胡启明,腾讯云专家工程师,专注 Kubernetes、降本增效等云原生领域,Crane 核心开发工程师,现负责成本优化开源项目 Crane 开源治理和弹性能力落地工作。
余宇飞,腾讯云专家工程师,专注云原生可观测性、成本优化等领域,Crane 核心开发者,现负责 Crane 资源预测、推荐落地、运营平台建设等相关工作。
田奇,腾讯高级工程师,专注分布式资源管理和调度,弹性,混部,Kubernetes Contributor,现负责 Crane 相关研发工作。
引言业务的稳定性和成本之间的矛盾由来已久。在云原生时代,按需付费的成本模型催生出了自动弹性伸缩技术——通过动态申请、归还云上资源,在满足业务需求的前提下,降低成本。
什么是 HPA谈到云原生中的弹性,大家自然想到 Kubernetes 的各种自动伸缩(Auto Scaling)技术,其中最具代表性的当属水平 Pod 自动伸缩(HPA)。
HPA 作为 Kubernetes 的内建功能,具有一系列优点:
- 兼顾业务高峰稳定、低谷降本的诉求。
- 功能稳定,社区中立:随着 kubernetes 版本的迭代,其本身的功能也在不断地丰富和完善,但 HPA 的核心机制一直保持稳定,这也说明它可以满足最通用的弹性伸缩场景。
- 顺应 Serverless 趋势:随着各个大厂发布 Serverless 容器产品,以及虚拟节点池技术的提出,HPA 很大程度上覆盖了集群自动伸缩(CA) 的功能,使得自动伸缩更轻量、更敏捷。
- 完善的扩展机制:提供诸如 custom_metrics、external_metric 等扩展指标,用户可以根据实际情况配置最适合业务的 HPA。
HPA 也并不完美:
-
如何配置:HPA 运行的效果取决于用户资源的配置(target、minReplicas、maxReplicas 等等)。配置过于激进可能导致应用可用性、稳定性受影响,配置过于保守弹性的效果就大打折扣。如何合理的配置是用好 HPA 的关键。
-
弹性不够及时:原生 HPA 是对监控数据的被动响应,此外应用本身启动、预热也需要一定时间,这使得HPA天生具有滞后性,进而可能影响业务稳定。这也是很多用户不信任、不敢用HPA的一个重要原因。
-
可观测性低:HPA 没法通过类似 Dryrun 方式测试,一旦使用便会实际修改应用的实例数量,存在风险;而且弹性过程也难以观测。
HPA 通常被应用于负载具有潮汐性的业务, 如果从流量或者资源消耗等指标的时间维度来看,会发现很明显的波峰、波谷形态。进一步观察,这类具有波动性的业务往往天然地在时间序列上也有着明显周期性,尤其是那些直接或间接服务于“人”的业务。
这种周期性是由人们的作息规律决定的,例如,人们习惯中午、晚上叫外卖;早晚会有出行高峰;即时是搜索这种业务时段不明显的服务,夜里的请求量也会大大低于白天。对于此类业务,一个很自然的想法,就是通过过去几天的数据预测出今天的数据。有了预测的数据(例如:未来24小时的业务 CPU 的使用情况),我们就可以对弹性伸缩做出某种“超前部署”,这也是 Effective HPA 能够克服原生 HPA 实时性不足的关键所在。
Effective HPA 是什么Effective HPA(简称 EHPA)是开源项目 Crane 中的弹性伸缩产品,它基于社区 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,监控,周期),让弹性更加高效,并保障了服务的质量:
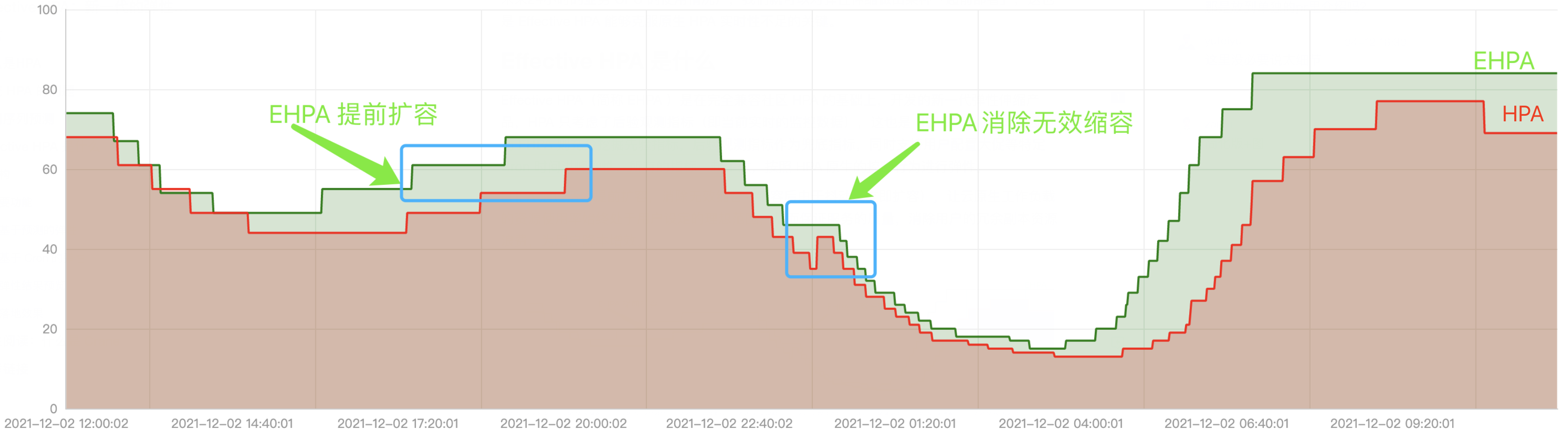
- 提前扩容,保证服务质量:通过算法预测未来的流量洪峰提前扩容,避免扩容不及时导致的雪崩和服务稳定性故障。
- 减少无效缩容:通过预测未来可减少不必要的缩容,稳定工作负载的资源使用率,消除突刺误判。
- 支持 Cron 配置:支持 Cron-based 弹性配置,应对大促等异常流量洪峰。
- 兼容社区:使用社区 HPA 作为弹性控制的执行层,能力完全兼容社区。
EHPA 的主要架构如下:

- EHPA Controller: 负责 EHPA 对象的控制逻辑,包括 EHPA 的增删改查和 HPA 的同步
- Metric Adapter:负责预测指标以及其他相关指标的生成
- Predictor:负责主要用于时序数据分析和预测
- TimeSeriesPrediction:时序数据预测 CRD,主要供 EHPA 和 MetricAdapter 进行消费
- HPA Controller: 社区原生 HPA 控制器,EHPA 对此完全兼容,允许用户有已经配置的 HPA
- KubeApiServer:社区原生 Kubernetes ApiServer
- Metric Server:社区原生 Metric Server
EHPA 充分挖掘 Workload 的相关指标,对于资源消耗和流量有明显周期性的 Workload,预测其在未来一段时间窗口的时序指标,利用该预测窗口数据,HPA 获取到的指标会带有一定的前瞻性,当前 EHPA 会取未来窗口期内指标的最大值,作为当前 HPA 的观测指标。
这样当未来流量上升超过 HPA 容忍度的时候,HPA 就可以在当下完成提前扩容,而当未来短时间内有流量降低,但是其实是短时抖动,此时由于 EHPA 取最大值,所以并不会立即缩容,从而避免无效缩容。
用户可以通过配置以下指标:
apiVersion: autoscaling.crane.io/v1alpha1
kind: EffectiveHorizontalPodAutoscaler
spec:
# Metrics 定义了弹性阈值,希望 workload 的资源使用保持在一个水平线上
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
# Prediction 定义了预测配置
# 如果不设置,则不开启弹性预测
prediction:
predictionWindowSeconds: 3600 # PredictionWindowSeconds 定义了预测未来多久的时间窗口。
predictionAlgorithm:
algorithmType: dsp
dsp:
sampleInterval: "60s"
historyLength: "3d"
- MetricSpec: 配置和 HPA 是一致的,保持用户一致的体验
- Prediction: 主要用来设置预测先关参数,包括预测窗口和算法类型,未来对于窗口时序指标的处理策略,用户可以自行定制。
- PredictionWindowSeconds: 预测未来时间窗口长度
- Dsp: 该算法是基于FFT(快速傅里叶变换)的时序分析算法,针对周期性强的时序有不错的预测效果,而且无需进行模型训练,简单高效
除了基于监控指标,有时候节假日弹性和工作日会有差异,简单的预测算法可能无法比较好的工作。那么此时可以通过设置周末的 Cron 将其副本数设置更大一些,从而弥补预测的不足。
针对某些非 Web 流量型应用,比如有些应用会在周末的时候无需工作,此时希望工作副本缩容为1,也可以配置 Cron 进行缩容,降低用户成本。
定时 Cron 弹性 Spec 设置如下:
apiVersion: autoscaling.crane.io/v1alpha1
kind: EffectiveHorizontalPodAutoscaler
spec:
crons:
- name: "cron1"
description: "scale up"
start: "0 6 ? * *"
end: "0 9 ? * *"
targetReplicas: 100
- name: "cron2"
description: "scale down"
start: "00 9 ? * *"
end: "00 11 ? * *"
targetReplicas: 1
- CronSpec: 可以设置多个 Cron 弹性配置,Cron 周期可以设置周期的开始时间和结束时间,在该时间范围内可以持续保证 Workload 的副本数为设定的目标值。
- Name:Cron 标识符
- TargetReplicas:本 Cron 时间范围内 Workload 的目标副本数
- Start:表示 Cron 的开始时间,时间格式是标准的 linux crontab 格式
- End: 表示 Cron 的结束时间,时间格式是标准的 linux crontab 格式
目前一些厂商和社区的弹性 Cron 能力存在一些不足之处:
- Cron 能力是单独提供的,弹性没有全局观,和 HPA 的兼容性差,会产生冲突
- Cron 的语义和行为不是很匹配,甚至使用起来非常难以理解,容易造成用户故障
下图是当前 EHPA 的 Cron 弹性实现和其他 Cron 能力对比:
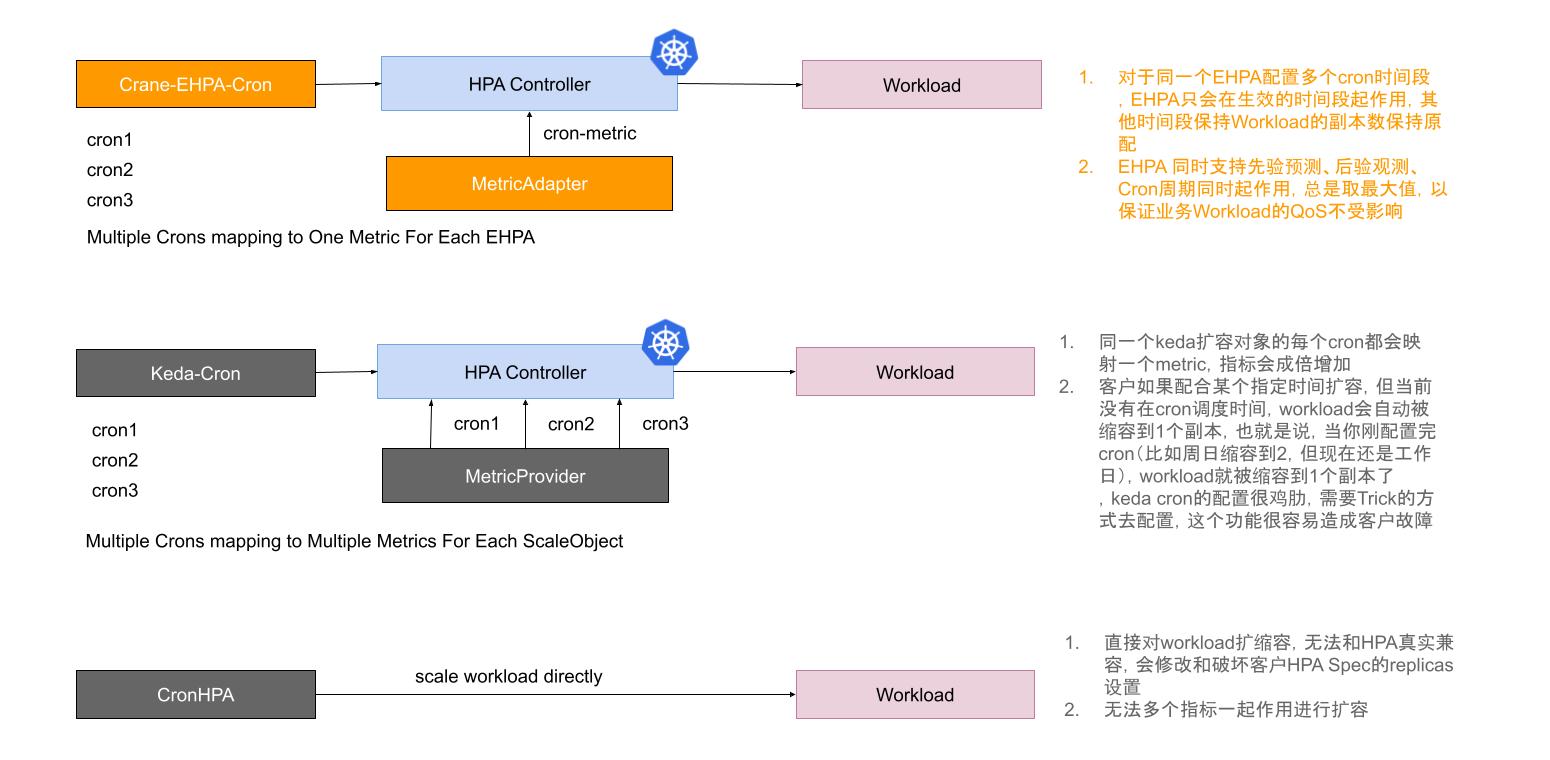
针对上述问题,EHPA 实现的 Cron 弹性,是在兼容 HPA 基础上来设计的,Cron 作为 HPA 的指标,是和其他指标一样共同作用于 Workload 对象的。另外,Cron 的设置也很简单,单独配置 Cron 的时候,不在激活时间范围是不会对 Workload 进行默认伸缩的。
弹性结果预览EHPA 支持预览(Dry-run)水平弹性的结果。在预览模式下 EHPA 不会实际修改目标工作负载的副本数,所以你可以通过预览EHPA弹性的效果来决定是否需要真的开始自动弹性。另外一种场景是当你希望临时关闭自动弹性时,也可以通过调整到预览模式来实现。
- ScaleStrategy: Preview 为预览模式,Auto 为自动弹性模式
- SpecificReplicas: 在预览模式时,可以通过设置 SpecificReplicas 指定工作负载的副本数
apiVersion: autoscaling.crane.io/v1alpha1
kind: EffectiveHorizontalPodAutoscaler
spec:
scaleStrategy: Preview # ScaleStrategy 弹性策略,支持 "Auto" 和 "Preview"。
specificReplicas: 5 # SpecificReplicas 在 "Preview" 模式下,支持指定 workload 的副本数。
status:
expectReplicas: 4 # expectReplicas 展示了 EHPA 计算后得到的最终推荐副本数,如果指定了 spec.specificReplicas,则等于 spec.specificReplicas.
currentReplicas: 4 # currentReplicas 展示了 workload 实际的副本数。
实现原理:当 EHPA 处于预览模式时,Ehpa-controller 会将底层的 HPA 对象指向一个 Substitute(替身) 对象,底层计算和执行弹性的 HPA 只会作用于替身,而实际的工作负载则不会被改变。
落地效果目前 EHPA 已经在腾讯内部开始使用,支撑线上业务的弹性需求。这里展示一个线上应用使用 EHPA 后的落地效果。
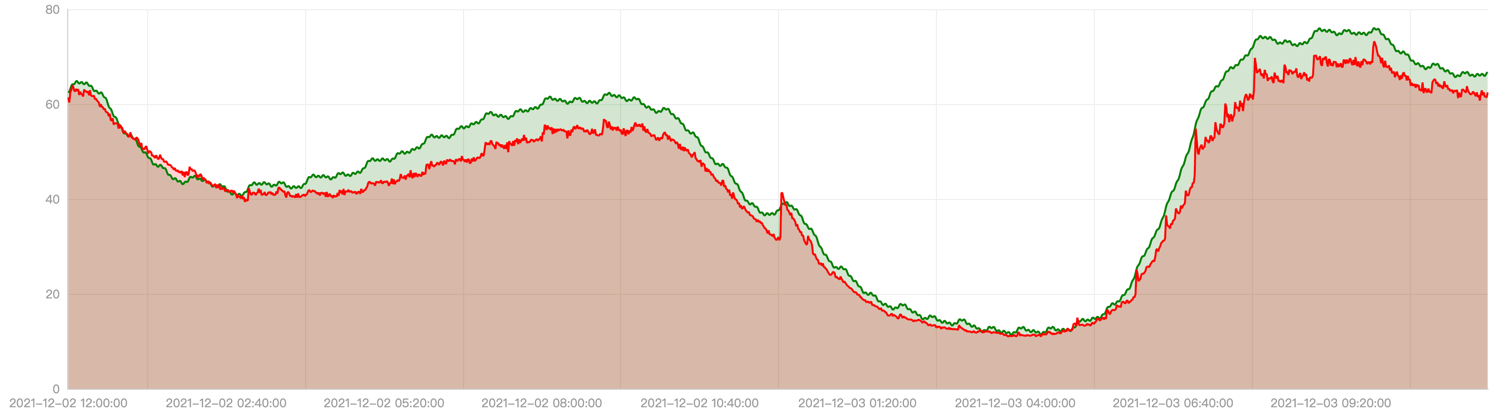
上图显示了该应用一天内的 CPU 使用。红色曲线是实际使用量,绿色曲线是算法预测出的使用量,可以看到算法可以很好的预测出使用量的趋势,并且根据参数实现一定的偏好(比如偏高)。
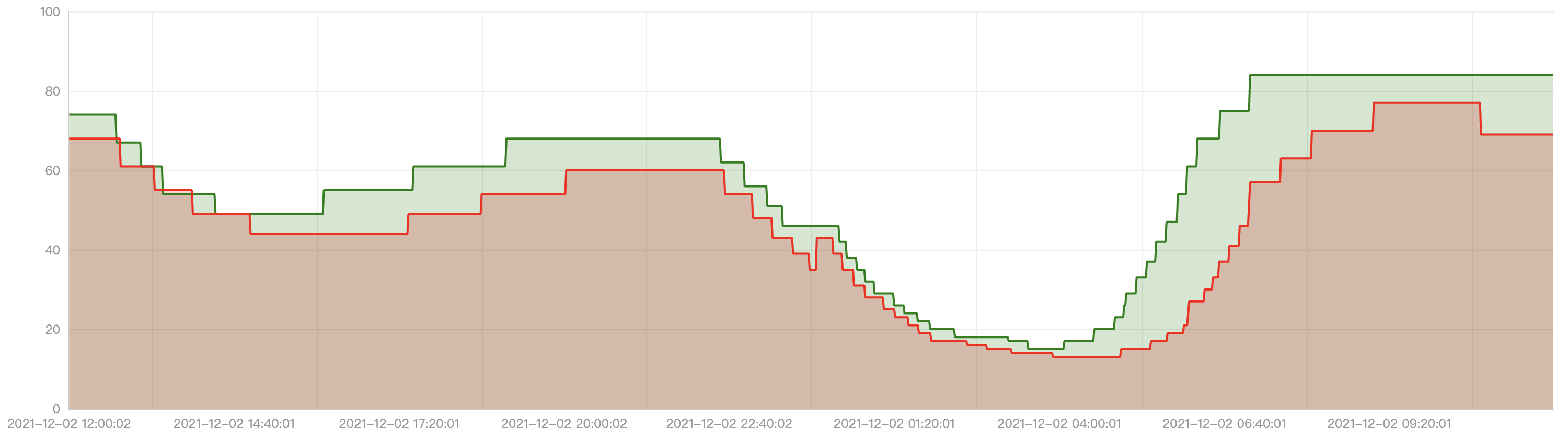
上图显示了该应用使用弹性后在一天内副本数的变化趋势。红色曲线是通过原生的 HPA 自动调整的副本数,而绿色曲线是通过 EHPA 自动调整的副本数,可以看到 EHPA 的弹性策略更加合理:提前弹和减少无效弹性。
衍生阅读:什么是 Crane为推进云原生用户在确保业务稳定性的基础上做到真正的极致降本,腾讯推出了业界第一个基于云原生技术的成本优化开源项目 Crane( Cloud Resource Analytics and Economics )。Crane 遵循 FinOps 标准,旨在为云原生用户提供云成本优化一站式解决方案。
Crane 的智能水平弹性能力是基于 Effective HPA 实现。用户在安装 Crane 后即可直接使用 Effective HPA 开启智能弹性之旅。
当前 Crane 项目主要贡献者包括有腾讯、小红书、谷歌、eBay、微软、特斯拉等知名公司的行业专家。
参考链接- Crane 开源项目地址:【https://github.com/gocrane/crane/】
- Crane 官网: 【https://docs.gocrane.io/】
- Effective HPA 使用文档:【https://docs.gocrane.io/dev/zh/tutorials/using-effective-hpa-to-scaling-with-effectiveness/】
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
④公众号后台回复【光速入门】,可获得腾讯云专家5万字精华教程,光速入门Prometheus和Grafana。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
