总是写很长的复杂的文章,目前发现真的有点无法静心去弄了,感觉写代码的动力要比写文章强大的多,所以,往后的文章还是写的剪短一点吧。
继续聊一聊模板匹配。 最近这方面也出了一些新的资料,说明还是有人关注他的。
我最近一个月的研究成果主要有以下几个方面。
一、顶层金字塔的候选点选择改由分水岭相关算法实现(用时10天)。
顶层的金字塔,我们是全图计算相关得分值的。当计算完所有的顶层金字塔得分后,我们得到了不同角度不同位置的一个全方位的候选点信息,接下来我们的目标就是从这些点中选择合适的候选点。
这里有几个指标可以作为初步筛选的依据:
1、最小的得分值。
2、重叠的区域。
在【工程应用一】 多目标多角度的快速模板匹配算法(基于NCC,效果无限接近Halcon中........) 一文中,我曾分享过如下的代码:
Point getNextMinLoc(Mat &result, Point minLoc, int maxValue, int templatW, int templatH) { int startX = minLoc.x - templatW / 3; int startY = minLoc.y - templatH / 3; int endX = minLoc.x + templatW / 3; int endY = minLoc.y + templatH / 3; if (startX < 0 || startY < 0) { startX = 0; startY = 0; } if (endX > result.cols - 1 || endY > result.rows - 1) { endX = result.cols - 1; endY = result.rows - 1; } int y, x; for (y = startY; y < endY; y++) { for (x = startX; x < endX; x++) { float *data = result.ptr<float>(y); data[x] = maxValue; } } double new_minValue, new_maxValue; Point new_minLoc, new_maxLoc; minMaxLoc(result, &new_minValue, &new_maxValue, &new_minLoc, &new_maxLoc); return new_minLoc; }
他通过不断的迭代,每次以剩余数据中最大值为候选点,并且逐步去除部分领域的方法来获取候选点。 我所能看到的开源项目里基本已这个代码为蓝图来实现他。
这个方法是可行的,我一直在用,但是他也是有缺陷的,当模板比较小的时候,我们的金字塔层数不够多,这个时候这个函数本身的计算的耗时就较为明显了,而且还有一个问题,就是他会返回相对来说较多的候选点。造成后续的进一步筛选的计算量加大。
我一直在寻找更为科学的办法,直到最近偶尔在一个地方看到一个这样的算法效果。


这不正是我们顶层金字塔需要的算法吗?
我尝试把几个测试图的顶层金字塔的得分数转换为图像,分别如下所示:
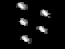


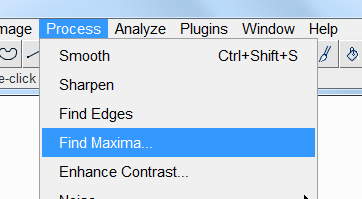
可以看到,他们都是类似的这种有局部最亮点的图像,那如何用算法实现呢,后来我在ImageJ里发现一个功能(如上图所示界面的Process菜单下的FindMaxma),基本就是这个功能的翻版:
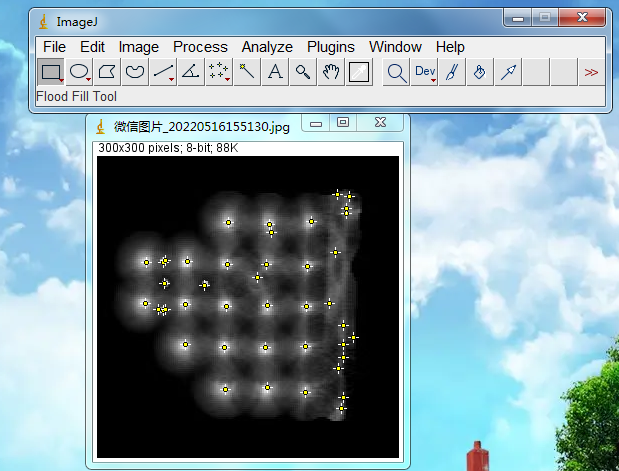
于是我就去ImageJ里找这个算法的代码,在MaximumFinder.java里找到了相关的资料,代码有1300多行,说垛也不多,不过我去描了一下,还是过于复杂了,关键是没有相关参考文章,无法理解其代码的意义,不过一个核心的意思就是利用了分水岭算法,并且ImageJ里的一些二值分割算法里也用到这个。
知道了他是用的分水岭算法,那就好办了,我同样在ImageJ的网站了找到了这个:https://imagej.nih.gov/ij/plugins/watershed.html,他提供了最原始的分水岭实现代码,对应文章为:The Watershed Transform: Definitions, Algorithms and Parallelization Strategies"。里面了用到了一些特殊的结构。在github上还可以找到一个对应的C版本的代码,不过那个里面有很多delete *p,建议删除,很影响速度。
我凭着我的聪明才智,把哪些什么Queue, List等等复杂的数据结构体都抛弃不用,即提高了代码速度,也减少了内存占用量,也基本实现了这个算法,而用在外面这里,需要先把得分的数据整形化,我测试把他划分为为1024个整形,应该就足够了。
分水岭的计算过程把图像分成一个一个的分开的块,外面有了块的标记后,选取每个块的最大值作为候选点的位置和得分值即可。
说起来简单,但是做起来难啊, 前前后后我这折腾这个过程,也用了10来天时间,结果就是对于大部分测试图,整体速度有40%的提高(因为顶层找到的候选点少了,同时找候选点的时间也少一些),对于那些本身目标就非常明确的图,区别不大,对于模板很小的图,顶层计算占据了很大耗时的图像,速度有200%的提高。
另外,单独说明一点,在我的测试中,仅仅依据最大得分选择候选点有可能会丢失一些目标,核心原因是顶层金字塔的角度量化方面可能到底局部得分偏向于某一侧,解决办法是检测通过分水岭获得的最大值周边3*3领域的点的角度和最大值处的角度的差异,如果差异明显,则周边的点最好也纳入候选点系列。
二、增加形状匹配的蒙版功能(4天搞定)
形状匹配的准确性和提取到的形状边缘算子的精确度有着很大的关系,在有些应用中,我们选择的模板可能有部分区域的边缘特征是不需要的,或者模板有部分噪音过于严重,会对检测结果有很大的影响,这时候带有蒙版功能的形状匹配就非常有必要了。
要实现这个功能,理论上来说是不复杂的,只要把哪些处于非有效区域的边缘特征点剔除掉即可。但是在实际的编码过程中,还是有几点要注意:
1、我们需要为蒙版图像也创建金字塔,那么客户提供的蒙版一般为二值图,在创建金字塔的过程中,因为是2*2插值缩放,必然会产生非二值的像素结果,处理办法是放松这个结果,只要处理的结果大于0,则赋值为白色,否则为黑色,如果不做这个处理,或用普通的127作为二值的阈值,调试发现会丢失目标。
2、即使是这样,可能还不够,在上述二值化的基础上,最好还对边缘进行一次半径为1的Dilate。
其实有了蒙版不是坏事,虽然在创建模型的时候速度会慢一些,但是后续因为特征点的减少,这个查找目标的速度反而会快一点,比如下面这个莫版图,我们最关系的其实周边的椭圆的形状,而椭圆内部有什么我们不在乎,所以增加了一个蒙版,在没有增加蒙版前共有13510 个边缘点(其实大部分边缘点都是无意义的点,设置蒙版后,只强调了有用的边缘信息,只有2828个特征点了。这也就意味着只需要匹配更少的特征数据了,速度和精确度都有所提高。




模板图 蒙版图 原始模板的特征点 带蒙版的特征点
三、蒙版可为空版本+对比度自动设置(2天)
有的时候可能还是不需要蒙版的,所以这个函数还是要考虑这个功能,即传入空指针就调用没有蒙版的函数。
另外,基于形状的匹配有个对比度和最小对比度的参数,一般客户还是希望自动化,这里取个简单的算法,直接用模板图像的OSTU二值化的那个参数作为对比度的值,最小对比度取其1/2或者1/4吧。
四、基于NCC版本的蒙版功能(废了我7天)
原来一直搞不定这个算法,主要是因为不晓得如何快速的计算中间的有些函数了,后来还是想起来那个行程编码,还是搞定了,具体的实现其实还是在上我上一篇博文之间就已经实现了,当然现在也可以借用那个博文来描述本算法的过程,详见:超越OpenCV速度的MorphologyEx函数实现(特别是对于二值图,速度是CV的4倍左右),只是那里是求最大值,这里是求累加值或者平方累加值。
用类似如下代码更改即可:
StdT = sqrtf(IM_Max((PowSumT - (float)SumT * SumT / ValidPixel) / ValidPixel, 0.000001)); // 模板的均方差,IM_Max还是主要为了防止计算精度有误差,导致小于0的情况出现 float *SumST = (float *)malloc(ValidW * ValidH * sizeof(float)); // 模板和原图相乘的卷积和 int *Sum = (int *)calloc(ValidCol * ValidW, sizeof(int)); // 保存一行像素每个有效列的累计值 int *SumP = (int *)calloc(ValidCol * ValidW, sizeof(int)); // 保存一行像素每个有效列的累计平方值 int *SumS_X = (int *)calloc(ValidW, sizeof(int)); float *PowSumS_X = (float *)calloc(ValidW, sizeof(float)); if ((SumST == NULL) || (Sum == NULL) || (SumP == NULL) || (SumS_X == NULL) || (PowSumS_X == NULL)) { Status = IM_STATUS_OUTOFMEMORY; goto FreeMemory; } // 注意这里没有使用Mask的信息,是因为Template之中Mask为0的地方像素值也为0,因此相乘还是0,所以可以不用带入Mask。 Status = IM_FastConv2(Src, Template.Bmp, SumST); // 整体计算出乘积卷积,缺点是耗用了内存,优点是能够能提高一定的速度 if (Status != IM_STATUS_OK) goto FreeMemory; int BlockSize = 8, Block = ValidW / BlockSize; for (int Y = 0; Y < ValidH; Y++) { float *LinePN = NCC + Y * ValidW; float *LineST = SumST + Y * ValidW; if (Y == 0) // 第一行第一个点,完整的进行计算 { for (int XX = 0, Index = 0; XX < TemplateW; XX++) { if (RL_V[XX].Amount != 0) { int *LinePS = Sum + Index * ValidW; int *LinePP = SumP + Index * ValidW; for (int Z = 0; Z < RL_V[XX].Amount; Z++) { unsigned char *LinePT = Src.Data + RL_V[XX].SE[Z].Start * StrideS + XX; for (int YY = RL_V[XX].SE[Z].Start; YY <= RL_V[XX].SE[Z].End; YY++) { for (int X = 0; X < Block * BlockSize; X += BlockSize) // 对速度基本没有啥影响 { __m128i SrcV = _mm_cvtepu8_epi16(_mm_loadl_epi64((__m128i *)(LinePT + X))); // 8个16位数据 __m128i PowerV = _mm_mullo_epi16(SrcV, SrcV); // 8个16位数据的平方 _mm_storeu_si128((__m128i *)(LinePS + X + 0), _mm_add_epi32(_mm_loadu_si128((__m128i *)(LinePS + X + 0)), _mm_cvtepu16_epi32(SrcV))); _mm_storeu_si128((__m128i *)(LinePS + X + 4), _mm_add_epi32(_mm_loadu_si128((__m128i *)(LinePS + X + 4)), _mm_cvtepu16_epi32(_mm_srli_si128(SrcV, 8)))); _mm_storeu_si128((__m128i *)(LinePP + X + 0), _mm_add_epi32(_mm_loadu_si128((__m128i *)(LinePP + X + 0)), _mm_cvtepu16_epi32(PowerV))); _mm_storeu_si128((__m128i *)(LinePP + X + 4), _mm_add_epi32(_mm_loadu_si128((__m128i *)(LinePP + X + 4)), _mm_cvtepu16_epi32(_mm_srli_si128(PowerV, 8)))); } for (int X = Block * BlockSize; X < ValidW; X++) { LinePS[X] += LinePT[X]; LinePP[X] += LinePT[X] * LinePT[X]; } LinePT += StrideS; } } Index++; } } }
那么目前算法研究到这一步,其实我后续一直想攻克的就是形状模型的创建速度和模型文件的大小问题,在Halcon中,我们会发现形状模型创建的速度特别快,而且模型文件也非常小。内部的机理我想无非就是他是在创建时只保存了为旋转和缩放的模板的不同金字塔层的特征,然后在匹配的时候进行特征的旋转。 而我们现在都是创建的时候旋转图像,然后再计算出个角度的特征。这个计算量就特别大了,如果同时还考虑缩放,那基本上模板图稍微大一点,就会造成速度奇慢和内存暴涨。所以我现在一直没有做即带旋转有带缩放的匹配,不是技术上实现不了,而是实现的实用性够呛。
目前,关于这个,我也一直在构思,是不是可以通过亚像素的canny来实现类似的功能呢,期待吧,也许将来补救就会有突破,相信自己。
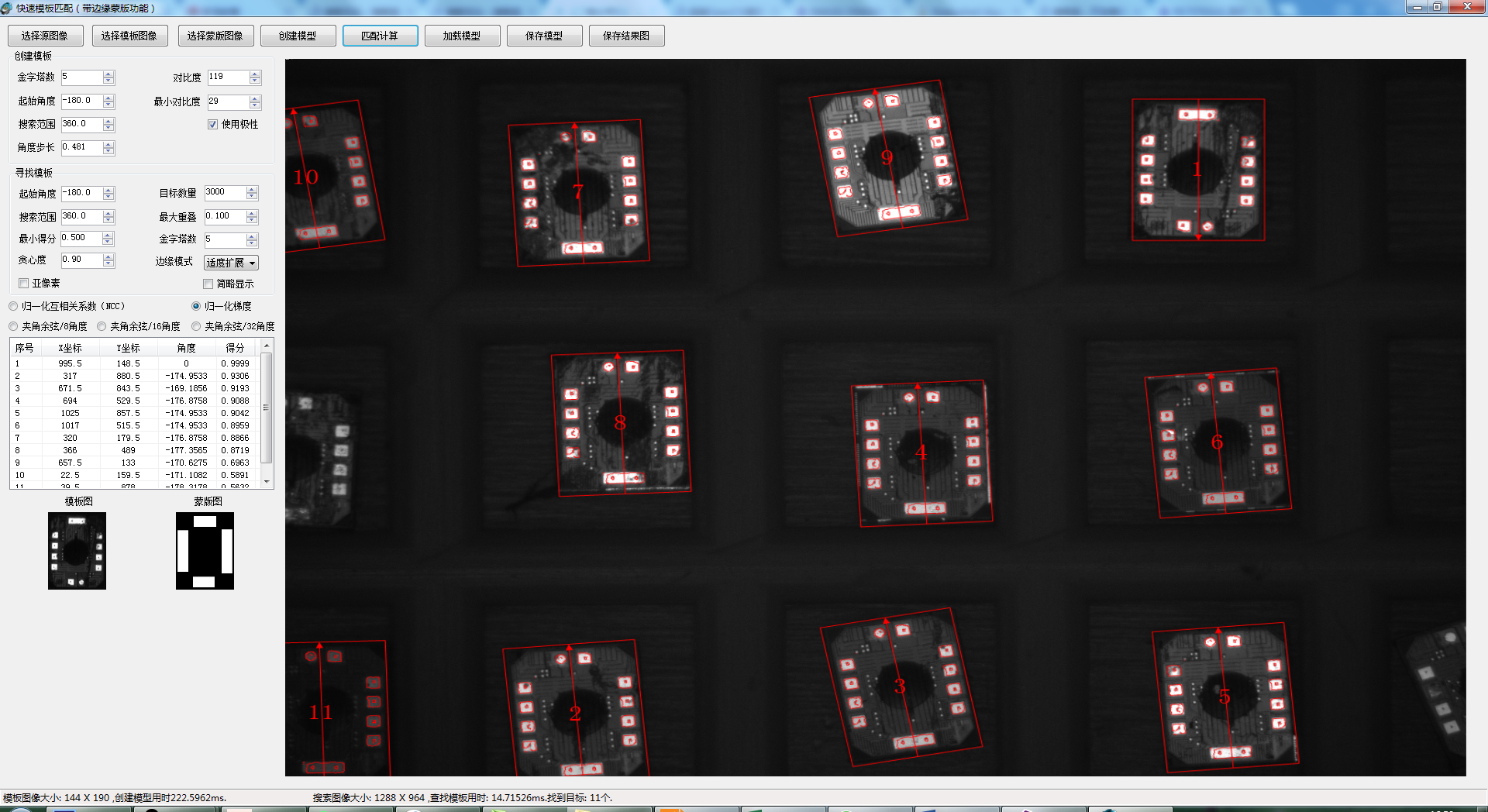
最新版的一个测试DEMO: 带蒙版的模板匹配。
如果想时刻关注本人的最新文章,也可关注公众号或者添加本人微信 laviewpbt
