设计一个支持数百万用户的系统是非常有挑战性的, 这是一个需要不断调整和优化的过程, 接下来的内容中, 我将构建一个系统, 从单个用户开始,到最后支持数百万的用户。
从单个服务开始千里之行,始于足下,让我们从最简单的单个服务开始。所有的内容都在一台服务器上运行,包括 Web 程序, 数据库,缓存 等等, 如下图
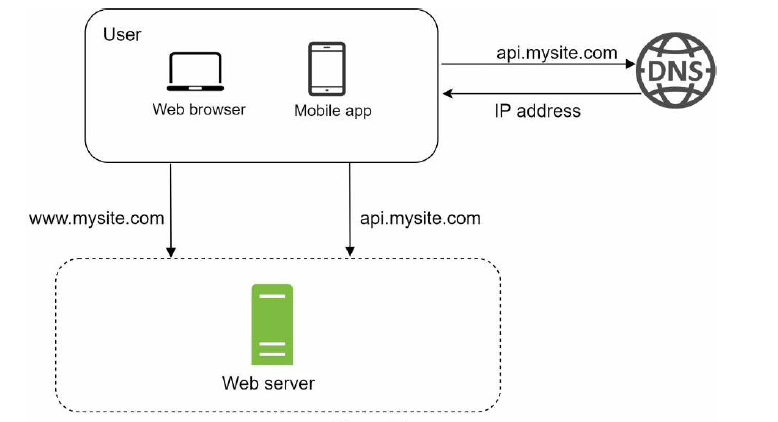
我们看一下它的工作流程。
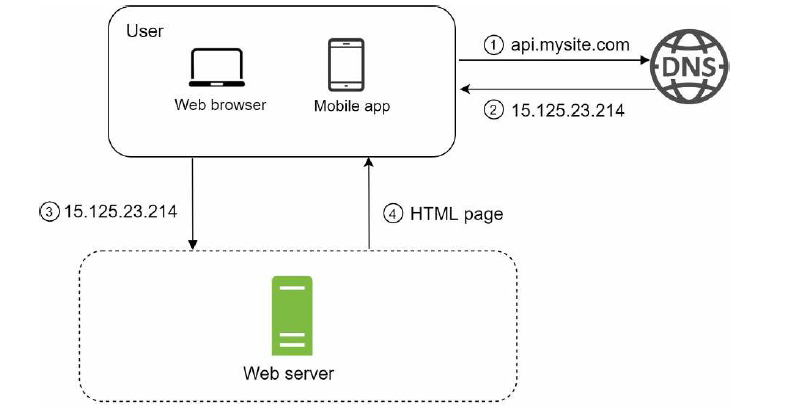
- 用户通过域名访问网站, 比如, api.mysite.com, 通常情况下, 域名解析服务 (DNS) 是由第三方提供的付费服务, 而不是我们的服务器所提供的。
- 返回 IP 地址给浏览器或者移动设备, 比如, 15.125.23.214。
- 通过 IP 地址, 发送 Http 请求到我们的 Web 服务器。
- Web 服务器返回 html 或者 json 内容, 浏览器进行渲染。
随着用户量的增长,此时一台服务器已经独木难支,我们需要两台服务器, 一个用于 Web 服务, 一个用于数据库。

您可以选择关系型数据库和非关系型数据库,那它们都有什么特点呢?
关系型数据库也称为关系型数据库管理系统 (RDBMS) 或
SQL 数据库,最常见的有 MySQL、Oracle 、PostgreSQL、Sql Server 等,可以通过 SQL 进行跨表查询。
而非关系型数据库也称为 NoSQL 数据库,最常见的有 Redis、 CouchDB,Neo4j、Cassandra、HBase、Amazon DynamoDB 等。它们分为四类:键值(Key-Value)存储数据库、列存储数据库、文档型数据库、图(Graph)数据库。
对于大多数开发人员来说,通常会选择关系型数据库。而非关系型数据库更适合以下几种情况:
-
应用程序需要超低延迟。
-
数据是非结构化的,或者没有任何关系数据。
-
只需要序列化和反序列化数据(JSON、XML、YAML 等)。
-
需要存储海量数据。
垂直缩放,又称为 "纵向扩展" (scale up), 是指升级服务器资源, 比如 CPU, RAM 等。而水平缩放又称为 "横向扩展" (scale out), 是指添加服务器到资源池中。
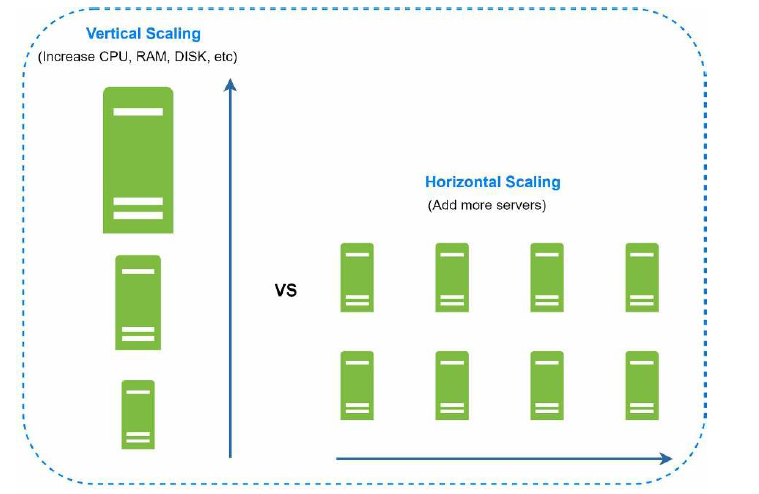
当流量比较少的时候, 选择纵向扩展就足够了,因为它足够简单,不过也有很大的局限性。
- 纵向扩展有硬件限制, 无限制的升级 CPU 和内存是不现实的。
- 纵向扩展没有高可用,如果一台服务器出现故障,网站或者应用就会直接崩溃。
而流量较大的时候,横向扩展是更好的选择,多个服务器也保证了高可用。如何让这些服务器更好的提供服务,我们还需要做负载均衡。
Load balancer负载均衡器可以平均分配流量给每台服务器,如下

我们水平扩展了 Web 服务,并引入了负载均衡器,来应对快速增长的网站流量, 并提供了高可用的服务。
现在,Web 层看上去不错,但是不要忘了,当前的设计只有一个数据库,并不支持故障转移和冗余。而数据库复制是一种常见的技术,可以解决这个问题。
Database replication数据库复制是把数据复制、传输到另外一个数据库,最终形成一个分布式数据库。用户可以访问到相同的信息,从而提高一致性、可靠性和性能。
通常它们之间是主/从(master/slave) 的关系,一主多从,主节点支持读写操作,而从节点仅支持读取操作,如下
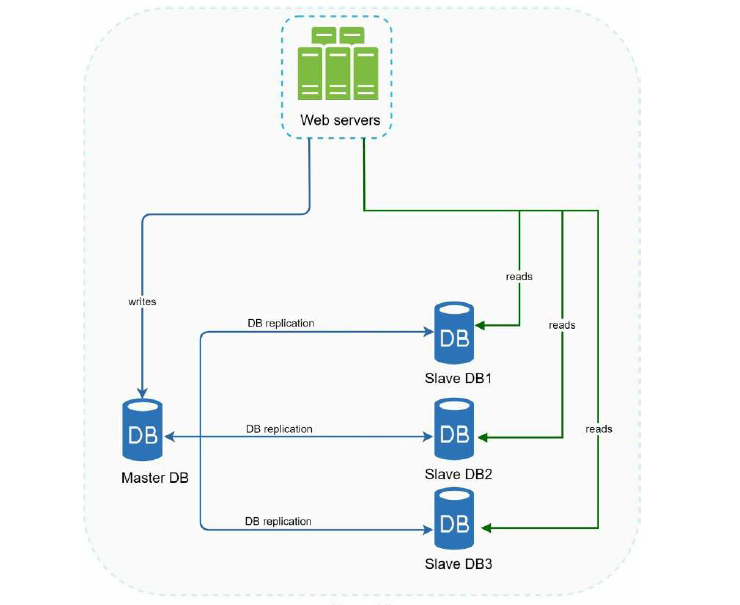
引入了数据库复制, 让我们看看现在网站整体的设计。

- 用户从 DNS 获取到 Load balancer 的 IP 地址, 并连接到 Load balancer。
- Http 请求被路由到服务器1 或者 服务器2。
- 使用数据库复制,进行读写分离。
现在,web 服务和数据库都已经做了优化,看上去不错!
接下来,还需要提升 web 的加载和响应时间,我们可以使用 CDN 缓存静态资源, 包括 js、css、image 等。
Content delivery network (CDN)CDN 是一个用于交付静态内容的网络服务,分布在不同的地理位置。当用户访问网站时,距离最近的 CDN 服务器提供静态资源,可以很好的改善网站的加载时间。
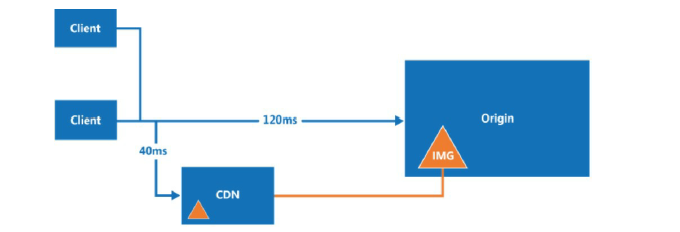
另外,对于数据库来说,我们也可以把一些热点数据添加到缓存中,这样可以减轻数据库的压力。
现在,我们的系统加了两层缓存。

- 对于静态资源,由 CDN 提供而不是 Web 服务器。
- 通过缓存数据来减少对数据库的访问。
现在我们的 Web 应用是有状态的服务,什么意思呢?假如用户在 Server 1 进行了登陆, 那后续也只能在 Server1 请求资源,因为只有 Server1 才拥有用户的会话信息,每个 Web 服务的状态都是独立的、隔离的。

我们需要把这些状态移出 Web层,通常单独保存在关系型数据库或者 NoSQL, 这样 Web 层就变成了无状态的。
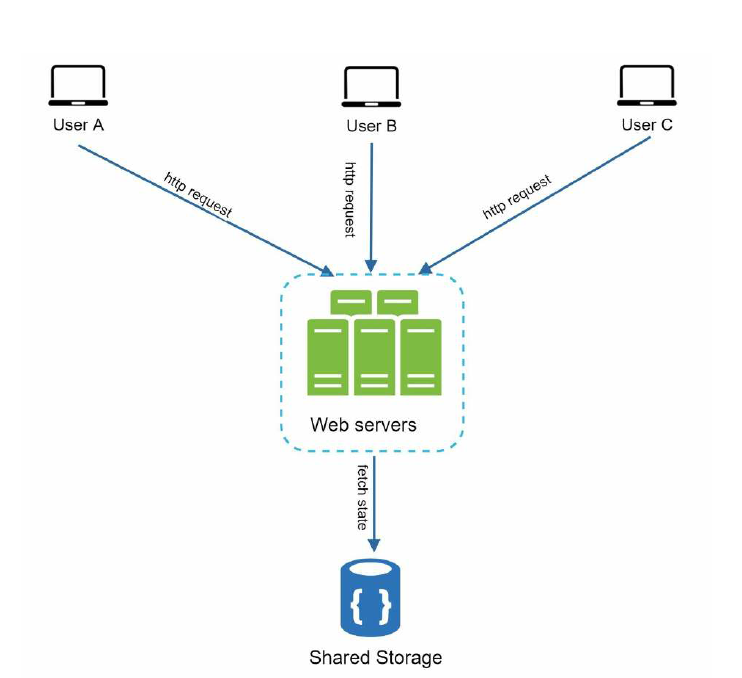
这样做有什么好处呢?在无状态的架构中,来自用户的 Http 请求可以发送到任何 Web 服务器,而状态信息统一保存在单独的共享存储中。无状态系统更简单、更容易扩展。

您的网站受到越来越多人的关注,用户也迅速发展,并扩展到全球。
如何为各个地区的用户都提供满意的服务?您可以在不同的地区设置多个数据中心。
如下图,我们分别在东、西两个地区配置了单独的数据中心, DC1、DC2。
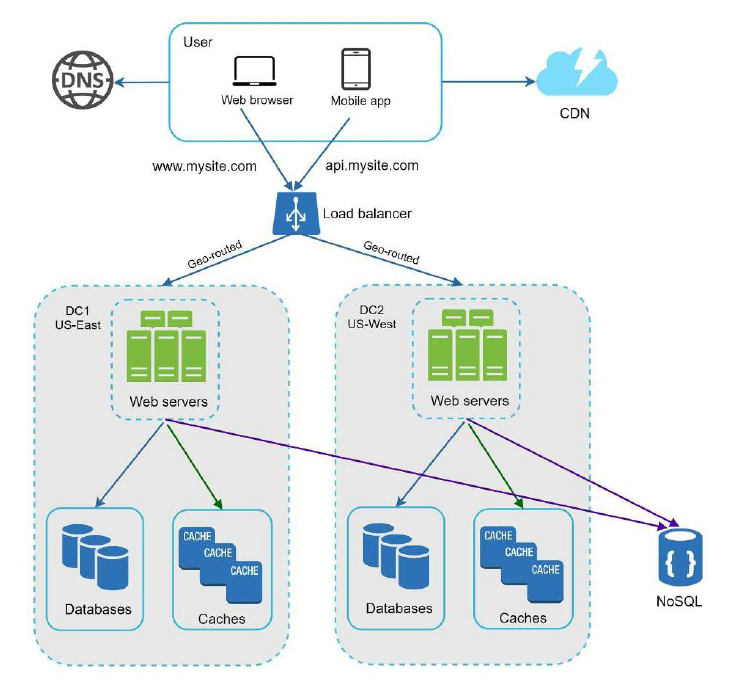
看上去不错!但是如何引导用户去不同的数据中心呢?答案是:DNS, 是的,众所周知,DNS 可以把我们网站的域名解析为 IP 地址,而使用 GeoDNS, 可以根据用户请求所在的位置,解析为不同的地区的 IP 地址。把用户引导到离他最近的数据中心,来达到加速的目的。
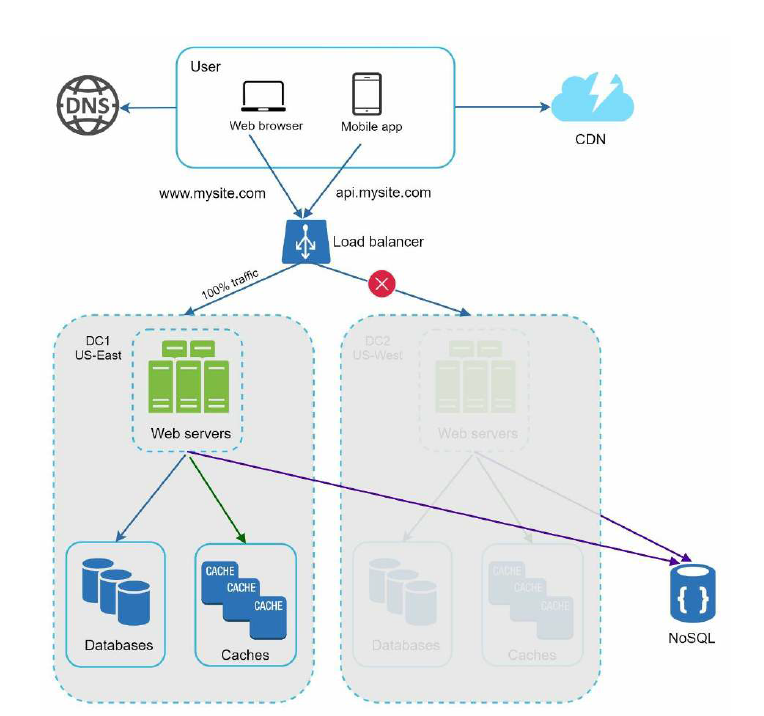
另外,如果某个数据中心发生重大事故,导致集群故障,我们可以把所有的流量都引导到健康的数据中心,这种架构就是我们常说的 "异地多活"。
Message queue当需要进行解耦时,引入消息队列通常是优先考虑的, 它支持异步通信,当您有耗时的任务需要处理时,可以通过生产者把消息发送到消息队列,Web 服务可以尽快的响应用户的请求,而消费者可以异步地去处理这些耗时任务。

当网站的流量越来越大时,就必须要引入监控工具了。
日志:监控错误日志很重要,它可以帮助您发现系统问题。 您可以把日志统一发送到日志中心,这样便于分析和查看。
指标:收集各种各样的指标,可以帮助我们更好的理解业务和系统。
- 系统指标::CPU、内存、磁盘 I/O,数据库等等。
- 业务指标:每日用户、活跃度等等。
自动化,当系统变得庞大且复杂时,我们需要引入自动化工具,CI/CD 很重要,自动化构建、测试、部署可以极大的提高开发人员的生产力。
现在,我们的系统引入了消息队列,以及一些监控和自动化工具。
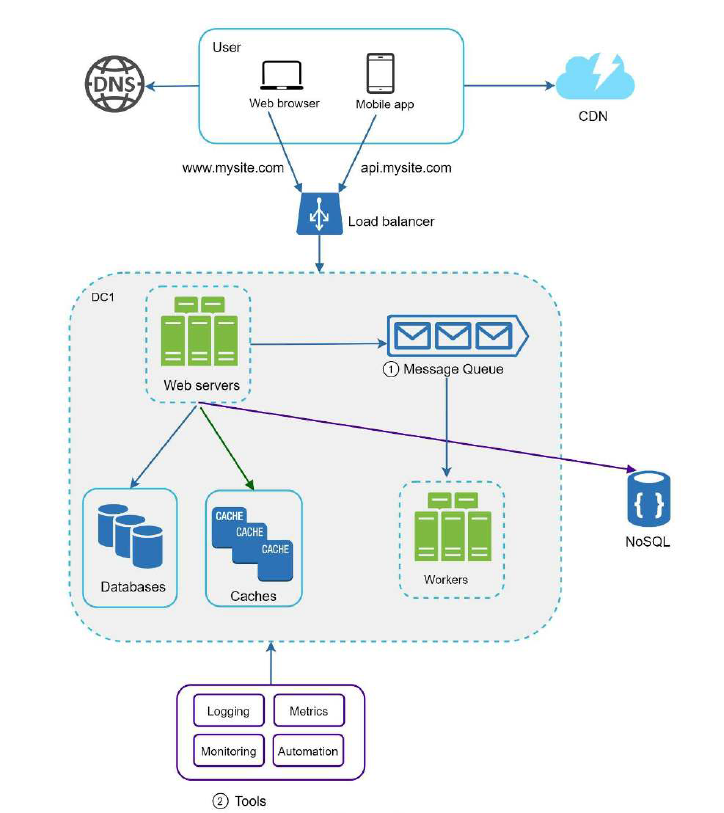
数据库的数据每天都在大步的增长,我们的数据库已经不堪重负了,是时候扩展数据库了,数据库分片是个很好的方案。
在下面的示例中,我们使用了哈希函数来进行分片, 根据不同的 user_id, 把数据平均分配到 4个数据库中。
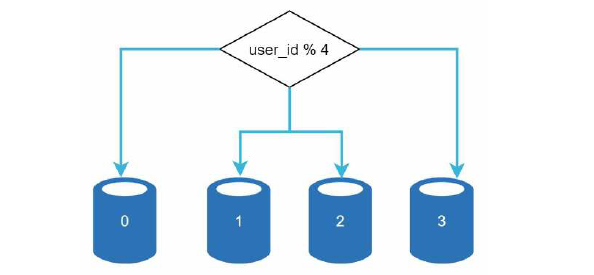
现在,我们看一下数据库的数据。
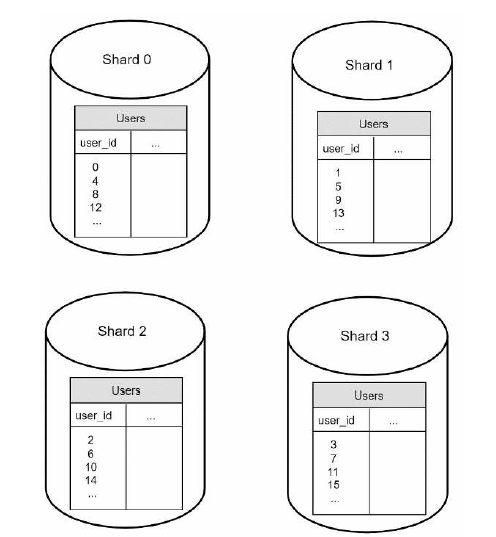
使用数据库分片的方案时,有一个要考虑的重要因素是分片键(sharding key), 或者叫分区键,比如上面的 user_id,因为可以通过 sharding key 找到相对应的数据库,另外,我们要选择一个可以均匀分布数据的键。
看起来不错!不过这种方案也给系统带来的复杂性和新的挑战,当数据越来越多,增加了数据库节点之后,我们需要重新进行数据分片。比如 useri_id % 5, 此时,为了保证哈希函数的正确路由,我们需要移动数据库大量的数据。
我们可以使用一致性哈希技术,来解决上面的问题,重新分片后,只需要移动一小部分数据即可,当然一致性哈希本文就不做详细的介绍了。
让我们看看最终的系统设计。
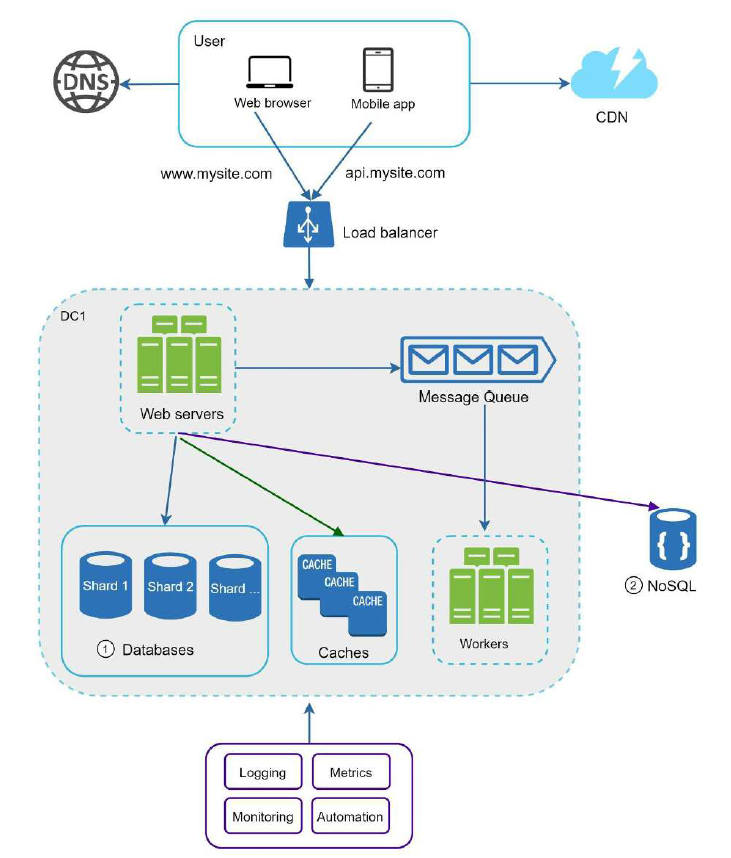
构建一个健壮的架构系统,其实是一个迭代的过程,为了支持数百万的用户的架构,我们需要做到以下几点:
- 保证 Web 层无状态
- 尽可能的缓存数据
- 异地多活,配置多个数据中心
- 使用分片扩展数据库
- 监控系统并使用自动化工具
希望对您有用!
译:等天黑