人工标注数据集中普遍存在噪声,ReLabel能够自动且低成本地将原本的单标签数据集转化为多标签数据集,并且提出配合random crop使用的高效LabelPooling方法,能够更准确地指导分类网络的训练
来源:晓飞的算法工程笔记 公众号
论文: Re-labeling ImageNet:from Single to Multi-Labels, from Global to Localized Labels

- 论文地址:https://arxiv.org/abs/2101.05022
- 论文代码:https://github.com/naver-ai/relabel_imagenet
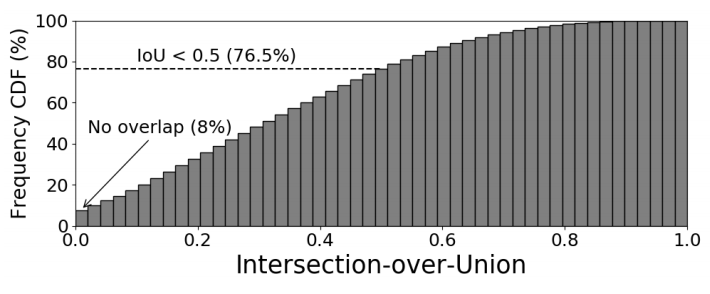
ImageNet数据集是图像识别领域很重要的数据集,数据集本身假设图片中只有一个目标,但是目前发现其中包含了很多噪声数据,很多图片实际上可能存在多个类别目标,这种情况就会误导网络的学习。此外,论文发现常用的Random crop数据增强方法会加剧这一现象,对验证集的每张图片进行100次Random crop,统计裁剪图片与原目标之间的IoU,结果如上面的图所示,IoU低于0.5的占比为76.5%,IoU为0的占比甚至高达8%,这显然会给训练带来极大的干扰。
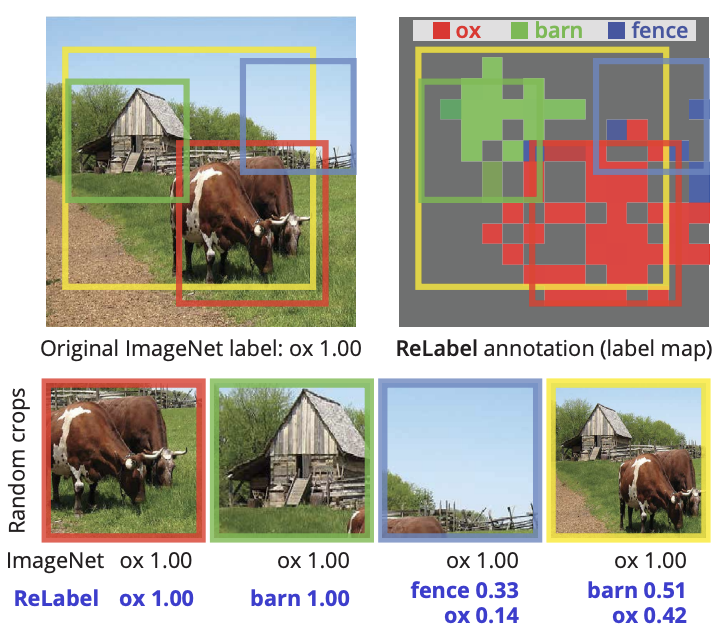
为了解决这一问题,论文提出ReLabel,通过一个标注网络(machine annotator)取得图片的pixel-wise多标签标注\(L\in \mathbb{R}^{H\times W\times C}\),该标注包含标签信息和位置信息,然后按该多标签标注信息将原本的单标签标注转化为多标签标注。论文也提出LabelPooling来配合Random crop使用,根据crop的区域与pixel-wise标注输出对应的多标签信息。区别于知识蒸馏,每张图片每次都需要forward计算,ReLabel方法仅需要每张图片进行一次forward计算,后续都是简单的比例计算,计算量较小。
Re-labeling ImageNet由于人工标注的成本很高,论文采用了一个标注网络(machine annotator)获取pixel-wise标注,网络结构可以为任意sota网络,考虑到训练的耗时,取该网络在Super-ImageNet数据集上预训练模型,然后在ImageNet上进行fine-tuned。根据交叉熵损失函数的特性,虽然该标注网络是在单标签数据集上训练得到的,但由于数据集存在噪声,这使得网络潜在有多标签预测的能力。
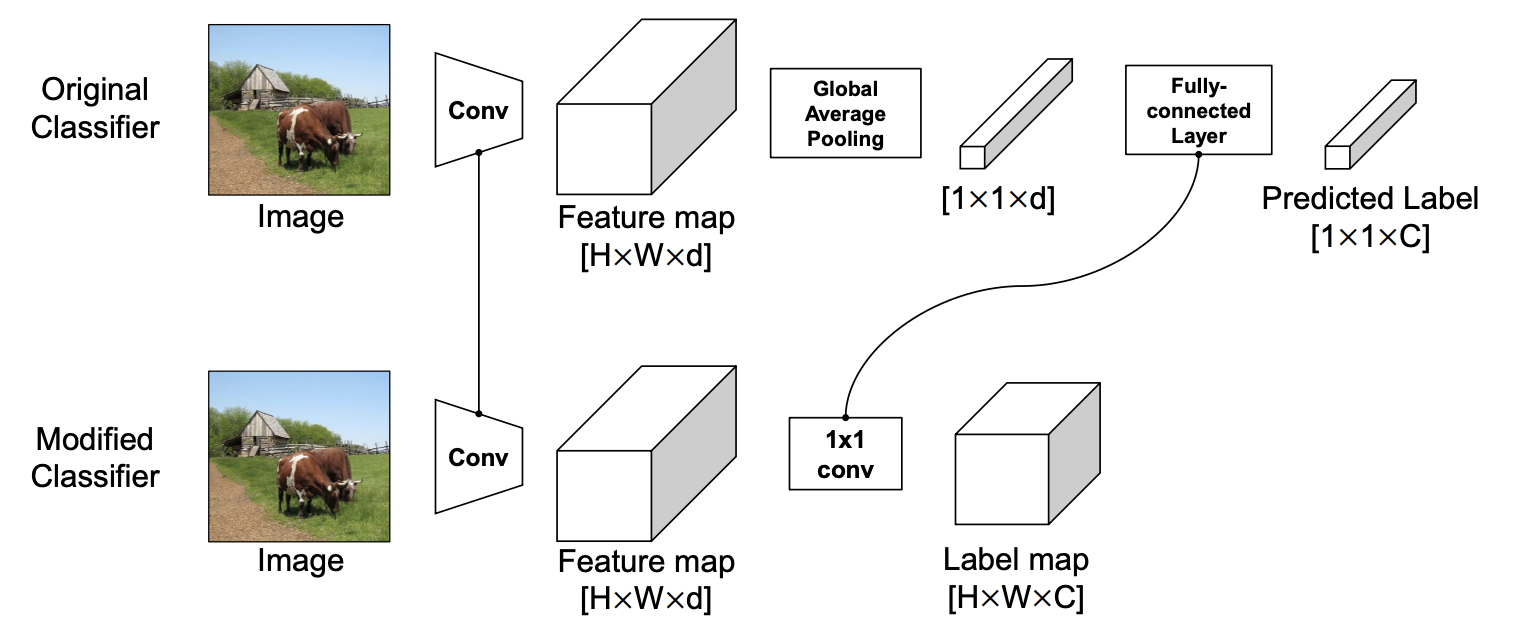
由于我们希望获取pixel-wise多标签标注,将原网络的全局池化层去掉,并将后续的全连接层替换为\(1\times 1\)卷积层,修改后的网络\(f(x)\)的输出变为\(L\in \mathbb{R}^{W\times H\times C}\),这便是我们需要的pixel-wise标注信息。
Training a Classifier with Dense Multi-labels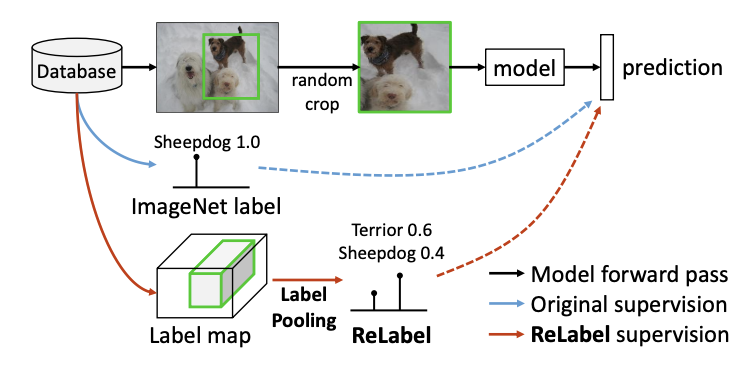
在获得多标签信息\(L\)后,训练时通过Label Pooling获取训练目标,如上图所示,与常规方法的主要区别如下:
- 常规的训练步骤不管random crop的结果,均赋予原图的单标签。
- Label Pooling先获取图片对应的pixel-wise多标签信息,然后使用RoIAlign对random crop对应的区域进行特征提取,最后使用全局池化和softmax操作进行分类,得到多标签向量\([0,1]^C\)。

使用ReLabel的训练流程可参考上面的伪代码,由于pixel-wise多标签标注是预先计算好的,所以采用ReLabel带来额外计算非常小。
DiscussionSpace consumption
当使用EfficientNet-L2作为标注网络时,输入分辨率为\(475\times 475\),输出的pixel-wise标注信息大小\(L\in \mathbb{R}^{15\times 15\times 100}\),保存所有图片的完整标注信息大约需要1TB的存储。对于每一张图片,除了top-k类别外,其它类别的pixel-wise标注信息几乎都为0,所以可以只需要保存每张图片的top-5 pixel-wise标注信息,大约为10GB,相当于ImageNet数据集大小的10%。
Time consumptionReLabel需要将ImageNet中每张图片进行一次前向计算,大约耗费10 GPU/时,相当于ResNet-50完整训练时间的3.3%。在每个迭代,LabelPooling大约增加每次迭代的0.5%的额外耗时,而知识蒸馏每轮迭代都要teacher网络进行一次完整的前向计算,耗时相当大。
Which machine annotator should we select?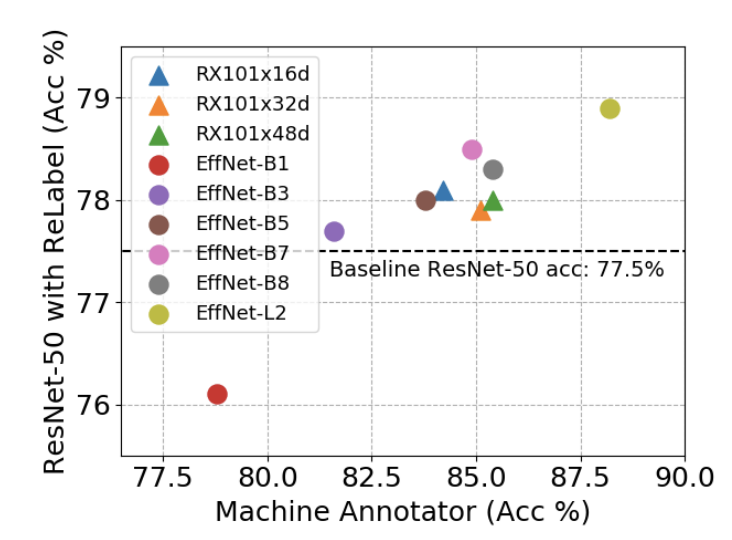
不同标注网络对ReLabel的效果影响很大,论文对比了多种网络结构,结果如上图所示,最终论文选择了EfficientNet-L2作为标注网络。
Factor analysis of ReLabel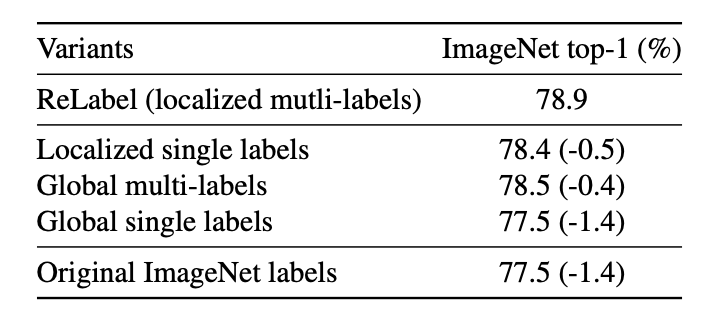
ReLabel是多标签和pixel-wise的,为了对比这两个特性的必要性,增加了以下三种实现的对比:
- Localized single labels:跟ReLabel的步骤一样,最后取softmax分数最大的标签,而非多标签。
- Global multi-labels:不使用RoIAlign,直接将完整的标注信息进行全局池化,最后取多标签。
- Global single labels:不使用RoIAlign,直接将完整的标注信息进行全局池化,最后softmax分数最大的标签。
结果如上图所示,论文提出的ReLabel实现方式效果最好。
Confidence of ReLabel supervision
论文也对ReLabel在不同IoU情况下的监督能力进行了探讨,记录5百万张random crop的图片与GT的IoU以及ReLabel输出的最大标签分数,结果如上图所示,标签分数与IoU正相关。当IoU非常小时,标签分数也非常小,这就相当于给网络训练提供了一个训练目标不确定的信号。
Experiments
多标签pixel-wise标注信息的可视化。

与其它标签监督方法对比。
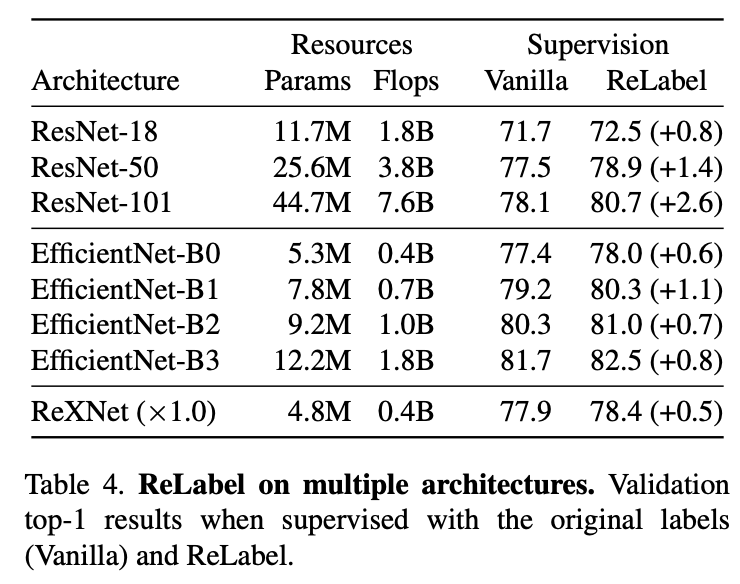
对不同网络结构的性能提升。

搭配其它训练技巧的效果。
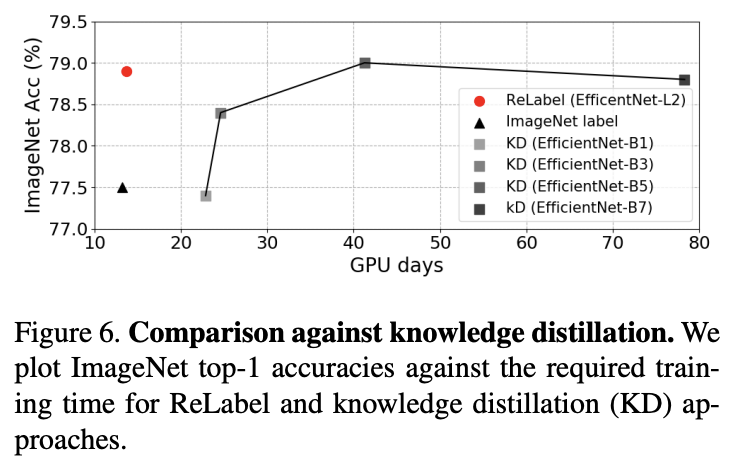
与知识蒸馏的耗时对比。
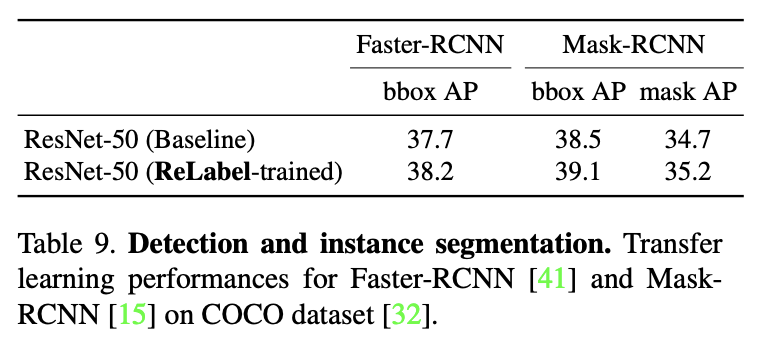
作为目标检测主干网络的表现。
Conclusion人工标注数据集中普遍存在噪声,ReLabel能够自动且低成本地将原本的单标签数据集转化为多标签数据集,并且提出配合random crop使用的高效LabelPooling方法,能够更准确地指导分类网络的训练。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
