Tensors贯穿PyTorch始终
和多维数组很相似,一个特点是可以硬件加速
Tensors的初始化有很多方式
-
直接给值
data = [[1,2],[3,4]] x_data = torch.tensor(data) -
从NumPy数组转来
np_arr = np.array(data) x_np = torch.from_numpy(np_array) -
从另一个Tensor
x_ones = torch.ones_like(x_data) -
赋01或随机值
shape = (2,3,) rand_tensor = torch.rand(shape) ones_tensor = torch.ones(shape) zeros_tensor = torch.zeros(shape)
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")
shape维度,dtype元素类型,device运行设备(cpu/gpu)
Tensors的操作使用GPU的方法
if torch.cuda_is_available():
tensor = tensor.to("cuda")
各种操作
-
索引和切片
tensor = torch.ones(4,4) print(tensor[0]) #第一行(0开始) print(tensor[;,0]) #第一列(0开始) print(tensor[...,-1]) #最后一列 -
连接
t1 = torch.cat([tensor,tensor],dim=1) #沿着第一维的方向拼接 -
矩阵乘法
三种办法,类似于运算符重载、成员函数和非成员函数
y1 = tensor @ tensor y2 = tensor.matmul(tensor.T) y3 = torch.rand_like(tensor) torch.matmul(tensor,tensor.T,out=y3) -
点乘
类似,也是三种办法
z1 = tensor * tensor z2 = tensor.mul(tensor) z3 = torch.rand_like(tensor) torch.mul(tensor,tensor,out=z3) -
单元素tensor求值
agg = tensor.sum() agg_item = agg.item() print(agg_item,type(agg_item)) -
In-place 操作
就是会改变成员内容的成员函数,以下划线结尾
tensor.add_(5) #每个元素都+5节约内存,但是会丢失计算前的值,不推荐使用。
-
Tensor转NumPy数组
t = torch.ones(5) n = t.numpy()注意,这个写法类似引用,没有新建内存,二者修改同步
-
NumPy数组转tensor
n = np.ones(5) t = torch.from_numpy(n)同样是引用,一个的修改会对另一个有影响
处理数据的代码通常很杂乱,难以维护,我们希望这部分代码和主代码分离。
加载数据集以FasnionMNIST为例,我们需要四个参数
-
root是路径
-
Train区分训练集还是测试集
-
download表示如果root找不到,就从网上下载
-
transform表明数据的转换方式
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FansionMNIST(
root = "data",
train = True,
download = True,
transform = ToTensor()
)
test_data = datasets.FansionMNIST(
root = "data",
train = False,
download = True,
transform = ToTensor()
)
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
必须实现三个函数__init__,__len__,__getitem__
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
__init__类似于构造函数
__len__求数据个数
__getitem__按下标找数据和标签,类似重载[]
DataLoaders主要做3件事,将数据划分为小batches,随机打乱数据,和多核处理。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data,batch_size = 64,shuffle=True)
test_dataloader = DataLoader(test_data,batch_size = 64,shuffle=True)
# 展示图像和标签
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
让数据变形成需要的形式
transform指定feature的变形
target_transform指定标签的变形
比如,需要数据从PIL Image变成Tensors,标签从整数变成one-hot encoded tensors
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
这里用了两个技术,ToTensor()和Lambda表达式
ToTensor()将PIL images或者NumPy数组转化成FloatTensor,每个像素的灰度转化到[0,1]范围内
Lambda类似C++里的Lambda表达式,我们需要将整数转化为 one-hot encoded tensor,就先创建一个长度为数据标签类型的全0的Tensor,然后用scatter_()把第y个值改为1。注意到,scatter的index接受的参数也是Tensor,可见Tensor的广泛使用。
神经网络是一些层或者模块,对数据进行处理。
torch.nn提供了诸多构造神经网络的模块,模块化的结构方便了管理复杂结构。
接下来以在FashionMNIST上构造一个图像分类器为例。
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
有GPU用GPU,没有用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
我们的网络从nn.Module继承来
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
然后创建一个实例(对象),把它放到device上
model = NeuralNetwork().to(device)
print(model)
跑一下的结果
Using cpu device
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
结果是返回值的softmax,这是个10维的概率,找最大的就是预测结果
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
以3张28x28的图像为例,分析它在network里的状态
input_image = torch.rand(3,28,28)
print(input_image.size())
'''
torch.Size([3,28,28])
'''
Flatten顾名思义,扁平化,用于将2维tensor转为1维的
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flag_image.size())
'''
torch.Size([3,784])
'''
Linear,做线性变换的
layer1 = nn.Linear(in_features=28*28,out_features=20)
hidden1 = layer1(flag_image)
print(hidden1.size())
'''
torch.Size([3,20])
'''
非线性激活函数,在Linear层后,增加非线性,让神经网络学到更多的信息
hidden1 = nn.ReLU()(hidden1)
Sequential,序列的,类似于把layers一层一层摆着
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3,28,28)
logits = seq_modules(input_image)
最后一层的结果返回一个在[-inf,inf]的值logits,通过softmax层后,映射到[0,1]
这样[0,1]的值可以作为概率输出,dim指定和为1的维度
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
这些layers是参数化的,就是说在训练中weights和biases不断被优化
以下的代码输出这个模型里的所有参数值
for name, param in model.named_parameters():
print(name,param.size(),param[:2])
训练神经网络的时候,最常用的是反向传播,模型参数根据loss functoin的梯度进行调整。
为了求梯度,也就是求导,我们使用torch.autograd。
考虑就一个layer的网络,输入x,参数w和b,以及一个loss function,也就是
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
考虑这个过程的Computational Graph,如下
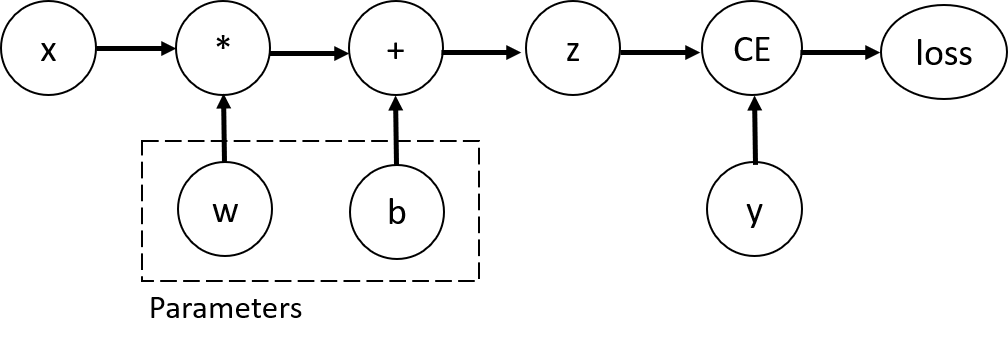
这个一定是DAG(有向无环图)
为了计算loss在w和b方向上的梯度,我们给他们设置requires_grad
w.requires_grad_(True)
b.requires_grad_(True)
Functions实际上是对象,有计算正向值和反向导数的成员。
print(z.grad_fn)
print(loss.grad_fn)
我们要计算Loss对w和b的偏导,只需要使用
loss.backward()
然后就得到了
print(w.grad)
print(b.grad)
注意:
- 我们只能计算图里叶子的梯度,内部的点不能算
- 一张图只能计算一次梯度,要保留节点的话,backward要传
retain_graph=True
import torch
x = torch.randn((1,4),dtype=torch.float32,requires_grad=True)
y = x ** 2
z = y * 4
print(x)
print(y)
print(z)
loss1 = z.mean()
loss2 = z.sum()
print(loss1,loss2)
loss1.backward() # 这个代码执行正常,但是执行完中间变量都free了,所以下一个出现了问题
print(loss1,loss2)
loss2.backward() # 这时会引发错误
所以要把loss1的那行改成
loss1.backward(retain_graph=True)
有些时候我们不需要计算梯度,比如模型已经训好了,只需要正向用
这个时候算梯度就很拖累时间,所以要禁用梯度
z = torch.matmul(x, w)+b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
'''
True
False
'''
另一个办法是用.detach()
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
'''
False
'''
如果函数的输出是tensor,就不能简单算梯度了
结果是一个矩阵(其实就是依次遍历x和y的分量,求偏导)
\[J=\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right) \]PyTorch不计算J的原始值,而是给一个\(v\),计算\(v^T\cdot J\),输出接口是统一的
具体来说,把v当参数传进去
inp = torch.eye(5, requires_grad=True)
out = (inp+1).pow(2)
out.backward(torch.ones_like(inp), retain_graph=True)
有了模型,接下来要进行训练、验证和测试。
前置代码首先要加载数据,建立模型
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
定义三个超参数
- Epochs数:数据集迭代次数
- Batch size:单次训练样本数
- Learning Rate:学习速度
接下来,我们进行多轮的优化,每轮叫一个epoch
每个epoch包含两部分,训练loop和验证/测试loop
Loss FunctionPyTorch提供常见的Loss Functions
- nn.MSELoss (Mean Square Error)
- nn.NLLLoss (Negative Log Likelihood)
- nn.CrossEntropyLoss (交叉熵)
我们使用交叉熵,把原始结果logits放进去
loss_fn = nn.CrossEntropyLoss()
初始化优化器,给它需要优化的参数,和超参数Learning Rate
optimizer = torch.optim.SGC(model.parameters(),lr = learning_rate)
优化器在每个epoch里做三件事
optimizer.zero_grad()将梯度清零loss.backward()进行反向传播optimizer.step()根据梯度调整参数
在train_loop里训练,test_loop里测试
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
learning_rate = 1e-3
batch_size = 64
epochs = 5
# Initialize the loss function
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
如何保存和加载训好的模型?
import torch
import torchvision.models as models
通过torch.save方法,可以将模型保存到state_dict类型的字典里。
model = models.vgg16(pretrained=True)
torch.save(model.state_dict(), 'model_weights.pth')
而要加载的话,需要先构造相同类型的模型,然后把参数加载进去
model = models.vgg16() # we do not specify pretrained=True, i.e. do not load default weights
model.load_state_dict(torch.load('model_weights.pth'))
model.eval()
注意,一定要调一下model.eval(),防止后续出错
上一种方法里,需要先实例化模型,再导入权值
有没有办法直接保存和加载整个模型呢?
我们用不传mode.state_dict()参数,改为model
保存方式:
torch.save(model,'model.pth')
加载方式:
model = torch.load('model.pth')