执行步骤:
- 从服务器发送
snyc给主服务器 - 主服务器收到命令后,开始执行
bgsave操作,将生成RDB文件,将生成的RDB文件同步给从服务。并使用一个缓冲区记录从现在开始的写命令 - 从服务载入接受到的RDB文件,期间不可进行其他操作。
- 主服务将缓冲区里的命令同步给从服务器
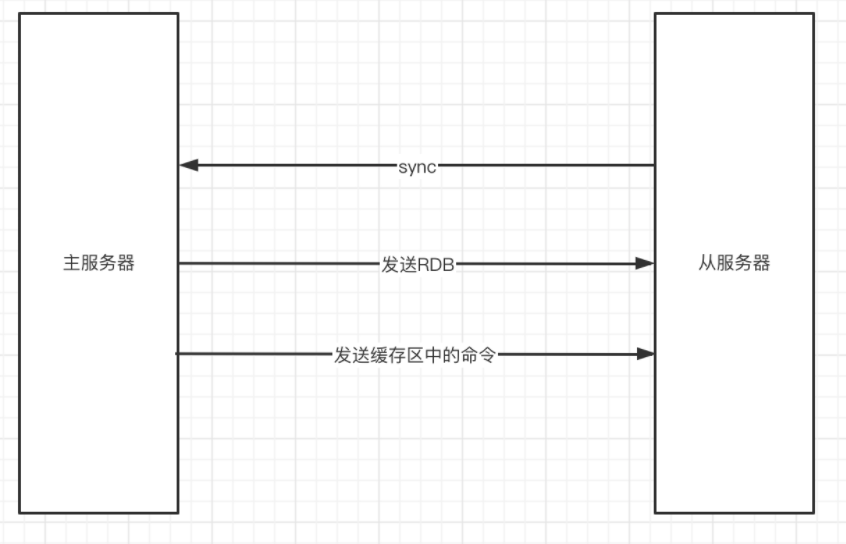
同步完成之后,后续的命令都是通过传播的方式发送给从服务器的。即当主服务执行完一条命令后,将该命令发送给从服务,完成数据的同步。
缺陷场景:
- 首次复制,不存在问题,毕竟新连接上一个master服务器,则需要复制其全量的数据
- 断开后重连复制,这是,仍是需要通过
sync进行全量的复制,这就是很耗费资源的。毕竟如果断开时间短,如中间网络抖动,导致中间短暂性断开,再次复制全量数据,成本太高。
关于sync命令:
- 主服务器需要执行
bgsave命令来生成RDB文件,这个操作会耗费主服务器的大量CPU、内存和磁盘IO资源。 - 主服务器将RDB文件发送给从服务器,会消耗双方的网络资源(带宽和流量)。
- 接受到RDB文件后,从服务器需要载入RDB文件,这个载入期间,从服务器因为阻塞而没有办法处理命令请求。
psnyc具备完整重同步(full resynchronization)和部分重同步(partial resynchronization)。
其中,完整重同步和sync的首次同步是一致的,通过主服务器生成RDB文件进行全量数据的同步,如果存在多个从服务器,主服务器仅会生成一份RDB文件,分别同步给各个从服务器。部分重同步则解决了sync断开重连的问题,当断开重连后,主服务器在条件允许的前提下,仅会发送断开期间的写命令。部分重同步的主要实现由以下三部分组成:
- 主服务器的复制偏移量(replication offset)和从服务器的复制偏移量
- 主服务器的复制积压缓冲区(replication backlogs)
- 服务器的运行ID(run ID)
主服务器记录的是自己发给从服务器的偏移量,从服务器记录的是自己接受到的数据偏移量。比如:当前主从服务器的偏移量均为100,在有新的写入命令后,主服务器的偏移量变成了110,而从服务器的是100,此时会有短暂的不一致,待主服务器将新写入命令同步给从服务器后,从服务器的偏移量会变更为110,此时主从服务器又是保持一致的数据了。
复制积压缓冲区一个固定长度的先进先出队列,默认1M,可通过配置repl_backlog_size调整其大小。当收到一条写入命令,除了发给从服务器外,还会将命令写入到复制积压缓冲区一份。
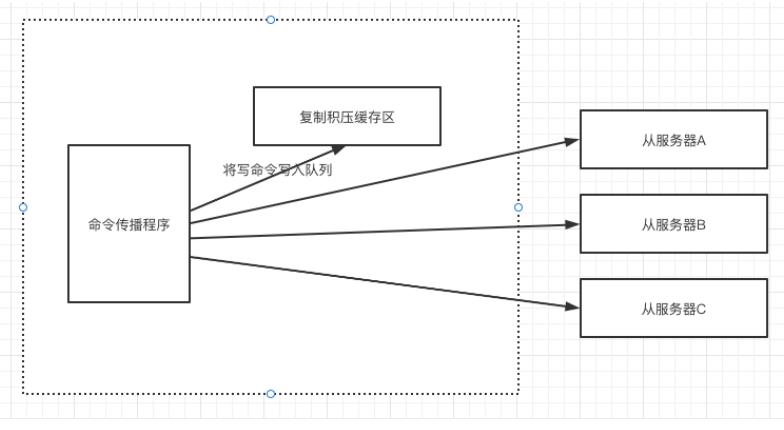
当从服务器A与主服务器断开后,中间的写入命令会无法同步给从服务器A,之后,重连后,从服务器会将其复制偏移量告知主服务器,如果该偏移量还在复制积压缓冲区中,则直接将复制积压缓冲区该偏移量后的命令发送给从服务器。
服务器的运行ID每个redis实例在启动时候,都会随机生成一个长度为40的唯一字符串来标识当前运行的redis节点。当从服务器对主服务器进行首次复制时,则将自己的runID发送给从服务器,从服务器会将这个ID保存起来。当从服务器与主服务器断开后重连时,会向主服务器发送当前存储的runID,主服务器收到后,会判断与当前自己的runID是否一致,如果不一致,则进行全量复制;如果一致,则判断复制偏移量是否还在复制积压缓冲区中,如果还在,则进行部分重同步。
psync命令psync <runId> <offset>
首次发送时为psync ? -1,之后发送的为上次master的runID和当前的复制偏移量。
由于每次实例重启都会重新生成runID,或者发生故障迁移后,新Master的runId必然与上一次的不一致,仍会导致完整重同步。
4.0版本以后的优化解决了psnyc的缺陷,简称:psync2
第一种情况:redis重启第一步,在redis关闭时,通过shutdown save,都会调用rdbSaveInfoAuxFields函数,把当前实例的repl-id和repl-offset保存到RDB文件中。
第二步,重启后加载RDB文件中的复制信息。把其中repl_id和repl_offset加载到实例中,分别赋给master_replid和master_repl_offset两个变量值。
当从库开启了AOF持久化,redis加载顺序发生变化优先加载AOF文件,但是由于aof文件中没有复制信息,所以导致重启后从实例依旧使用全量复制!
第三步:向主库上报复制信息,判断是否进行部分同步。
- 从实例向主库上报master_replid与主实例的master_replid1或replid2有一个相等,用于判断主从未发生改变;
- 从实例上报的master_repl_offset+1字节,还存在于主实例的复制积压缓冲区中,用于判断从库丢失部分是否在复制缓冲区中;
redis从库默认开始复制积压缓冲区,方便从库切换为主库,其他从库可以直接从master节点获取缺失的命令。通过两组replId实现。
第一组:master_replid和master_repl_offset:如果redis是主实例,则表示为自己的replid和复制偏移量; 如果redis是从实例,则表示为自己主实例的replid1和同步主实例的复制偏移量。
第二组:master_replid2和second_repl_offset:无论主从,都表示自己上次主实例repid1和复制偏移量;用于兄弟实例或级联复制,主库故障切换psync。
判断是否使用部分复制条件:如果从库提供的master_replid与master的replid不同,且与master的replid2不同,或同步速度快于master; 就必须进行全量复制,否则执行部分复制。
公众号:慢行的蜗牛