本篇文章会介绍一个我自己写的库,库地址在这里,主要作用是提供一个注解,在你方法上使用这个注解,库提供的功能会帮你把数据自动缓存起来,下次再调用这个方法只要入参是一致的则直接会从缓存里面拿数据,不会再执行方法了(方法里面的内容可能是走DB或者PRC)。
写这个库的原因是公司内部有一个类似工具,刚开始并没有Get到它有多大的用处,随着在公司接触更多的业务需求,发现这真的是太香了。并且我对它有一些自己的更多想法,所以打算自己写一个开源出来一方面是可以给自己其他开源项目使用,另外一方面我觉得有相同需求的人还蛮多的,而Github上也没有一个尽善尽美的类似库。
不同量级用户的代码真的是不一样,我在原来公司也做的也是C端的业务,对于缓存运用虽然非常多,但是主要是利用Redis数据结构特点来做一些业务上的实现会更多一些,例如用string来做互斥锁/配置开关/状态记录,用zset来做榜单/实现dmq需求,用list/set/hash来做高性能短时数据库。对于很多DB的数据都是直接查,主要当时的产品用户量非常平稳,拿了融资的那段时间公司有钱,数据库用的非常好,从库也多, 上线不需要压测,随便点点RTT自己觉得过得去就行,所以我觉得偶尔写一下读写redis的代码也没啥用工作量。
但是现在的公司,C端接口都做限流,除了分页数据几乎所有数据都加一层缓存,甚至分页数据的第一页都会做。这就很麻烦,每次都要写一大堆重复代码,从Redis取值,空走就DB/RPC,然后回写Redis。最可怕的是批量取值,从Redis去拿完以后还要把没有命中的筛选出来然后去DB/RPC取,然后回写这部分值到Redis。因为用户量很大,还有羊毛党会刷接口,未命中的值可能还需要做空缓存防止穿透到DB。
本仓库包含以下内容:
- @Cache注解一个
- 对指定方法进行自动缓存(Redis或者caffeine本地缓存)
- 可对不存在的数据进行自动空缓存,并发下防止缓存穿透
- 可开启获取缓存时自动进行互斥锁,防止缓存击穿保护DB(下个版本更新)
本库已经上架maven中央仓库,已经引入到自己项目pom文件中就行,请注意直接在mvnrepository会出现很多2.0.0以下的版本,请不要使用,那...那...是我上架的是做测试不小心发到release上的debug版本。
所有版本查询请点击这里 这里 这里
Maven
<!-- https://mvnrepository.com/artifact/cn.someget/cache-anno -->
<dependency>
<groupId>cn.someget</groupId>
<artifactId>cache-anno</artifactId>
<version>2.0.0</version>
</dependency>
Gradle
// https://mvnrepository.com/artifact/cn.someget/cache-anno
implementation group: 'cn.someget', name: 'cache-anno', version: '2.0.0'
导入jar包就好了,除此之外无需为本库做任何配置,所有bean也已经spring.factories暴露出来,可以直接被启动类扫描到。
使用说明 一. 注意事项-
导入本库后配置中必须要有redis相关的配置,支持jedis和lettuce,只要spring自动装配或者你手动装配一个redisTemplate就行(注意如果你有多个RedisTemplate<String, String>你需要给其中一个指定@Primary),不然无法使用本库。
-
使用注解存入的数据,序列化方式均为String,当然注解自动读数据反序列化也是String,所以如果你有使用注解存入数据,但是不适用注解读取数据的需求,请使用String反序列化读取。
-
所有redis的io异常都已经捕获,有异常只会打日志,不会影响你的业务,不会影响你的数据读取,兜底会走db查询。
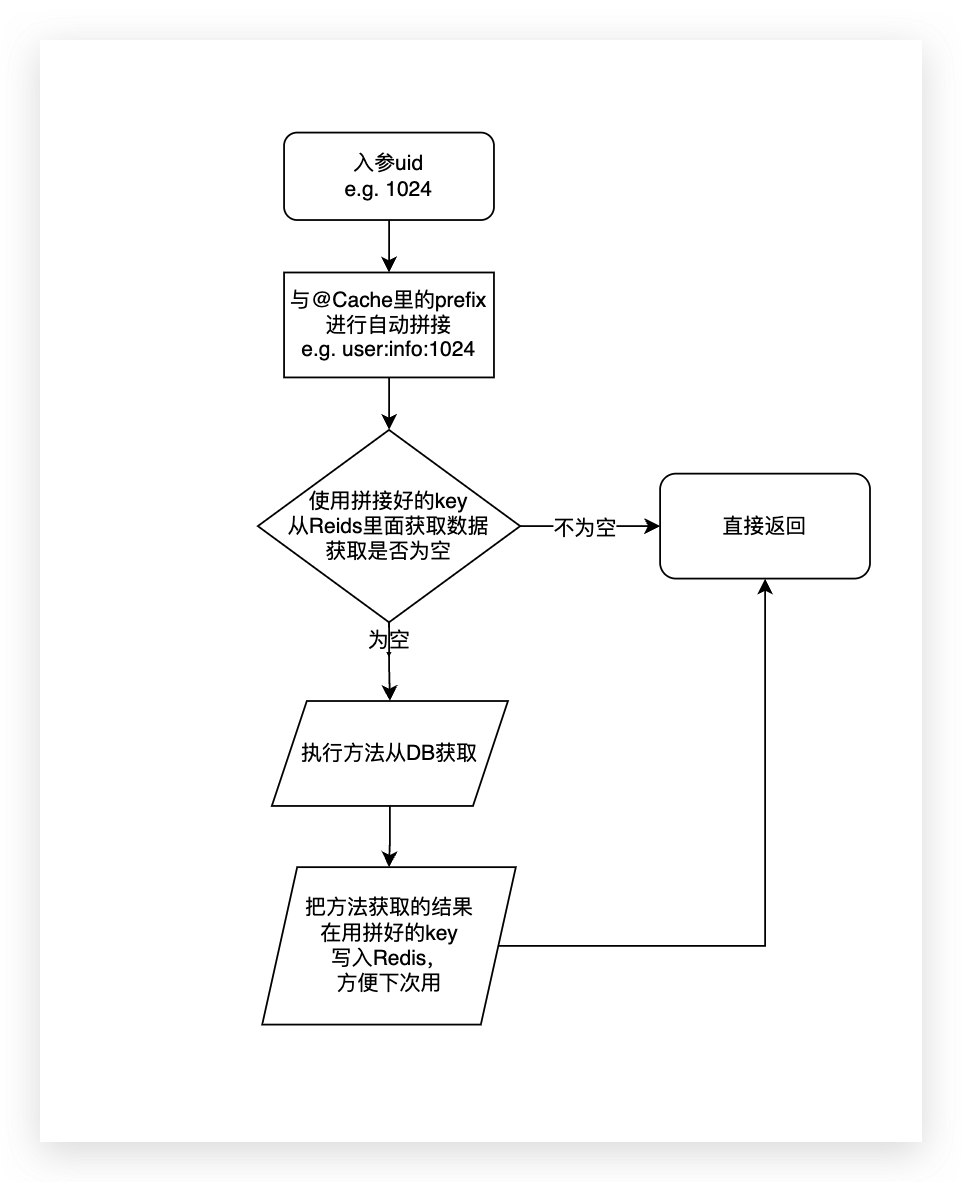
- 查询一个数据,例如下面,通过uid查询用户的详细数据,加上@Cache(注意不要导错包哈)注解,prefix是你缓存数据Redis的Key前缀,注意需要加一个占位符,我自动写入的时候会把入参拼接到这个prefix上。查询之前会根据注解中的prefix拼接上入参uid从Redis中尝试获取数据,如果没有数据则执行方法,执行完方法再自动写入缓存。那么下次在执行这个方法的时候,又会执行上面步骤prefix拼接入参尝试从Redis获取数据,但是因为上次自动写入了,所以拿到数据就直接返回了,不会再执行方法走DB查询了。
// 建议prefix定义成常量,便于复用, one to one可以不用传clazz参数
@Cache(prefix = "user:info:%d")
public UserInfoBO getIpUserInfo(Long uid) {
UserInfo userInfo = userInfoMapper.selectByUid(uid);
if (userInfo == null) {
return null;
}
UserInfoBO bo = new UserInfoBO();
BeanUtils.copyProperties(userInfo, bo);
return bo;
}
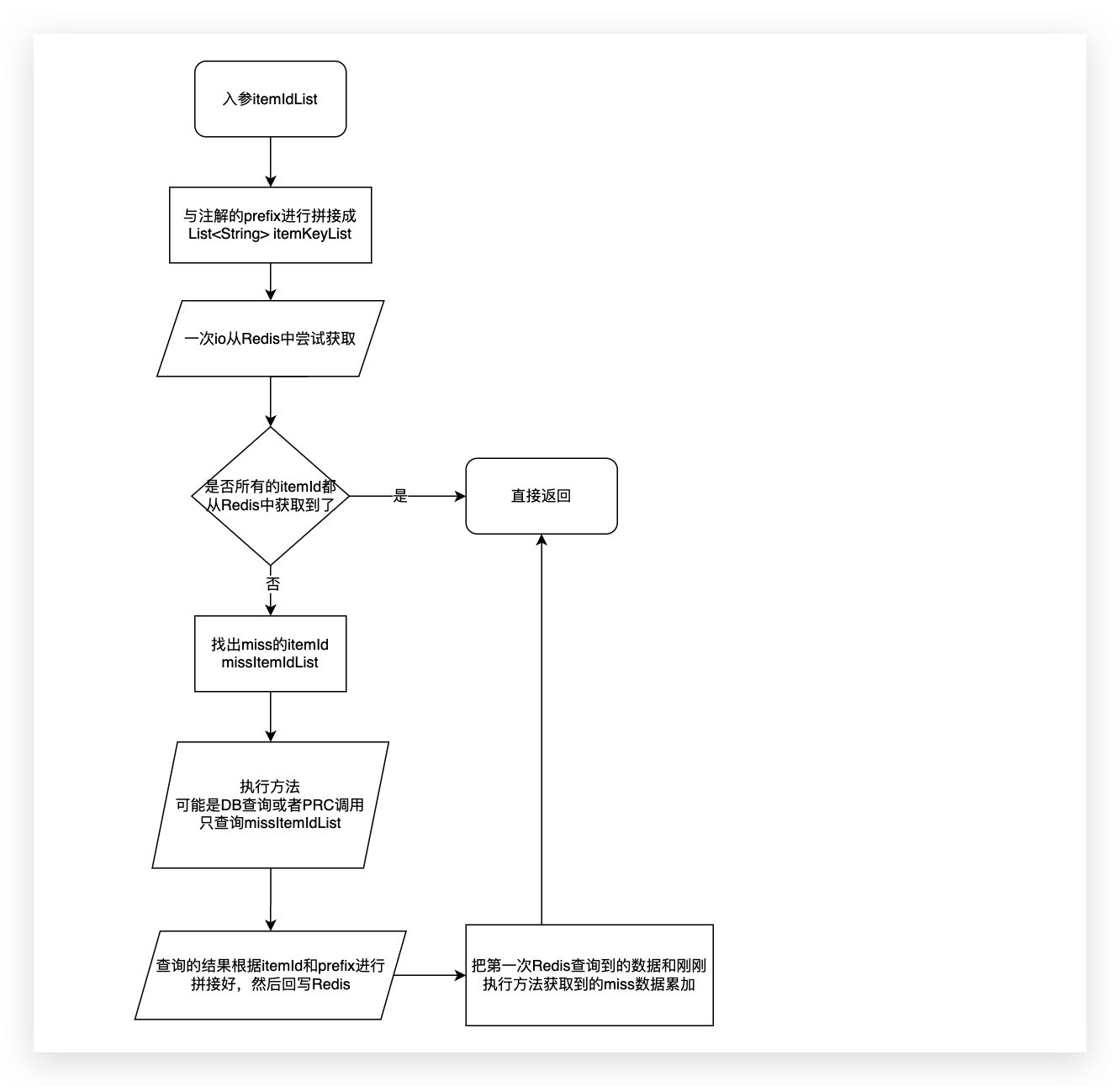
- 查询多个数据,例如下面,通过一堆itemId获取多个item的详细数据,和上面一样你需要指定prefix,查询之前会通过把入参所有的itemId进行和注解里面的prefix拼接,然后批量一次性尝试从redis里面获取,如果所有itemId都获取到则直接返回,但是如果有未命中的itemId则会把这未命中的itemId再统一走方法进行远程获取最后和Redis里面的汇总(远程获取完 会自动写入Redis,方便你下次命中)
// 返回值是集合类型,clazz必须要传
@Cache(prefix = "mall:item:%d", clazz = MallItemsBO.class)
public Map<Long, MallItemsBO> listItems(List<Long> itemsIds) {
BaseResult<List<MallItemsDTO>> result = itemsRemoteClient.listItems(new ItemsReqDTO());
if (result == null || CollectionUtils.isEmpty(result.getData())) {
return Collections.emptyMap();
}
return result.getData().stream()
.map(mallItemsDTO -> {
MallItemsBO mallItemsBO = new MallItemsBO();
BeanUtils.copyProperties(mallItemsDTO, mallItemsBO);
return mallItemsBO;
}).collect(Collectors.toMap(MallItemsBO::getItemId, Function.identity()));
}
核心原理是利用AOP对你为注解设置的参数和入参进行拼接成一个key,每次在方法执行前走缓存去查询一遍,如果缓存有数据则直接返回不再执行方法,如果缓存没有查数据,则执行方法拿到数据取写入缓存。
如果是数据批量获取,还会看Redis命中的数量来判断是全部返回,还是把未命中的去执行方法,最后把缓存和方法查询结果一起汇总返回给方法调用方
因为java的泛型擦除的限制我无法判断Map的value泛型具体是什么, 请@Cache中的参数hasMoreValue需要设置成true,请切记
其中占位符要注意,如果是String占位符要%s,整型占位符%d,浮点型占位符%f 详情请参考这里
其实总的来说就是分为两类,入参是对象或者List,也就是单个获取和批量获取,如果是批量获取的话切记List要在一号位,并且方法入参不能超过两个,否则会报错提示不支持。
五. 注解里面的参数含义启用空缓存写入
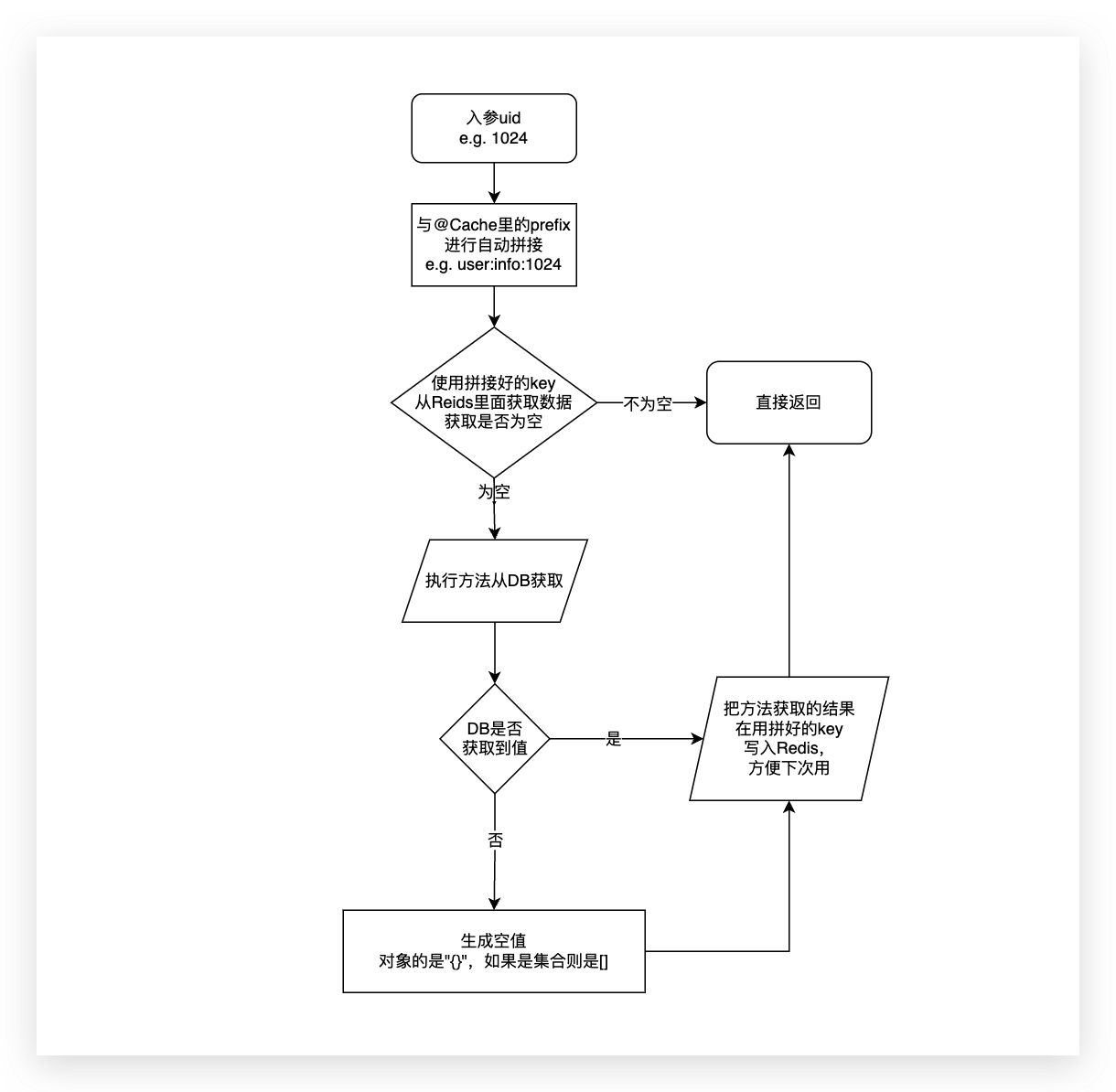
@Cache含有missExpire的属性,属性含义是DB中不存在的值的过期时间(单位是秒),默认值是0,如果是0则表示如果查询的值DB中不存在的话,不进行空缓存处理。如果是非0,那么从Redis中查询值未命中会走方法查询,方法查询返回结果也是不存在那么会储存一个空值(如果是对象的是"{}",如果是集合则是[]),过期时间是missExpire这个值(推荐3-10秒左右),支持上述表格中的所有类型。
注意:
- 开启空缓存以后插入记录后也要进行删除缓存处理,因为可能对应值DB中已经有了,但是Redis还存在空值正处于TTL中。
空缓存如果是对象是会缓存id为-1的对象,如果是集合会缓存一个空集合,id为-1的对象不会返回给方法调用方,会直接被过滤掉,符合大家编码习惯。要注意的是缓存对象必须要有id字段(Integer和Long都可以),否则无法过滤会返回的一个所有属性都是null的空对象。2.0.1版已经支持设置对象空缓存为"{}"所以不用必须含有id字段了,如果命中空缓存方法调用方拿到的是null,符合大家编码习惯,但是所有空缓存对象一定要有无参构造,否则反序列化无法生成空对象。
启用本地缓存
@Cache含有usingLocalCache的属性,属性含义是是否启用本地缓存,在一些场景下电商营销域要频繁通过RPC获取商品域的商品数据,因为营销场景QPS非常高,即便在RPC之前有一层Redis,但是频繁获取商品导致Redis的QPS非常高。而商品数据是不怎么变化的,所以在Redis之前再加一层本地缓存就显得非常有必要,Redis的QPS能降低不少。
有不少场景进行本地缓存提升都非常大,本库也支持进行本地缓存,只需使用注解是把usingLocalCache的属性设置为true(默认是false),本库使用的本地缓存是最近风头压过guava的caffeine,这样获取数据之前先从本地缓存进行查询,如果本地缓存没有命中则再去查询Redis。
注意:多层缓存会增加Cache-DB不一致可能,一定程度抗流可以用,但是不要过分依赖,这里本地缓存默认TTL是3秒,暂时不支持修改。
后言下一步计划是
- 写好单元测试,这个库我还会写一篇文章,基于单测的code更加直观来介绍它是怎么的好用。
- 防止缓存击穿已经有好的方案,下一个版本会迭代进去,对于高风险接口可以开启。
- 目前没有配套的缓存逐出注解,参考Spring-Cache我想一下怎么做到最好
如果你感兴趣或者有相同的需求欢迎使用本库,更加提一个 Issue 或者提交一个 Pull Request。
【文章原创作者:韩国机房 http://www.558idc.com/kt.html欢迎留下您的宝贵建议】