- index: 这个索引很重要,通过 [ hashcode(key)%_buckets.len ] 确定指定key应该落到的索引位置(不用遍历key,通过轻量计算可以快速直接找到数据)
- value: value为int类型实际上也是一个索引,这个索引指向了_entries数组里的真正目标实体(_buckets并没有直接放数据内容,但HashTable里是直接把内容都放到bucket[]里的)
private struct Entry { public uint hashCode; /// <summary> /// 0-based index of next entry in chain: -1 means end of chain /// also encodes whether this entry _itself_ is part of the free list by changing sign and subtracting 3, /// so -2 means end of free list, -3 means index 0 but on free list, -4 means index 1 but on free list, etc. /// </summary> public int next; public TKey key; // Key of entry public TValue value; // Value of entry }
_entries直接存放Dictionary数据实体,加上数组的索引,每个元素有5个关键信息(索引实际不属于Entry结构的内容,方便说明放在一起解释)
- index:这个索引就是_buckets里value的对应的值,key算出hashcode后先找到指定的bucket,碰撞发送时通过其value定位到_entries指定实体
- hashCode:key的hashcode ,这里的hashcode是uint(HashTable的hashCode是不用最高位的,他的最高位1表示发生碰撞,而Dictionary使用next标记碰撞,所以会保留hashcode所有位,hashcode默认0,被填充后写入当前key的hashcode,存储hashcode是为了对比方便,key的比较先比较code会快很多,code不一样key肯定不一样,code一样key才可能一样,在当前entry被remove时,hashcode不更新,因为没有必要更新,int为值类型,数据0与12345654321消耗都是一样的,而且这里也没有用0表示特殊含义)
- key: 存储TKey
- value: 存储TValue
- next: 比hashcode多出来的一个数据,不仅标记碰撞还记录了碰撞数据的完整链路,同时也标记了空槽的完整链路。
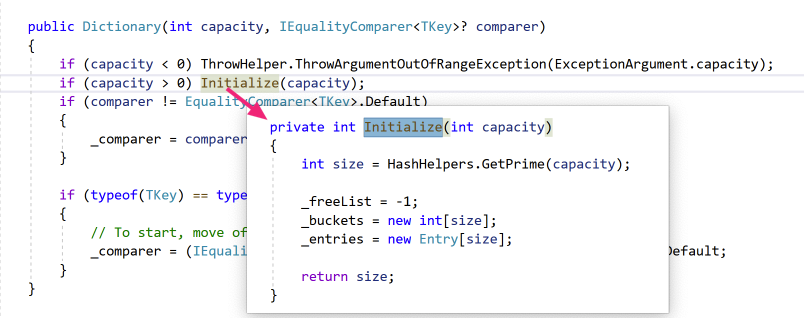
上面的代码逻辑我们可以看出较常用的参数为capacity(默认不填是取的0)。 通过Initialize函数,可以看到capacity这个值并不是这个Dictionary的真实容量,真正的大小是GetPrime(capacity) 即大于capacity的最近的一个素数,如果不填capacity那即是大于0的最近的一个素数,为3。 这里capacity是用户设置的容量,size是这个Dictionary真正的大小,count为当前Dictionary存储了多少个真正的数据 比如使用Dictionary(2)初始化时 capacity=2;size=3;count=0. _freeList在构造函数中被初始化为-1 (隐含的_freeCount初始化为0 ,因为int默认就是0所以这里不用写) _buckets及_entries在Dictionary初始化的时候也完成了初始化,数组大小已经被确定(值类型的数据资源已经全部被直接分配了)。 2.4:官方文档 下面是主要的2份官方文档
- Dotnet Source Browser : https://source.dot.net/#System.Private.CoreLib/Dictionary.cs
- MSDN : https://docs.microsoft.com/zh-cn/dotnet/api/system.collections.generic.dictionary-2?redirectedfrom=MSDN&view=net-5.0
- 数据是以怎样的顺序存入的
- 如何高效查找数据(不通过遍历的方式)
- 如何处理碰撞
- 移除数据产生的空闲位如何重复利用
- 如何扩容
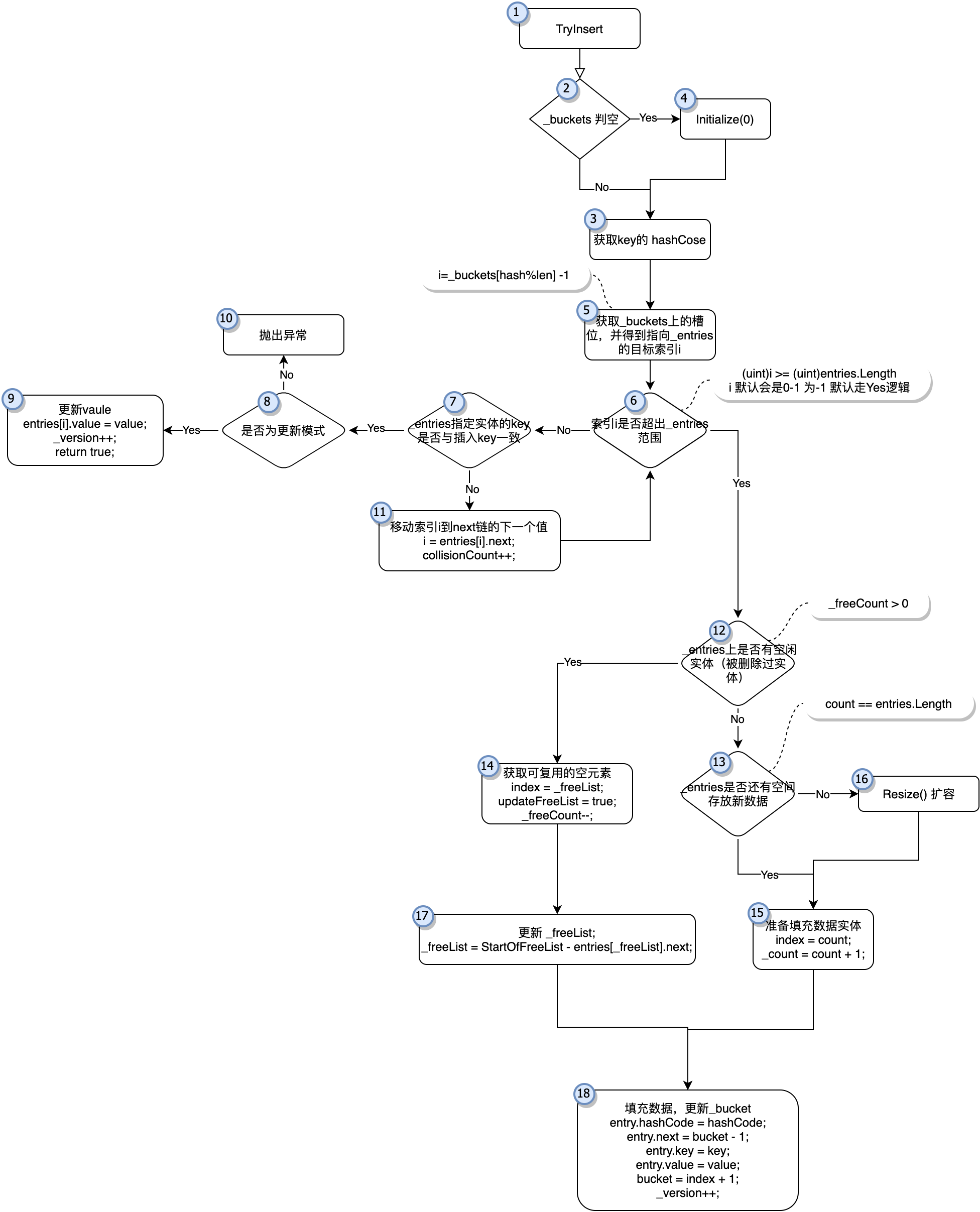 「图-TryInsert」
上图为新增元素的简单流程图(对应着TryInsert函数)
「图-TryInsert」
上图为新增元素的简单流程图(对应着TryInsert函数)
- 注意文中流程图是根据dotnet core 3.1 fx 的实际源代码省略了部分与元素存储关联不强的逻辑绘制出来的 。(不同版本coreFX 可能会略有不同)
- 涉及到流程图虽然有简化部分逻辑,但是重要核心逻辑已多次核验,这里建议您可以对照Dotnet Source Browser里的源代码一起看。
- 因为官方源代码相关逻辑篇幅大且有许多关联性,如果只贴一部分很难描述全面,所以下文中会尽量避免直接贴代码,而是选择将源代码转换为流程图或图表进行介绍。
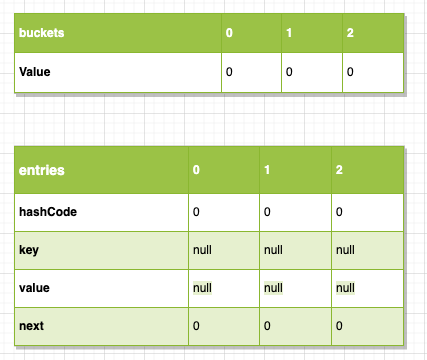 「图-entries-0」
上图以表格形式简单展示了dictionary内部的核心的buckets及entries数组结构。
dictionary插入元素的关键就是元素应该插入到entries数组的什么地方,如何在删改查时快速定位到元素。
分析插入如何执行
如图「图-TryInsert」为插入及更新的关键代码的简化流程图,在插入前有基本的参数校验,值得一提的是默认初始化函数Initialize(0)实际上将创建一个长度为3的存储空间如图「图-entries-0」
这里提一下Initialize(因为这个函数逻辑比较简单没有话流程图)
「图-entries-0」
上图以表格形式简单展示了dictionary内部的核心的buckets及entries数组结构。
dictionary插入元素的关键就是元素应该插入到entries数组的什么地方,如何在删改查时快速定位到元素。
分析插入如何执行
如图「图-TryInsert」为插入及更新的关键代码的简化流程图,在插入前有基本的参数校验,值得一提的是默认初始化函数Initialize(0)实际上将创建一个长度为3的存储空间如图「图-entries-0」
这里提一下Initialize(因为这个函数逻辑比较简单没有话流程图)
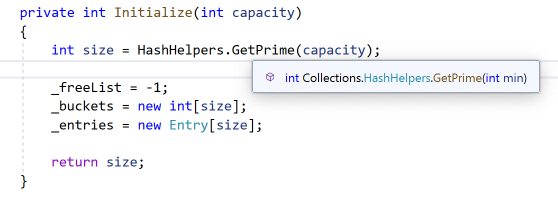 可以看到一个细节实际是dictionary的容量并不是我们指定的capacity,而是取的GetPrime的值
可以看到一个细节实际是dictionary的容量并不是我们指定的capacity,而是取的GetPrime的值
现在如果没有发生碰撞,会进入「图-TryInsert」的步骤12开始找合适的地方进行插入。(这个我们待会再看)
在这之前我们先来看下碰撞发生时Dictionary的处理机制,现在请关注「图-TryInsert」的步骤7,步骤11,他们是处理碰撞的关键。 检查到碰撞(如果_buckets[hash%len]是一个大于0的数字即表示有碰撞发生,与这个Key碰撞的数据就是entries[_buckets[hash%len] -1] )可能确实是遇到了一个重复的Key,所以需要在步骤7里进行检查,如果Key确实是重复的那很简单直接更新掉,如果现在是插入模式就抛出异常即可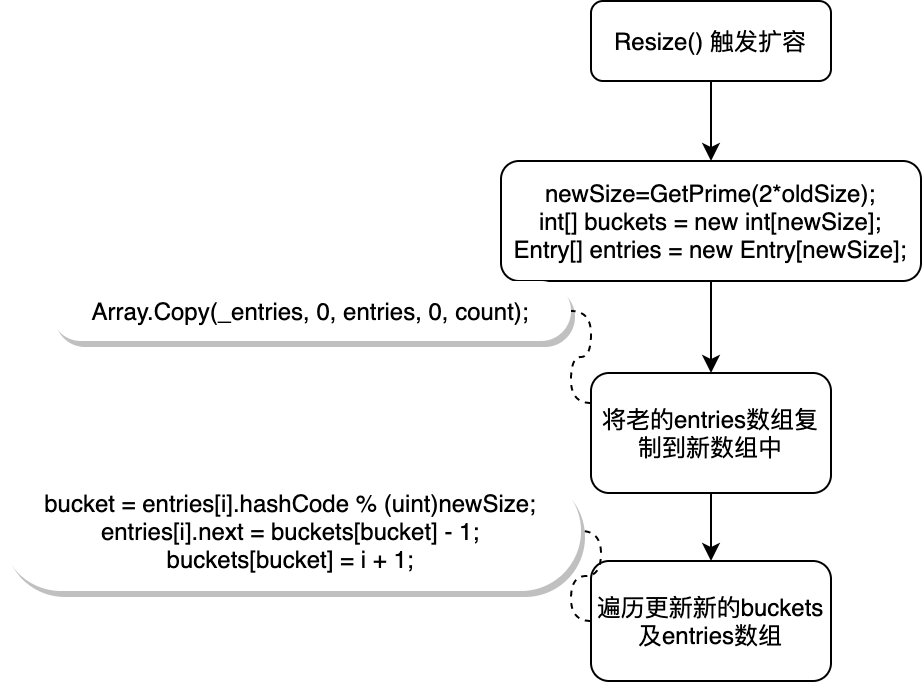
扩容的逻辑相对简单,新的大小为GetPrime(2*oldSize),需要注意的是老的entries被复制到新数组后由于len发生了变化_bucket及entries[i].next都需要重新计算并更新。hashcode用新的size求余得到bucket(这里的bucket代表的是buckets数组的一个索引),并将entries[i].next指向bucket之前指向的数据,再更新bucket的值为当前entry的索引,注意这里并没有像TryInsert一样去碰撞链中对比Key的实际值是否相等,因为扩容的数据都是老数据是不可能有重复Key的。
- entry.hashCode = hashCode; //更新hashCode
- entry.next = bucket - 1; //更新next 如果没有碰撞初始buctet是0,next就会是-1,否则next会是碰撞链的下一个索引
- entry.key = key; //填充key
- entry.value = value; //填充value
- bucket = index + 1; //更新bucket的新值指向当前entry,下次再有hashcode命中这个bucket就会先找到当前entry开始碰撞流程
- _version++; //更新数据版本,遍历时需要确保版本一致
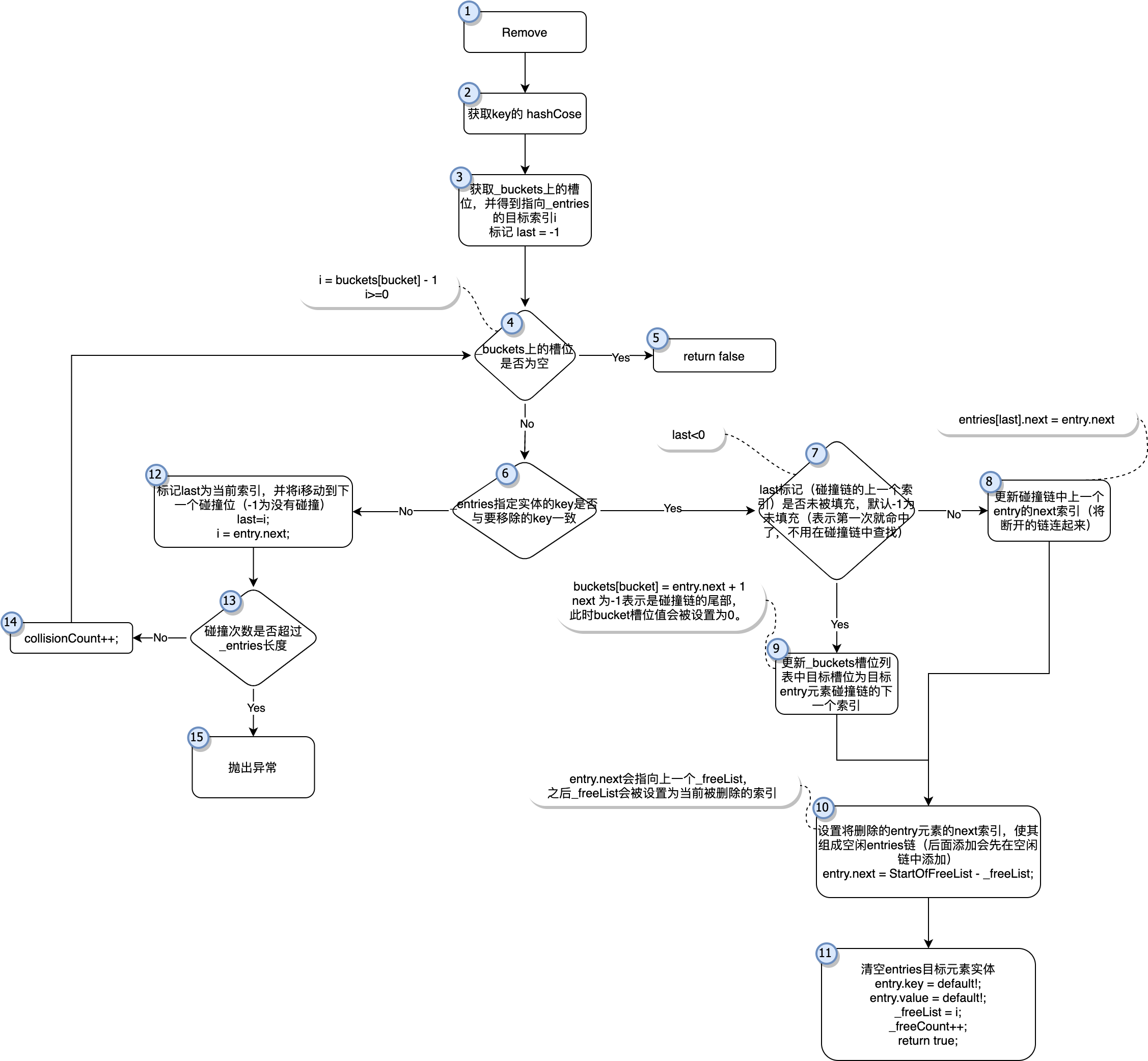 「图-Remove」
上图为移除元素的简单流程图(对应着Remove函数)
在前面的添加中我们已经提到插入数据时如果遇到空位是要先插入空位的,而空位就是在Remove中产生的,同时他还负责维护空位链表。
如「图-Remove」步骤1,2,3 与TryInsert是类似的,都是先获取到hashcode。不过在步骤4中稍有不同,通过hashcode定位到buckets上的槽位,如果槽位值没有指向entries里的任何元素(buckets[bucket] - 1>=0)就直接返回false,反之则继续
「图-Remove」
上图为移除元素的简单流程图(对应着Remove函数)
在前面的添加中我们已经提到插入数据时如果遇到空位是要先插入空位的,而空位就是在Remove中产生的,同时他还负责维护空位链表。
如「图-Remove」步骤1,2,3 与TryInsert是类似的,都是先获取到hashcode。不过在步骤4中稍有不同,通过hashcode定位到buckets上的槽位,如果槽位值没有指向entries里的任何元素(buckets[bucket] - 1>=0)就直接返回false,反之则继续
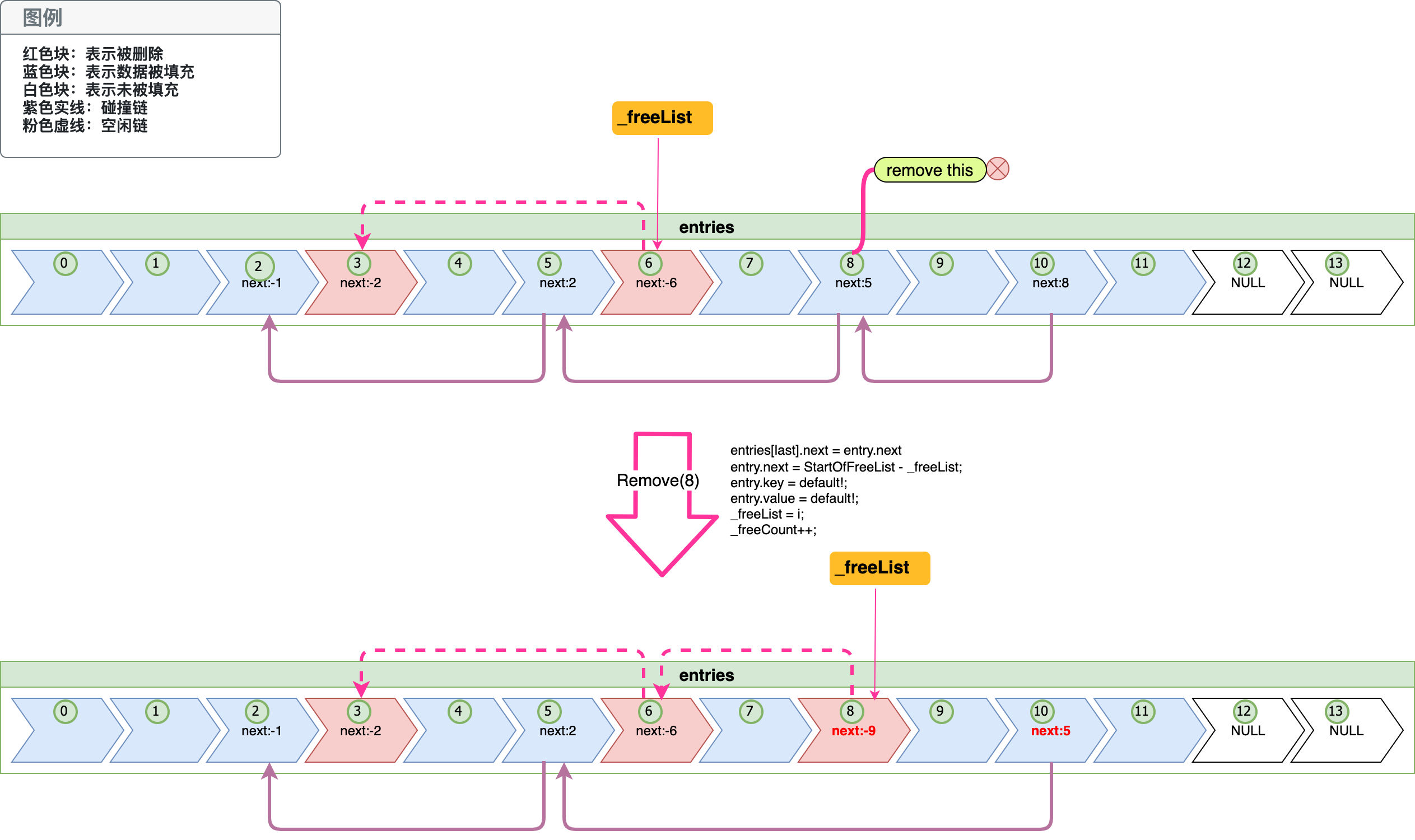
「图-删除元素」
上图简单的表述了一次删除中next在碰撞链及空闲链中的变化(上图省略了buckets的变化),上图entries上方的粉红虚线为空闲链,下方紫色实线为一条碰撞链(注意在entries中空闲链只会有一条,而碰撞链会有很多,上图只画了一条)。在「图-删除元素」我们称上面删除发生前的entries为状态1,下面删除后的为状态2。
现在我们先看状态1中的entries的空闲链,它的_freeList指向了entries[6],entries[6]就是空闲链的开始,然后-3-entries[6].next =3 就是空闲链的下一个索引为3即entries[3],这个时候我们发现entries[3].next已经是-2了,表示它已经是链尾了。 然后我们再来看下碰撞链,碰撞链从entries[10]开始,entries[10]的next是8,它就会链接到entries[8],以此类推一直找到链尾entries[2]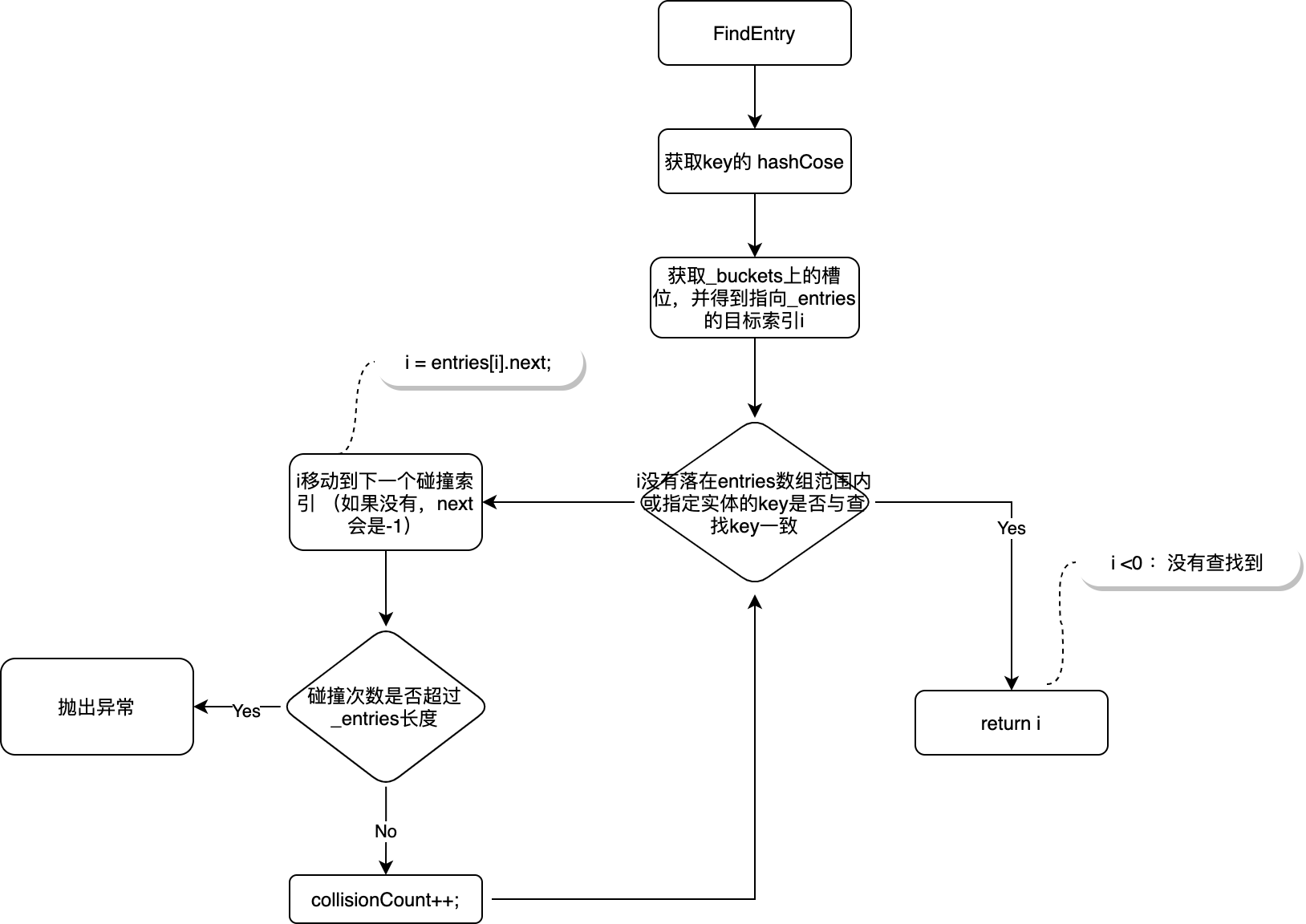
「图-FindEntry」
如上图是dictionary中通过key查找元素的关键代码的流程图,可以看到上面的流程几乎都在TryInsert及Remove中出现过,因为在新增及删除时其实都需要通过Key在dictionary里查找一遍有没有同样的Key,而查找逻辑是一致的,这里就不再重复讲述了。 四:解析一组操作的实际处理过程 4.1:实例介绍 通过上文我们已经知道dictionary是如何通过buckets与entries维护数据的,但无论如何2个数组之间的关系的确有些绕,要完全搞清楚里面的逻辑最好还是有实际的数据实例,接下来我们通过一个简单的例子来看下buckets,entries里的内容是如何变化的。(实例代码代码会触发新增,删除,扩容,碰撞及对空槽位的重复利用等关键步骤)var dc = new Dictionary<string, string>(1); dc.Add("1", "11"); dc.Add("2", "22"); dc.Add("3", "33"); dc.Add("4", "44"); dc.Remove("1"); dc.Remove("3"); dc.Add("1", "11"); dc.Add("5", "55");
代码如上,我们每运行一行,为buckets,entries里的数据做一次快照,分析其中的关系。
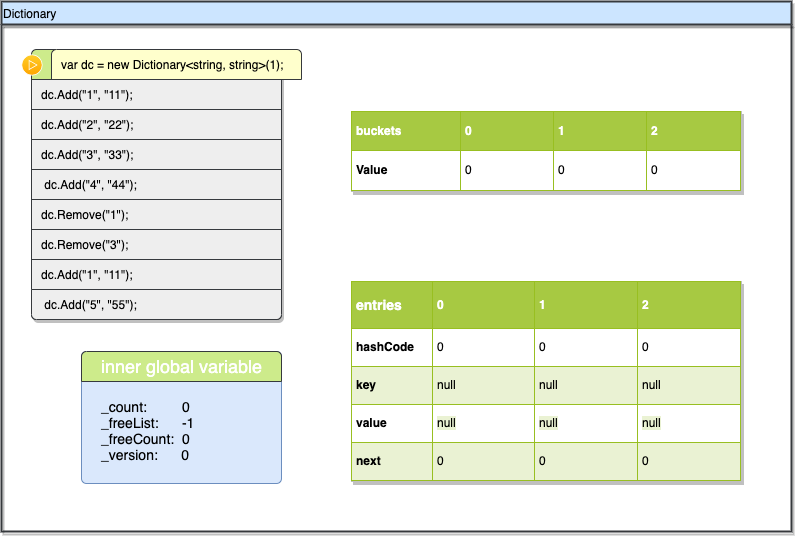
当运行new Dictionary<string, string="">(1)时,dc完成初始化,执行Initialize,上文已经提到过这个初始化函数它并不是用1来作为dc的容量,它使用大于1的第一个素数即3,所以执行初始化后dc的size会变成3,bucket与entries里的数据也都是初始值,int类型全部为0,引用类型为null。同时上图左下角记录了部分关键变量的值,注意_freeList为-1表示没有由于删除导致的空位,其余的都是默认值0
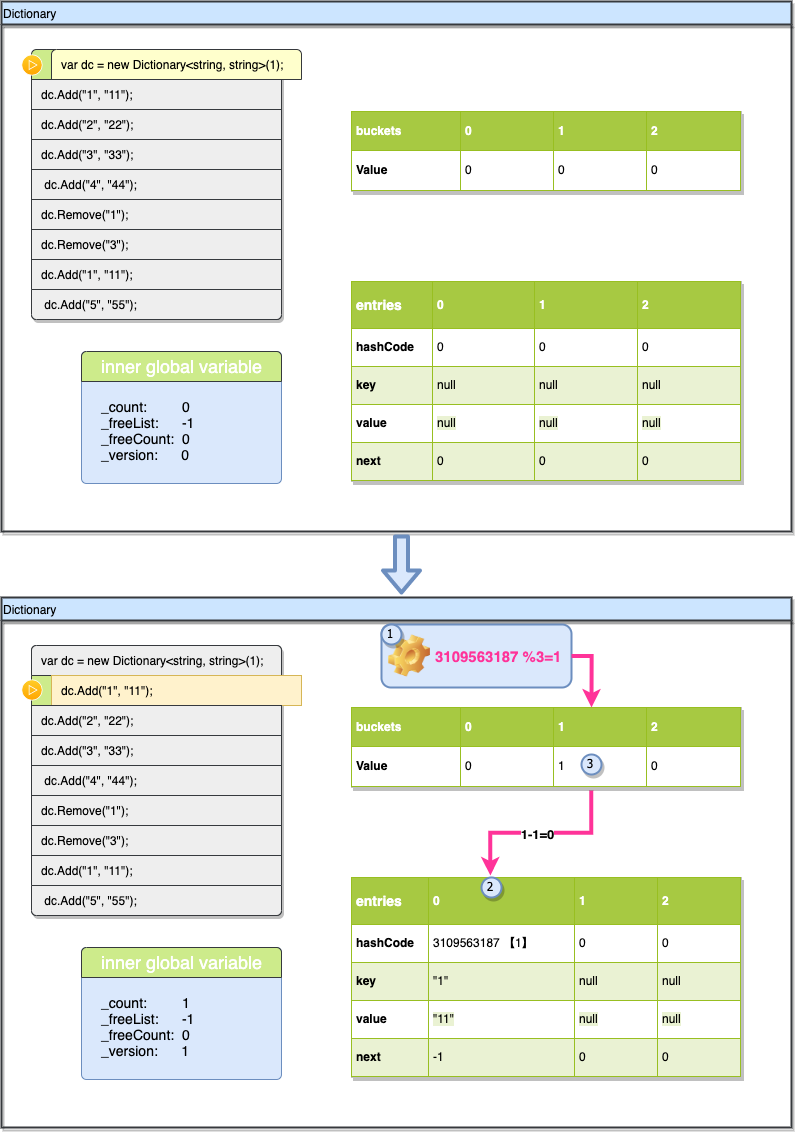 现在执行Add("1", "11"),我们计算“1”的hashcode为3109563187,然后我们通过3109563187%3的到索引1,表示他要使用buckets[1]这个槽位,这个槽位开始的值是0,表示之前没有元素使用过,可以直接插入。检查_freeList为-1,表示没有空位,开始按_count进行插入,初始_count为0,所以entries[0]就是要插入数据的位置,把hashcode,key,value插入进去,next取buckets[1]-1 为-1表示没有碰撞,最后更新buckets[1]的值为buckets[1]的索引+1即为1 ,插入完成后需要将_version++,_count也会+1。 (上图中➀➁➂表示索引数据跟新的顺序,通过这个顺序可以看出一个细节buckets[1] 虽然一开始就要用到他,而他的值是最后才确定并写入的。后面的图例中将不再标注这个顺序,hashCode后的【1】表示hashcode%len的求余结果)
4.4:Add("2", "22")
现在执行Add("1", "11"),我们计算“1”的hashcode为3109563187,然后我们通过3109563187%3的到索引1,表示他要使用buckets[1]这个槽位,这个槽位开始的值是0,表示之前没有元素使用过,可以直接插入。检查_freeList为-1,表示没有空位,开始按_count进行插入,初始_count为0,所以entries[0]就是要插入数据的位置,把hashcode,key,value插入进去,next取buckets[1]-1 为-1表示没有碰撞,最后更新buckets[1]的值为buckets[1]的索引+1即为1 ,插入完成后需要将_version++,_count也会+1。 (上图中➀➁➂表示索引数据跟新的顺序,通过这个顺序可以看出一个细节buckets[1] 虽然一开始就要用到他,而他的值是最后才确定并写入的。后面的图例中将不再标注这个顺序,hashCode后的【1】表示hashcode%len的求余结果)
4.4:Add("2", "22")
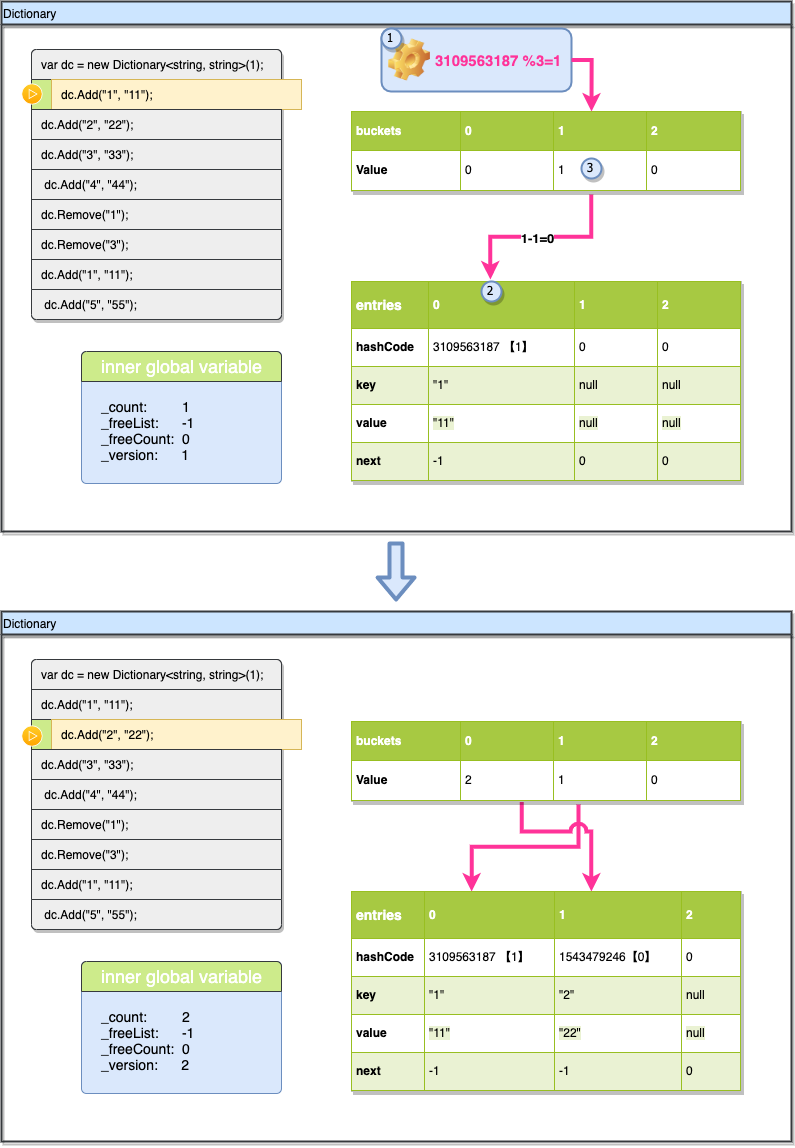 现在插入第2个Key,流程与上一个类似。这一次hashcode%len是0,所以对应的是第一个槽位,插入的位置也是以_count为索引,之前插入完成后_count已经+1,同样完成插入后_count与_version都递增1。
现在插入第2个Key,流程与上一个类似。这一次hashcode%len是0,所以对应的是第一个槽位,插入的位置也是以_count为索引,之前插入完成后_count已经+1,同样完成插入后_count与_version都递增1。
4.4:Add("3", "33")
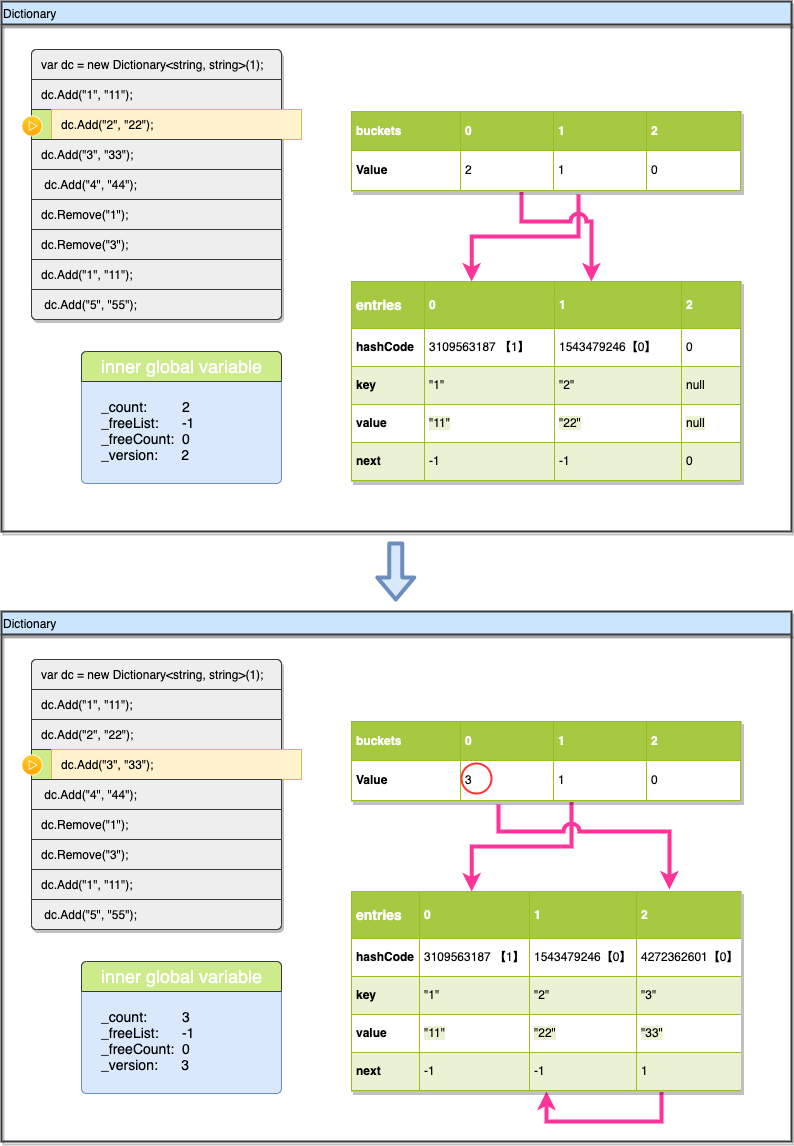 现在插入Key "3",这个时候稍微有些变化,因为插入时发生了碰撞,3的hashcode%3的值也是0(刚刚Key“2”也是0),所以我们先找到了buckets[0], buckets[0]-1=1 直接找到entries[1]对应的数据位(注意上图buckets[0]为3是指插入完成之后的值他会更新为3,之前的值直接查看该图上部分快照数据即可),然后用entries[1].key与现在插入的key进行对比(避免插入重复key),然后检查entries[1].next 发现是-1(表示他后面没有碰撞链)那就直接在后面的空位entries[2]插入新数据就可以了(这里的“后面的空”是指下一个可用空间,并不是指数组的下一个),同时现在出现了一条碰撞链由entries[2]指向entries[1](右下方红线所示),不过现在buckets[0]的值需要更新,需要更新为entries[2]的索引+1即3。
4.6:Add("4", "44")
现在插入Key "3",这个时候稍微有些变化,因为插入时发生了碰撞,3的hashcode%3的值也是0(刚刚Key“2”也是0),所以我们先找到了buckets[0], buckets[0]-1=1 直接找到entries[1]对应的数据位(注意上图buckets[0]为3是指插入完成之后的值他会更新为3,之前的值直接查看该图上部分快照数据即可),然后用entries[1].key与现在插入的key进行对比(避免插入重复key),然后检查entries[1].next 发现是-1(表示他后面没有碰撞链)那就直接在后面的空位entries[2]插入新数据就可以了(这里的“后面的空”是指下一个可用空间,并不是指数组的下一个),同时现在出现了一条碰撞链由entries[2]指向entries[1](右下方红线所示),不过现在buckets[0]的值需要更新,需要更新为entries[2]的索引+1即3。
4.6:Add("4", "44")
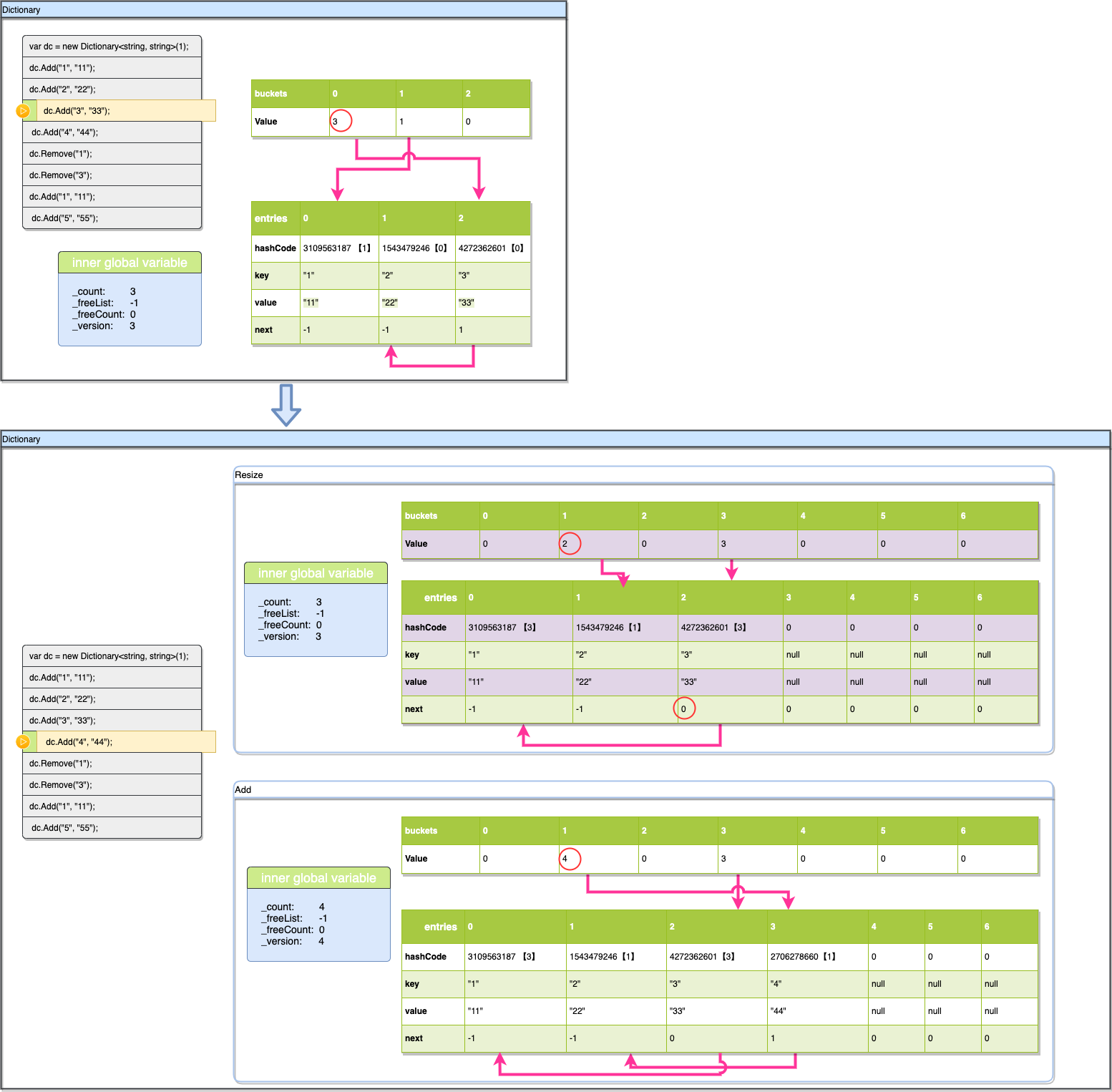 这一次的插入同样会有点特殊,因为我们dictionary开始的容量只有3,现在要插入第4个数据时,我们发现entries已经满了,在插入前,需要先扩容。
这一次的插入同样会有点特殊,因为我们dictionary开始的容量只有3,现在要插入第4个数据时,我们发现entries已经满了,在插入前,需要先扩容。
- 扩容
- 插入
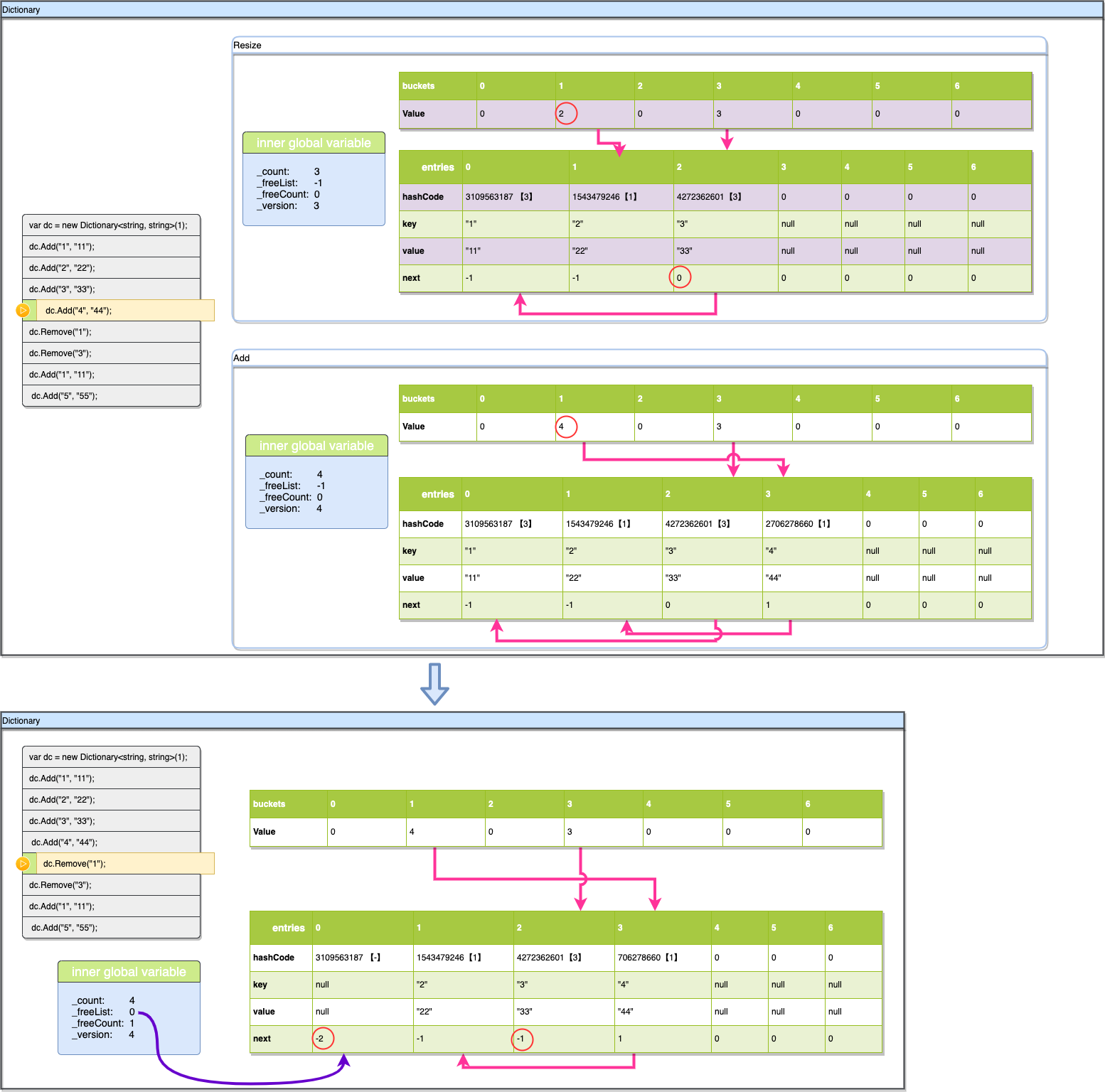
现在我们看一下删除逻辑同时跟踪一下空槽的逻辑,删除Key:“1”也是一样先计算hashcode(key)%len结果是3,通过buckets[3]的值3,可以先找到元素entries[2]进行对比(2是通过buckets[3]-1计算得出),对比Key后发现entries[2].key不是要找的值,继续查找entries[0](0是通过entries[2].next得到),确认entries[0]为目标元素后直接移除key,value对。
- _version的作用
 可以看到一旦_version发生变化就会报错,MoveNext()主要用在遍历中,最常见的foreach就会用到,所以我们说在遍历时是不能改变集合内容。在我之前的认知里,foreach时新增,修改,删除都是不能进行的,那现在我们看到Remove时_version是没有去改变了,那就是说可以删除了,当即在工程里验证了一下,的确foreach里进行Remove存在并没有报错。
可以看到一旦_version发生变化就会报错,MoveNext()主要用在遍历中,最常见的foreach就会用到,所以我们说在遍历时是不能改变集合内容。在我之前的认知里,foreach时新增,修改,删除都是不能进行的,那现在我们看到Remove时_version是没有去改变了,那就是说可以删除了,当即在工程里验证了一下,的确foreach里进行Remove存在并没有报错。
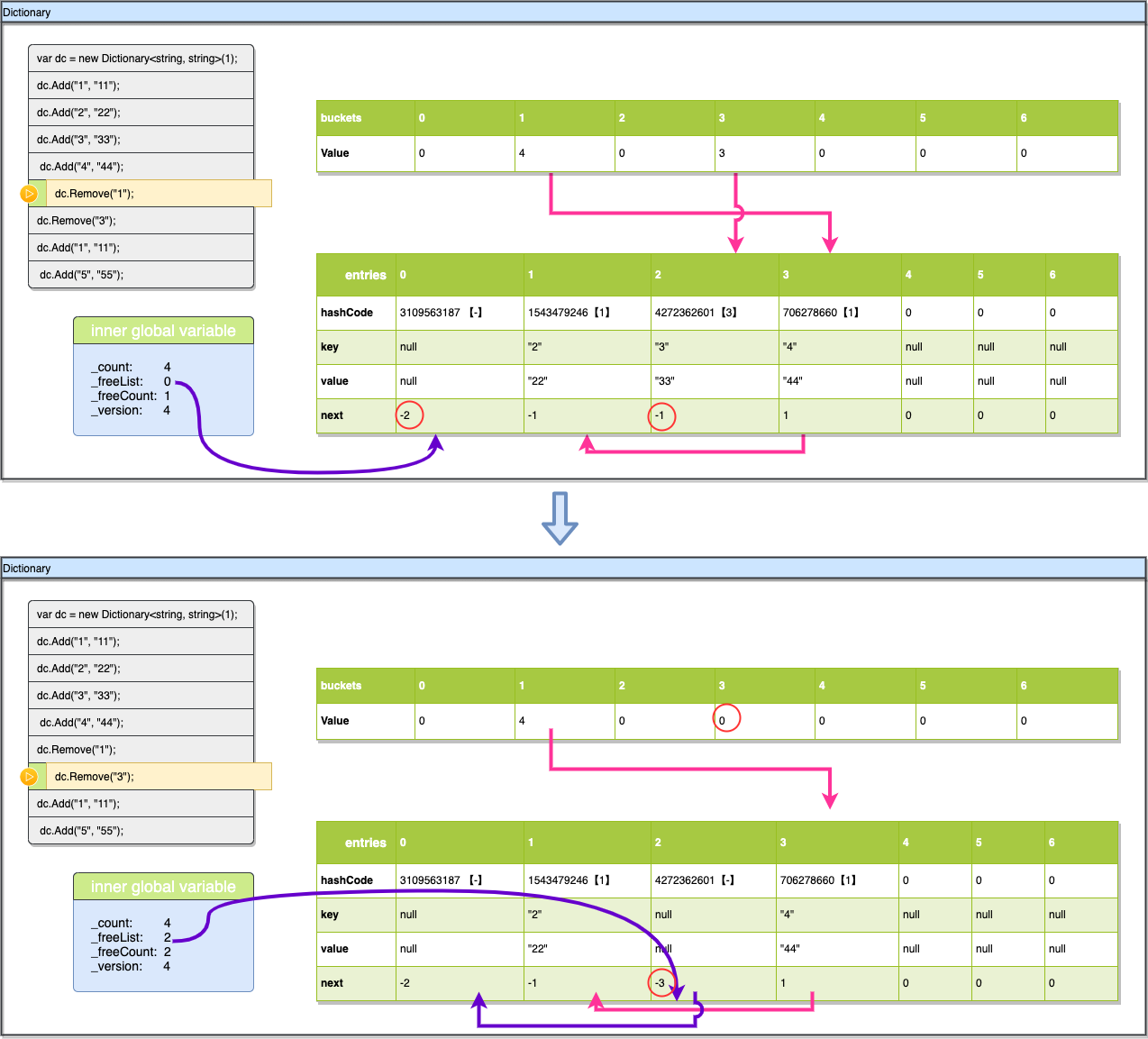
现在我们再删除一个数据,看看空闲链的dictionary里是如何维护的,与前面一步的删除类似,我们先计算Key:“3”的hashcod,hashcod%7=3 我们找到buckets[3]的值3,用3-1的到2,那entries[2]就是我们要找的链首,直接对比entries[2].key发现就是我们要找的元素,与前面的步骤一样移除。不过这里entries[2].next在移除前是-1,代表entries[2]其实是没与集合里的其他元素有碰撞的,所以没有碰撞链需要更新。不过这里还有一点与之前删除Key:“1”不一样,删除Key:“1”时被删除的值是碰撞链里的元素且不是链首,所以其实buckets里的值是不用更新的,不过现在删除的数据没有碰撞链(如果是碰撞链首也是一样处理),所以需要将buckets[3]的值更新为entries[2].next+1即为0。
现在我们来看下空闲链,同样_freeList现在变成了2 指向刚刚被删除的元素,_freeCount也递增1,不过现在有2个空位了,_freeList指向第一个空位,那第二空位(后面的空位)在什么地方,如何标记呢,现在entry的next属性又要发挥作用了,他用StartOfFreeList-next的值来标记空闲链的下一个(StartOfFreeList就是-3 我们可以用 |next|-3 这个来方便表示及计算),这个处理方式前文已经介绍过,这里就不重复描述了。我们直接看到 entries[2].next他现在应该变为StartOfFreeList - _freeList (这个_freeList是之前的_freeList为0)即-3-0=-3,所以我们看到当前的next变成了-3。-3 的指向就是 |-3|-3=0,表示此空位的下一个空位是entries[0] 现在我们再把key:“1”加回来,看一下dictionary是如何利用空位的,前面hashcode的操作都是一样的,通过hashcode%7找到buckets[3]他的值是0,表示key:“1”没在集合里没有碰撞,直接插入就可以,之前都是直接插入在entries[_count]下的,不过这次_freeList=2,所以它会先使用空位完成插入,插入完成后将_freeList变为空闲链的下一个(-3-(-3)=0)即为0,然后_version跟之前一样加1,注意这里的_count是同样没有变的,如果用空位_count的值也不会递增。最后buckets[3]的值也要更新为entries[2]的索引+1。
4.10:Add("5", "55")
现在我们再把key:“1”加回来,看一下dictionary是如何利用空位的,前面hashcode的操作都是一样的,通过hashcode%7找到buckets[3]他的值是0,表示key:“1”没在集合里没有碰撞,直接插入就可以,之前都是直接插入在entries[_count]下的,不过这次_freeList=2,所以它会先使用空位完成插入,插入完成后将_freeList变为空闲链的下一个(-3-(-3)=0)即为0,然后_version跟之前一样加1,注意这里的_count是同样没有变的,如果用空位_count的值也不会递增。最后buckets[3]的值也要更新为entries[2]的索引+1。
4.10:Add("5", "55")
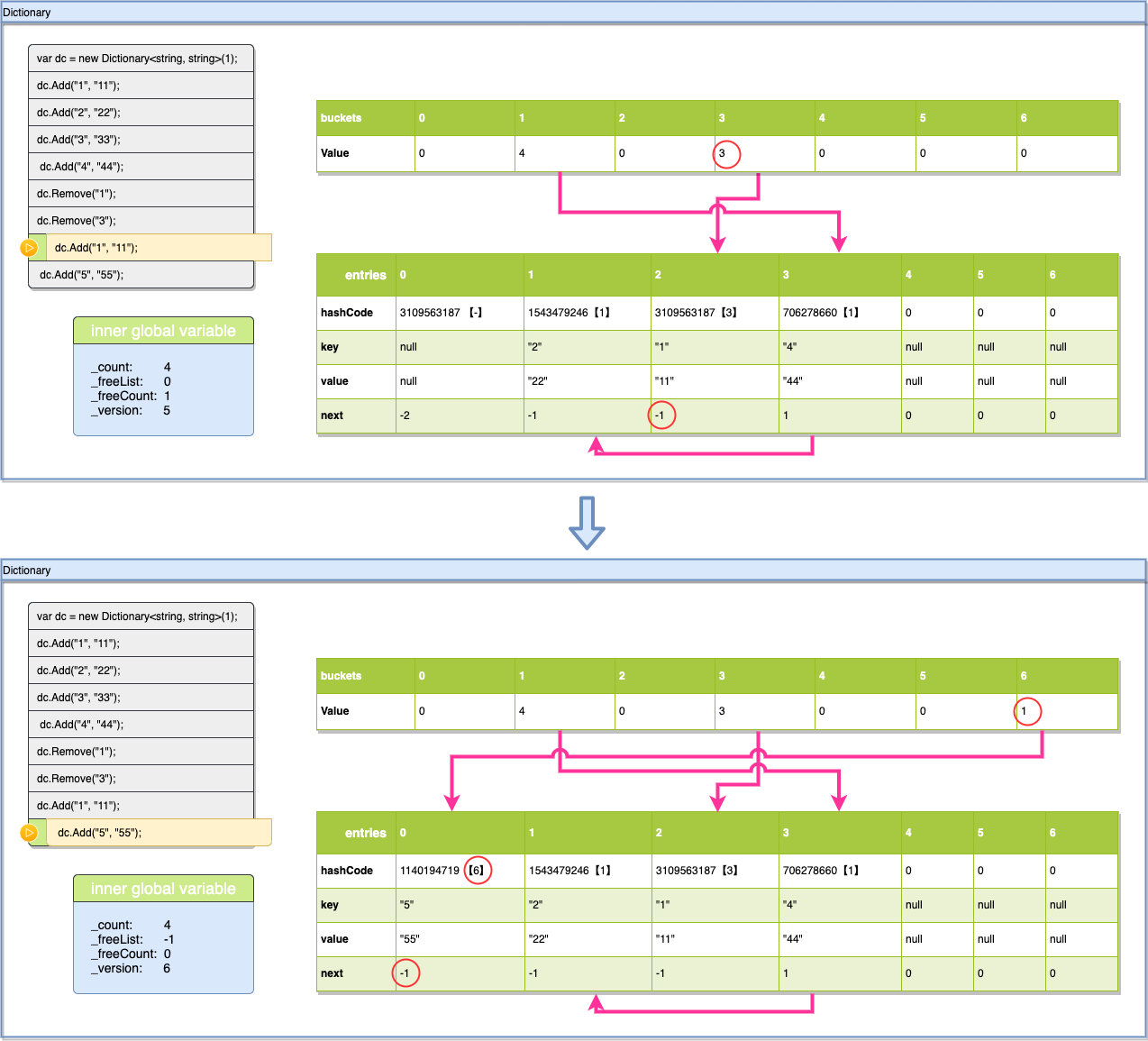 最后一步插入Key:“5”,本次插入会把空位用完,所以_freeList又会变回-1,其他数据的变化之前都描述过(上图红圈标志的地方)这里就不重复讲了,大家可以根据根据前文中讲到的规则自己计算。
五:Dictionary与Hashtable执行速度简单对比
通过以上对Dictionary实际操作,然后又分析了其中每一步其内部主要数据的变化,相信大家会对Dictionary的操作逻辑有个清楚的认识。在上文中会时不时把Dictionary与Hashtable做比较,其实MSDN上已经明确不建议使用HashTable。
最后一步插入Key:“5”,本次插入会把空位用完,所以_freeList又会变回-1,其他数据的变化之前都描述过(上图红圈标志的地方)这里就不重复讲了,大家可以根据根据前文中讲到的规则自己计算。
五:Dictionary与Hashtable执行速度简单对比
通过以上对Dictionary实际操作,然后又分析了其中每一步其内部主要数据的变化,相信大家会对Dictionary的操作逻辑有个清楚的认识。在上文中会时不时把Dictionary与Hashtable做比较,其实MSDN上已经明确不建议使用HashTable。

- Dictionary当然除了在泛型上的优势外,由于使用了2个数组维护数据,数据利用率更高,查找,插入,删除都会更快(原因上文其实都有对比提到)。只有在数据量小的时候Hashtable少用一个数组,每个元素也少一个next的属性,其内存占用可能会小一点,不过随着数据存储的越来越多,这个优势会被抹平,因为Dictionary数据数组利用率高。
- 还有一个区别,默认版本Dictionary不是线程安全的,而Hashtable是线程安全的,这意味着Hashtable可以在多个线程在直接被操作,应用开发者不用考虑安全问题。不过这算不上是Hashtable的一个优点,只是它的一个特点,Hashtable在内部实现更新操作有加锁,而Dictionary没有,如果想在多线程条件下操作Dictionary需要自己加锁。
1 string[] dataStrs = new string[1000000]; 2 for (int i = 0; i < 1000000; i++) 3 { 4 dataStrs[i] = i.ToString(); 5 } 6 var testDc = new Dictionary<string, string>(); 7 //var testDc = new Hashtable(); 8 Stopwatch sw = new Stopwatch(); 9 Console.WriteLine("any key to start"); 10 Console.ReadLine(); 11 Console.WriteLine("ing......"); 12 13 for (int j = 0; j < 10; j++) 14 { 15 testDc = new Dictionary<string, string>(); 16 //testDc = new Hashtable(); 17 sw.Restart(); 18 sw.Start(); 19 for (int i = 0; i < 1000000; i++) 20 { 21 testDc.Add(dataStrs[i], dataStrs[i]); 22 } 23 sw.Stop(); 24 Console.WriteLine($"time {sw.ElapsedMilliseconds}"); 25 Console.ReadLine(); 26 } 27 Console.WriteLine("end of test"); 28 Console.ReadLine();使用以上代码对Dictionary与Hashtable的插入性能进行简单对比。
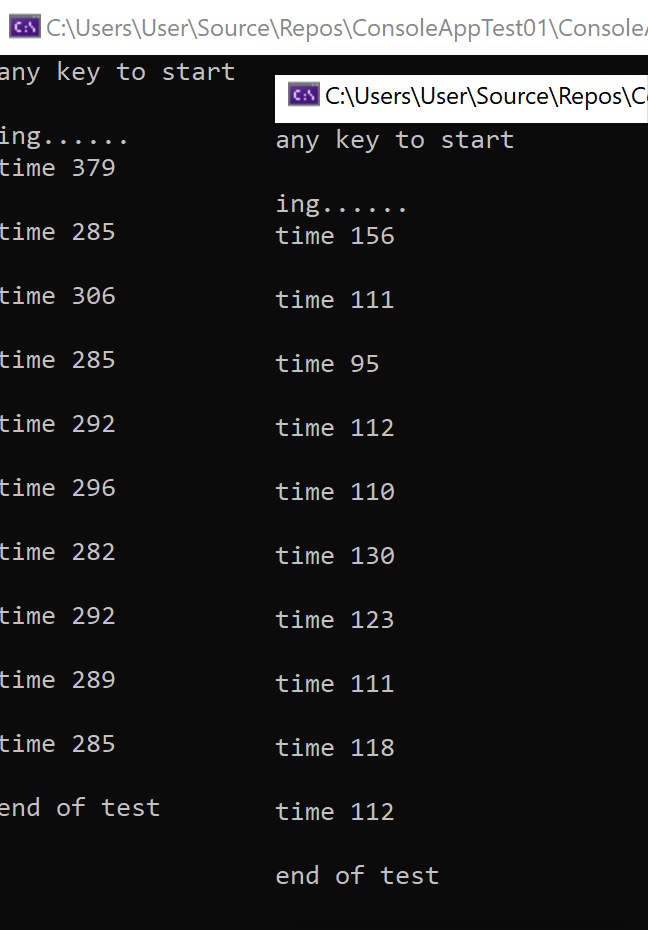 如上图测试结果左边为Hashtable,右边为Dictionary,可以看到仅从插入性能上来看Dictionary的确是要大幅优于Hashtable。
如果您对读取性能进行对比测试也会得到类似结果。
前面已经提过Dictionary借助将buckets槽位信息与entries数据数组分离及对新增next属性的利用让Dictionary的碰撞查找计算量大幅低于Hashtable,同时数据空间的利用率也得到了提高,这也是以上测试结果会有如此大差距的主要原因。
六:后记
如上图测试结果左边为Hashtable,右边为Dictionary,可以看到仅从插入性能上来看Dictionary的确是要大幅优于Hashtable。
如果您对读取性能进行对比测试也会得到类似结果。
前面已经提过Dictionary借助将buckets槽位信息与entries数据数组分离及对新增next属性的利用让Dictionary的碰撞查找计算量大幅低于Hashtable,同时数据空间的利用率也得到了提高,这也是以上测试结果会有如此大差距的主要原因。
六:后记
篇幅比较长,但是一直都是围绕同一个内容进行讲述。笔者会尽力让描述前后有联系,并避免过多介绍孤立的无关信息。事实上文章的草稿(或者叫个人笔记)一年前就完成了(所以大家也看到调试时其实没有使用最新的.Net6)。而即便是自己写的内容时隔一年再来回看,也能发现很多细节也并不是读一遍自己就能秒懂的。如果之前没有关注过这些看完会花点时间,但我相信是会有价值的。
本文大多数图表,示例及描述其实也是经过反复修改,并对照实现代码核对或逐行调试而得出来的。但即便如此限于自身水平或认知上的限制也难免会有错误或不全面的表述,大家在阅读过程中如果发现有纰漏的地方,可以以任何方式提出( mycllq@hotmail.com 因为自由互联似乎不允许访客留言,这里也留个邮箱方便未注册用户),我会在确认后第一时间更正。