Redis 或许是我们大部分场景都会用到的一个利器,虽然是利器,用的姿势不对的话,终究还是会整出幺蛾子的。
比较常见的问题,不外乎内存暴增,慢查询等情况。
那么对于内存问题,可以借助redis自带的bigkey分析,也可以借助一些第三方工具来进行离线分析,如 redis-rdb-tools 和 rdr。
为什么是离线分析呢?
redis 在运行时,根据配置会生成一个 dump.rdb 的备份文件,这个备份文件是一个二进制文件,也是存在 redis 里面的数据的一个快照。
离线分析,分析的就是这个 rdb 文件。
受这两个项目的启发,老黄也用了好几个周末的时间写了个简单的离线分析工具。
下面简单介绍一下如何使用这个小工具。
rdb-tools项目地址: https://github.com/catcherwong/rdb-tools
工具下载方式:
- 从 Github Release 下载最新稳定版本 https://github.com/catcherwong/rdb-tools/releases/
- 通过 nuget 下载安装 https://www.nuget.org/packages/rdb-cli/
在 Github Release 下载的是无需运行时的单文件,压缩后是 5MB 左右,解压后是 11MB 左右,需要根据不同的操作系统下载不同的可运行文件,
nuget 的话,自然就是在安装了 .net 6 的前提下, 通过 dotnet tool install 的方式来安装
输入 ./rdb-cli -h 可以看到帮助信息。
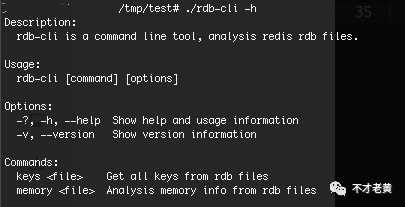
其中最主要的还是 memory 命令。
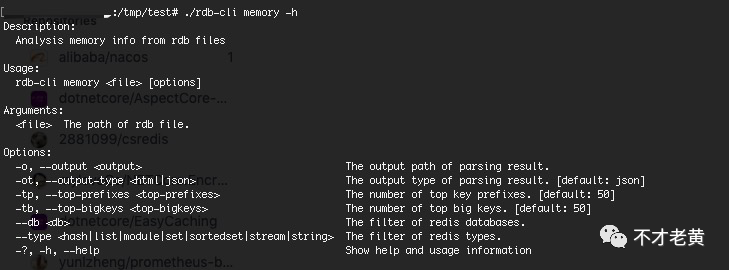
从帮助信息可以看到,需要指定 rdb 文件,和一些特定的选项。
一个比较简单常用的示例如下:
./rdb-cli memory /tmp/test/demo.rdb -ot html
这个会分析 demo.rdb ,同时分析结果以 html 的形式展现。

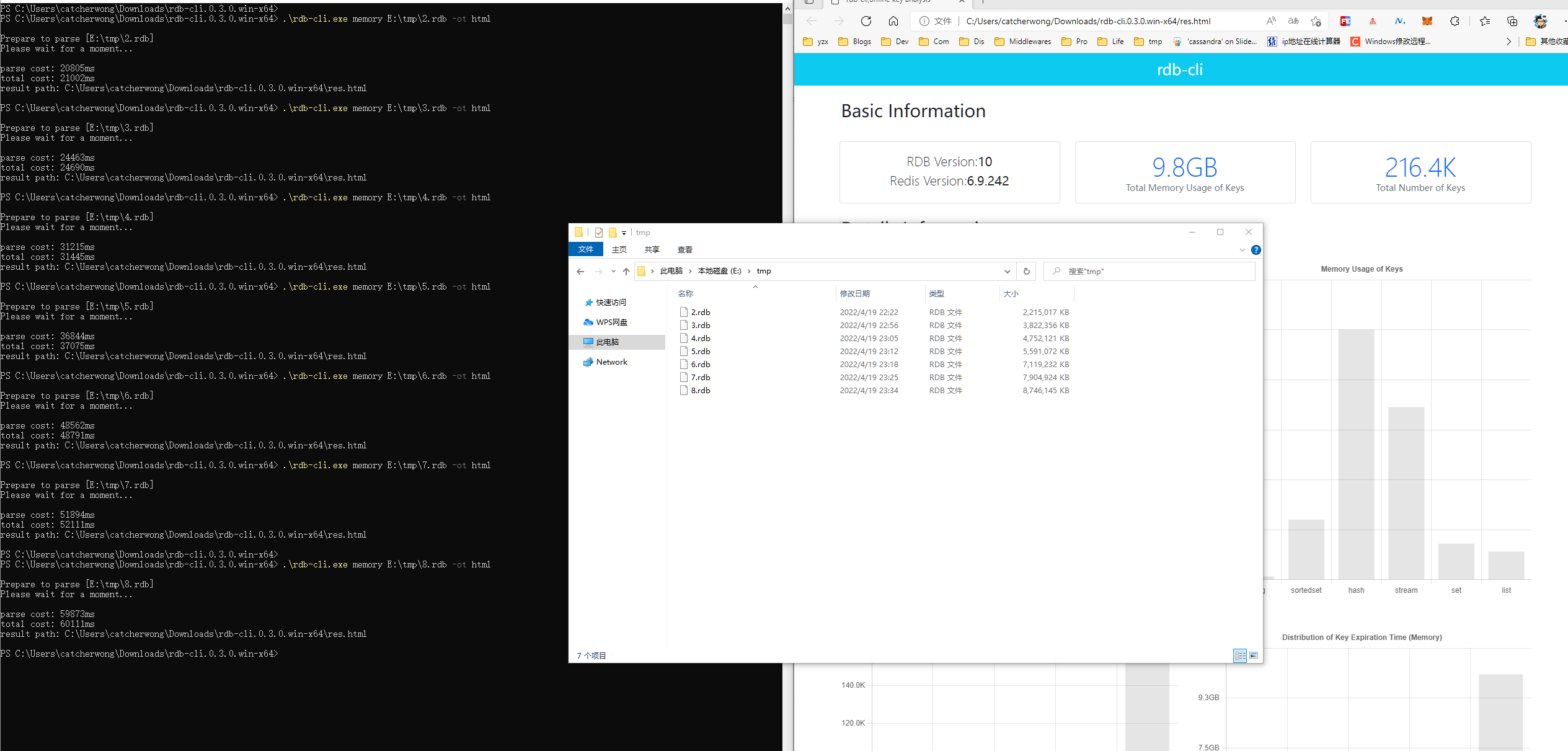
可以看到分析一个 2GB 的文件,大概需要 32秒左右。
html 如下:
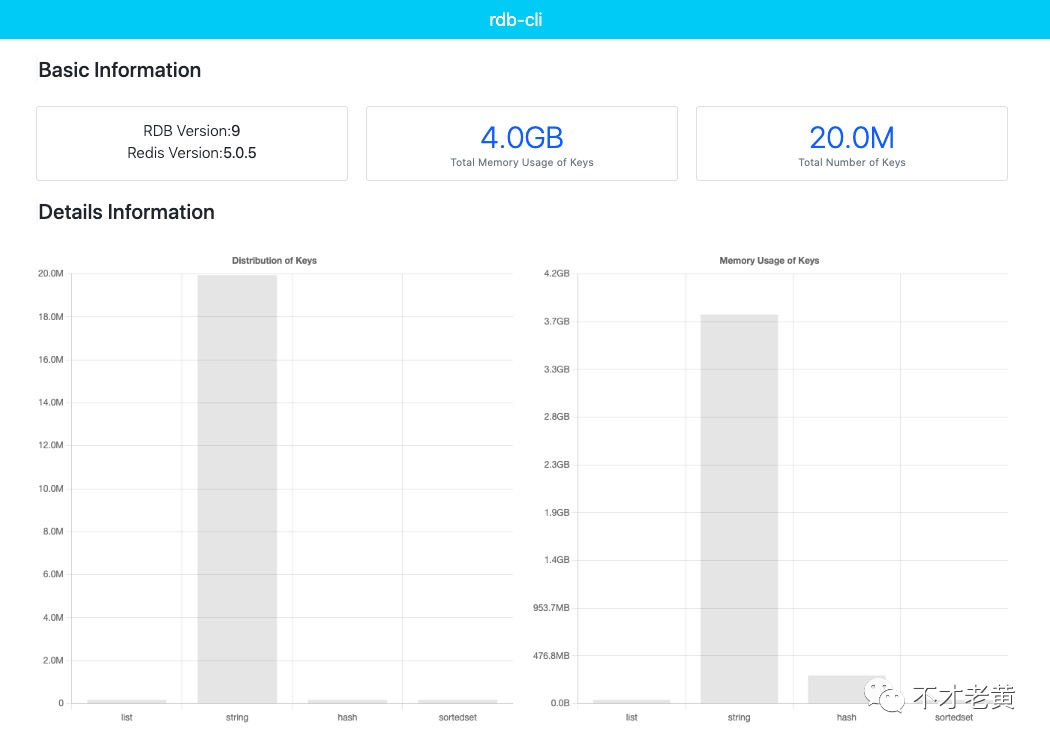

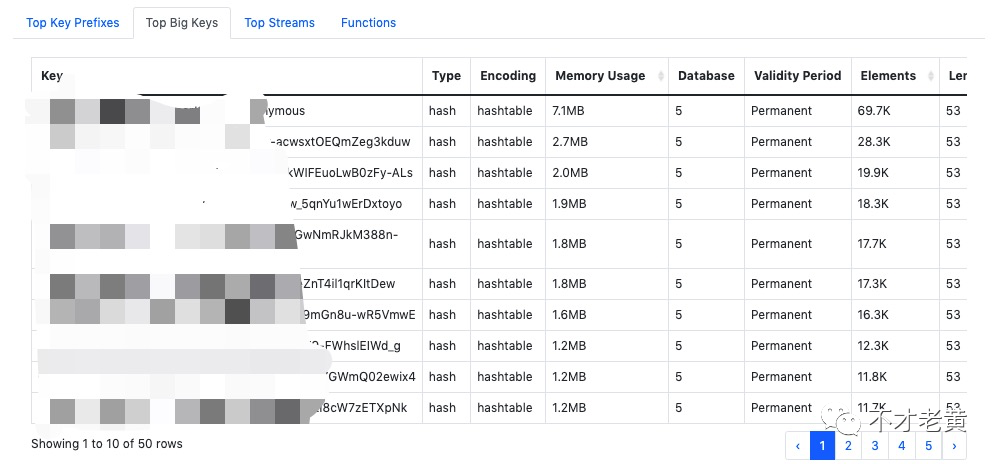
第一部分是基础信息,rdb 的版本信息, redis 的版本信息,总的内存,总的 key 数量。
第二部分是几个柱状图,主要是不同数据类型的内存和数量分布,以及过期时间的内存和数量分布。
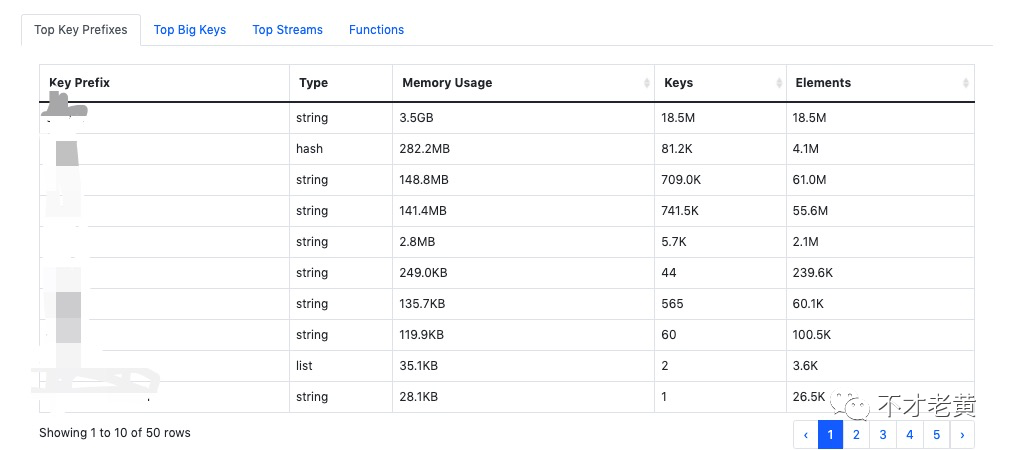
第三部分是几个表格,前几的 Key 前缀列表、前几的大 Key 列表、前几的 Stream 列表,Function 列表(Redis 7.0)。
当然,如果想进行一些过滤,可以指定不同的参数选项即可。
只想分析 db 9 和 db 10
./rdb-cli memory /tmp/test/demo.rdb -ot html --db 9 --db 10
只想分析 hash 和 string 类型
./rdb-cli memory /tmp/test/demo.rdb -ot html --type string --type hash
rdb-tools 除了这个直接可用的 cli 工具外,还有一个 parser 的类库,这个类库就是解析的核心类库, cli 也是基于这个做了一个 ReadCallback。
所以完全可以基于这个 parser 的类库,打造一个自定义的离线分析工具。
一些细节分析 rdb 文件,其实就是分析一个二进制文件。
不同版本的 redis,其 rdb 文件不一定一样,毕竟 rdb 文件也有版本的概念。
目前最新的 redis 7 ,rdb 的版本是 10,
redis 5.x ~ 6.x ,rdb 的版本则是 9 。
在 rdb-tools 里面,是用 BinaryReader 来读取 rdb 文件的。
目前大部分 rdb 文件的解析应该都是按照下面这个文档来的。
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format
不过它目前还没有包含 listpack 的解析。
最直观的方式是对照 redis 源码里面的 rdb.c 这个文件。
https://github.com/redis/redis/blob/7.0-rc3/src/rdb.c
rdb 对数字这一块的解码操作要特别注意,不一定能用 BitConverter.ToIntXX 来获得正确的值!!
另外有一些地方对大端和小端存储也有区分,这个是很容易踩坑的地方。
内存数据统计的时候用的是生产者消费者模式(BlockingCollection),边解析边统计,避免一次性把 redis 的数据都加载到内存中,造成内存溢出。
目前解析一次,占用的内存基本是在几十M 左右。
总结可能有人会问,为什么已经有这样的工具了,还要再写一个?
主要是考虑到下面几个吧
- 活跃度的问题和对新版 redis 的支持程度
- 自定义序列化这一块的扩展性
- 不同领域的探索和社区支持
写这么一个工具,也加深了 redis 底层存储和数据结构的一些认知。
感兴趣的可以一起参与完善。
补充了一下对 2~8GB 大小 rdb 文件分析的情况,可供参考。
 如果您认为这篇文章还不错或者有所收获,可以点击右下角的【推荐】按钮,因为你的支持是我继续写作,分享的最大动力!
如果您认为这篇文章还不错或者有所收获,可以点击右下角的【推荐】按钮,因为你的支持是我继续写作,分享的最大动力!