hive 存储格式有很多,但常用的一般是 TextFile、ORC、Parquet 格式,在我们单位最多的也是这三种
hive 默认的文件存储格式是 TextFile。
除 TextFile 外的其他格式的表不能直接从本地文件导入数据,要先导入到 TextFile 格式的表中,再从表中用 insert 导入到其他格式的表中。
一、TextFileTextFile 是行式存储。
建表时无需指定,一般默认这种格式,以这种格式存储的文件,可以直接在 HDFS 上 cat 查看数据。
可以用任意分隔符对列分割,建表时需要指定分隔符。
不会对文件进行压缩,因此加载数据的时候会比较快,因为不需要解压缩;但也因此更占用存储空间。
二、ORCFileORCFile 是列式存储。
建表时需指定 STORED AS ORC,文件存储方式为二进制文件。
Orc表支持None、Zlib、Snappy压缩,默认支持Zlib压缩。
Zlib 压缩率比 Snappy 高,Snappy 效率比 Zlib 高。
这几种压缩方式都不支持文件分割,所以压缩后的文件在执行 Map 操作时只会被一个任务所读取。
因此若压缩文件较大,处理该文件的时间比处理其它普通文件的时间要长,造成数据倾斜。
另外,hive 建事务表需要指定为 orc 存储格式。
ORC 格式如下所示:
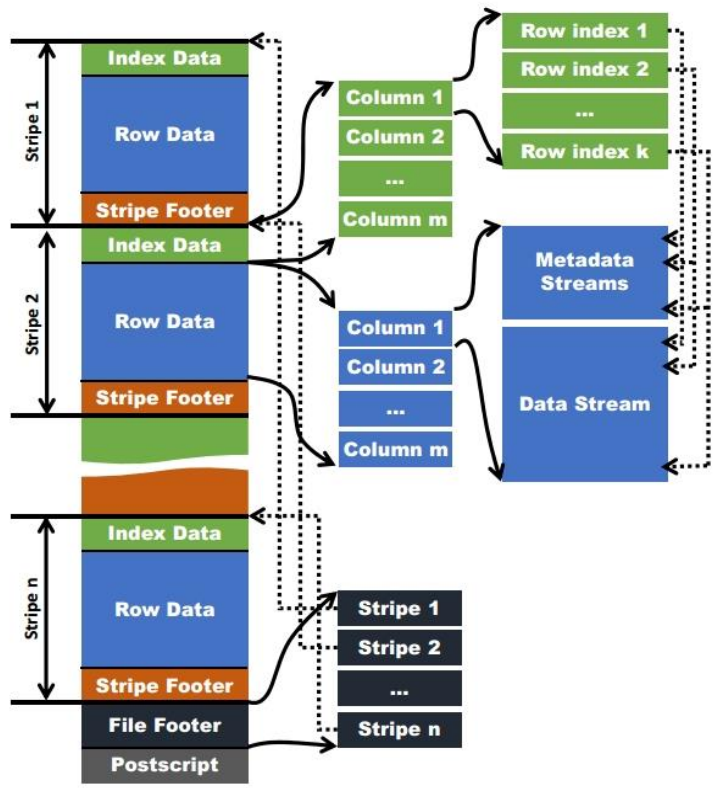
- stripe:存储数据的地方,包括实际数据、数据的索引信息
- index data:保存了数据在 stripe 中位置的索引信息
- rows data:数据实际存储的地方,数据以流的形式进行存储
- stripe footer:保存数据所在的文件目录
- file footer:包含了文件中 stripe 的列表,每个 stripe 的行数,以及每个列的数据类型。它还包含每个列的最小值、最大值、行计数、求和等聚合信息。
- postscript:含有压缩参数和压缩大小相关的信息
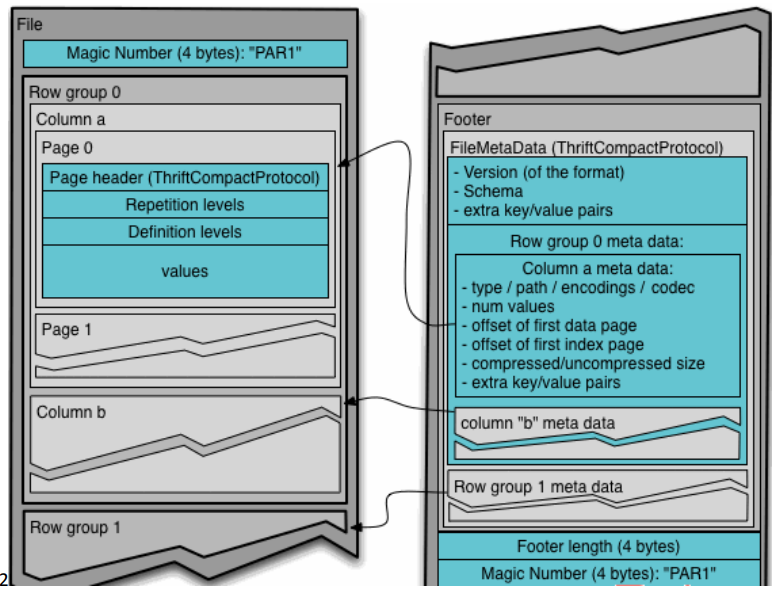
Parquet 也是列式存储。
建表时需指定 STORED AS PARQUET,文件存储方式为二进制文件。
可以使用的压缩方式有 UNCOMPRESSED、 SNAPPY、GZP和LZO。默认值为 UNCOMPRESSED,表示页的压缩方式
-
行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
-
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
同样的数据,TextFile 为 2.4G 的情况下,将原数据存放为 ORC 以及 Parquet 格式后,其占用存储大小以及查询效率大致如下:
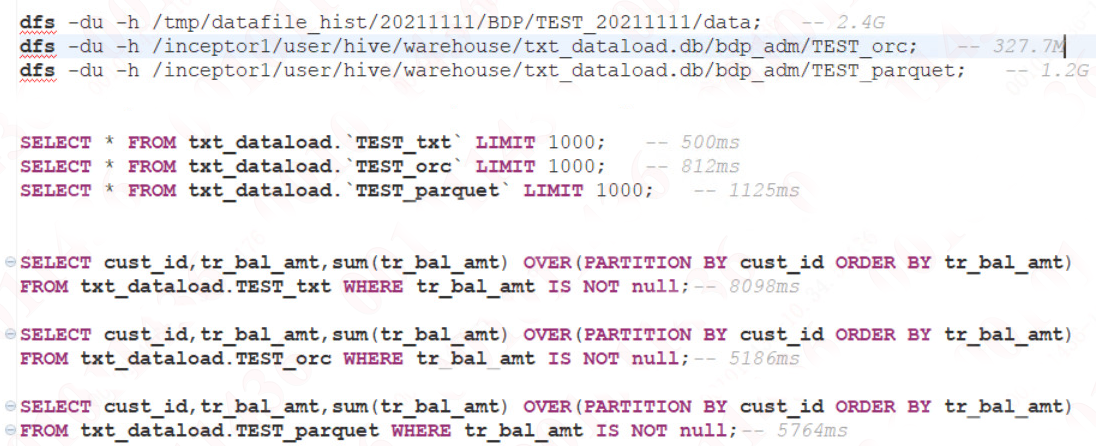
由此可以看出压缩比:ORC > Parquet > TextFile
在只有 Fecth 的情况下,由于 TextFile 不需要解压缩,因此效率较高。
对于需要 MapReduce 操作的查询,效率:ORC >= Parquet > TextFile
当然,这只是我自己简单的测试,有些变量并没有控制好。
比如在单个文件比较大的情况下,可能 Parquet 的效率会比较高。
在实际生产中,使用 Parquet 存储 lzo 压缩的方式比较常见,这种情况下可以避免由于读取不可分割的大文件引发的数据倾斜。
但是,如果数据量并不大,使用 ORC 存储 snappy 压缩的效率还是非常高的;对于需要事务的场景,还是用 ORC。
至于要用哪种存储格式,需要基于自身业务进行考量。
今天的文章到这里就结束了,如果觉得写的不错的话,可以随手点个赞和关注!
关注“大数据的奇妙冒险”,转载请注明出处!