表示特定服务器上面,连续范围的分片键值所包含的一组数据,是一个逻辑概念。
例如,某数据块记录如下:
{ "_id" : "chunk-a", // 数据块Id "ns" : "user.address", // 该数据块对应的数据库名和表名 "min" : { // 该数据块对应的分片键值的起始值(包含),是“Shi Jiazhuang” "city" : "Shi Jiazhuang" }, "max" : { // 该数据块对应的分片键值的结束值(不包含),是“Nanjjing” "city" : "Nan Jing" }, "shard" : "repa" // 该数据块存储在repa分片服务器 }
// 即该数据块记录表示,数据库user中的表address中的“city”字段中,其值从“Shi Jiazhuang”(包含)到“Nan Jing”(不包含)这段连续区间的数据,都存储在名为repa的分片服务器。
1.2 Chunk Size(数据块大小)
数据块所对应的数据,如果超过64M(默认值),则会被系统自动切分为两个数据,即数据块会从1块切分为2块,图示如下:

1.3 Migration(数据块迁移)
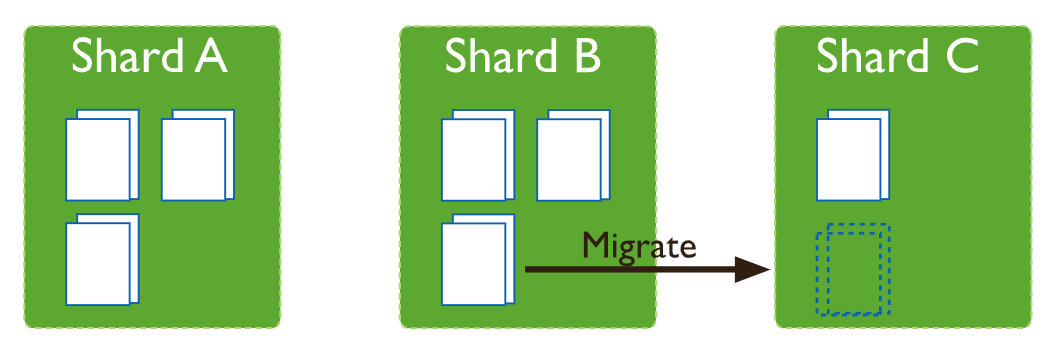
mongodb有一个后台的平衡器进程,它会监控各个分片服务器上面的数据块的数量,如果发现不同的分片服务器上面数据块的数量差异,超过阈值,则会启动数据块迁移任务,
直至不同的分片服务器之间的数据块的数量差异落在阈值之内,图示如下:
1.4 Migration Thresholds(迁移阈值)
数据块的迁移阈值,是和该表的数据块总数相关的,具体如下:
数据块总数量 阈值 小于20 2 20-79 4 大于等于80 82. 迁移流程
数据块的迁移对于用户和应用层来说是透明的,当然可能会有些性能的损失,整个迁移流程有7个步骤,图示如下

各个步骤的内容如下:
1. 平衡器发送迁移命令给源节点。
2. 源节点启动了一个内部的数据块迁移命令给目标节点,同时在数据块迁移期间,对于该数据块的请求依然路由到源节点。
3. 目标节点首先创建该数据块上缺失的索引(如果需要的话)。
4. 目标节点到源节点拉取数据。
5. 目标节点需要到源节点再请求在步骤4执行期间的增量变更数据(新增、更新和删掉),如果有则跳转到步骤4,直到没有增量数据。
6. 数据全部迁移成功后,源节点会向配置服务器(config server)发送请求,更新该数据块的元数据中的"分片服务器(shard)"的值为目标节点。
7. 源节点删除本地的该数据块对应的数据。
3. 最佳实践以上分享了数据块和数据块迁移的一些基本概念和流程,下面是一些最佳实践。
3.1 关于数据块大小的选择数据块的大小,默认是64M,通常情况下是不需要修改它的,但是有时候该值的大小根据不同的业务场景会带来不同的影响,需要综合多方面的因素来设置该值。
数据块大小太小:通常情况下,较小的数据块大小,会带来更频繁的数据块迁移,数据在集群间的分布会更加均衡,但是如果分片键设置的不够合理,则会产生很多无法切分(split)的大数据块,太大的数据块无法在分片之间迁移,从而导致数据分布的不均衡性,此时需要把数据块大小调大。
数据块大小太大:较大的数据块,意味着更少的数据块迁移,数据在集群间的分布容易出现不平衡,同时也容易产生读写热点(可手动切分),此时需要把数据块大小调小。
3.2 关于数据块迁移对集群性能的影响数据块迁移除了占用目标节点和源节点的带宽和磁盘读写资源外,在迁移流程中的步骤6会短暂阻塞对该数据块的访问,影响应用的访问,因此建议设置平衡器的活跃时间窗口,设置为业务低估时进行,步骤如下:
1. 连接到mongos。
2. 切换到config数据库
use config
3. 启动平衡器
如果平衡器是关闭状态,则设置活跃时间窗口也是不会做数据迁移的,命令如下:
sh.startBalancer()
4. 修改活跃时间窗口
db.settings.updateOne( { _id: "balancer" }, { $set: { activeWindow : { start : "01:00", stop : "06:00" } } }, // start和stop的格式为"HH:MM",其中HH的取值范围是0到23,MM的取值范围是00到59 { upsert: true } )https://github.com/tomliugen