最早学习C、C++语言时,它们都是把内存的管理全部交给开发者,这种方式最灵活但是也最容易出问题,对人员要求极高;后来出现的一些高级语言像Java、JavaScript、C#、Go,都有语言自身
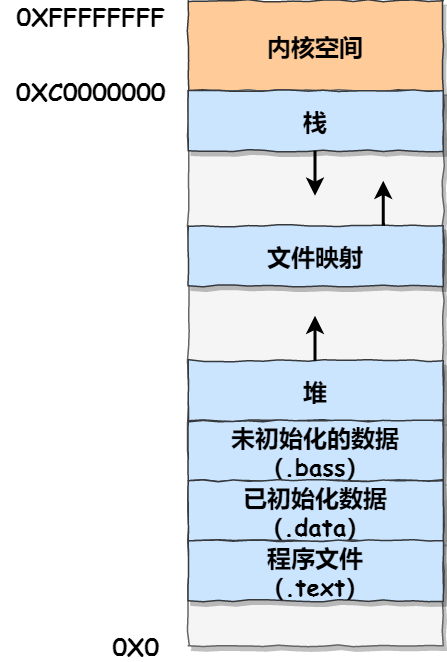
- 程序文件段(.text),包括二进制可执行代码;
- 已初始化数据段(.data),包括静态常量;
- 未初始化数据段(.bss),包括未初始化的静态变量;(bss与data一般作为静态存储区)
- 堆段,包括动态分配的内存,从低地址开始向上增长;
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增长(跟硬件和内核版本有关 (opens new window));
- 栈段,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。当然系统也提供了参数,以便我们自定义大小;
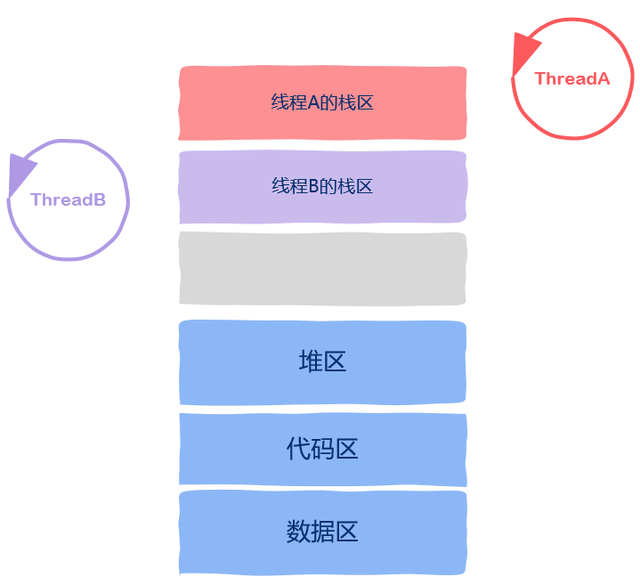 Go语言中的GMP管理机制来说,只有M对应的是操作系统中的线程,所以goroutine中是保留了必要的(rp、bp、pc指针),当goroutine执行时,对应到指定的栈空间地址区中。
说的有点远,回到本文主题。
内存分配一般有三种方式:静态存储区(根对象、静态变量、常量)、栈(函数中的临时局部变量)、堆(malloc、new等);
一般最长讨论的是栈和堆,栈的特点可以认为是线性内存,管理简单,分配比堆上更快,栈上分配的内存一般不需要程序员关心,程序语言都有专门的栈帧来管理(一般来说线程的栈空间是2M有的是8M,不能变化超过会崩溃,Go语言中goroutine是2kb,Go语言来有自己的栈扩容和缩容能力,64位系统超过1G则会崩溃)。(这里说的线性内存其实在真实的机器物理内存中并不一定连续,这是因为操作系统提供了虚拟内存,让各个程序看起来是独占整个物理内存,实际上对程序来说连续的地址空间,在操作系统视角下未必是连续的,可以参考这篇文章)
因为堆区是多个线程共用的,所以就需要一套机制来进行分配(考虑内存碎片、公平性、冲突解决);不同的内存分配管理方式的适用场景都不同。在详细讲解Go内存分配策略之前,我们先来看一个简单的内存分配。
堆内存分配
堆内存在最开始时时连续的,当程序运行过程中大家都去堆中申请自己的使用空间,如果不做任何处理,那么会产生两个主要问题:
第一个内存碎片问题:
假设堆有100M,线程A申请500M,线程B申请200M,线程C申请300M,此时堆空间为A(500)B(200)C(300),然后A和C把空间释放了,空间变为 空闲区(500m)线程B空间(200M)空闲区(300M) 这时候线程D需要留600M就会发现此时没有完成的一块空间给线程D;
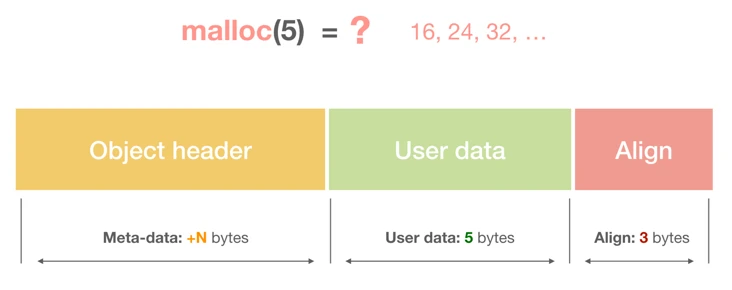
所以一些高级语言中堆空间分配以类似操作系统的页式分配的方式进行管理,分割出一个个小块,一个小块中包含一些元数据(如用户数据大小、是否空闲、头指针、尾指针)、用户数据区、对齐padding区;
因为现代操作系统一个页的区域一般是4kb,所以每次分配堆内存块也会把用户数据区设置为4kb的倍数,同时因为还需要额外的区域来存储元数据信息,但是元数据大小未必是4字节的倍数(像C++中可以设置4字节对齐https://blog.csdn.net/sinat_28296297/article/details/77864874),在加上要考虑到CPU的伪共享缓存带来的性能问题,所以需要一些额外的空闲空间来做补充(这就是对齐字节的意义)。
Go语言中的GMP管理机制来说,只有M对应的是操作系统中的线程,所以goroutine中是保留了必要的(rp、bp、pc指针),当goroutine执行时,对应到指定的栈空间地址区中。
说的有点远,回到本文主题。
内存分配一般有三种方式:静态存储区(根对象、静态变量、常量)、栈(函数中的临时局部变量)、堆(malloc、new等);
一般最长讨论的是栈和堆,栈的特点可以认为是线性内存,管理简单,分配比堆上更快,栈上分配的内存一般不需要程序员关心,程序语言都有专门的栈帧来管理(一般来说线程的栈空间是2M有的是8M,不能变化超过会崩溃,Go语言中goroutine是2kb,Go语言来有自己的栈扩容和缩容能力,64位系统超过1G则会崩溃)。(这里说的线性内存其实在真实的机器物理内存中并不一定连续,这是因为操作系统提供了虚拟内存,让各个程序看起来是独占整个物理内存,实际上对程序来说连续的地址空间,在操作系统视角下未必是连续的,可以参考这篇文章)
因为堆区是多个线程共用的,所以就需要一套机制来进行分配(考虑内存碎片、公平性、冲突解决);不同的内存分配管理方式的适用场景都不同。在详细讲解Go内存分配策略之前,我们先来看一个简单的内存分配。
堆内存分配
堆内存在最开始时时连续的,当程序运行过程中大家都去堆中申请自己的使用空间,如果不做任何处理,那么会产生两个主要问题:
第一个内存碎片问题:
假设堆有100M,线程A申请500M,线程B申请200M,线程C申请300M,此时堆空间为A(500)B(200)C(300),然后A和C把空间释放了,空间变为 空闲区(500m)线程B空间(200M)空闲区(300M) 这时候线程D需要留600M就会发现此时没有完成的一块空间给线程D;
所以一些高级语言中堆空间分配以类似操作系统的页式分配的方式进行管理,分割出一个个小块,一个小块中包含一些元数据(如用户数据大小、是否空闲、头指针、尾指针)、用户数据区、对齐padding区;
因为现代操作系统一个页的区域一般是4kb,所以每次分配堆内存块也会把用户数据区设置为4kb的倍数,同时因为还需要额外的区域来存储元数据信息,但是元数据大小未必是4字节的倍数(像C++中可以设置4字节对齐https://blog.csdn.net/sinat_28296297/article/details/77864874),在加上要考虑到CPU的伪共享缓存带来的性能问题,所以需要一些额外的空闲空间来做补充(这就是对齐字节的意义)。
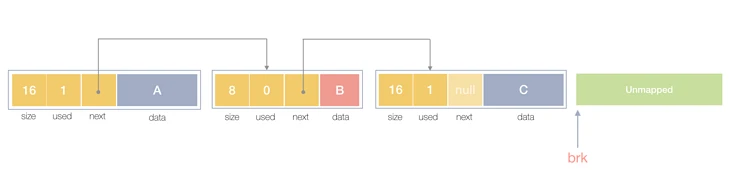
 那么如果只用链表形式来管理堆内存,看起来就像是下面这样:
那么如果只用链表形式来管理堆内存,看起来就像是下面这样:
 第二个则是并发冲突问题
因为多个线程在同时向堆内存中申请资源,如果没有控制必然会出现冲突和覆写问题,所以常见的方案是使用锁,但是锁则不可避免的带来性能问题;所以有各种各样的方案兼顾性能和碎片化以及预分配的策略来进行内存分配。
一个简单的内存分配器
我们先按照上面的介绍来实现一个简单的内存分配器,即实现一个malloc、free方法。
第二个则是并发冲突问题
因为多个线程在同时向堆内存中申请资源,如果没有控制必然会出现冲突和覆写问题,所以常见的方案是使用锁,但是锁则不可避免的带来性能问题;所以有各种各样的方案兼顾性能和碎片化以及预分配的策略来进行内存分配。
一个简单的内存分配器
我们先按照上面的介绍来实现一个简单的内存分配器,即实现一个malloc、free方法。
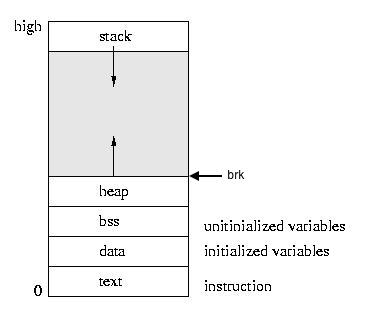 在这里我们我们把data、bss、heap三个区域统称为“data segment”,datasegment的结尾由一个指向此处的指针brk(program break)确定。如果想在heap上分配更多的空间,只需要请求系统由低像高移动brk指针,并把对应的内存首地址返回,释放内存时,只需要向下移动brk指针即可。
在Linux和unix系统中,我们这里就调用sbrk()方法来操纵brk指针:
在这里我们我们把data、bss、heap三个区域统称为“data segment”,datasegment的结尾由一个指向此处的指针brk(program break)确定。如果想在heap上分配更多的空间,只需要请求系统由低像高移动brk指针,并把对应的内存首地址返回,释放内存时,只需要向下移动brk指针即可。
在Linux和unix系统中,我们这里就调用sbrk()方法来操纵brk指针:
- sbrk(0)获取当前brk的地址
- 调用sbrk(x),x为正数时,请求分配x bytes的内存空间,x为负数时,请求释放x bytes的内存空间
void *malloc(size_t size) { void *block; block = sbrk(size); if (block == (void *) -1) { return NULL; } return block; }现在问题是我们可以申请内存,但是如何释放呢?因为释放内存需要sbrk来移动brk指针向下缩减,但是我们目前没有记录这个区域的尺寸信息; 还有另外一个问题,假设我们现在申请了两块内存,A\B,B在A的后面,如果这时候用户想将A释放,这时候brk指针在B的末尾处,那么如果简单的移动brk指针,就会对B进行破坏,所以对于A区域,我们不能直接还给操作系统,而是等B也同时被是释放时再还给操作系统,同时也可以把A作为一个缓存,等下次有小于等于A区域的内存需要申请时,可以直接使用A内存,也可以将AB进行合并来统一分配(当然会存在内存碎片问题,这里我就先不考虑)。 所以现在我们将内存按照块的结构来进行划分,为了简单起见,我们使用链表的方式来管理;那么除了本身用户申请的内存区域外,还需要一些额外的信息来记录块的大小、下一个块的位置,当前块是否在使用。整个结构如下:
typedef char ALIGN[16]; // padding字节对齐使用 union header { struct { size_t size; // 块大小 unsigned is_free; // 是否有在使用 union header *next; // 下一个块的地址 } s; ALIGN stub; }; typedef union header header_t;这里将一个结构体与一个16字节的数组封装进一个union,这就保证了这个header始终会指向一个对齐16字节的地址(union的尺寸等于成员中最大的尺寸)。而header的尾部是实际给用户的内存的起始位置,所以这里给用户的内存也是一个16字节对齐的(字节对齐目的为了提升缓存命中率和批处理能力提升系统效率)。 现在的内存结构如下图所示:
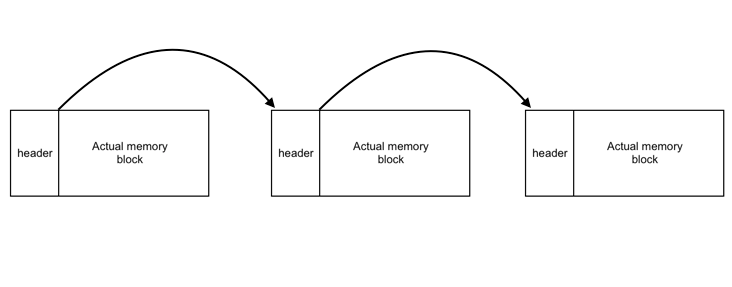 现在我们使用head和tail来使用这个链表
现在我们使用head和tail来使用这个链表
header_t *head, *tail为了支持多线程并发访问内存,我们这里简单的使用全局锁。
pthread_mutex_t global_malloc_lock;我们的malloc现在是这样:
void *malloc(size_t size) { size_t total_size; void *block; header_t *header; if (!size) // 如果size为0或者NULL直接返回null return NULL; pthread_mutex_lock(&global_malloc_lock); // 全局加锁 header = get_free_block(size); // 先从已空闲区域找一块合适大小的内存 if (header) { // 如果能找到就直接使用,无需每次向操作系统申请 header->s.is_free = 0; // 标志这块区域非空闲 pthread_mutex_unlock(&global_malloc_lock); // 解锁 // 这个header对外部应该是完全隐藏的,真正用户需要的内存在header尾部的下一个位置 return (void*)(header + 1); } // 如果空闲区域没有则向操作系统申请一块内存,因为我们需要header存储一些元数据 // 所以这里要申请的内存实际是元数据区+用户实际需要的大小 total_size = sizeof(header_t) + size; block = sbrk(total_size); if (block == (void*) -1) { // 获取失败解锁、返回NULL pthread_mutex_unlock(&global_malloc_lock); return NULL; } // 申请成功设置元数据信息 header = block; header->s.size = size; header->s.is_free = 0; header->s.next = NULL; // 更新链表对应指针 if (!head) head = header; if (tail) tail->s.next = header; tail = header; // 解锁返回给用户内存 pthread_mutex_unlock(&global_malloc_lock); return (void*)(header + 1); } // 这个函数从链表中已有的内存块进行判断是否存在空闲的,并且能够容得下申请区域的内存块 // 有则返回,每次都从头遍历,暂不考虑性能和内存碎片问题。 header_t *get_free_block(size_t size) { header_t *curr = head; while(curr) { if (curr->s.is_free && curr->s.size >= size) return curr; curr = curr->s.next; } return NULL; }
可以看下现在我们的内存分配具有的基本能力:
- 通过加锁保证线程安全
- 通过链表的方式管理内存块,并解决内存复用问题。
void free(void *block) { header_t *header, *tmp; void *programbreak; if (!block) return; pthread_mutex_lock(&global_malloc_lock); // 全局加锁 header = (header_t*)block - 1; // block转变为header_t为单位的结构,并向前移动一个单位,也就是拿到了这个块的元数据的起始地址 programbreak = sbrk(0); // 获取当前brk指针的位置 if ((char*)block + header->s.size == programbreak) { // 如果当前内存块的末尾位置(即tail块)刚好是brk指针位置就把它还给操作系统 if (head == tail) { // 只有一个块,直接将链表设置为空 head = tail = NULL; } else {// 存在多个块,则找到tail的前一个快,并把它next设置为NULL tmp = head; while (tmp) { if(tmp->s.next == tail) { tmp->s.next = NULL; tail = tmp; } tmp = tmp->s.next; } } // 将内存还给操作系统 sbrk(0 - sizeof(header_t) - header->s.size); pthread_mutex_unlock(&global_malloc_lock); // 解锁 return; } // 如果不是最后的链表就标志位free,后面可以复用 header->s.is_free = 1; pthread_mutex_unlock(&global_malloc_lock); }以上就是一个简单的内存分配器;可以看到我们使用链表来管理堆内存区域,并通过全局锁来线程安全问题,同时也提供一定的内存复用能力。当然这个内存分配器也存在几个严重的问题:
- 全局锁在高并发场景下会带来严重性能问题
- 内存复用每次从头遍历也存在一些性能问题
- 内存碎片问题,我们内存复用时只是简单的判断块内存是否大于需要的内存区域,如果极端情况下,我们一块空闲内存为1G,而新申请内存为1kb,那就造成严重的碎片浪费
- 内存释放存在问题,只会把末尾处的内存还给操作系统,中间的空闲部分则没有机会还给操作系统。
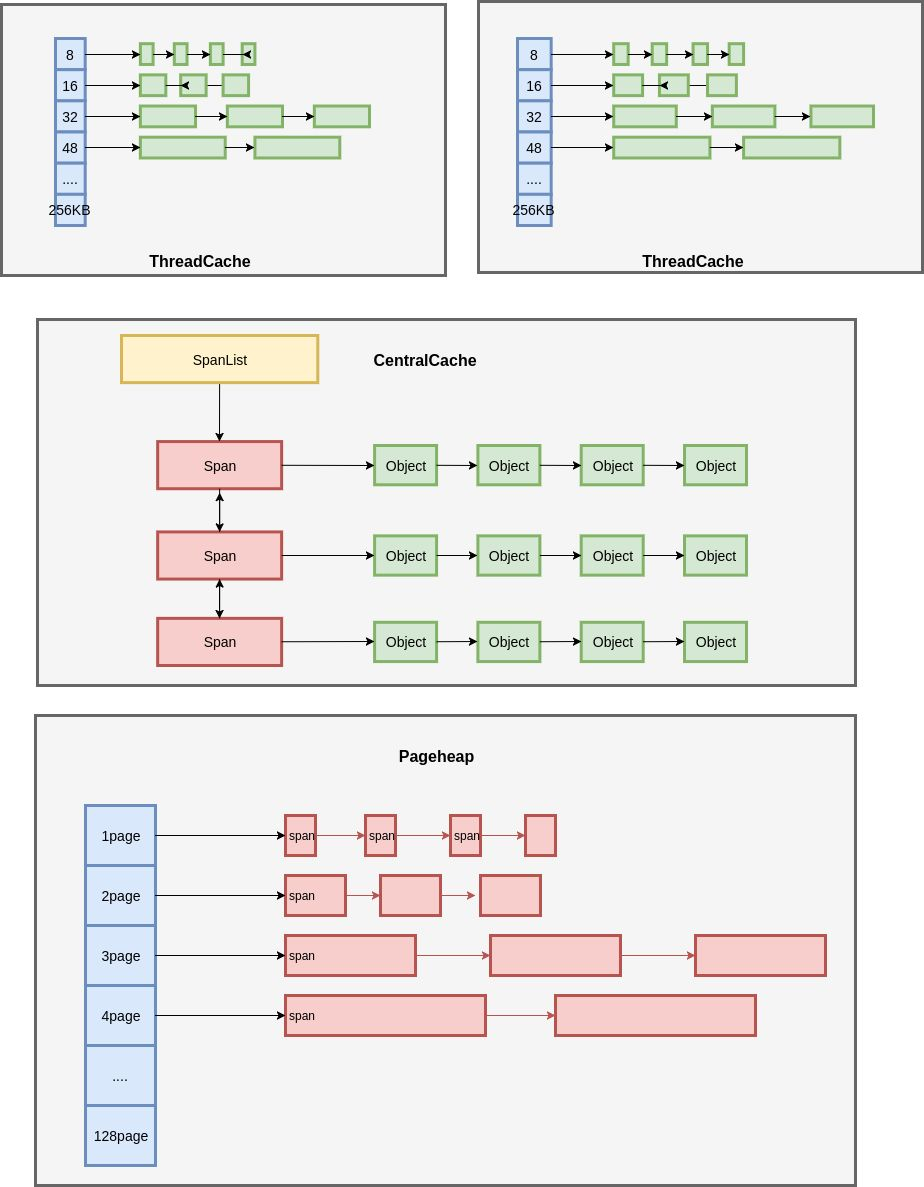 TCMalloc的几个重要概念:
TCMalloc的几个重要概念:
- Page:操作系统对内存管理以页为单位,TCMalloc也是这样,只不过TCMalloc里的Page大小与操作系统里的大小并不一定相等,而是倍数关系。《TCMalloc解密》里称x64下Page大小是8KB。
- Span:一组连续的Page被称为Span,比如可以有2个页大小的Span,也可以有16页大小的Span,Span比Page高一个层级,是为了方便管理一定大小的内存区域,Span是TCMalloc中内存管理的基本单位。
- ThreadCache:每个线程各自的Cache,一个Cache包含多个空闲内存块链表,每个链表连接的都是内存块,同一个链表上内存块的大小是相同的,也可以说按内存块大小,给内存块分了个类,这样可以根据申请的内存大小,快速从合适的链表选择空闲内存块。由于每个线程有自己的ThreadCache,所以ThreadCache访问是无锁的。
- CentralCache:是所有线程共享的缓存,也是保存的空闲内存块链表,链表的数量与ThreadCache中链表数量相同,当ThreadCache内存块不足时,可以从CentralCache取,当ThreadCache内存块多时,可以放回CentralCache。由于CentralCache是共享的,所以它的访问是要加锁的。
- PageHeap:PageHeap是堆内存的抽象,PageHeap存的也是若干链表,链表保存的是Span,当CentralCache没有内存的时,会从PageHeap取,把1个Span拆成若干内存块,添加到对应大小的链表中,当CentralCache内存多的时候,会放回PageHeap。如上图,分别是1页Page的Span链表,2页Page的Span链表等,最后是large span set,这个是用来保存中大对象的。毫无疑问,PageHeap也是要加锁的。
- 小对象大小:0~256KB;分配流程:ThreadCache -> CentralCache -> HeapPage,大部分时候,ThreadCache缓存都是足够的,不需要去访问CentralCache和HeapPage,无锁分配加无系统调用,分配效率是非常高的。
- 中对象大小:257~1MB;分配流程:直接在PageHeap中选择适当的大小即可,128 Page的Span所保存的最大内存就是1MB。
- 大对象大小:>1MB;分配流程:从large span set选择合适数量的页面组成span,用来存储数据。
- 栈比堆更高效,不需要GC,因此Go会尽可能的将内存分配到栈上。Go的协程栈可以自动扩容和缩容
- 当分配到栈上可能会引起非法内存访问等问题,则会使用堆,如:
- 当一个值在函数被调用后访问(即作为返回值返回变量地址),这个值极有可能被分配到堆上
- 当编译器检测到某个值过大,这个值被分配到堆上(栈扩容和缩容有成本)
- 当编译时,编译器不知道这个值的大小(slice、map等引用类型)这个值会被分配到堆上
- 最后,不要去猜值在哪,只有编译器和编译器开发者知道
- 微小对象(0,16byte):分配流程为,mache->mcentral->mheap位图查找->mheap基数树查找->操作系统分配
- 小对象 [16byte, 32KB]:分配流程与微小对象一样
- 大对象(32KB以上):分为流程为,mheap基数树查找->操作系统分配(不经过mcache和mcentral)
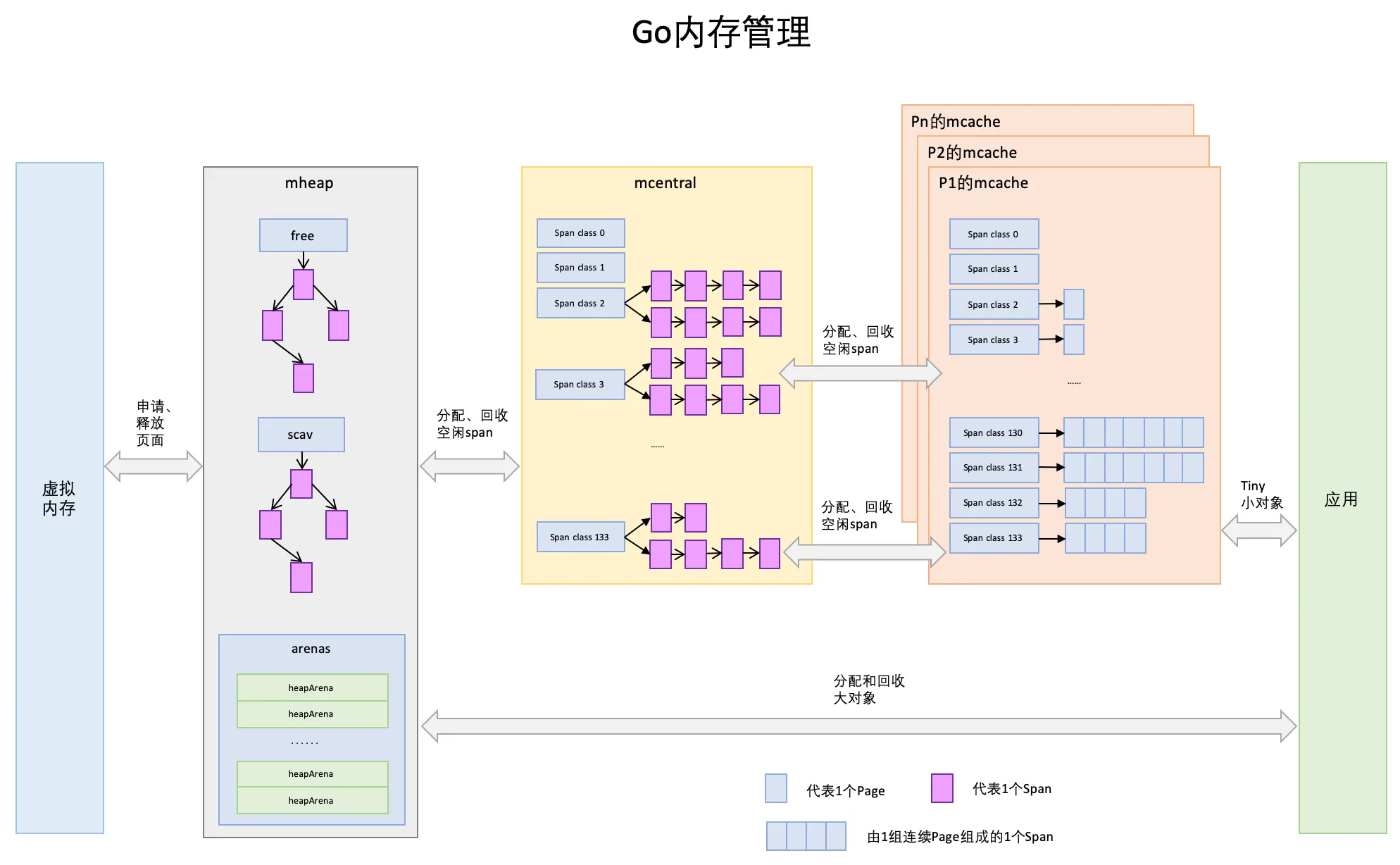 主要涉及如下概念:
page
与TCMalloc中的Page相同,一个page大小为8kb(为操作系统中页的两倍),上图中一个浅蓝色的长方形代表一个page
span
span是Go中内存管理的基本单位,go中为mspan,span的大小是page的倍数,上图中一个淡紫色的长方形为一个span
Go1.9.2往后一共划分了67级的mspan;
主要涉及如下概念:
page
与TCMalloc中的Page相同,一个page大小为8kb(为操作系统中页的两倍),上图中一个浅蓝色的长方形代表一个page
span
span是Go中内存管理的基本单位,go中为mspan,span的大小是page的倍数,上图中一个淡紫色的长方形为一个span
Go1.9.2往后一共划分了67级的mspan;
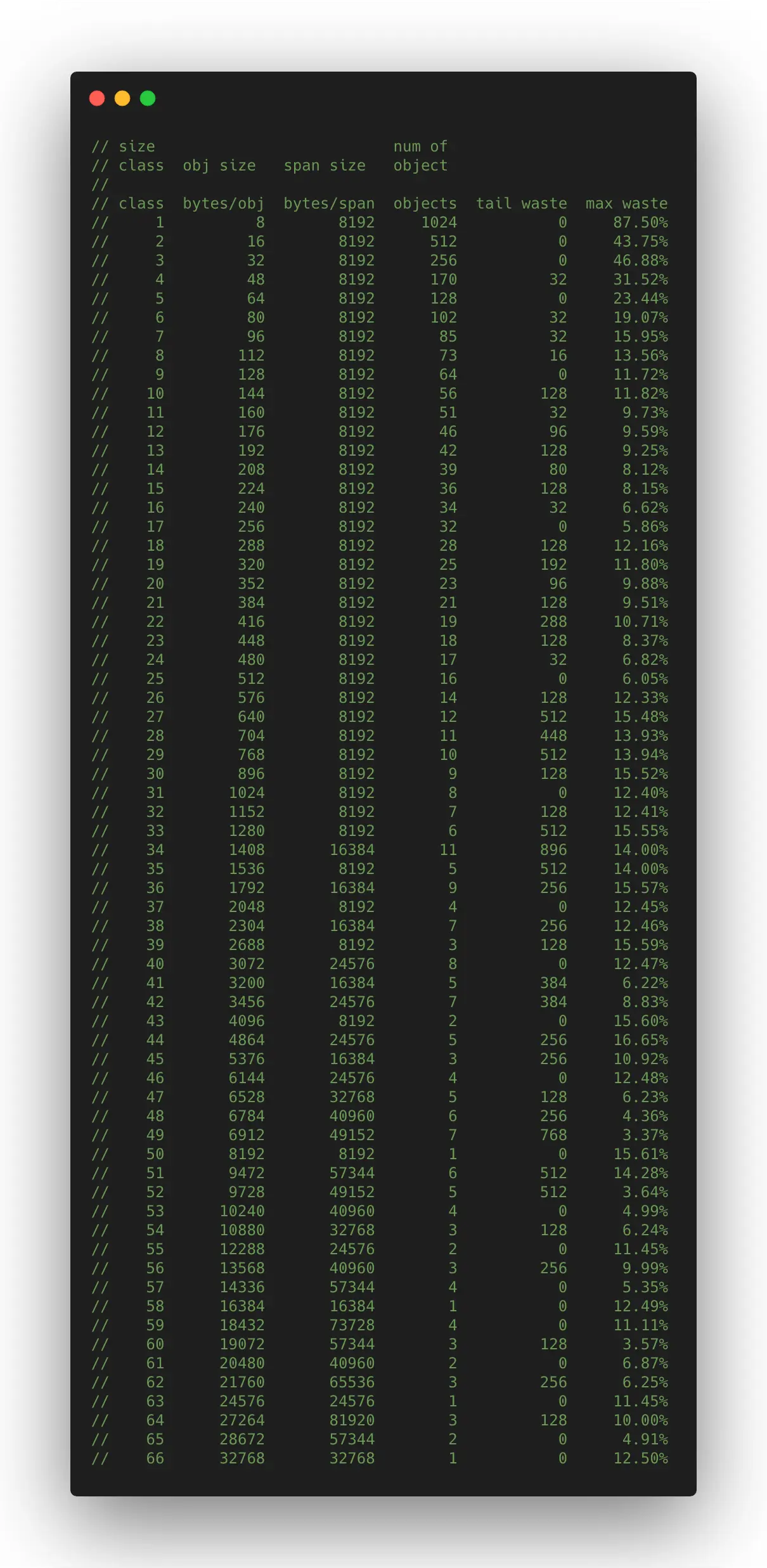 比如第一级span中每个对象大小是8b、第一级span的大小是一个page即8192b、一共可以存放1024个对象。
对应到代码中放在一个叫做class_to_size的数组中,存储每个级别的span中的object的大小
比如第一级span中每个对象大小是8b、第一级span的大小是一个page即8192b、一共可以存放1024个对象。
对应到代码中放在一个叫做class_to_size的数组中,存储每个级别的span中的object的大小
// path: /usr/local/go/src/runtime/sizeclasses.go const _NumSizeClasses = 67 var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536,1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}还有一个class_to_allocnpages数组存储每个级别的span对应的page的个数
// path: /usr/local/go/src/runtime/sizeclasses.go const _NumSizeClasses = 67 var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}代码中mspan结构体的定义如下:
// path: /usr/local/go/src/runtime/mheap.go type mspan struct { //链表前向指针,用于将span链接起来 next *mspan //链表前向指针,用于将span链接起来 prev *mspan // 起始地址,也即所管理页的地址 startAddr uintptr // 管理的页数 npages uintptr // 块个数,表示有多少个块可供分配 nelems uintptr // 用来辅助确定当前span中的元素分配到了哪里 freeindex uintptr //分配位图,每一位代表一个块是否已分配 allocBits *gcBits // allocBits的补码,以用来快速查找内存中未被使用的内存 allocCache unit64 // 已分配块的个数 allocCount uint16 // class表中的class ID,和Size Classs相关 spanclass spanClass // class表中的对象大小,也即块大小 elemsize uintptr // GC中来标记哪些块已经释放了 gcmarkBits *gcBits }这里有一个spanClass需要注意下,他其实是class_to_size的两倍,这是因为每个类别的对象对应两个mspan,一个分配给含有指针的的对象,一个分配给不含有指针的对象,这样垃圾回收时,针对无指针对象的span区域不需要进行复杂的标记处理,提升效果。 举个例子,第10级的size_class中一个对象是144字节,一个span占用一个page,共可以存储56个对象(可以看到56个对象占不满1个page,所以尾部会有128字节是无用的),它的mspan结构如下:
 当然微小对象的分配会复用一个对象,比如两个char类型都放在一个object中。后续会介绍。
mcache
mcache与TCMalloc中的ThreadCache类似,每个层级的span都会在mcache中保存一份;每个逻辑处理器P会有自己的mcache,对这部分区域的访问是无锁的。mcache的结构中有几个字段需要关注:
当然微小对象的分配会复用一个对象,比如两个char类型都放在一个object中。后续会介绍。
mcache
mcache与TCMalloc中的ThreadCache类似,每个层级的span都会在mcache中保存一份;每个逻辑处理器P会有自己的mcache,对这部分区域的访问是无锁的。mcache的结构中有几个字段需要关注:
//path: /usr/local/go/src/runtime/mcache.go type mcache struct { // mcache中对应各个等级的span都会有两份缓存 alloc [numSpanClasses]*mspan // 下面三个是在微小对象分配时专门使用 tiny uintptr tinyoffset uintptr local_tinyallocs uintptr } numSpanClasses = _NumSizeClasses << 1可以看到macache包含所有规格的span,微小对象和小对象都会先从这里开始找空间,大对象(超过32kb)没有对应的class索引,不经过这里。alloc数组中一共有134个元素,每一个级别的span在其中有两个即67x2;因为每一个级别对应两个span,一个给无指针的对象使用一半给有指针的对象使用(无指针对象在垃圾回收时不需要去扫描他是否引用了其他活跃对象),结构如下:
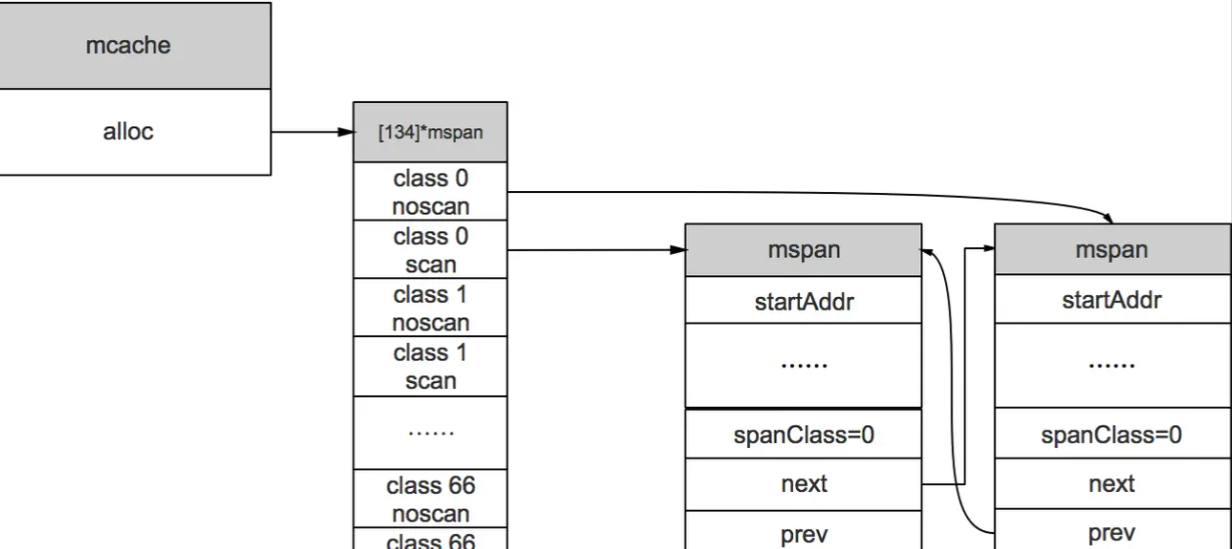 mcache也是从mcentral中获取的内存,Go运行时初始化时会调用runtime.allocmache初始化线程缓存
mcache也是从mcentral中获取的内存,Go运行时初始化时会调用runtime.allocmache初始化线程缓存
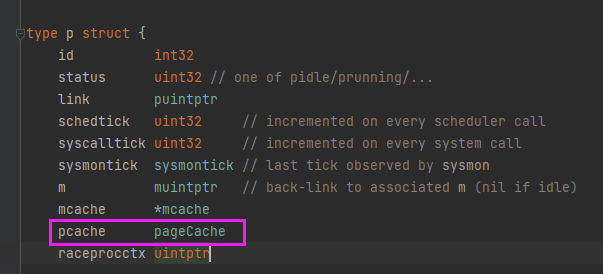
// init initializes pp, which may be a freshly allocated p or a // previously destroyed p, and transitions it to status _Pgcstop. func (pp *p) init(id int32) { pp.id = id //////// ......... ///////// if pp.mcache == nil { if id == 0 { if mcache0 == nil { throw("missing mcache?") } // Use the bootstrap mcache0. Only one P will get // mcache0: the one with ID 0. pp.mcache = mcache0 } else { pp.mcache = allocmcache() } } .......... }该函数会在系统栈中调用runtime.mheap中的缓存分配器初始化新的runtime.mcache结构体:
// dummy mspan that contains no free objects. var emptymspan mspan func allocmcache() *mcache { var c *mcache // 在系统栈中调用mheap的缓存分配器创建mcache systemstack(func() { lock(&mheap_.lock) // mheap是所有协程共用的需要加锁访问 c = (*mcache)(mheap_.cachealloc.alloc()) c.flushGen = mheap_.sweepgen unlock(&mheap_.lock) }) // 将alloc数组设置为空span for i := range c.alloc { c.alloc[i] = &emptymspan } c.nextSample = nextSample() return c }但是刚刚初始化的mcache中所有的mspan都是空的占位符emptymspan 之后需要时会从mcentral中获取指定spanClass的span:
// refill acquires a new span of span class spc for c. This span will // have at least one free object. The current span in c must be full. // // Must run in a non-preemptible context since otherwise the owner of // c could change. func (c *mcache) refill(spc spanClass) { // Return the current cached span to the central lists. s := c.alloc[spc] ............... if s != &emptymspan { // Mark this span as no longer cached. if s.sweepgen != mheap_.sweepgen+3 { throw("bad sweepgen in refill") } mheap_.central[spc].mcentral.uncacheSpan(s) } // Get a new cached span from the central lists. s = mheap_.central[spc].mcentral.cacheSpan() ................ ............... c.alloc[spc] = s }refill这个方法在runtime.malloc方法中会调用; mcentral mcentral是所有线程共享的的缓存,需要加锁访问;它的主要作用是为mcache提供切分好的mspan资源。每个spanClass对应一个级别的mcentral;mcentral整体是在mheap中管理的,它之中包含两个mspan链表,Go1.17.7版本中分别为partial代表有空闲区域的span、full代表无空闲区域的span列表。(这里并不是网上很多文章讲的nonempty和empty队列)
type mcentral struct { spanclass spanClass partial [2]spanSet // list of spans with a free object full [2]spanSet // list of spans with no free objects }
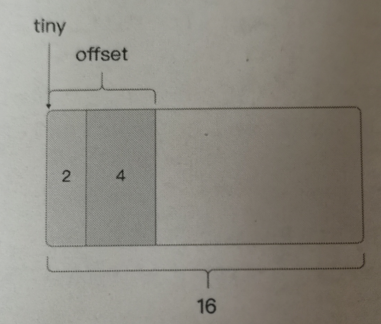
type spanSet struct { spineLock mutex spine unsafe.Pointer // *[N]*spanSetBlock, accessed atomically spineLen uintptr // Spine array length, accessed atomically spineCap uintptr // Spine array cap, accessed under lock index headTailIndex }对于微小对象和小对象的内存会首先从mcache和mcentral中获取,这部分要看runtime.malloc代码 微小对象分配 Go中小于16字节的作为微小对象,微小对象会被放入sizeClass为2的span中即16字节,这里并不是说每次微小对象分配都分配一个16字节的空间,而是会把一个16字节的空间按照2、4、8的规则进行字节对齐的形式来存储,比如1字节的char会被分配2字节空间,9字节的数据会被分配2+8=10字节空间。
off := c.tinyoffset // Align tiny pointer for required (conservative) alignment. if size&7 == 0 { off = alignUp(off, 8) } else if sys.PtrSize == 4 && size == 12 { // Conservatively align 12-byte objects to 8 bytes on 32-bit // systems so that objects whose first field is a 64-bit // value is aligned to 8 bytes and does not cause a fault on // atomic access. See issue 37262. // TODO(mknyszek): Remove this workaround if/when issue 36606 // is resolved. off = alignUp(off, 8) } else if size&3 == 0 { off = alignUp(off, 4) } else if size&1 == 0 { off = alignUp(off, 2) }如果当前的一个16字节元素能够容纳新的微小对象则充分利用当前元素空间
if off+size <= maxTinySize && c.tiny != 0 { // The object fits into existing tiny block. x = unsafe.Pointer(c.tiny + off) c.tinyoffset = off + size c.tinyAllocs++ mp.mallocing = 0 releasem(mp) return x }
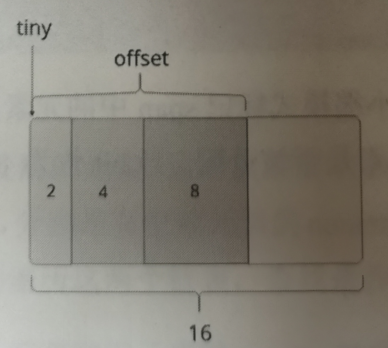 否则从下一个元素中去分配空间
否则从下一个元素中去分配空间
// Allocate a new maxTinySize block. span = c.alloc[tinySpanClass] v := nextFreeFast(span) if v == 0 { v, span, shouldhelpgc = c.nextFree(tinySpanClass) } x = unsafe.Pointer(v) (*[2]uint64)(x)[0] = 0 (*[2]uint64)(x)[1] = 0 // See if we need to replace the existing tiny block with the new one // based on amount of remaining free space. if !raceenabled && (size < c.tinyoffset || c.tiny == 0) { // Note: disabled when race detector is on, see comment near end of this function. c.tiny = uintptr(x) c.tinyoffset = size } size = maxTinySizenextFreeFast和nextFree的内容在下面介绍 小对象分配
var sizeclass uint8 if size <= smallSizeMax-8 { sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)] } else { sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)] } size = uintptr(class_to_size[sizeclass]) spc := makeSpanClass(sizeclass, noscan) span = c.alloc[spc] v := nextFreeFast(span) if v == 0 { v, span, shouldhelpgc = c.nextFree(spc) } x = unsafe.Pointer(v) if needzero && span.needzero != 0 { memclrNoHeapPointers(unsafe.Pointer(v), size) }1-6行,根据参数中要分配的空间大小计算对应的sizeClass即对象大小 7-9行,根据对象大小的等级以及是否有指针(noscan)找到mcache的alloc数组中对应的span 第10行,先计算当前的span中是否有空闲空间,并返回可分配的空闲空间地址 11-13行,如果mcache当前对应的span没有空闲空间,则进入到nextFree函数寻找一个空闲的span 然后经过其他处理(垃圾回收标记、锁定关系标识等)返回给调用方 同时也需要注意到,这里的空间分配都是需要做内存对齐的,比如申请17字节的空间,但是span的分类中是按照8的倍数进行增长的,比17大且最接近的级别是32,所以即使需要17字节,在内部也会使用一个32字节的空间,这也是上面代码中需要根据size计算sizeClass的原因;也可以看到这种分配方式必然会存在内存浪费,TCMalloc算法机尽量将浪费率控制在15%以内 nextFreeFast中可以看到用到了上面mspan中的freeIndex、allocCache等属性; 因为这里使用了allocCache来对前64字节进行快速访问,如果当前分配字节在allocCache范围之内,可以直接利用位图缓存来进行快速计算可分配的区域;至于为什么是64字节,我猜与CPU中CacheLine的大小有关,64位CPU的cache line就是64字节,利用此来提升CPU缓存命中率,提升性能。
// nextFreeFast returns the next free object if one is quickly available. // Otherwise it returns 0. func nextFreeFast(s *mspan) gclinkptr { theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache? if theBit < 64 { result := s.freeindex + uintptr(theBit) if result < s.nelems { freeidx := result + 1 if freeidx%64 == 0 && freeidx != s.nelems { return 0 } s.allocCache >>= uint(theBit + 1) s.freeindex = freeidx s.allocCount++ return gclinkptr(result*s.elemsize + s.base()) } } return 0 }关于freeIndex和allocCache的关系,实际是利用了bitmap位图缓存和阶段标记的方式来进行配合,因为allocCache一次只能缓存64字节数据,所以在span被分配过程中,allocCache是滚动前进的,一次标识一块64字节区域,而freeIndex代表上次分配结束的元素位置,通过当前allocCache中的空闲位置+freeIndex即可以算出当前span被分配的区域。
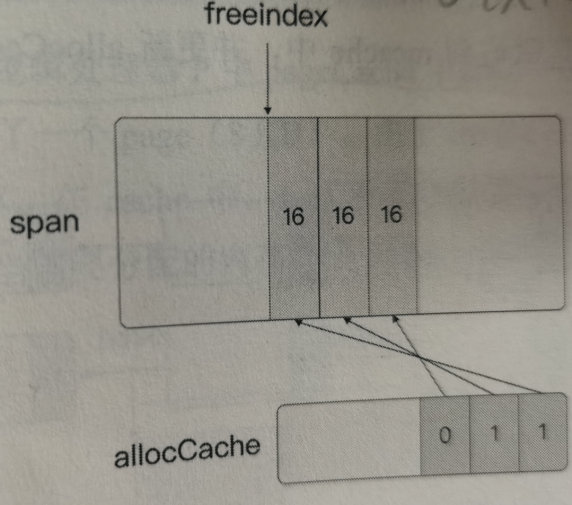 具体计算方式可以mbitmap.go中的nextFreeIndex方法
具体计算方式可以mbitmap.go中的nextFreeIndex方法
// nextFreeIndex returns the index of the next free object in s at // or after s.freeindex. // There are hardware instructions that can be used to make this // faster if profiling warrants it. func (s *mspan) nextFreeIndex() uintptr { sfreeindex := s.freeindex snelems := s.nelems if sfreeindex == snelems { return sfreeindex } if sfreeindex > snelems { throw("s.freeindex > s.nelems") } aCache := s.allocCache bitIndex := sys.Ctz64(aCache) for bitIndex == 64 { // Move index to start of next cached bits. sfreeindex = (sfreeindex + 64) &^ (64 - 1) if sfreeindex >= snelems { s.freeindex = snelems return snelems } whichByte := sfreeindex / 8 // Refill s.allocCache with the next 64 alloc bits. s.refillAllocCache(whichByte) aCache = s.allocCache bitIndex = sys.Ctz64(aCache) // nothing available in cached bits // grab the next 8 bytes and try again. } result := sfreeindex + uintptr(bitIndex) if result >= snelems { s.freeindex = snelems return snelems } s.allocCache >>= uint(bitIndex + 1) sfreeindex = result + 1 if sfreeindex%64 == 0 && sfreeindex != snelems { // We just incremented s.freeindex so it isn't 0. // As each 1 in s.allocCache was encountered and used for allocation // it was shifted away. At this point s.allocCache contains all 0s. // Refill s.allocCache so that it corresponds // to the bits at s.allocBits starting at s.freeindex. whichByte := sfreeindex / 8 s.refillAllocCache(whichByte) } s.freeindex = sfreeindex return result }
在回到nextFree函数中
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) { s = c.alloc[spc] shouldhelpgc = false freeIndex := s.nextFreeIndex() // 获取可分配的元素位置 if freeIndex == s.nelems { //如果当前span没有可分配空间,调用refill方法把当前span交给mcentral的full队列 // 并从mcentral的partial队列取一个有空闲的span放到mcache上 // The span is full. if uintptr(s.allocCount) != s.nelems { println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems) throw("s.allocCount != s.nelems && freeIndex == s.nelems") } c.refill(spc) shouldhelpgc = true s = c.alloc[spc] freeIndex = s.nextFreeIndex() // 在新获取的span中重新计算freeIndex } if freeIndex >= s.nelems { throw("freeIndex is not valid") } v = gclinkptr(freeIndex*s.elemsize + s.base()) // 获取span中数据的起始地址加上当前已分配的区域获取一个可分配的空闲区域 s.allocCount++ if uintptr(s.allocCount) > s.nelems { println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems) throw("s.allocCount > s.nelems") } return }函数第4行获取下一个被分配的元素位置,如果freeIndex等于span中的最大元素数目,代表当前级别span已经被分配完了,这时候需要调用mcache的refill方法去mheap中对应的spanClass的mcentral中,把当前没有空闲的span还给mcentral的full队列,并从partail对列中获取一个有空闲区域的span放到mcache上。 下方可以看到refill方法,如果mcache对应等级的span没有则直接从mcentral中获取,否则代表当前span已经没有可分配的空间,所以需要把这个span重新交给mcentral,等待垃圾回收器标记完成之后则可以后面继续使用。
func (c *mcache) refill(spc spanClass) { // Return the current cached span to the central lists. s := c.alloc[spc] ............... if s != &emptymspan { // Mark this span as no longer cached. if s.sweepgen != mheap_.sweepgen+3 { throw("bad sweepgen in refill") } mheap_.central[spc].mcentral.uncacheSpan(s) } // Get a new cached span from the central lists. s = mheap_.central[spc].mcentral.cacheSpan() ................ ............... c.alloc[spc] = s }进入到cacheSpan函数中可以看到,这里的获取空闲span经过以下几个顺序:
- 是先从partail队列中已经被垃圾回收清扫的部分尝试拿一个span
- 如果pop没有代表当前没有被GC清扫的span,从partial队列中未被GC清扫的部分尝试获取空闲span,并进行清扫
- 如果partail队列都没获取到,尝试从full队列的未清扫区获取一个span,进行清扫,并放入到full队列的以清扫区,代表这个span不会分配给其他的mcache了;
- 如果未清扫区也没有获取到对应的span则代表mcentral需要扩容,向mheap申请一块区域。
// Allocate a span to use in an mcache. func (c *mcentral) cacheSpan() *mspan { // Deduct credit for this span allocation and sweep if necessary. spanBytes := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) * _PageSize deductSweepCredit(spanBytes, 0) traceDone := false if trace.enabled { traceGCSweepStart() } spanBudget := 100 var s *mspan sl := newSweepLocker() sg := sl.sweepGen // Try partial swept spans first. if s = c.partialSwept(sg).pop(); s != nil { goto havespan } // Now try partial unswept spans. for ; spanBudget >= 0; spanBudget-- { s = c.partialUnswept(sg).pop() if s == nil { break } if s, ok := sl.tryAcquire(s); ok { // We got ownership of the span, so let's sweep it and use it. s.sweep(true) sl.dispose() goto havespan } } // Now try full unswept spans, sweeping them and putting them into the // right list if we fail to get a span. for ; spanBudget >= 0; spanBudget-- { s = c.fullUnswept(sg).pop() if s == nil { break } if s, ok := sl.tryAcquire(s); ok { // We got ownership of the span, so let's sweep it. s.sweep(true) // Check if there's any free space. freeIndex := s.nextFreeIndex() if freeIndex != s.nelems { s.freeindex = freeIndex sl.dispose() goto havespan } // Add it to the swept list, because sweeping didn't give us any free space. c.fullSwept(sg).push(s.mspan) } // See comment for partial unswept spans. } sl.dispose() if trace.enabled { traceGCSweepDone() traceDone = true } // We failed to get a span from the mcentral so get one from mheap. s = c.grow() if s == nil { return nil } // At this point s is a span that should have free slots. havespan: if trace.enabled && !traceDone { traceGCSweepDone() } n := int(s.nelems) - int(s.allocCount) if n == 0 || s.freeindex == s.nelems || uintptr(s.allocCount) == s.nelems { throw("span has no free objects") } freeByteBase := s.freeindex &^ (64 - 1) whichByte := freeByteBase / 8 // Init alloc bits cache. s.refillAllocCache(whichByte) // Adjust the allocCache so that s.freeindex corresponds to the low bit in // s.allocCache. s.allocCache >>= s.freeindex % 64 return s }对于mcache如果觉得当前级别的span剩余空间无法满足用户要求的大小,则会把这个span交给mcentral;mcentral根据条件判断是直接放到堆中等待回收还是需要放到自己来管理,如果自己管理那么再判断这个span的freeIndex与容量的关系如果还有剩余容量则进入partialSweep队列,如果么有容量则进入fullSweep中。
func (c *mcentral) uncacheSpan(s *mspan) { if s.allocCount == 0 { throw("uncaching span but s.allocCount == 0") } sg := mheap_.sweepgen stale := s.sweepgen == sg+1 // Fix up sweepgen. if stale { // Span was cached before sweep began. It's our // responsibility to sweep it. // // Set sweepgen to indicate it's not cached but needs // sweeping and can't be allocated from. sweep will // set s.sweepgen to indicate s is swept. atomic.Store(&s.sweepgen, sg-1) } else { // Indicate that s is no longer cached. atomic.Store(&s.sweepgen, sg) } // Put the span in the appropriate place. if stale { // It's stale, so just sweep it. Sweeping will put it on // the right list. // // We don't use a sweepLocker here. Stale cached spans // aren't in the global sweep lists, so mark termination // itself holds up sweep completion until all mcaches // have been swept. ss := sweepLocked{s} ss.sweep(false) } else { if int(s.nelems)-int(s.allocCount) > 0 { // Put it back on the partial swept list. c.partialSwept(sg).push(s) } else { // There's no free space and it's not stale, so put it on the // full swept list. c.fullSwept(sg).push(s) } } }可以看到mcentral中的partial和full都是拥有两个元素的spanSet数组,这样的目的其实是双缓存策略,当垃圾回收只回收和用户协程并发进行,每次回收一半而写入另一半,下一次交替过来,这样保证永远有空间可以分配,而不是串行等待垃圾回收完成后在分配空间,以空间换时间来提升响应性能
type mcentral struct { spanclass spanClass partial [2]spanSet // list of spans with a free object full [2]spanSet // list of spans with no free objects }mcentral中的grow方法涉及到mheap的内存分配和管理,下面介绍。 mheap mheap与TCMalloc中的PageHeap类似,代表Go中所持有的堆空间,mcentral管理的span也是从这里拿到的。当mcentral没有空闲span时,会向mheap申请,如果mheap中也没有资源了,会向操作系统来申请内存。向操作系统申请是按照页为单位来的(4kb),然后把申请来的内存页按照page(8kb)、span(page的倍数)、chunk(512kb)、heapArena(64m)这种级别来组织起来。 pageCache的位图缓存 mcentral中的grow方法会调用mheap的alloc方法
// grow allocates a new empty span from the heap and initializes it for c's size class. func (c *mcentral) grow() *mspan { npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) size := uintptr(class_to_size[c.spanclass.sizeclass()]) s, _ := mheap_.alloc(npages, c.spanclass, true) if s == nil { return nil } // Use division by multiplication and shifts to quickly compute: // n := (npages << _PageShift) / size n := s.divideByElemSize(npages << _PageShift) s.limit = s.base() + size*n heapBitsForAddr(s.base()).initSpan(s) return s }然后内部调用allocSpan方法。
func (h *mheap) alloc(npages uintptr, spanclass spanClass, needzero bool) (*mspan, bool) { // Don't do any operations that lock the heap on the G stack. // It might trigger stack growth, and the stack growth code needs // to be able to allocate heap. var s *mspan systemstack(func() { // To prevent excessive heap growth, before allocating n pages // we need to sweep and reclaim at least n pages. if !isSweepDone() { h.reclaim(npages) } s = h.allocSpan(npages, spanAllocHeap, spanclass) }) if s == nil { return nil, false } isZeroed := s.needzero == 0 if needzero && !isZeroed { memclrNoHeapPointers(unsafe.Pointer(s.base()), s.npages<<_PageShift) isZeroed = true } s.needzero = 0 return s, isZeroed }
而在allocSpan方法中,如果要分配的区域不大,并且不需要考虑物理对齐的情况下,会首先从逻辑处理器的pageCache缓存上去获取空间,这样的目的是为了无锁分配空间提升性能(又是空间换时间)。 下面的16行可以看到先从逻辑处理器P的pcache上尝试获取对应的空间。
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) { // Function-global state. gp := getg() base, scav := uintptr(0), uintptr(0) // On some platforms we need to provide physical page aligned stack // allocations. Where the page size is less than the physical page // size, we already manage to do this by default. needPhysPageAlign := physPageAlignedStacks && typ == spanAllocStack && pageSize < physPageSize // If the allocation is small enough, try the page cache! // The page cache does not support aligned allocations, so we cannot use // it if we need to provide a physical page aligned stack allocation. pp := gp.m.p.ptr() if !needPhysPageAlign && pp != nil && npages < pageCachePages/4 { c := &pp.pcache // If the cache is empty, refill it. if c.empty() { lock(&h.lock) *c = h.pages.allocToCache() unlock(&h.lock) } // Try to allocate from the cache. base, scav = c.alloc(npages) if base != 0 { s = h.tryAllocMSpan() if s != nil { goto HaveSpan } // We have a base but no mspan, so we need // to lock the heap. } }
 pageCache的结构如下:
代码在runtime/mpagecache.go中
pageCache的结构如下:
代码在runtime/mpagecache.go中
// 代表pageCache能够使用的空间数,8x64一共是512kb空间 const pageCachePages = 8 * unsafe.Sizeof(pageCache{}.cache) // pageCache represents a per-p cache of pages the allocator can // allocate from without a lock. More specifically, it represents // a pageCachePages*pageSize chunk of memory with 0 or more free // pages in it. type pageCache struct { base uintptr // base代表该虚拟内存的基线地址 // cache和scav都是起到位图标记的作用,cache主要是标记哪些内存位置已经被使用了,scav标记已经被清除的区域 // 用来加速垃圾未收,在垃圾回收一定条件下两个可以互换,提升分配和垃圾回收效率。 cache uint64 // 64-bit bitmap representing free pages (1 means free) scav uint64 // 64-bit bitmap representing scavenged pages (1 means scavenged) }下面回到mheap的allocSpan方法中 基数树 如果pageCache不满足分配条件或者没有空闲空间了,则对mheap进行全局加锁获取内存
// For one reason or another, we couldn't get the // whole job done without the heap lock. lock(&h.lock) ................. if base == 0 { // Try to acquire a base address. base, scav = h.pages.alloc(npages) if base == 0 { if !h.grow(npages) { unlock(&h.lock) return nil } base, scav = h.pages.alloc(npages) if base == 0 { throw("grew heap, but no adequate free space found") } } } ................ unlock(&h.lock)这里首先从mheap的pages中去获取,这个pages是一个pageAlloc的结构体实例,它是以基数树的形式来进行管理。最多有5层,每个节点都对应一个pallocSum对象,除叶子节点外每个节点都包含连续8个子节点的内存信息,越上层的节点包含的内存信息越多,一颗完整的基数树最多能够代表16G内存空间。同时这里面还做了一些搜索优化 然后当mheap没有空间时,会向操作系统去申请,这部分代码在mheap的grow函数中,会调用到pageAlloc的grow和sysGrow方法,内部会调用平台相关的sysUsed方法来向操作系统去申请内存。
 mheap中还有一个要注意的地方,就是对mcentral的管理
mheap中还有一个要注意的地方,就是对mcentral的管理
//path: /usr/local/go/src/runtime/mheap.go type mheap struct { lock mutex // spans: 指向mspans区域,用于映射mspan和page的关系 spans []*mspan // 指向bitmap首地址,bitmap是从高地址向低地址增长的 bitmap uintptr // 指示arena区首地址 arena_start uintptr // 指示arena区已使用地址位置 arena_used uintptr // 指示arena区末地址 arena_end uintptr central [67*2]struct { mcentral mcentral pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte } }
首先注意到这里的sys.CacheLineSize,根据这个对mcentral做空余对齐,来防止CPU的伪共享缓存带来的性能问题(关于伪共享缓存推荐看我的这篇文章:https://www.cnblogs.com/dojo-lzz/p/16183006.html)。 其次要注意到这里mcentral的个数是67x2=134,也是针对有指针和无指针对象分别处理,提升垃圾回收效率,进而提升整体性能。 借用一下这张图看的更清晰一些
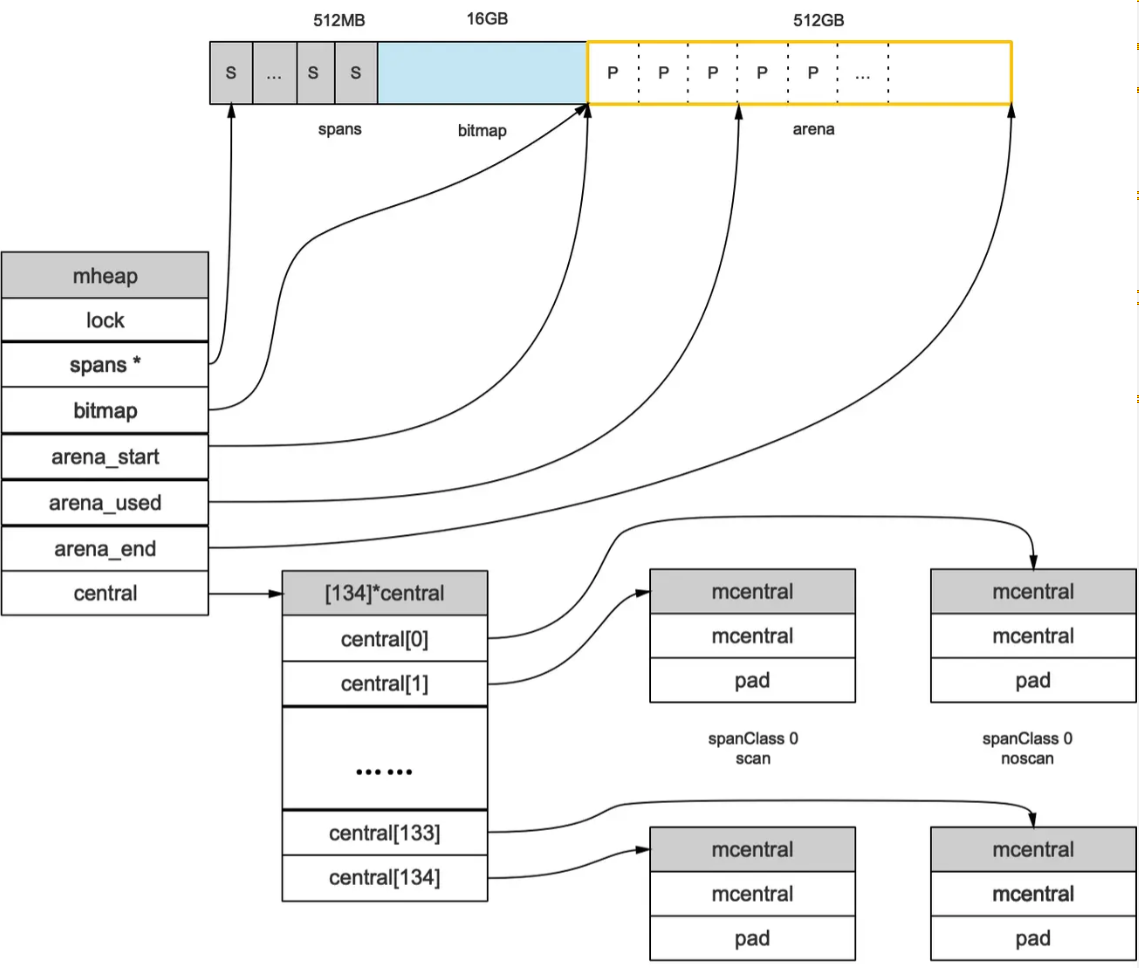 总结来看通过细致的对象划分、极致的多级缓存+无锁策略缓存、精确的位图管理来进行精细化的内存管理和性能保障。
整个文章大概花费一个月时间,通过自己看源码能够发现,现有讲解Go内存分配的资料要么已经老旧、要么人云亦云,还是独立思考实践最能揭露本质。
参考文章
总结来看通过细致的对象划分、极致的多级缓存+无锁策略缓存、精确的位图管理来进行精细化的内存管理和性能保障。
整个文章大概花费一个月时间,通过自己看源码能够发现,现有讲解Go内存分配的资料要么已经老旧、要么人云亦云,还是独立思考实践最能揭露本质。
参考文章
- 图解Go语言内存分配:https://juejin.cn/post/6844903795739082760
- 内存分配器:https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-memory-allocator/
- 栈空间管理:https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-stack-management/
- 技术干货 | 理解 Go 内存分配:https://cloud.tencent.com/developer/article/1861429
- 一个简单的内存分配器:https://github.com/KatePang13/Note/blob/main/%E4%B8%80%E4%B8%AA%E7%AE%80%E5%8D%95%E7%9A%84%E5%86%85%E5%AD%98%E5%88%86%E9%85%8D%E5%99%A8.md
- 编写自己的内存分配器:https://soptq.me/2020/07/18/mem-allocator/
- Go内存分配原来这么简单:https://segmentfault.com/a/1190000020338427
- 图解Go语言内存分配:https://juejin.cn/post/6844903795739082760
- TCMalloc介绍:https://blog.csdn.net/aaronjzhang/article/details/8696212
- TCMalloc解密:https://wallenwang.com/2018/11/tcmalloc/
- 图解TCMalloc:https://zhuanlan.zhihu.com/p/29216091
- 内存分配器:https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-memory-allocator/
- 进程与线程:https://baijiahao.baidu.com/s?id=1687308494061329777&wfr=spider&for=pc
- 内存分配器 (Memory Allocator):https://blog.csdn.net/weixin_30940783/article/details/97806139
