进程
-
-
基于进程并发
创建多个进程,然后每个进程分配任务,如果多个进程之间有通信,则使用管道,系统ipc(消息队列、信号量、信号、共享内存)以及套接字进行。安全可靠,代码健壮性高,但是开销比较大。如果用在远程链接上,不同的机器上独立运行的进程,在设计精良的系统上,又可能是一个提高并行与性能的低成本方式
-
基于线程并发
在c++11之前,大家实现多线程编程,可谓是八仙过海各显神通;有使用pthread的,有使用boost::thread的,还有使用根据各个系统平台提供的多线程API。在C++11之后,c++组织将多线程纳入了自己的组件库,这为多线程开发带来很大的便捷。依赖少了,移植性高了。
创建多个线程,对每个线程进行任务分配,如果多个线程有通信,则使用信号量,条件变量,互斥锁等手段进行。这只是简单的介绍一下,真正的多线程实现,又有各种需要考虑的问题,资源安全,任务分配合理性,以及减少切换性能开销等。对应而生的一些新的技术,比如说线程池,任务系统,线程安全智能指针等等。
-
当然多核处理系统已经诞生了很长一段时间了,但是对于程序开发人员来说,有部分人员还是忽略了这些,现在这个时间,很有必要将之纳入自己的专业技能中了。
使用并发的原因:一是关注点分离(SOC)和提高性能
-
关注点分离(SOC)
关注点进行分离;简单来说,通过将实现逻辑或者计算的一些代码进行分类,把一些不粘连的代码进行分离,这样就可以程序更加的容易理解与健壮,而且我们在处理并发的时候,更容易处理临界区域问题。
-
提高性能
利用并发提高性能有两种方式
-
任务并发
将一个任务拆分为几个部分,各个部分并发运行,从而降低总运行时间;
虽然说起来很简单,但是这个需要处理各个分任务之间可能存在的依赖问题,有时候需要付出很大的精力去处理。
-
数据并发
不同的数据部分上执行相同的指令
任务并发是,一个线程执行算法的一部分,另一个线程执行算法的另外一部分;但是数据并发是,两个线程执行的指令是相同的,但是执行的数据是不一样的
-
自从2000年以来,多核成为主流形式以后;经常会看到部分人在讲,如果性能不行,性能低下,那就多开几个线程,就会提高性能。从一定意义来讲,这句话有道理,但是也不是完全有道理。
并发何时不能用与何时能用是同等重要的事情。核心一个原因收益比不上成本的几种情况,如下所示
-
收益比不上成本
-
性能提升小于维护成本
大多数情况下,使用并发是增加了程序的复杂度,使得代码不好理解。有可能当事人写的清楚,但是后来维护的不清楚,即使在有文档的情况下也会看的一头雾水,还极易可能引起更多的问题。在这种情况下,如果提升的性能很小,那么就没有必要去做并发了。除非潜在的性能提升以及关注点分离的非常清晰,那就请不要用并发
-
性能提升小于预期
我们常说,杀鸡焉用宰牛刀。在这里这句话也非常实用,操作系统会为每一个线程分配:虚拟处理器、寄存器组、指令计数器、核处理器状态等操作系统资源,那么在每次线程启动时,也会有固定的开销,然后才会把线线程加入到调度器中。那么比如说,线程中的任务完成所耗费时间小于线程启动的时间,那这个就非常得不偿失,可以用杀鸡焉用宰牛刀来描述一点都不过分
-
线程是有限资源
我们举一个简单的例子;大家都很清楚线程是需要系统资源的,假设每个线程都有1MB的堆栈空间,对于一个可用地址空间为4GB(32bit)的平坦架构的进程来说,4096个线程将会耗费光所有的地址空间。那么留给代码、静态数据或者堆数据的空间是0,那么效率怎么能高那?尽管我们使用线程池来优化线程所占用资源,但是也并不是灵丹妙药,在线程很多的情况下,消耗很多系统资源,也是会导致整个系统运行更加缓慢。从这一点来讲,一定得平衡好这个节点,换句话说,我们开启并发模式,一定是为了更加有价值的事情才会忽略一些限制,比如说并发可以使设计更加清晰,关注点分离的更加彻底,使当前的负载更加均衡,提高系统运行的性能,那么并发是值得去做的。
-
备注:其实写这两个小节,我是非常纠结的,如果不写,那么一些并发的背景与基础概念将介绍的含糊其辞,对于看这个文章的人来说,可能不清楚并发到底是为了解决什么样的问题,或者说接下来的多线程渲染是否是行业主流趋势,没有一个清晰的了解。但是写了这一段,又觉得少了很多东西,比如说一些实际存在的profile数据证明;另外是我读了一些书籍以及博客,整理所写的这些东西,总觉得哪里少了点东西,哪里说得不准确。如有有识之人指正或者找我讨论,我欢迎至极。
3. 生产者消费者模型为什么要单独拎出来这个基础的多线程模型那。其实主要是为了后面多线程渲染的方案做一个基础预热,其实下面第二节所讲的多线程渲染方案,主要是围绕生产者消费者展开。如果是否要考虑现代api的一些特性,将围绕分摊编码器、编码器分摊是否值得去介绍,具体的一些思考以及理解,将会在第三节简单展开来说,受自己新渲染api掌握的深度局限,可能思考的方向并非完全正确,有指正之人,将感激不尽。
本节只介绍单生产者单消费者模型,至于更复杂一些的单生产者多消费者、多生产者单消费者、多生产者多消费者,在这里不赘述了,有兴趣的可以自行查阅相关的资料与文档。
3.1 线程基础本文围绕pthread的api对线程的一些基础进行讨论,c++11的相关的api将不在本文的讨论范围内。
pthread中的p代表的是POSIX,pthread是IEEE(电子和电气工程师协会)委员会开发的一组线程接口,负责指定便携式操作系统接口(POSIX)
1. 线程管理-
线程创建
int pthread_create (pthread_t *thread,pthread_attr_t *attr,void *(*start_routine)(void *),void *arg)
-
pthread_t
该数据类型表示线程在进程中的唯一的表示符,是一个无符号长整型数据(32位系统为4字节,在vc以及MinGW64中为4字节,GCC(POSIX系统以及Cygwin)为8字节)。该值不是由用户指定的,是在函数创建新的线程的标识符赋值该变量。
-
pthread_attr_t
指定线程的属性,可以使用NULL表示默认属性;默认状态下,线程在被创建时要被赋予一些属性,这个属性存储在pthread_attr_t变量中,包含线程调度策略,堆栈相关信息,join或者detach的状态等
-
start_routine与arg
指定线程开始运行的函数,而arg是start_routine所需要的参数,是一个无类型指针
-
线程属性
线程创建,在默认情况下是带有一些属性的,开发人员可以通过线程属性对象更改其中的一些属性。其中pthread_attr_init与pthread_attr_destroy用于初始化/销毁线程属性对象
然后使用属性的api来查询或者设置线程属性对象中的特定属性,如下:
-
分离或可链接状态
-
调度继承
-
调度策略
-
调度参数
-
调度范围
-
堆栈大小
-
堆栈位置
-
堆栈保护大小
-
创建完线程后,如何知道操作系统何时安排它运行,它将在那个处理器或者内核上运行?
线程一旦创建,线程就是对等的,并且可以创建其他线程,而且线程之间是没有隐含的层次结构或者依赖关系
pthreads提供了一些api来进行调度执行,可以安排线程运行为FIFO(先进先出)、RR(循环)或者OTHER(操作系统确定),并提供了设置线程调度优先级的能力,可以具体在sched_setscheduler手册中查看
pthreads API不会提供将线程绑定到特定CPU/核心的一些例子。pthread_setaffinity_np是非标准的,可以处理将线程绑定到某个cpu,具体请查看相关的api(本地操作系统会提供一些api来处理这些问题)。
-
-
线程结束
void pthread_exit (void *retval); int pthread_cancel (pthread_t thread);
线程会在下面的几种情况发生时,会终止线程
-
start_routine函数return了,线程所做的工作已经完成了
-
调用了pthread_exit函数,会将所有的线程停止
-
当前线程被另外一个线程通过调用pthread_cancel取消
-
通过调用exec()或者exit()来终止线程
-
main()函数完成,但是并没有显示调用pthread_exit函数,线程会终止。但是如果main()显示调用了pthread_exit,main()函数会被堵塞等待线程执行完毕后在退出
pthread_exit函数,retval由开发人员指定参数,这个参数可以在pthread_exit执行完后获的线程退出的一些状态
pthread_cancel函数,当前线程通过pthread_t参数指定另外一个线程的id来取消另外一个线程;当然这个只能取消同一个进程下的另外一个线程,成功返回0,失败返回对应的错误码
-
-
线程阻塞
线程创建后有两种类型,一种是分离的,一种的可链接的
显示的创建可链接或可分离的线程,使用线程属性对象,其典型的四个步骤如下:
-
声明pthread_attr_t数据类型的属性变量
-
初始化属性变量pthread_attr_init()
-
设置属性分离状态pthread_attr_setdetachstate()
-
完成后,释放属性使用的资源pthread_attr_destory()
-
pthread_join函数是线程间同步的一种方式
-
其它线程可以通过指定的threadid来等待线程完成
-
同一个线程不可以被多个线程进行join,否则会出现不可意料的问题
-
-
pthread_detach可用于显示的指定线程为可分离的,但是已经是可分离的不可以指定为可链接的
如果线程是需要可链接的,那就考虑在创建线程时设置为可链接的。如果在创建线程之前,就明确知道该线程不需要链接,运行完毕后,就结束了,那就在创建线程时设置为可分离的,这样在线程运行完毕后,一些系统资源也会一起被回收。因为系统资源有限,如果创建的可链接的线程很多的话,有可能新创建一根线程会有堆栈资源不够用的错误。
-
-
线程堆栈
开发者往往会忽略这个问题,但是这个也总是会引起一些问题,POSIX标准并没有规定线程的堆栈大小,而开发者总是喜欢使用默认的堆栈,当使用的系统资源超出了默认的堆栈大小,通常会产生程序终止或者数据损坏,然后花很大力气与时间查询这个问题。
堆栈管理的API如下:
pthread_attr_getstacksize (attr, stacksize); pthread_attr_setstacksize (attr, stacksize); pthread_attr_getstackaddr (attr, stackaddr); pthread_attr_setstackaddr (attr, stackaddr);从api的名字就可以大概了解这些函数的作用,这里不在赘述
提醒:POSIX标准没有规定一个线程的堆栈大小(又一次强调了这个问题),因此想要编写一个高质量的安全可靠的移植性强的程序,不要去依赖默认的堆栈设置,而是自己去调用pthread_attr_setstacksize来分配足够的堆栈空间(重点).
-
概述
-
互斥量API
pthread_mutex_init (mutex,attr) pthread_mutex_destroy (pthread_mutex_t *mutex) pthread_mutexattr_init (attr) pthread_mutexattr_destroy (attr) phtread_mutex_lock(pthread_mutex_t *mutex) phtread_mutex_trylock(pthread_mutex_t *mutex) phtread_mutex_unlock(pthread_mutex_t *mutex)
具体的api作用,这里不在赘述了,需要查询具体使用的可以去查pthread的开发手册
-
互斥量使用顺序
-
创建和初始化互斥量
-
多个线程试图锁定互斥锁
-
只有一个成功并且该线程拥有互斥锁
-
所有者线程执行一些操作
-
所有者线程释放互斥锁
-
另一个线程获取互斥锁重复4、5操作
-
互斥锁被销毁
pthread中互斥锁的基本概念是,在任何时间段只有一个线程可以拥有互斥锁,即使多个线程尝试去获取互斥锁,也只有一个线程会成功获取。
-
-
-
创建/销毁
-
创建
互斥锁声明是用pthread_mutex_t,并且初始化后是解锁状态,使用前需要初始化,两种初始化方式如下:
-
静态: pthread_mutex_t mymutex = PTHREAD_MUTEX_INITIALIZE
-
动态: 常规方式初始化,可以设置互斥锁的属性
-
-
销毁
pthread_mutex_destroy()释放不需要的互斥对象
-
属性
attr是可以设置互斥锁的属性,也可以指定为NULL来设置为默认值。pthread标准中关于互斥锁属性有三个如下:
-
protocol: 指定用于防止互斥锁优先级反转的协议
-
prioceiling: 指定互斥锁的优先级上限
-
process-shared: 指定互斥锁在进程共享
备注: 并非所有的系统都提供了三个可选的互斥锁属性
-
-
-
锁定/解锁
-
锁定
-
pthread_mutex_lock函数用来获取互斥锁的锁定,如果当前互斥锁已经被另外一个线程锁定了,那么将被堵塞,直到互斥锁解锁;这里就会涉及到一个问题,一个线程获取到了互斥锁,另外的线程则会一直轮询这个互斥锁,这将是会消耗系统资源的,故开发者慎用此种方式。
-
pthread_mutex_trylock()尝试锁定互斥锁,如果互斥锁被锁定,那么会返回"busy"错误码。可以防止死锁情况,比如说优先级反转
-
-
解锁
-
pthread_mutex_unlock()函数用来解锁互斥锁,解锁互斥锁后,其他线程才可以拿到该锁的所有权。但是有两种情况是错误的使用方式,如下:
-
互斥锁已经解锁了,再次解锁
-
互斥锁由另外一个线程锁拥有,当前线程进行解锁
-
-
-
-
概述
如果是互斥量的话,那么就是两种状态,这样如果有的线程没有获取到互斥锁的所有权,那么就会一直在轮询等待该互斥锁被释放,然后获取所有权,在去做一些事情。这样会浪费一些系统性能,pthread标准提供了条件变量,可以在一个线程被阻塞的时刻,被另一个线程发送信号,当收到信号时,阻塞的线程被唤醒然后获取与之相关的互斥锁。
pthread标准中条件变量的使用要搭配互斥锁。条件变量在某个线程在满足某种条件下才会被唤醒去操作临界区,避免了不断的轮询检查条件是否成立而浪费系统资源的问题。互斥量的使用,要保证同一时刻,不会有多个线程去进行pthread_cond_wait以及pthread_cond_signal,造成不可预料的问题。
pthread_cond_init (condition,attr); pthread_cond_destroy (condition); pthread_condattr_init (attr); pthread_condattr_destroy (attr); pthread_cond_wait(condition,mutex); pthread_cond_signal(condition); pthread_cond_broadcast(condition); -
创建/销毁
-
创建
条件变量的声明类型是pthread_cond_t,在使用之前需要进行初始化,初始化有如下两种:
-
静态: pthread_cond_t mycond = PTHREAD_COND_INITIALIZER
-
动态: 使用pthread_cond_init函数进行创建,条件变量的id通过函数的参数进行返回;attr可以设置条件变量的属性,attr可以设置为process-shared(并非所有的系统可以设置进程共享属性),创建和销毁条件变量属性对象是使用pthread_condattr_init()与pthread_condattr_destory()函数
-
-
销毁
释放不需要的条件变量使用pthread_cond_destory()函数
-
-
等待/释放
-
等待
pthread_cond_wait函数,该函数是阻塞当前线程。阻塞时,先锁定互斥锁,在等待条件变量时自动释放互斥锁。收到信号时唤醒线程,然后自动锁定互斥锁,解锁是需要开发人员进行解锁。
-
释放
pthread_cond_signal/pthread_cond_broadcast函数,在线程操作完临界区时,需要解锁互斥锁,这样在等待信号量的线程会获取互斥锁并锁定。当不止一个线程在在等待信号时,用pthread_cond_broadcast来代替pthread_cond_signal
-
注意事项
在等待信号量pthread_cond_wait之前要锁定互斥锁,否则线程将不会被堵塞
在释放信号量pthread_cond_signal之后要解锁互斥锁,否则其它线程将获取不了互斥锁,不被允许匹配pthread_cond_wait
-
-
简单说一下
严格来讲,semaphores并不是pthread标准的一部分,是由POSIX标准定义的,是可以和pthread一起使用,但是并没有带pthread_前缀就可见一斑了。
信号量的创建分为有名信号量与无名信号量,开发者常用的是一些无名信号量,由于他允许多个线程对临界区资源进行操作,这也是它并没有条件变量以及事件等安全的原因。
另外对于信号量,在window平台可以使用pthread_win32这个pthread的库,来使用信号量。在unix、以及linux、macos可以使用pthread,但是并非就代表,这些平台都可以使用信号量,信号量并非是pthread的标准,是POSIX的标准。在最新的macos以及ios系统中,信号量就已经不能使用了(macos以及ios中可以使用dispatch_semaphore_t,bgfx中对于macos以及ios也是用此api),已经是undefined了,所以想要使用信号量,就需要查阅相关的资料,自己对信号量在做一层封装,以方便使用与移植性。具体的api以及一些注意事项,这里就不再展开赘述了,想要了解的可以专门去查看一些资料去学习。
总结: 这个就是属于题外话了,对于引擎来说,引擎的可移植性是一个非常重要的指标,那么当开发多线程的时候,就不能单单依赖于某一个平台的api了,就需要对各个平台中功能相同接口不一样api,封装成统一的接口以供引擎开发使用。这是一个麻烦的事情,但是这个过程可以了解各个平台差异性,熟悉一些api的具体能力以及缺陷,从中甄选或者封装出来高效的统一接口,这就是在考察引擎开发人员的基本功了。所以引擎在对于一些基础性的东西来说,它不是想象中的那么困难,它只是一个组合体,让艺术人员更好的展现一些东西,而不用在担心效果以外的其他问题。所以请不要对引擎开发抱有畏惧心态,万丈高楼平地起,都是简单的东西凑成了不简单而已。
-
概述
先回归最原始的问题,多线程是为了关注分离点以及提高性能;那么使用生产者消费者模型,拆解任务,把任务拆解为提交任务与执行任务,代码框架更加清晰,更加容易拓展。另外,生产者消费者模型的临界区资源保护处理相对清晰,多任务处理,提高数据并发处理的效率;并且在现下这种硬件,更容易的提高程序的性能。也就是说生产者消费者模型也是遵循这个规则。
-
具体思路
利用信号量,将生产者消费者任务进行分割,生产者作为任务提交者,消费者作为任务执行者,这样逻辑代码将分割处理。使用双队列队以及信号量临界区资源进行保护以及同步。简单的提供一个生产者消费者例子来说明一些问题。
例子中的代码是对信号量以及线程进行了封装的接口,感兴趣的可以查阅一些开源的引擎的源码,推荐ue。一般多线程开发,不会去直接调用一些线程库或者平台提供的线程的api,而是对其进行一定意义上的封装,对外提供统一接口。这样接口易用,并且如果平台对线程api进行了修改,也可更好的维护,简单的说就是健壮性以及拓展性都会提高。
说明:该代码是笔者自己学习验证一些多线程方案的一个demo案例,虽说比较简陋,但是大体框架以及思路是没有问题的#pragma once #include "ThreadSemaphore.h" #include "ThreadMutex.h" #include "ThreadQueue.h" #include <unistd.h> namespace ThreadMultiRender { class ThreadDoubleQueue :public ThreadQueue { public: //区分一下初始化与赋值的区别,c++规定中,对象的成员变量的初始化动作是发生在进入构造函数本体之前 //而赋值,是首先调用默认构造函数对成员变量进行设初值,然后再赋予新值,对比来看性能显而易见,如果对象多了就明显了 //比如说成员变量的内存对齐,简单的手动对齐,还有更加复杂的一些方式,当然都是一些简单的事情组装出来的 //当然这个例子只是一个案例,更多的一些规则以及一些编码细节都没有遵循,但这些是应该去做的 //比如说方法的读写属性,如果确认方法百分百类内自己调用,那么就要声明为私有的,防止使用起来歧义以及错误 //还有注释,不求复杂标准,但求最基本的注释一定要写出来,方正罗里吧嗦的一堆,尽量让自己写出来的代码优雅 //还有一些其他的基础的规则,还是建议大家尽量去做,如果不清楚,可以多读读EffectiveC++系列 ThreadDoubleQueue() : m_EncoderList(0) , m_RenderList(0) { } virtual ~ThreadDoubleQueue() { } //MainThread call this function virtual void EngineUpdate() { BeginRender(); //Submit Render CMD m_PrintMutex.Lock(); m_EncoderList += 1; LOGI("MainThread=================================:%f", m_EncoderList); m_PrintMutex.UnLock(); Present(); } //RenderThread Call this function virtual void RenderOneFrame() { m_RenderSem.WaitForSignal(); //m_RenderList = 2; m_PrintMutex.Lock(); LOGI("RenderThread===:%f", m_RenderList); m_PrintMutex.UnLock(); SimulationBusy(); m_MainSem.Signal(); } private: void Swap(float lhs,float rhs) { float temp = lhs; lhs = rhs; rhs = lhs; } void SimulationBusy() { sleep(3000); for (int i = 0; i < 10000000; i++) { float value = 10 * 20 * 4.234 * 2341; } } //唤醒渲染线程 void BeginRender() { m_RenderSem.Signal(); } //等待渲染线程渲染完毕,交换缓冲队列 void Present() { m_MainSem.WaitForSignal(); //Swap(m_EncoderList,m_RenderList); float temp = m_EncoderList; //m_EncoderList = m_RenderList; m_RenderList = temp; m_PrintMutex.Lock(); LOGI("Swap CMD m_EncoderList ===:%f", m_EncoderList); LOGI("Swap CMD m_RenderList ===:%f", m_RenderList); m_PrintMutex.UnLock(); } private: float m_EncoderList; float m_RenderList; ThreadSemaphore m_MainSem; ThreadSemaphore m_RenderSem; ThreadMutex m_PrintMutex; }; }
该代码并不能运行,只是一个框架学习demo,其中有一些类是笔者自己写的库中的封装。
其它的代码这里就不再提供了,感兴趣的可以自己去封装一套简单的跨平台线程库。这里只提供核心生产者消费的任务拆分,临界区数据保护,同步策略。
-
任务拆分
主线程唤醒渲染线程,生产渲染指令
渲染线程被唤醒后,执行渲染指令
-
数据保护
渲染线程执行渲染队列(渲染buffer)的命令,或者说读取渲染队列的渲染命令;主线程往编码队列(编码buffer)提交命令,或者说是往编码队列写渲染命令。在满足一定条件下,交换渲染队列与编码队列的命令,这样读写是分开的,不会同时读写一个buffer或者是队列,保证数据是安全的,逻辑处理也更加清晰。
-
同步策略
主线程生产完渲染指令,申请编码队列与渲染队列交换,如果渲染线程没有执行完上一次渲染队列指令,那么主线程是被阻塞;
渲染线程执行完上一次渲染队列指令,主线程结束阻塞,编码队列与渲染队列互换。渲染线程执行交换后的渲染队列指令,主线程编码下一次编码队列指令,如此循环。
-
-
总结
这是典型的双队列同步解决方案,是生产者消费者的一种解决方案。当然还有其他的方案,比如说环形无锁队列等,当然这里不再讨论这种方案,感兴趣的可自行查阅环形无锁队列这种经典模式。有人为问为啥要介绍双队列同步方案,那是因为接下来的bgfx多线程方案是基于刚才所介绍这种框架之上的。
双队列同步方案,一个特点是,主线程是比渲染线程快一次编码指令的,或者说渲染线程执行的渲染指令是滞后的,这在游戏引擎中的被称为差帧渲染。这种方式的好处是,将算力分摊,不在让渲染线程执行一些与逻辑相关的操作,只关注于自己渲染指令的执行,这样GPU的执行耗时会更加平稳,不会再出现极端的波峰与波谷现象,导致帧率波动过大。而主线程也不需要在去关心渲染指令的提交,只需要去关心相关逻辑以及一些CPU算子的处理。
Bgfx多线程渲染是以生产者消费者为基础,将逻辑拆分到生产线程,将执行拆分拆到渲染线程,使用双队列(双缓冲)来保护临界区资源。但是这并非是真正的多线程渲染,真正的多线程渲染是没有渲染线程的概念,如Vulkan、Metal以及Dx12,可以多个线程同时访问图形API。目前的图形API,如OpenGL、OpenGLES、DX9及DX10不允许多个线程同时访问图形API(多线程同时访问图形API有诸多限制)。
Bgfx中并不支持立即模式的渲染模式,它的整体框架设计,没有有区分移动端以及PC端,是主线程比渲染线程快至多一帧的延迟模式。UE4的多线程渲染框架中,提供了立即模式与延迟模式两种方式,个人认为这种框架设计能更好的释放不同平台的特性。毕竟移动端的GPU架构与PC端的GPU架构是不一样的(移动端是TBR的架构,而PC端是IBR架构)。
Bgfx虽然对于多线程的封装并不如一些商业引擎做的灵活与复杂,但是Bgfx胜在轻量。倘若让开发者将UE4的渲染系统摘抄出来,不如直接拿这个开发者祭天,这样开发者能更痛快一些。还有就是Bgfx中虽然多线程架构不是非常灵活好用,但是它在驱动层的封装,OpenGL、Metal、Vulkan以及DX系列,将绝大多数渲染所需的接口囊括进来了,因此这也是众多人员乐意使用它的原因之一。
笔者虽然对于Bgfx的了解不足Bgfx设计者的十之一二,但是笔者在学习Bgfx的过程中也会有一些自己的看法以及想法在,如下:
-
内存管理不够灵活
Bgfx中是从初始化开始,就定义了最大的Drawcall数量,并为之申请了一个非常大的内存池出来给其使用。然后内存回收起来并非是用线程安全的智能指针进行管理,而是手动去管理那个资源该回收了。如果一帧内需要绘制的Drawcall数量超过了最大值,就会崩溃,如果改变其最大Drawcall数量,那就导致整体内存又翻倍。而超过Drawcall最大数量的帧少数存在的。因此它对于一些重型的游戏引擎来说,bgfx的内存管理的方式是需要进行拓展开发。
-
代码堆积&宏满天
Bgfx中的代码逻辑,从开发者的角度来讲,确实是比较清晰的。但是如果从阅读者来讲,Bgfx的代码完全堆积在一个文件中,这就导致Bgfx的入门异常艰难,常常为了理清一个逻辑,要看好长时间的代码才能理清楚。另外一个问题是,Bgfx中的宏定义真的是满天都是,有的时候,看着看着就完全懵掉了。这就导致Bgfx的代码可读性极其差。
-
Bgfx的Encoder与新图形API的区别
Bgfx中是有编码器池的概念,即EncoderPool,Encoder从EncoderPool中分配而出。渲染线程持有EncoderPool池,每个线程可以从EncoderPool中申请至多一个Encoder。但是每个持有Encoder的线程编码渲染命令提交到m_submit(双缓冲队列之一)时,Bgfx并未有时序处理。而新的图形API中,例如Vulkan中,不同线程持有CommandBuffer(可与Bgfx的Encoder类比)是来自于不同的CommandBufferPool中,并且CommandBuffer之间可以使用事件与屏障做同步处理,这样不同的CommandBuffer之间也可以人为定义时序了,而不是像Bgfx一样不可控制,想要控制还需要开发者自己拓展。因此Bgfx多线程框架对Vulkan、Metal以及DX12来说是极其不友好的。而这块做的比较好的引擎就是U3D了,针对新的图形API提供了GraphicsJobs的多线程渲染模式,能更好的利用图形API特性。
虽然Bgfx有一些缺点,但是整体来说它是非常轻量的,并且在渲染的各个能力支持是比较全的,相较于一些成熟商业级引擎有一些不足,但是它的轻量以及完备足以让它作为一些小型引擎的渲染底层了。
1. Bgfx框架Bgfx虽然代码堆积在一个文件内,宏定义满天飞,但是它整体的框架层次边界还是很清晰的。
-
接口层
主要是在Bgfx.h这个头文件,主要包含一些渲染所使用的接口、对外所使用的数据结构
-
编码层
这一层稍微复杂些,主要涉及Context、Encoder以及CommandBuffer三个类。其主要是一些线程同步、临界区资源安全保护、Encoder编码数据如何安全提交到m_submit队列。
-
驱动层
这一层就比较简单直观,由一个基类RenderContextI,其下有对应图形API的子类,并包含一些各个图形API对应的资源封装类。而其与编码层的交互,分为两个方面
-
渲染资源的创建(例如CreateXXX、SetXXXX等等由渲染线程遍历CommandBuffer进行调用)
-
RenderQueue(包含一帧中所有的drawcall数据)中一帧渲染命令数据的执行(在Submit函数中for循环执行)
-
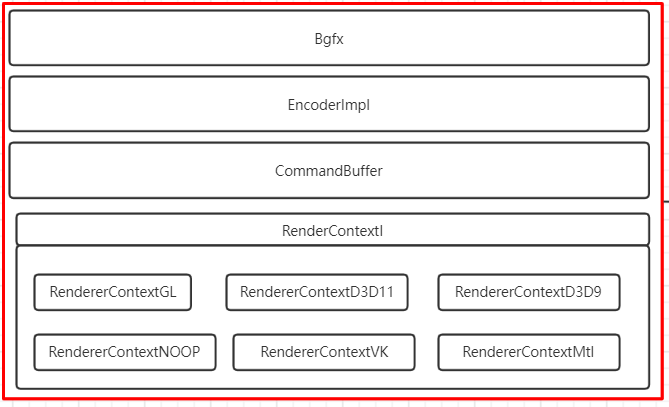
bgfx的对外接口是集中在bgfx.h这个头文件内。其主要接口提供分为两个方式,如下
-
C语言类型的接口
-
Encoder类提供的接口
这两种接口是有所关联的,C语言的接口,一部分是把命令编码进了CommandBuffer(m_submit队列成员变量),一部分是调用到了Encoder类的接口。故C语言类型的接口是包含Encoder类所提供的接口的。
1.1 对外接口-
Encoder接口
void setMarker(const char* _marker); void setState(uint64_t _state, uint32_t _rgba=0); void setCondition(OcclusionQueryHandle _handle,bool _visible); void setStencil(uint32_t _fstencil,uint32_t _bstencil=BGFX_STENCIL_NONE); uint16_t setScissor(uint16_t _x, uint16_t _y, uint16_t _width, uint16_t _height); void setScissor(uint16_t _cache = UINT16_MAX); uint32_t setTransform(const void* _mtx,uint16_t _num=1); uint32_t allocTransform(Transform* _transform,uint16_t _num); void setTransform(uint32_t _cache,uint16_t _num = 1); void setUniform(UniformHandle _handle,const void* _value,uint16_t _num=1); void setIndexBuffer(IndexBufferHandle _handle); void setIndexBuffer(IndexBufferHandle _handle,uint32_t _firstIndex,uint32_t_numIndices); void setIndexBuffer(DynamicIndexBufferHandle _handle); void setIndexBuffer(DynamicIndexBufferHandle _handle,uint32_t _firstIndex,uint32_t _numIndices); void setIndexBuffer(const TransientIndexBuffer* _tib); void setIndexBuffer(const TransientIndexBuffer* _tib,uint32_t _firstIndex,uint32_t _numIndices); void setVertexBuffer(uint8_t _stream,VertexBufferHandle _handle); void setVertexBuffer(uint8_t _stream,VertexBufferHandle _handle,uint32_t _startVertex ,uint32_t _numVertices,VertexLayoutHandle _layoutHandle = BGFX_INVALID_HANDLE); void setVertexBuffer(uint8_t _stream,DynamicVertexBufferHandle _handle); void setVertexBuffer(uint8_t _stream,DynamicVertexBufferHandle _handle,uint32_t _startVertex , uint32_t _numVertices, VertexLayoutHandle _layoutHandle = BGFX_INVALID_HANDLE); void setVertexBuffer(uint8_t _stream,const TransientVertexBuffer* _tvb); void setVertexBuffer(uint8_t _stream,const TransientVertexBuffer* _tvb,uint32_t _startVertex , uint32_t _numVertices,VertexLayoutHandle _layoutHandle=BGFX_INVALID_HANDLE); void setVertexCount(uint32_t _numVertices); void setInstanceDataBuffer(const InstanceDataBuffer* _idb); void setInstanceDataBuffer(const InstanceDataBuffer* _idb,uint32_t _start,uint32_t _num); void setInstanceDataBuffer(VertexBufferHandle _handle,uint32_t _start,uint32_t _num); void setInstanceDataBuffer(DynamicVertexBufferHandle _handle,uint32_t _start,uint32_t _num); void setInstanceCount(uint32_t _numInstances); void setTexture(uint8_t _stage,UniformHandle _sampler ,TextureHandle _handle,uint32_t _flags=UINT32_MAX); void touch(ViewId _id); void submit(ViewId _id,ProgramHandle _program,uint32_t _depth=0,uint8_t _flags= BGFX_DISCARD_ALL); void submit(ViewId _id,ProgramHandle _program,OcclusionQueryHandle _occlusionQuery ,uint32_t _depth=0,uint8_t _flags=BGFX_DISCARD_ALL); void submit(ViewId _id,ProgramHandle _program,IndirectBufferHandle _indirectHandle ,uint16_t _start=0,uint16_t _num=1,uint32_t _depth=0,uint8_t _flags=BGFX_DISCARD_ALL); void setBuffer(uint8_t _stage,IndexBufferHandle _handle,Access::Enum _access); void setBuffer(uint8_t _stage,VertexBufferHandle _handle,Access::Enum _access); void setBuffer(uint8_t _stage,DynamicIndexBufferHandle _handle,Access::Enum _access); void setBuffer(uint8_t _stage,DynamicVertexBufferHandle _handle,Access::Enum _access); void setBuffer(uint8_t _stage,IndirectBufferHandle _handle,Access::Enum _access); void setImage(uint8_t _stage,TextureHandle _handle,uint8_t _mip ,Access::Enum _access,TextureFormat::Enum _format=TextureFormat::Count); void dispatch(ViewId _id,ProgramHandle _handle,uint32_t _numX=1 ,uint32_t _numY=1,uint32_t _numZ=1,uint8_t _flags=BGFX_DISCARD_ALL); void dispatch(ViewId _id,ProgramHandle _handle,IndirectBufferHandle _indirectHandle ,uint16_t _start=0,uint16_t _num=1,uint8_t _flags=BGFX_DISCARD_ALL); void discard(uint8_t _flags = BGFX_DISCARD_ALL); void blit(ViewId _id,TextureHandle _dst,uint16_t _dstX,uint16_t _dstY,TextureHandle _src ,uint16_t _srcX=0,uint16_t _srcY=0,uint16_t _width=UINT16_MAX,uint16_t _height=UINT16_MAX); void blit(ViewId _id,TextureHandle _dst,uint8_t _dstMip,uint16_t _dstX,uint16_t _dstY ,uint16_t _dstZ,TextureHandle _src,uint8_t _srcMip=0,uint16_t _srcX=0 ,uint16_t _srcY=0,uint16_t _srcZ=0,uint16_t _width=UINT16_MAX ,uint16_t _height=UINT16_MAX,uint16_t _depth=UINT16_MAX);
从接口来看,包含了设置渲染状态(混合、模板、剪裁、深度、卷绕等)、设置矩阵、设置顶点、索引、纹理、图片、几何实例化数据等一次Drawcall所需要的渲染资源以及状态的接口。开发者通过这些接口将渲染资源以及状态设置给Encoder中,并存储到自身的缓存中,在submit函数被调用时,提交到m_submit队列中。
-
C语言类型接口
//创建GPU资源,并有相关Enum枚举标记 IndexBufferHandle createIndexBuffer(const Memory* _mem, uint16_t _flags); void setName(IndexBufferHandle _handle, const bx::StringView& _name); void destroyIndexBuffer(IndexBufferHandle _handle); VertexLayoutHandle createVertexLayout(const VertexLayout& _layout); void destroyVertexLayout(VertexLayoutHandle _handle); VertexBufferHandle createVertexBuffer(const Memory* _mem, const VertexLayout& _layout, uint16_t _flags); void destroyVertexBuffer(VertexBufferHandle _handle); DynamicIndexBufferHandle createDynamicIndexBuffer(uint32_t _num, uint16_t _flags); DynamicIndexBufferHandle createDynamicIndexBuffer(const Memory* _mem, uint16_t _flags); void update(DynamicIndexBufferHandle _handle, uint32_t _startIndex, const Memory* _mem); DynamicVertexBufferHandle createDynamicVertexBuffer(uint32_t _num, const VertexLayout& _layout, uint16_t _flags); DynamicVertexBufferHandle createDynamicVertexBuffer(const Memory* _mem, const VertexLayout& _layout, uint16_t _flags); void update(DynamicVertexBufferHandle _handle, uint32_t _startVertex, const Memory* _mem); uint32_t getAvailTransientIndexBuffer(uint32_t _num); uint32_t getAvailTransientVertexBuffer(uint32_t _num, uint16_t _stride); void allocTransientIndexBuffer(TransientIndexBuffer* _tib, uint32_t _num); void allocTransientVertexBuffer(TransientVertexBuffer* _tvb, uint32_t _num, const VertexLayout& _layout); void allocInstanceDataBuffer(InstanceDataBuffer* _idb, uint32_t _num, uint16_t _stride); IndirectBufferHandle createIndirectBuffer(uint32_t _num); ShaderHandle createShader(const Memory* _mem); uint16_t getShaderUniforms(ShaderHandle _handle, UniformHandle* _uniforms, uint16_t _max); void destroy(ShaderHandle _handle); ProgramHandle createProgram(ShaderHandle _vsh, ShaderHandle _fsh, bool _destroyShaders); ProgramHandle createProgram(ShaderHandle _vsh, bool _destroyShader); void destroyProgram(ProgramHandle _handle); TextureHandle createTexture(const Memory* _mem); void* getDirectAccessPtr(TextureHandle _handle); void destroyTexture(TextureHandle _handle); uint32_t readTexture(TextureHandle _handle, void* _data, uint8_t _mip); TextureHandle createTexture(...); TextureHandle createTexture2D(...); TextureHandle createTexture3D(...); TextureHandle createTextureCube(...); void updateTexture(TextureHandle _handle,...); void updateTextureCube(TextureHandle _handle,...); void updateTexture2D(TextureHandle _handle,...); void updateTexture3D(TextureHandle _handle,...); FrameBufferHandle createFrameBuffer(...); void destroy(FrameBufferHandle _handle); TextureHandle getTexture(FrameBufferHandle _handle, uint8_t _attachment); UniformHandle createUniform(const char* _name, UniformType::Enum _type, uint16_t _num); void getUniformInfo(UniformHandle _handle, UniformInfo& _info); void destroyUniform(UniformHandle _handle); OcclusionQueryHandle createOcclusionQuery(); OcclusionQueryResult::Enum getResult(OcclusionQueryHandle _handle, int32_t* _result); void destroy(OcclusionQueryHandle _handle); void setPaletteColor(...); void setViewXXXX(ViewId _id, const char* _name); //显示创建编码器接口、以及同步接口 Encoder* begin(bool _forThread = false); void end(Encoder* _encoder); //主线程申请交换队列接口 uint32_t frame(bool _capture = false);
这块主要是有几块重要接口(另外一小部分其它功能接口就不做介绍了)
-
bgfx对外类c接口中关于GPU资源的创建,这部分接口会返回XXHandle的数据结构。XXHandle用于索引图形API返回的句柄ID(注意出现概率很高的数据结构Memory)
-
一部分是调用到了Encoder中的接口(不在展示)。
-
关于编码器创建,编码器同步通信接口。
-
主线程与渲染线程同步通信的接口。
-
对外的数据结构,是为了更好的与主线程与渲染线程进行数据的同步交换。其涉及如下几个部分
-
bgfx初始化设置相关的据结构封装;平台属性,初始化设置,以及图形API能力支持
struct PlatformData {}; struct Init {}; struct Caps {}; const Caps* getCaps(); const Stats* getStats();
-
对带有GPU句柄返回值的渲染资源的抽象封装
#define BGFX_HANDLE(_name) \ struct _name { uint16_t idx; }; \ inline bool isValid(_name _handle) { return bgfx::kInvalidHandle != _handle.idx; } BGFX_HANDLE(DynamicIndexBufferHandle) BGFX_HANDLE(DynamicVertexBufferHandle) BGFX_HANDLE(FrameBufferHandle) BGFX_HANDLE(IndexBufferHandle) BGFX_HANDLE(IndirectBufferHandle) BGFX_HANDLE(OcclusionQueryHandle) BGFX_HANDLE(ProgramHandle) BGFX_HANDLE(ShaderHandle) BGFX_HANDLE(TextureHandle) BGFX_HANDLE(UniformHandle) BGFX_HANDLE(VertexBufferHandle) BGFX_HANDLE(VertexLayoutHandle)
从数据结构封装来看,不难看出都是一些带有GPU句柄返回值的一些资源,针对这些资源,bgfx对外提供其对应的数据结构封装,更方便主线程(编码线程)与渲染线程的交互,同时也防止误传值(EffectiveC++有介绍这个思路)
-
一次Drawcall所需要的渲染资源的抽象封装,以及一帧所有数据统计封装
struct TransientIndexBuffer {}; struct TransientVertexBuffer {}; struct TextureInfo {}; struct UniformInfo {}; struct Attachment {}; struct Attrib {}; struct AttribType {}; struct TextureFormat {}; struct UniformType {}; struct BackbufferRatio {}; struct OcclusionQueryResult {}; struct ViewMode {}; struct Resolution {}; struct Stats//一帧中相关状态的封装 {};
-
内存相关;
这个数据结构是非常重要的,主线程(编码器线程)生产渲染指令,但是有些指令是需要cpu端的数据的,比如说顶点数据。那么就会存在主线程以及渲染线程都会有拥有该份数据所有权的时刻,那么如果不对其加以读写保护,那么是会产生读写冲突等问题。bgfx中的方案是,利用Memory这个对外数据结构,将主线程的CPU数据拷贝一份到渲染线程中,这样主线程与渲染线程各持有一份自己的数据,就不会担心临界区资源的问题了。(bgfx还提供了一种方式,主线程提供一个数据释放的函数,然后以函数指针的形式交给渲染线程保管,但是该段内存的释放还是归于渲染线程管理)
struct Memory {}; struct Access {}; const Memory* alloc(uint32_t _size); const Memory* copy(const void* _data,uint32_t _size); const Memory* makeRef(const void* _data,uint32_t _size ,ReleaseFn _releaseFn=NULL,void* _userData=NULL);
-
排序优化相关
笔者目前暂未涉略到,不过按照笔者的理解是优化处理相关的一些;还有一部分是顶点打包,顶点布局也是优化相关的一些处理(顶点布局相关的处理,在ue以及u3d中都有对应的方案来优化处理,感兴趣的可以自行查看)
struct Topology {}; struct TopologyConvert {}; struct TopologySort {}; void vertexPack(...); void vertexUnpack(...); uint32_t topologyConvert(...); void topologySortTriList(...); VertexLayoutHandle createVertexLayout(const VertexLayout& _layout); void destroy(VertexLayoutHandle _handle);
编码层,主要的类为Context、EncoderI以及ComandBuffer。对接口层的具体实现,对多线程同步通信的处理,Encoder与CommandBuffer区别与联系,对临界区资源安全保护。
-
主线程与渲染线程同步的封装
基于生产者消费者模型,利用信号量机制,对渲染线程与主线程之间的同步进行封装处理。主线程申请交换双队列函数为Frame(),渲染线程渲染函数为RenderFrame()函数。
-
编码线程与主线程同步的封装
基于生产者消费者模型,利用信号量机制,对编码线程与主线程之间的同步进行封装处理。
-
Encoder与CommandBuffer区别与联系
Encoder是由EncoderPool分配,其至多可以分配八个编码器(如想添加可改动代码),并在申请Encoder时,由一把锁保护,防止多个线程同时申请编码器,其本身拥有RenderDraw、RenderBind以及RenderCompute等数据结构及变量,可以缓存编码线程编码的一次Drawcall数据,该数据是要提交到m_submit队列中的。
CommandBuffer是m_submit的成员变量,主线程(编码线程)创建带有GPU句柄的渲染资源,以Key-value的格式编码到CommandBuffer中(Key为XXHandle,Value为内存数据或XXHandle)。
在渲染线程启动时,先执行完m_render队列中CommandBuffer的渲染命令(调用驱动层封装的接口),然后在将m_render队列中N个Drawcall全部执行一遍(调用驱动层的Submit()函数)。
-
临界区资源安全保护
CommandBuffer面临多个编码线程同时进行编码,这里使用互斥锁保护
m_submit队列面临多个编码线程同时进行编码,使用一把自旋锁对m_submit进行保护
CommandBuffer中编码的渲染命令如果带有图形API返回的句柄,bgfx是返回一个XXHandle的对象给编码线程使用(这一块是有一个内存池)。其一是防止有返回GPU句柄的值,外部使用的时候传值错误(EffectiveC++有介绍);其二使用内存池,小内存从池分配,防止碎片,提高创建对象性能;其三,主线程其实也并不关心真的图形API返回句柄的值,bgfx根据XXHandle索引到对应的真正的图形API句柄再使用即可。
驱动层主要是几个方面,创建渲染资源的统一接口,执行m_render渲染命令队列的命令,渲染资源的数据结构封装。
-
GPU资源创建
渲染API统一接口封装,其基类RenderContextI,例如创建FBO、创建顶点、创建着色器对象等纯虚函数接口,每一个子类都要去实现基类中的接口。
-
RenderQueue执行
编码层优先将m_render队列中的CommandBuffer进行遍历执行,CommandBuffer记录的渲染命令是创建一些带有GPU句柄的渲染资源,然后调用对应的函数进行创建。
-
渲染资源的封装
将每一个图形api对应的渲染资源抽象为数据结构,以方便进行使用。
-
个人看法:
这里着重说一下Bgfx中关于OpenGL的拓展,Bgfx对于OpenGL做了大量的API拓展,这也是对硬件平台性能的极致压榨,也是对引擎效果跟性能的一种极致提升了。感兴趣的同学可以自行查看相关(拓展)代码。针对于驱动层,笔者有自己的一些看法与理解。如下
-
OpenGL渲染状态每次Drawcall都要重置一遍
bfx中对于OpenGL&ES渲染命令的执行(submit)函数,其中对于渲染状态,bgfx是每一次drawcall都会开启关闭大量的渲染状态。而OpenGL是状态机,一个状态的改变,如果开发人员不去改变,OpenGL会一直保持这个状态,如果开发人员频繁的去改变一些状态,这对性能来说,也是有所消耗的。UE4中是对其做了缓存处理的,每一次Drawcall都与上一次对比,这样可减少部分渲染状态反复重置的问题。
-
渲染资源的封装不够灵活
关于渲染资源的封装,bgfx更像是对渲染数据做一些简单封装以便于使用而已,并没有对其进行抽象,然后opengl、dx、vulkan以及metal都有自己的一套资源数据结构。这也不能说这种模式不好,但是如果想依靠智能指针(线程安全)管理资源的生命周期,就得需要在进行拓展了;或者是做常见的LRU缓存处理,也是一件比较头疼的事情,要写好几份代码。感兴趣的同学可以查看这块的封装,也可以去查看UE4中关于这块的处理方案,同时思考一下UE4为什么这么做?
-
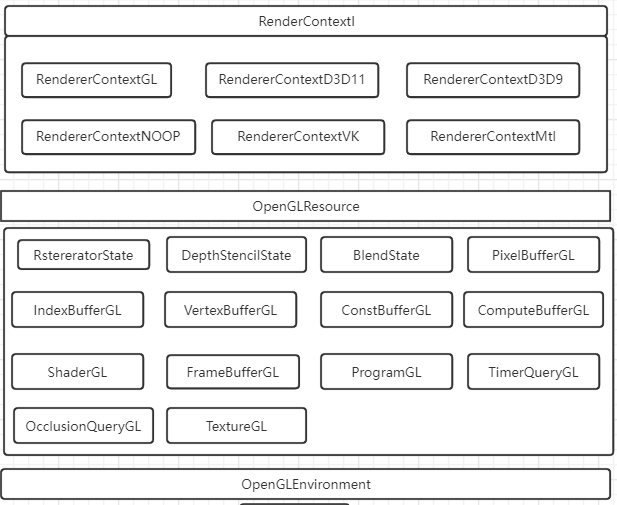
上一节从广义的框架或者层次结构上结合一些接口或者细节来介绍了一下Bgfx,由此也会对Bgfx有一个初步的认知。本节将主要分析Bgfx中多线程渲染的一些方案跟细节。主要从如下几个方面介绍,主线程与渲染线程同步通信,编码线程与主线程同步通信,GPUHandle机制的设计。
2.1 渲染线程与主线程同步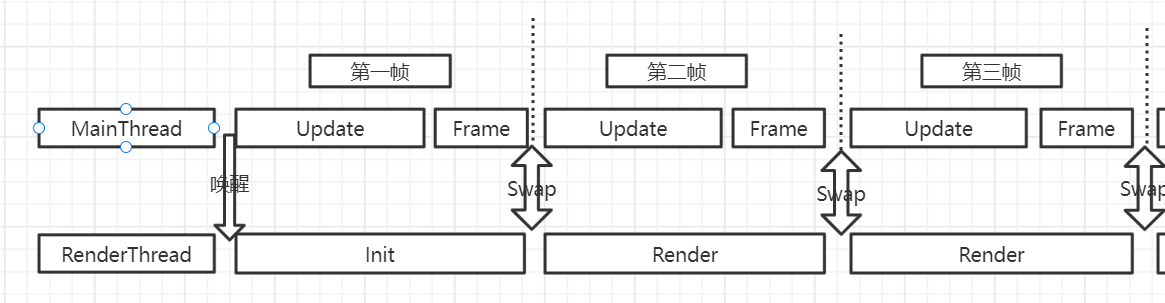
如上图三,主线程第一帧先唤醒渲染线程,然后执行Init操作,然后主线程进行编码第一帧的渲染命令,并将命令缓存到m_submit队列中。当第一帧的Update走完,标志着主线程第一帧编码命令已经结束,这个时候调用Frame函数申请与渲染线程进行命令队列的交换,如果这个时候渲染线程的Init函数执行完毕了,那么就会交换队列。主线程继续Update更新编码渲染命令到m_submit队列中,渲染线程并行执行第一帧的渲染命令(将渲染命令提交到GPU中),如此往复。如果主线程跑的比渲染线程快,主线程第N+1帧已经编码完毕,渲染线程第N帧还未执行完毕,主线程阻塞;如果渲染线程比主线程快,渲染线程第N帧已经执行结束,主线程第N+1帧未编码结束,渲染线程阻塞。这样就能保证朱祥成至多比渲染线程多跑一帧,除了在交换队列是串行外,其它时间是并行。
为了方便理解,这里笔者将bgfx的双队列方案用简单的伪代码实现出来,这样更方便大家去理解上段介绍的知识。
class Context { public: Context() { } void Init() { //主线程第一帧起始时调用一次 m_ApiSem.Post(); } //Each Frame is called by the MainThread void Frame() { m_RenderSem.Wait(); Swap(); m_ApiSem.Post(); } //Each Frame is called by the RenderThread void RenderFrame() { m_ApiSem.Wait(); //编码标记的渲染命令被驱动层执行创建真正渲染资源 CommandBuffer.Render(); Render(); m_RenderSem.Post(); } private: Render() { //m_Render渲染队列执行 } void Swap() { Frame temp; temp = m_Submit; m_Submit = m_Render; m_Render = temp; } private: RenderSem m_RenderSem; APISem m_ApiSem; Frame m_Submit; Frame m_Render; };
这段是伪代码,并不太严谨或者说可以运行,但它可以清晰的描述双队列帧同步的实现方式,这样更容易理解。细心的人可能已经发现了,这段伪代码与前面章节的生产者消费者模型非常像(严格意义上来讲是一模一样)。这就说明一个道理,往往很复杂的方案或者技术都是从一些很基础的知识上延伸出来,将一些简单的知识叠加到一起就会变得不简单。
2.2 编码线程与主线程同步本节的部分内容在第一节的第二个小部分已经简略的介绍了,本节在以图的方式具体介绍一下。
1. 同步策略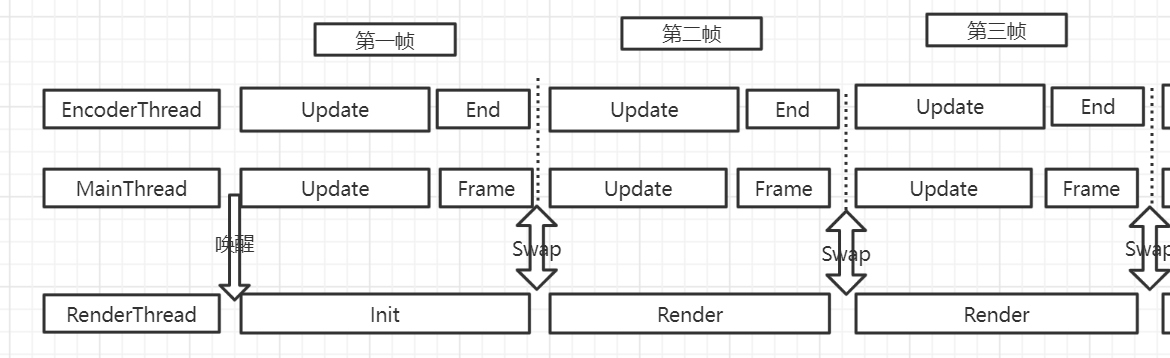
如上图四,在bgfx中,如果不申请编码器,bgfx是默认有一个编码器给主线程使用。编码线程,或者称之为工作线程,进行一些渲染命令的编码,编码线程编码完毕(如果是多个编码线程,主线程在申请交换队列时等待所有的编码线程编码完毕),然后主线程在与渲染线程交换m_submit与m_render队列。
2. Encoder与CommandBuffer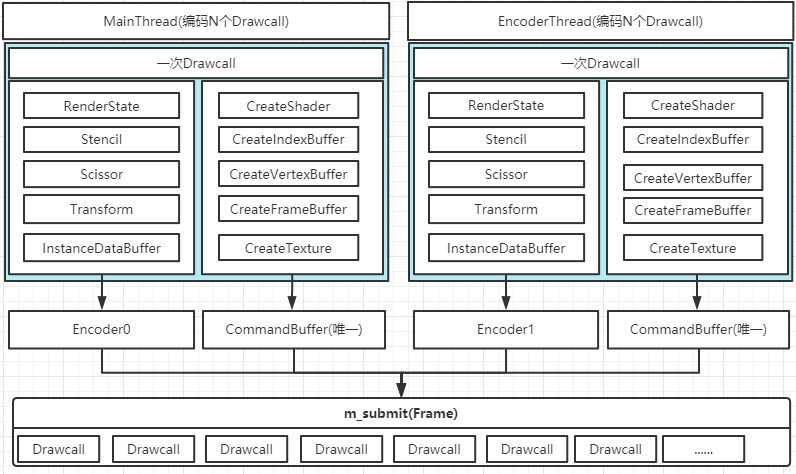
如上图五所示,其中Encoder是可以有多个,CommandBuffer在m_submit队列只有一个(具体为CMDPre与CMDPos)。CommandBuffer编码带GPU返回句柄的渲染命令,会返回Bgfx封装的XXHandle。Encoder设置一次Drawcall相关的渲染命令时,XXHandle也是参数之一。这样Drawcall创建Shader、创建FBO、创建VBO、设置渲染状态(混合、深度、模板、剪裁等)等是一个完整的Pipeline了,然后在合适的时机将这次Drawcall提交到m_submit队列中。
3. SubmitQueue安全保护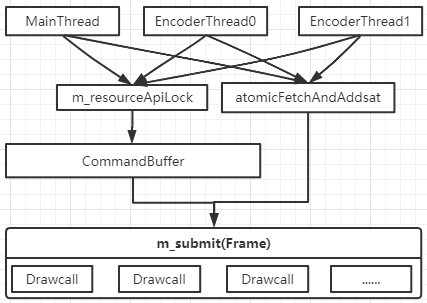
如上图六,无论是编码线程,亦或者是主线程,严格意义上来讲,都可以统一称为编码线程。区别是在与主线程有与渲染线程同步操作,而编码线程是与主线程进行同步。主线程(编码线程)在往CommandBuffer中写渲染命令时需要拿到资源锁才可以进行编码,防止多个线程同时往CommandBuffer中写入数据。编码器中一次Drawcall的缓存渲染资源(调用submit(...)函数启动提交)向m_submit中提交时,是需要拿一把锁(自旋锁),确认当前m_submit中安全的可以写入一次Drawcall渲染数据的位置,然后写入。
备注:本文不在对bgfx的view的机制进行详细介绍(由于篇幅有限,字数严重超标),感兴趣的同学可自行查看源码。
3. GPUHandle封装主线程或者是编码线程,使用CommandBuffer编码渲染命令时,图形APi是会返回GPU的句柄的(其实也就是一个int值),但是图形API的句柄ID并不会返回给主线程使用,而是返回了一个XXHandle对象回来。
这个XXHandle具体的作用是,在bgfx中作为数组的ID去找到真正的图形API的值,并对其进行操作。换句话说它更像是一个中间代理值,XXHandle代表了什么图形API的返回值。
bgfx对于XXHandle的作用如下
-
大量渲染命令的创建,都带有图形API返回值(XXHandle对象),这些值也就是一个整数而已,所以小内存会频繁申请释放;bgfx使用了内存池进行管理,避免内存碎片化,提升性能(关于这块,bgfx使用了内存换时间的一种思路,感兴趣的可以自行查阅)
-
如果真的返回给主线程一个图形API的整型值,很有可能使用时会传错,如果是结构体类型的形参,那编译期也是过不了的,运行期的时候也比较好查问题。毕竟传一个数字,属于魔法系列了,关于这块EffectiveC++系列有介绍。而且主线程或者是编码线程并不太关心真的图形API的返回值是什么,只要是可以通过一个对象或者是指针找到对应的图形API的返回值,并进行使用就可以了。
-
另外就是安全性问题了,这个XXHandle什么时机创建,什么时机释放。而bgfx采用的是谁创建,谁释放;主线程或者编码线程创建XXHandle,引用计数加一,销毁XXHandle时,其引用计数减一,等到为0时,编码DestroyXX命令销毁真正的图形API资源,在主线程下一帧编码结束后,申请交换队列时,在释放XXHandle,避免渲染线程使用了主线程创建的已经在当前帧删除掉的XXHandle对象(延迟一帧删XXHandle)。
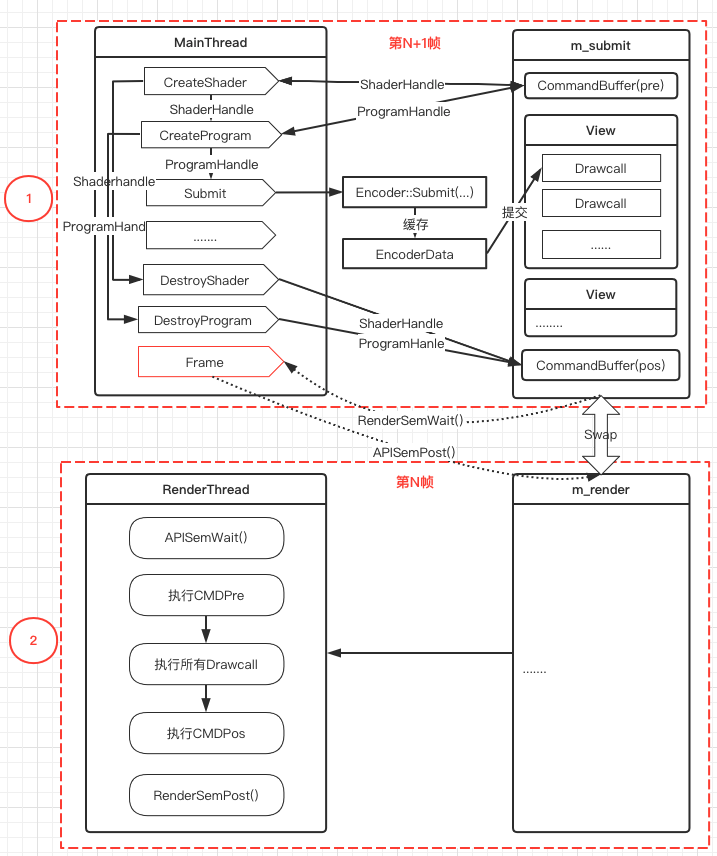
如上图七所示,主线程发送创建渲染命令的信号,CommandBuffer对其进行编码,然后返回XXHandle对象,主线程拿到XXHandle对象在通过Encoder设置给Drawcall的渲染资源中。当销毁渲染资源时,CommandBuffer也对其进行编码,然后在渲染线程真正的销毁图形API的资源。主线程在下一帧交换队列时,删除上一帧在内存池的XXHandle对象的数据,其内存给新申请的XXHandle使用。
关于返回Handle的方式,UE4中是采用了线程安全的智能指针进行管理返回一个XXRef,这样统一了驱动层与编码层资源的逻辑关系,这样更容易管理一些。但如果说性能问题,这块笔者没有亲自测试过这两种方式的性能。UE4对于线程安全的引用计数处理(自旋锁),而bgfx中编码渲染命令也是拿一把锁后,在进行XXHandle的相关处理,其实也算是不相上下。因此笔者更倾向于UE4的设计方式,UE4的设计方式统一了驱动层编码层的渲染资源的封装。
3. Vulkan编码器设计作为Khronos组织的新的一代跨平台图形API,与其兄弟OpenGL或者是GLES是完全不同的,并不向GL兼容。完全摒弃了GL的一些缺点,更加面向多核编程开发。其核心概念对于多线程渲染开发更加友好。
新一代Vulkan是一个完全脱离了OpenGL限制的图形API,不在有渲染线程的概念,也不在有渲染上下文的概念。可以将一帧内所有的渲染的创建与渲染状态的设置设置到一个CommandBuffer(也可以多个),一帧编码结束后,进行一次submit提交到VKQueue中,如下图八所示
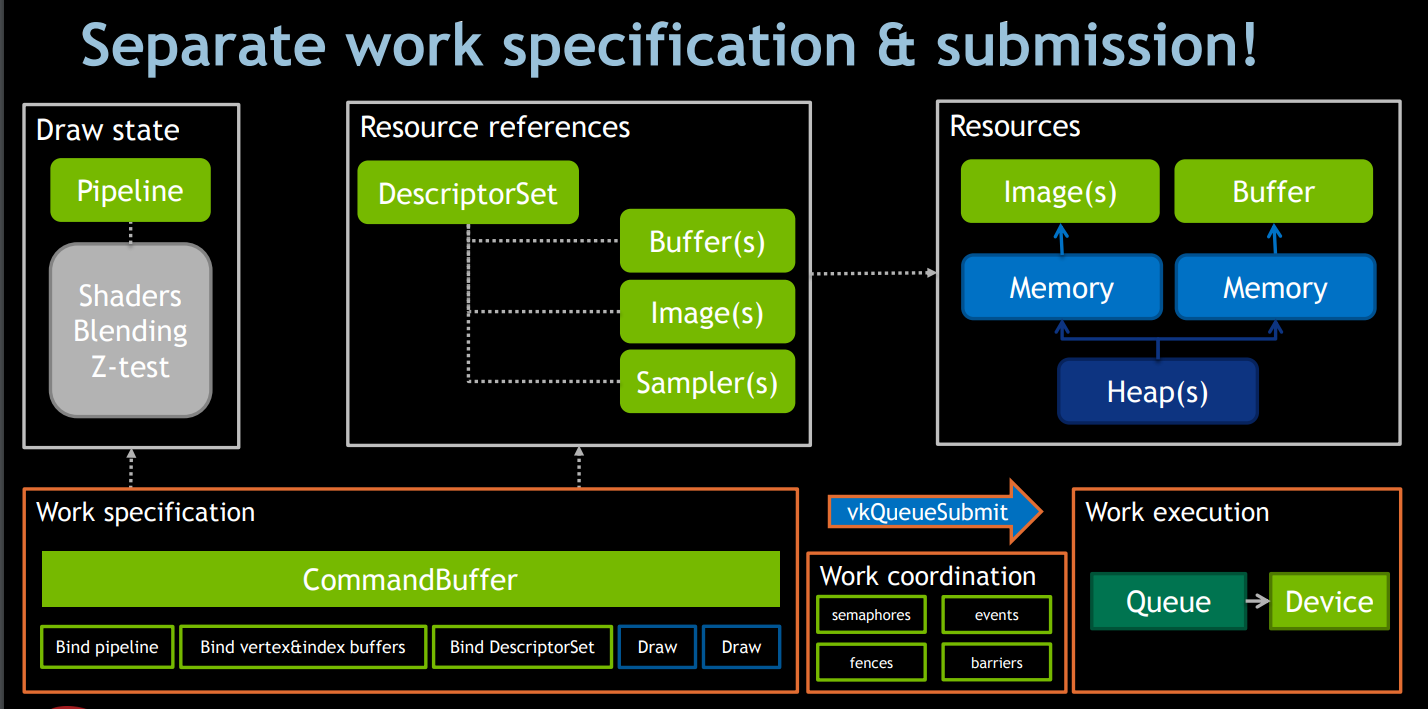
那如果是多个线程,每个编码线程可以分配一个CommandBufferPool(bgfx中只有一个EncoderPool),然后拿到CommandBuffer,进行编码。在这里提示一下,不同线程的CommandBuffer不能来自于同一个CommandBuffer中,如果是来自同一个,那么就需要外部自己同步,这样是很不划算的,图形API层级的同步肯定是比外部同步要快的多的。并且考虑到了,如果一个线程想拥有多个CommandBuffer进行编码的话,那么该线程自己独自拥有一个CommandBufferPool就好。Vulkan中编码线程也是需要与主线程进行同步,然后将渲染命令队列提交到GPU进行执行,这与bgfx是非常类似的,不同的是bgfx是主线程将渲染命令提交到渲染线程。如下图九、图十
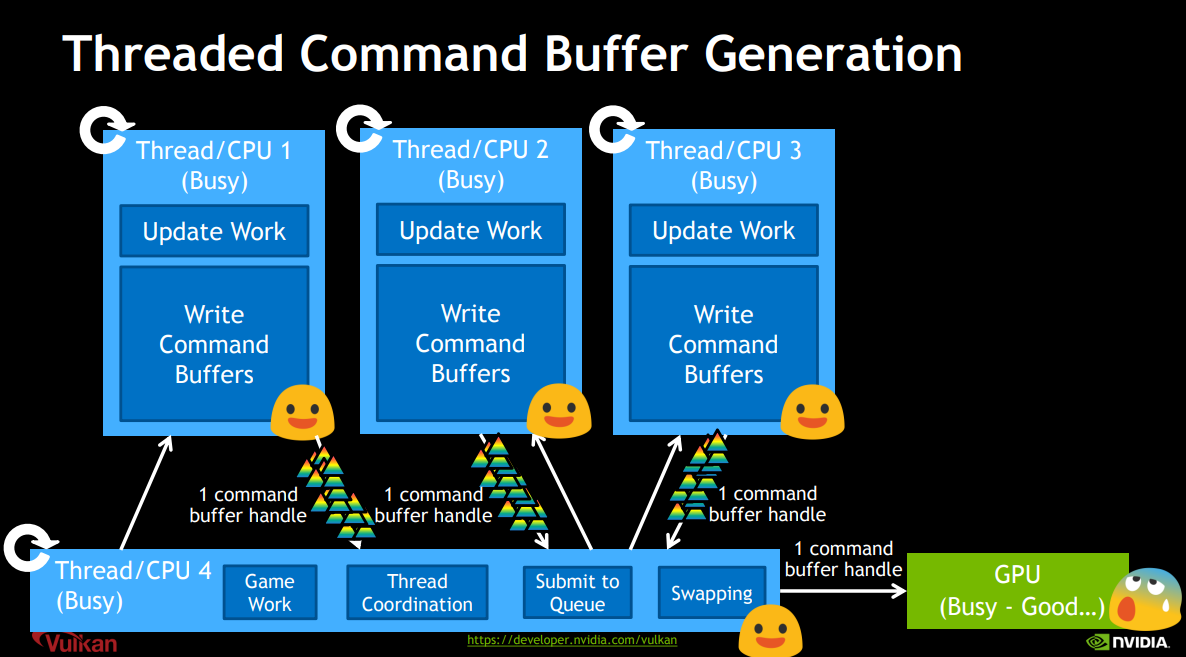

既然有多个线程进行编码,那就必然要有相关同步的处理在里面,vulkan也对此提供了全面的支持。semaphore(信号)用于同步Queue(VKQueue是可以有多个的);Fence(栅栏)用于同步GPU和CPU;Event(事件)和Barrier(屏障)用于同步Command Buffer。如下图十一
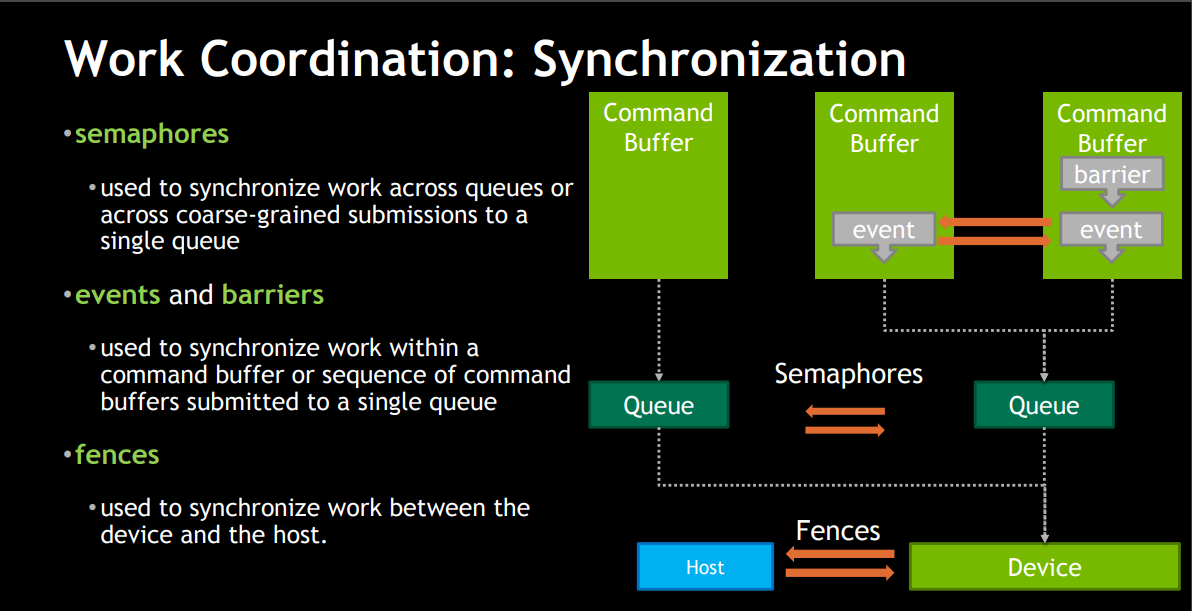 图十一
图十一
关于Vulkan的介绍,还是比较浅显,因此对于其多线程渲染的介绍可能一些细节并未介绍清楚(其实笔者了解的也算比较浅显,还未掌握精髓),如果精通Vulkan的大佬,还望不吝赐教,笔者在此感激不尽。
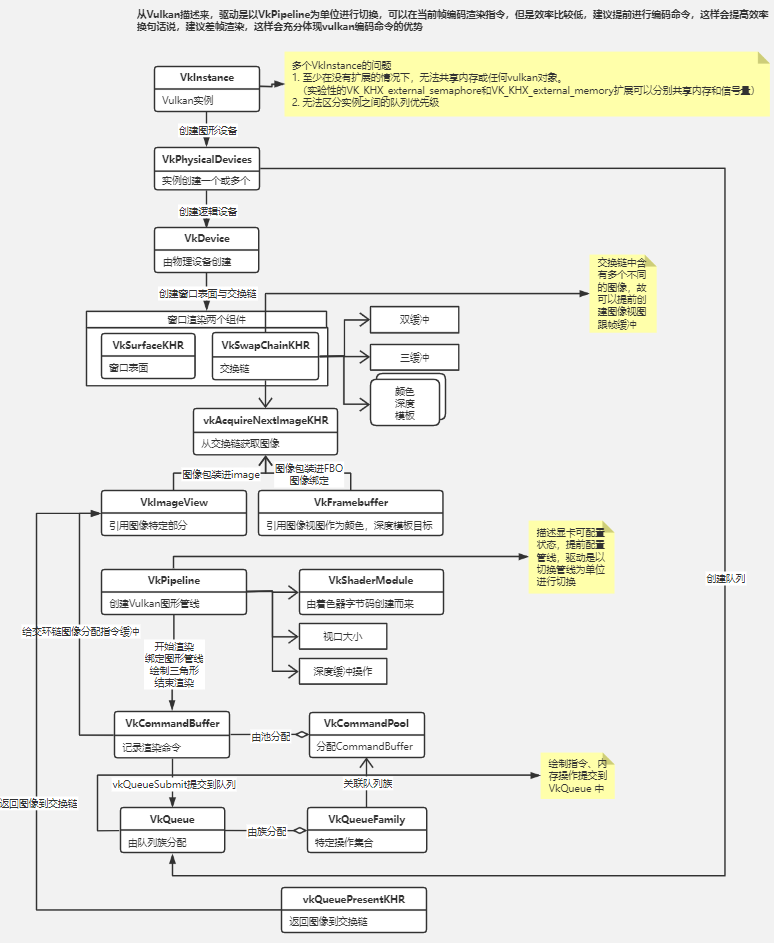
附加:如下图,使用Vulkan绘制一个三角形所需要的流程,感兴趣的可自行查阅Vulkan的文档。
 4. 结束语
4. 结束语
当代多核心并行计算架构已经是现代硬件的标配,无论是商业级游戏引擎UE4以及U3D都已经对多核并行计算的硬件架构做了多线程渲染架构的调整,还是开源的bgfx渲染引擎都对多线程渲染做了支持。因此未来的时代,随着技术与图形API的进步,多线程渲染会做的越来越好,多线程渲染将会变成基础的技术学科。
本来是想多写一些东西的,但是写着写着发现,章节字数变得异常多,因此删掉了一些章节及细节,导致某些部分只能介绍个大体的框架出来,有非常多的细节都没介绍,希望未来有时间补充出来。
Vulkan中的介绍,部分图片来源于网络,如有侵权,请联系,会删除。
在此感谢参考文献中的作者。
最后希望这篇文章能给想学习bgfx的读者带来些许帮助,如果有错误,请留言,感谢关注和收藏。
参考文献-
https://www.bookstack.cn/read/Cpp_Concurrency_In_Action/content-chapter1-1.2-chinese.md
-
https://www.runoob.com/cplusplus/cpp-multithreading.html
-
https://hpc-tutorials.llnl.gov/posix/
-
https://hpc.llnl.gov/documentation/tutorials/introduction-parallel-computing-tutorial
-
https://bkaradzic.github.io/bgfx/overview.html
-
https://developer.nvidia.com/sites/default/files/akamai/gameworks/blog/munich/mschott_vulkan_multi_threading.pdf
-
https://github.com/bkaradzic/bgfx
-
https://www.cnblogs.com/timlly/p/14327537.html#2533-rhi%E7%BA%BF%E7%A8%8B%E7%9A%84%E5%AE%9E%E7%8E%B0
-
https://zhuanlan.zhihu.com/p/44116722
-