- [源码解析] TensorFlow 分布式 DistributedStrategy 之基础篇
- 1. StrategyBase
- 1.1 初始化
- 1.2 使用
- 1.3 CTL
- 1.4 Scope
- 1.4.1 使用
- 1.4.2 功能
- 1.4.3 Scope 范围
- 1.5 StrategyExtendedV2
- 1.5.1 locality
- 1.5.2 如何更新
- 1.6 继承关系
- 2. 读取数据
- 2.1 直接读取数据集
- 2.1.1 用例
- 2.1.2 基类实现
- 2.1.3 MirroredExtended 实现
- 2.1.4 input_lib 功能
- 2.1.5 InputWorkers
- 定义
- 构建
- 2.1.6 DistributedDataset
- 初始化
- 建立数据
- 数据集
- 迭代数据
- 2.1.7 DistributedIterator
- DistributedIterator
- DistributedIteratorBase
- 2.2 通过方法初始化
- 2.2.1 StrategyBase
- 2.2.2 MirroredStrategy
- 2.2.3 建立 InputWorkers
- 2.2.4 input_contexts
- 2.2.5 返回数据集
- 2.2.6 构建数据集
- 2.3 高层使用
- 2.3.1 Keras
- 2.2.2 其他路径
- 2.1 直接读取数据集
- 0xFF 参考
- 1. StrategyBase
前文之中我们已经介绍了 Strategy 这个基本概念,tf.distribute.Strategy 是一个可在多个 GPU、多台机器或 TPU 上进行分布式训练的 TensorFlow API。使用此 API,您只需改动较少代码就能基于现有模型和训练代码来实现单机多卡,多机多卡等情况的分布式训练。tf.distribute.Strategy 旨在实现以下目标:
- 覆盖不同维度的用户用例。
- 易于使用,支持多种用户(包括研究人员和 ML 工程师等)。
- 提供开箱即用的高性能。
- 从用户模型代码之中解耦,这样可以轻松切换策略。
- 支持 Custom Training Loop,Estimator,Keras。
- 支持 eager excution。
从系统角度或者说从开发者的角度看,Strategy 是基于Python作用域或装饰器来实现的一套机制。它提供了一组命名的分布式策略,如ParameterServerStrategy、CollectiveStrategy来作为Python作用域,这些策略可以被用来捕获用户函数中的模型声明和训练逻辑,其将在用户代码开始时生效。在后端,分布式系统可以重写计算图,并根据选择的策略(参数服务器或集合)合并相应的语义。
因此我们分析的核心就是如何把数据读取,模型参数,分布式计算融合到Python作用域或装饰器之中,本章我们就从 Strategy 的类体系结构和读取数据开始。
依然安利两个大神:
[TensorFlow Internals] (https://github.com/horance-liu/tensorflow-internals),虽然其分析的不是最新代码,但是建议对 TF 内部实现机制有兴趣的朋友都去阅读一下,绝对大有收获。
https://home.cnblogs.com/u/deep-learning-stacks/ 西门宇少,不仅仅是 TensorFlow,其公共号还有更多其他领域,业界前沿。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(5) --- Session
[源码解析] TensorFlow 分布式环境(7) --- Worker 动态逻辑
[源码解析] TensorFlow 分布式环境(8) --- 通信机制
[翻译] 使用 TensorFlow 进行分布式训练
1. StrategyBaseStrategyBase 是一个设备列表之上的状态和计算分布策略。是 v1 策略和 v2 策略类的基类。
1.1 初始化StrategyBase 初始化方法之中最主要就是设定 extended,其类型是 StrategyExtendedV2 或者 StrategyExtendedV1。
class StrategyBase(object):
def __init__(self, extended):
self._extended = extended
# Flag that is used to indicate whether distribution strategy is used with
# Estimator. This is required for backward compatibility of loss scaling
# when using v1 optimizer with estimator.
self._scale_loss_for_estimator = False
if not hasattr(extended, _retrace_functions_for_each_device):
# extended._retrace_functions_for_each_device dictates
# whether the same function will be retraced when it is called on
# different devices.
try:
extended._retrace_functions_for_each_device = (
len(extended.worker_devices) > 1)
distribution_strategy_replica_gauge.get_cell(num_replicas).set(
self.num_replicas_in_sync)
except:
# Default for the case where extended.worker_devices can't return
# a sensible value.
extended._retrace_functions_for_each_device = True
# Below are the dicts of axis(int) -> tf.function.
self._mean_reduce_helper_fns = {}
self._reduce_sum_fns = {}
# Whether this strategy is designed to work with ClusterCoordinator.
self._should_use_with_coordinator = False
@property
def extended(self):
```tf.distribute.StrategyExtended with additional methods.```
return self._extended
如果想使用 Keras compile/fit,请参照 https://www.tensorflow.org/guide/distributed_training#using_tfdistributestrategy_with_keras。
也可以将 tf.distribution.Strategy 的派生类传递给 tf.estimator.RunConfig 来指定 tf.estimator.Estimator 应该如何分配计算,具体可以参照 https://www.tensorflow.org/guide/distributed_training#using_tfdistributestrategy_with_estimator_limited_support。
在建立和执行模型时,应该首先使用 tf.distribution.Strategy.scope 来指定一个策略。 指定策略意味着这将使代码处于这个策略的 cross-replica context 中,因此这个策略将负责控制比如 variable placement 这样的功能。
1.3 CTL如果您正在编写一个自定义的训练循环(custom training loop),您将需要多调用一些方法,
- 使用 tf.distribut.Strategy.experimental_distribute_dataset 将 tf.data.Dataset 转换,使之能产生 per-replica 值。如果您想手动指定数据集如何在各个副本之间进行划分,请使用tf.distribut.Strategy.distribut_datasets_from_function。
- 使用 tf.distribution.Strategy.run 为每个副本运行函数,该函数使用 per-replica 的值(例如来自tf.distribution.DistributedDataset对象)并返回一个 per-replica。这个函数是在 副本上下文 中执行的,这意味着每个操作都在每个副本上单独执行。
- 最后使用一个方法(如tf.distributed.Strategy.reduce)将得到的 per-replica 的值转换成普通的张量。
下面代码是 CTL 一个典型用例,其使用一个普通的 dataset 和 replica_fn 在名为 my_strategy 的特定 tf.distribution.Strategy 下分布式运行。在 replica_fn 中创建的任何变量都是使用 my_strategy 的策略创建的。
用户可以使用 reduce API 来聚合各副本的结果,并将其作为对 tf.distributedDataset 进行一次迭代的返回值。用户也可以使用 tf.keras.metrics(如损失、准确度等)来累积各步骤的度量。
with my_strategy.scope():
@tf.function
def distribute_train_epoch(dataset):
def replica_fn(input):
# process input and return result
return result
total_result = 0
for x in dataset:
per_replica_result = my_strategy.run(replica_fn, args=(x,))
total_result += my_strategy.reduce(tf.distribute.ReduceOp.SUM,
per_replica_result, axis=None)
return total_result
dist_dataset = my_strategy.experimental_distribute_dataset(dataset)
for _ in range(EPOCHS):
train_result = distribute_train_epoch(dist_dataset)
分发策略的范围(作用域)决定了如何创建变量以及在何处创建变量,比如对于 MultiWorkerMirroredStrategy 而言,创建的变量类型是 MirroredVariable ,策略将它们复制到每个工作者之上。Scope 的方法主要是通过调用 _extended._scope 来完成。该方法返回了一个 Context manager,这可以设置本策略为当前策略,并且分发变量。
def scope(self):
"""Context manager to make the strategy current and distribute variables.
Returns:
A context manager.
"""
return self._extended._scope(self)
具体使用方法如下:
>>> strategy = tf.distribute.MirroredStrategy([GPU:0, GPU:1])
>>> # Variable created inside scope:
>>> with strategy.scope():
... mirrored_variable = tf.Variable(1.)
>>> mirrored_variable
MirroredVariable:{
0: <tf.Variable 'Variable:0' shape=() dtype=float32, numpy=1.0>,
1: <tf.Variable 'Variable/replica_1:0' shape=() dtype=float32, numpy=1.0>
}
>>> # Variable created outside scope:
>>> regular_variable = tf.Variable(1.)
>>> regular_variable
<tf.Variable 'Variable:0' shape=() dtype=float32, numpy=1.0>
当进入了 Strategy.scope 之后,会执行如下操作:
- strategy 被安装在全局上下文内,作为当前策略。 在这个范围内,调用 tf.distribution.get_strategy() 将返回这个策略。在这个范围之外,它将返回默认的无操作(no-op)策略。
- 进入这个 scope 也就进入了 cross-replica context。
- scope 内的变量创建将被策略拦截。每个策略都定义了它要如何影响变量的创建。像 MirroredStrategy、TPUStrategy 和 MultiWorkerMiroredStrategy 这样的同步策略在每个副本上创建变量,而ParameterServerStrategy 在参数服务器上创建变量。这是在策略自定义的 tf.variable_creator_scope 之中完成的。
- 在某些策略中也可以输入默认的设备范围:在 MultiWorkerMiroredStrategy 中,每个 worker 上输入的默认设备范围是 /CPU:0。
注意:进入 Scope 不会自动分配计算,除非是像 keras model.fit 这样的高层训练框架。如果您没有使用 model.fit,您需要使用 strategy.run API 来明确分配该计算。
1.4.3 Scope 范围什么在 Scope 之内?什么在之外?
- 任何创建分布式变量的操作都必须在 strategy.scope 中调用。这可以通过在范围上下文中直接调用变量创建函数来实现,或者由 strategy.run 或 Keras.Model.fit 自动为您输入。
- 任何可能惰性创建变量的函数(例如,Model.call(),追踪一个tf.function,等等)也应该在作用域内调用。
- 变量创建的另一个来源可以是检查点的恢复。
- 任何在作用域之外创建的变量都不会被分发。
请注意,任何在策略内部创建的变量都会捕获策略信息。因此,在 strategy.scope 之外对这些变量的读写也可以无缝进行,而不需要用户进入 scope。
一些需要进入策略范围的策略 API(如strategy.run和strategy.reduce)会自动进入 scope,这意味着在使用这些API 时,您不需要自己明确进入 scope。
模型、优化器、Metrics 可以在 TF 之中创建变量,这样的对象应该总是在作用域内初始化。当 tf.keras.Model 在strategy.scope 内被创建,Model 对象会捕获范围信息。当高层的训练框架方法,如 model.compile,model.fit 等被调用时,捕获的范围将被自动输入,相关的策略将被用来分配训练等。
警告:简单地调用model(..)不会自动进入 Strategy 的范围 -- 只有高水平的训练框架 API 支持这种行为:model.compile、model.fit、model.evaluation、model.predict 和 model.save 都可以在范围内或范围外调用。
1.5 StrategyExtendedV2StrategyExtendedV2 为需要分布感知(distribution-aware)的算法提供额外的API。
@tf_export(distribute.StrategyExtended, v1=[])
class StrategyExtendedV2(object):
# Additional APIs for algorithms that need to be distribution-aware.
tf.distributed.DistributedValues 可以具有与分布式变量相同的 locality,这导致 mirrored value 会驻留在与变量相同的设备上(而不是计算设备上)。针对 locality,用户可以做如下操作:
- 可以使用 tf.distribution.StrategyExtended.update 来更新变量的值。
- 可以使用 tf.distribution.StrategyExtended.colocate_vars_with 来让一个变量与另一个变量有相同的 locality。
- 可以使用 tf.distribution.StrategyExtended.reduce_to 或 tf.distribution.StrategyExtended.batch_reduce_to 将 PerReplica value 转换到另一个变量的 locality。
接下来我们看看如何更新一个分布式变量(distributed variable)。分布式变量(distributed variable)是在多个设备上创建的变量,比如镜像变量和同步读取(SyncOnRead)变量。更新分布式变量的标准模式是:
- 在传递给 tf.distribution.Strategy.run 的函数中来计算得到一个(update, variable)对列表。例如,更新可能是一个变量的损失梯度。
- 通过调用 tf.distribution.get_replica_context().merge_call() 来切换到 cross-replica 模式,调用时将更新和变量作为参数。
- 通过调用 tf.distribution.StrategyExtended.reduce_to(VariableAggregation.SUM, t, v)(针对一个变量)或tf.distribution.StrategyExtended.batch_reduce_to(针对一个变量列表)来对更新进行求和。
- 可以为每个变量调用 tf.distribution.StrategyExtended.update(v) 来更新它的值。
如果您在副本上下文中调用 tf.keras.optimizer.Optimizer.apply_gradients方法,则步骤 2 到 4 会由类tf.keras.optimizer.Optimizer 自动完成。
事实上,更新分布式变量的更高层次的解决方案是对该变量调用 assign,就像您对普通的 tf.Variable 一样操作。您可以在 replica context 和 cross-replica context 中调用该方法。
对于一个 mirrored 变量,在 replica context 中调用 assign 需要在变量构造函数中指定aggregation类型。在这种情况下,您需要自行处理在步骤2到4中描述的上下文切换和同步。如果您在 cross-replica context 中对 mirrored variable 调用 assign,您只能 assign 一个值,或者从一个镜像的 tf.distribution.DistributedValues 中来 assign 值。对于一个 _SyncOnRead 变量,在 replica 上下文中,您可以简单地调用 assign,而不发生任何聚合。在 cross-replica context 中,您只能给一个 SyncOnRead 变量分配一个值。
1.6 继承关系Strategy 继承关系如下,其中 V1 版本是一条路线,V2 版本又是一条路线。
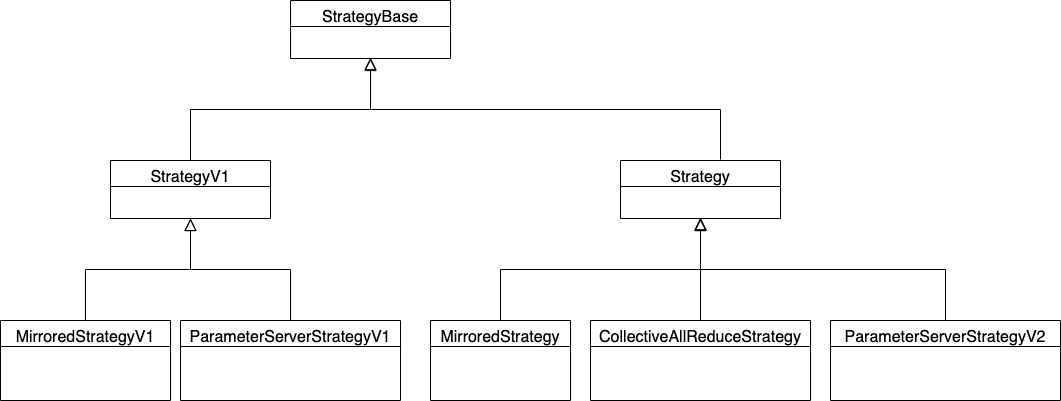
图 1 Strategy 继承关系
Extended 继承关系如下:
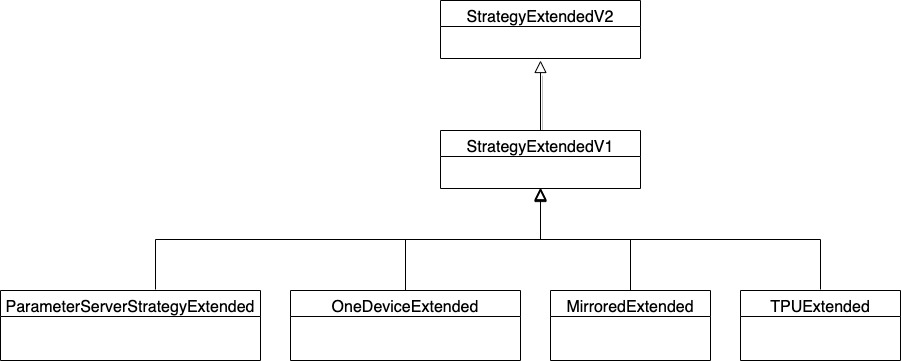
图 2 Extended 继承关系
至此,我们分析了Strategy的类体系,但是还没有领略Strategy的精妙之处,我们需要继续分析下去,本文会先看看如何处理数据,下一篇看看如何处理变量。
2. 读取数据我们接下来看看如何读取数据。对于输入数据集,主要有两种实现:
- experimental_distribute_dataset :从 tf.data.Dataset 生成 tf.distribute.DistributedDataset,得到的数据集可以像常规数据集一样迭代读取。
- _distribute_datasets_from_function :通过调用 dataset_fn 来分发 tf.data.Dataset。
我们接下来用 MirroredStrategy 来分析如何读取数据。总体的逻辑大致如下:在每个工作者上对数据集进行复制,重新分批和分片。首先会按文件分片,这样每个工作者将看到不同的文件子集。如果无法做到,工作者则将尝试对最终输入进行分片,这样每个工作者会运行整个预处理流水线,但是只收到自己的数据集分片,从而达到数据并行的目的。
2.1 直接读取数据集 2.1.1 用例以下是如何使用 experimental_distribute_dataset 来直接得到数据集。
>>> global_batch_size = 2
>>> # Passing the devices is optional.
... strategy = tf.distribute.MirroredStrategy(devices=["GPU:0", "GPU:1"])
>>> # Create a dataset
... dataset = tf.data.Dataset.range(4).batch(global_batch_size)
>>> # Distribute that dataset
... dist_dataset = strategy.experimental_distribute_dataset(dataset)
>>> @tf.function
... def replica_fn(input):
... return input*2
>>> result = []
>>> # Iterate over the tf.distribute.DistributedDataset
... for x in dist_dataset:
... # process dataset elements
... result.append(strategy.run(replica_fn, args=(x,)))
>>> print(result)
[PerReplica:{
0: <tf.Tensor: shape=(1,), dtype=int64, numpy=array([0])>,
1: <tf.Tensor: shape=(1,), dtype=int64, numpy=array([2])>
}, PerReplica:{
0: <tf.Tensor: shape=(1,), dtype=int64, numpy=array([4])>,
1: <tf.Tensor: shape=(1,), dtype=int64, numpy=array([6])>
}]
StrategyBase 方法之中,主要三种数据相关操作是:分批,分片,预取(大家可以回到PyTorch数据读取部分看看异同)。
在上面的代码片段中,分批操作具体是:
- dataset 首先按照 global_batch_size 进行分批。
- 其次调用 experimental_distribute_dataset 把 dataset 按照一个新分批大小(batch size)进行重新分批,新分批大小等于"全局分批大小除以同步副本数量"。用户可以用 Pythonic for loop 来遍历它。
- x 是一个 tf.distribution.DistributedValues,其包含所有副本的数据,而每个副本会得到新批次大小的数据。
- tf.distribution.Strategy.run 将负责把 x 中每个副本对应的数据(per-replica)分发给每个副本执行工作函数 replica_fn。
分片(Sharding)包含跨多个工作者的自动分片(autosharding)。
- 首先,在多工作者(multi-worker)分布式训练中(使用tf.distribution.experimental.MultiWorkerMirroredStrategy 或 tf.distribution.TPUStrategy 时),在一组工作者上自动分片(autosharding)数据集意味着每个工作者被分配了整个数据集的一个子集(如果设置了正确的tf.data.experimental.AutoShardPolicy)。这是为了确保在每个 step 中,每个工作者都会处理一个全局的,包含不重叠的数据集元素的批次。自动分片有几个不同的选项,可以使用 tf.data.experimental.DistributeOptions 来指定。
- 然后,每个工作者内的分片意味着该方法将在所有工作者设备之间分割数据(如果存在多个)。无论多工作者(multi-worker)是否设定自动分片,这都会发生。
- 对于跨多个工作者的自动分片,默认模式是 tf.data.experimental.AutoShardPolicy.AUTO。如果数据集是从读者数据集(例如tf.data.TFRecordDataset、tf.data.TextLineDataset等)中创建的,该模式将尝试按文件分片,否则按数据分片,其中每个工作者将读取整个数据集,但是只处理分配给它的分片。然而,如果每个工作者的输入文件少于一个,我们建议您通过设置 tf.data.experimental.DistributeOptions.auto_shard_policy 为 tf.data.experimental.AutoShardPolicy.OFF 来禁止跨工作者的数据集自动分片。
对于预取(prefetch),默认情况下,该方法在用户提供的 tf.data.Dataset 实例的末尾添加一个预取转换。预取转换的参数是 buffer_size,就是同步的副本(replicas in sync)的数量。
experimental_distribute_dataset 的定义如下,其实就是调用 extended 来完成操作。
def experimental_distribute_dataset(self, dataset, options=None):
"""Creates tf.distribute.DistributedDataset from tf.data.Dataset.
Args:
dataset: tf.data.Dataset that will be sharded across all replicas using
the rules stated above.
options: tf.distribute.InputOptions used to control options on how this
dataset is distributed.
Returns:
A tf.distribute.DistributedDataset.
"""
distribution_strategy_input_api_counter.get_cell(
self.__class__.__name__, "distribute_dataset").increase_by(1)
return self._extended._experimental_distribute_dataset(dataset, options)
我们用 MirroredExtended 来看看具体实现,其实就是调用 input_lib.get_distributed_dataset 来进行处理,因此我们深入到 input_lib 之中。
def _experimental_distribute_dataset(self, dataset, options):
if (options and options.experimental_replication_mode ==
distribute_lib.InputReplicationMode.PER_REPLICA):
raise NotImplementedError(
"InputReplicationMode.PER_REPLICA "
"is only supported in "
"distribute_datasets_from_function."
)
return input_lib.get_distributed_dataset(
dataset,
self._input_workers_with_options(options),
self._container_strategy(),
num_replicas_in_sync=self._num_replicas_in_sync,
options=options)
input_lib 提供了关于处理输入数据的一些基础功能。get_distributed_dataset 是一个通用函数,其可以被所有策略用来返回分布式数据集。返回的分布式数据集实例是不同的,这取决于我们是在 TF1 还是 TF2 的背景下。返回的分布式数据集实例的 API 也有所不同。这里用到了 DistributedDataset 和 input_workers,所以我们有必要一一进行分析。
def get_distributed_dataset(dataset,
input_workers,
strategy,
num_replicas_in_sync=None,
input_context=None,
options=None,
build=True):
"""Returns a distributed dataset from the given tf.data.Dataset instance.
Args:
dataset: a tf.data.Dataset instance.
input_workers: an InputWorkers object which specifies devices on which
iterators should be created.
strategy: a tf.distribute.Strategy object, used to run all-reduce to
handle last partial batch.
num_replicas_in_sync: Optional integer. If this is not None, the value is
used to decide how to rebatch datasets into smaller batches so that
the total batch size for each step (across all workers and replicas)
adds up to dataset's batch size.
input_context: InputContext for sharding. Only pass this in for between
graph multi-worker cases where there is only one input_worker. In
these cases, we will shard based on the input_pipeline_id and
num_input_pipelines in the InputContext.
options: Default is None. tf.distribute.InputOptions used to control
options on how this dataset is distributed.
build: whether to build underlying datasets when a DistributedDataset is
created. This is only useful for ParameterServerStrategy now.
Returns:
A distributed dataset instance.
"""
if tf2.enabled():
return DistributedDataset( # 接下来会分析 DistributedDataset
input_workers,
strategy,
dataset,
num_replicas_in_sync=num_replicas_in_sync,
input_context=input_context,
build=build,
options=options)
else:
return DistributedDatasetV1(
dataset,
input_workers, # 接下来会分析 InputWorkers
strategy,
num_replicas_in_sync=num_replicas_in_sync,
input_context=input_context,
options=options)
InputWorkers 的作用是从输入 worker 设备到计算设备的 1-to-many mapping。worker_device_pairs 就是映射关系列表,每个 item 是 (input device, a tuple of compute devices fed by that input device)。
class InputWorkers(object):
"""A 1-to-many mapping from input worker devices to compute devices."""
# TODO(ishark): Remove option canonicalize_devices and make all the callers
# pass canonicalized or raw device strings as relevant from strategy.
def __init__(self,
worker_device_pairs,
canonicalize_devices=True):
"""Initialize an InputWorkers object.
Args:
worker_device_pairs: A sequence of pairs: (input device, a tuple of
compute devices fed by that input device).
canonicalize_devices: Whether to canonicalize devices for workers fully or
partially. If False, it will partially canonicalize devices by removing
job and task.
"""
self._worker_device_pairs = worker_device_pairs
self._input_worker_devices = tuple(d for d, _ in self._worker_device_pairs)
self._canonicalize_devices = canonicalize_devices
if canonicalize_devices:
self._fed_devices = tuple(
tuple(device_util.canonicalize(d)
for d in f)
for _, f in self._worker_device_pairs)
else:
self._fed_devices = tuple(
tuple(device_util.canonicalize_without_job_and_task(d)
for d in f)
for _, f in self._worker_device_pairs)
@property
def num_workers(self):
return len(self._input_worker_devices)
@property
def worker_devices(self):
return self._input_worker_devices # 返回 device, worker 信息
def compute_devices_for_worker(self, worker_index):
return self._fed_devices[worker_index]
def __repr__(self):
devices = self.worker_devices
debug_repr = ",\n".join(" %d %s: %s" %
(i, devices[i], self._fed_devices[i])
for i in range(len(devices)))
return "%s:{\n%s}" % (self.__class__.__name__, debug_repr)
def serialize(self):
return (self._worker_device_pairs, self._canonicalize_devices)
def deserialize(self, serialized):
return InputWorkers(serialized)
在 MirroredStrategy 之中有成员变量 _input_workers,因此,如果调用时候就会生成 InputWorkers。
@property
def _input_workers(self):
return self._input_workers_with_options()
_input_workers_with_options 会根据 self._devices 来进行配置,就是生成各种映射关系,然后配置进去。
def _input_workers_with_options(self, options=None):
if not options:
# 没有配置就直接建立
return input_lib.InputWorkers(self._input_workers_devices)
# 有配置就依据配置生成
if (options.experimental_replication_mode ==
distribute_lib.InputReplicationMode.PER_REPLICA):
# PER_REPLICA 处理
if options.experimental_place_dataset_on_device:
self._input_workers_devices = (
tuple(
(device_util.canonicalize(d, d), (d,)) for d in self._devices))
else:
self._input_workers_devices = (
tuple((device_util.canonicalize("/device:CPU:0", d), (d,))
for d in self._devices))
return input_lib.InputWorkers(self._input_workers_devices)
else:
if not options.experimental_fetch_to_device:
return input_lib.InputWorkers([
(host_device, (host_device,) * len(compute_devices))
for host_device, compute_devices in self._input_workers_devices
])
else:
return input_lib.InputWorkers(self._input_workers_devices)
这里使用了 device_util.canonicalize 方法,其作用是把设备分类。
def canonicalize(d, default=None):
"""Canonicalize device string.
If d has missing components, the rest would be deduced from the default
argument or from '/replica:0/task:0/device:CPU:0'. For example:
If d = '/cpu:0', default='/job:worker/task:1', it returns
'/job:worker/replica:0/task:1/device:CPU:0'.
If d = '/cpu:0', default='/job:worker', it returns
'/job:worker/replica:0/task:0/device:CPU:0'.
If d = '/gpu:0', default=None, it returns
'/replica:0/task:0/device:GPU:0'.
Note: This uses "job:localhost" as the default if executing eagerly.
Args:
d: a device string or tf.config.LogicalDevice
default: a string for default device if d doesn't have all components.
Returns:
a canonicalized device string.
"""
if isinstance(d, context.LogicalDevice):
d = tf_device.DeviceSpec.from_string(d.name)
else:
d = tf_device.DeviceSpec.from_string(d)
# Fill in missing device fields using defaults.
result = tf_device.DeviceSpec(
replica=0, task=0, device_type="CPU", device_index=0)
if ops.executing_eagerly_outside_functions():
# Try to deduce job, replica and task in case it's in a multi worker setup.
host_cpu = tf_device.DeviceSpec.from_string(
config.list_logical_devices("CPU")[0].name)
if host_cpu.job:
result = result.make_merged_spec(host_cpu)
else:
# The default job is localhost if eager execution is enabled
result = result.replace(job="localhost")
if default:
# Overrides any defaults with values from the default device if given.
result = result.make_merged_spec(
tf_device.DeviceSpec.from_string(default))
# Apply d last, so that it's values take precedence over the defaults.
result = result.make_merged_spec(d)
return result.to_string()
DistributedDataset 支持预先分发数据到多个设备。
初始化下面代码中省略了大量检查代码,关键点是调用了 build 方法。
class DistributedDataset(_IterableInput, composite_tensor.CompositeTensor):
"""Distributed dataset that supports prefetching to multiple devices."""
def __init__(self,
input_workers,
strategy,
dataset=None,
num_replicas_in_sync=None,
input_context=None,
components=None,
element_spec=None,
enable_get_next_as_optional=None,
build=True,
options=None):
"""Distribute the dataset on all workers.
If num_replicas_in_sync is not None, we split each batch of the dataset
into num_replicas_in_sync smaller batches, to be distributed among that
worker's replicas, so that the batch size for a global step (across all
workers and replicas) is as expected.
Args:
input_workers: an InputWorkers object.
strategy: a tf.distribute.Strategy object, used to run all-reduce to
handle last partial batch.
dataset: tf.data.Dataset that will be used as the input source. Either
dataset or components field should be passed when constructing
DistributedDataset. Use this when contructing DistributedDataset from a
new tf.data.Dataset. Use components when constructing using
DistributedDatasetSpec.
num_replicas_in_sync: Optional integer. If this is not None, the value
is used to decide how to rebatch datasets into smaller batches so that
the total batch size for each step (across all workers and replicas)
adds up to dataset's batch size.
input_context: InputContext for sharding. Only pass this in for between
graph multi-worker cases where there is only one input_worker. In
these cases, we will shard based on the input_pipeline_id and
num_input_pipelines in the InputContext.
components: datasets when DistributedDataset is constructed from
DistributedDatasetSpec. Either field dataset or components should be
passed.
element_spec: element spec for DistributedDataset when constructing from
DistributedDatasetSpec. This will be used to set the element_spec for
DistributedDataset and verified against element_spec from components.
enable_get_next_as_optional: this is required when components is passed
instead of dataset.
build: whether to build underlying datasets when this object is created.
This is only useful for ParameterServerStrategy now.
options: tf.distribute.InputOptions used to control options on how this
dataset is distributed.
"""
super(DistributedDataset, self).__init__(input_workers=input_workers)
self._input_workers = input_workers
self._strategy = strategy
self._options = options
self._input_context = input_context
self._num_replicas_in_sync = num_replicas_in_sync
if dataset is not None:
self._original_dataset = dataset
self._built = False
if build:
self.build() # 这里是关键
else:
self._cloned_datasets = components
self._cardinality = _cardinality(self._cloned_datasets[0])
self._enable_get_next_as_optional = enable_get_next_as_optional
if element_spec != _create_distributed_tensor_spec(
self._strategy, self._cloned_datasets[0].element_spec):
raise ValueError("Mismatched element_spec from the passed components")
self._element_spec = element_spec
self._built = True
build 主要作用是调用 _create_cloned_datasets_from_dataset。
def build(self, dataset_to_replace=None):
dataset = dataset_to_replace or self._original_dataset
self._cardinality = _cardinality(dataset)
self._enable_get_next_as_optional = _enable_get_next_as_optional(
self._strategy, dataset, self._cardinality)
self._create_cloned_datasets_from_dataset(dataset, self._input_context,
self._input_workers,
self._strategy,
self._num_replicas_in_sync)
self._element_spec = _create_distributed_tensor_spec(
self._strategy, self._cloned_datasets[0].element_spec)
self._built = True
_create_cloned_datasets_from_dataset 在每个工作者上对数据集进行克隆和分片(这里就使用到了InputWorkers以获取设备信息)。首先会尝试按文件分片,以便每个工作者看到不同的文件子集。如果无法做到,则将尝试对最终输入进行分片,这样每个工作者将运行整个预处理管道,并且只收到自己的数据集分片。
此外,_create_cloned_datasets_from_dataset 将每个工作者上的数据集重新匹配成 num_replicas_in_sync 个更小的批次。这些更小的批次分布在该工作者的副本中,这样全局步骤(global step)的批次大小(跨越所有工作者和副本)加起来就等于原始数据集的批次大小。
def _create_cloned_datasets_from_dataset(self, dataset, input_context,
input_workers, strategy,
num_replicas_in_sync):
if num_replicas_in_sync is not None:
num_workers = input_context.num_input_pipelines if input_context else len(
input_workers.worker_devices)
# 用 _make_rebatch_fn 来重新 batch 数据
rebatch_fn = self._make_rebatch_fn(dataset, num_workers,
num_replicas_in_sync)
else:
rebatch_fn = None
self._cloned_datasets = []
if input_context:
# Between-graph where we rely on the input_context for sharding
if rebatch_fn is not None:
dataset = rebatch_fn(dataset, input_context.input_pipeline_id)
dataset = input_ops.auto_shard_dataset(dataset,
input_context.num_input_pipelines,
input_context.input_pipeline_id,
num_replicas_in_sync)
self._cloned_datasets.append(dataset)
else:
# 复制数据,返回 _RemoteDataset
replicated_ds = distribute.replicate(dataset,
input_workers.worker_devices)
for i, worker in enumerate(input_workers.worker_devices):
with ops.device(worker):
cloned_dataset = replicated_ds[worker] # 找到某 worker 对应的数据集
if rebatch_fn is not None:
cloned_dataset = rebatch_fn(cloned_dataset, i) # 重新 batch,返回 _RebatchDataset
# 自动分区,返回 _AutoShardDataset
cloned_dataset = input_ops.auto_shard_dataset(
cloned_dataset, len(input_workers.worker_devices), i,
num_replicas_in_sync)
self._cloned_datasets.append(cloned_dataset)
distribute.replicate 是用来复制数据,把数据复制到一系列设备上,这里返回 _RemoteDataset。
def replicate(dataset, devices):
"""A transformation that replicates dataset onto a list of devices.
Args:
dataset: A tf.data.Dataset object.
devices: A list of devices to replicate the dataset on.
Returns:
A dictionary mapping device name to a dataset on that device.
"""
dataset_device = dataset._variant_tensor.device
datasets = {}
if len(devices) == 1 and devices[0] == dataset_device:
datasets[devices[0]] = dataset
return datasets
with ops.colocate_with(dataset._variant_tensor):
dataset = dataset._apply_debug_options()
graph_def = dataset._as_serialized_graph(
strip_device_assignment=True,
external_state_policy=ExternalStatePolicy.WARN)
for device in devices: # 遍历设备,复制数据到设备上,每个设备一个 _RemoteDataset
ds = _RemoteDataset(graph_def, device, dataset.element_spec)
datasets[device] = ds
return datasets
_make_rebatch_fn 返回一个把输入数据集 rebatches 的 callable,这里返回 _RebatchDataset。
def _make_rebatch_fn(self, dataset, num_workers, num_replicas_in_sync):
"""Returns a callable that rebatches the input dataset.
Args:
dataset: A tf.data.Dataset representing the dataset to be distributed.
num_workers: An integer representing the number of workers to distribute
dataset among.
num_replicas_in_sync: An integer representing the number of replicas in
sync across all workers.
"""
if num_replicas_in_sync % num_workers:
raise ValueError(
"tf.distribute expects every worker to have the same number of "
"replicas. However, encountered num_replicas_in_sync ({}) that "
"cannot be divided by num_workers ({})".format(
num_replicas_in_sync, num_workers))
num_replicas_per_worker = num_replicas_in_sync // num_workers
with ops.colocate_with(dataset._variant_tensor):
batch_size = distribute.compute_batch_size(dataset)
def rebatch_fn(dataset, worker_index):
try:
def apply_rebatch():
batch_sizes = distribute.batch_sizes_for_worker(
batch_size, num_workers, num_replicas_per_worker, worker_index)
return distribute._RebatchDataset(
dataset, batch_sizes).prefetch(num_replicas_per_worker)
def apply_legacy_rebatch():
return distribute._LegacyRebatchDataset(
dataset, num_replicas_in_sync).prefetch(num_replicas_per_worker)
with ops.colocate_with(dataset._variant_tensor):
return control_flow_ops.cond(
math_ops.not_equal(batch_size, -1),
true_fn=apply_rebatch,
false_fn=apply_legacy_rebatch)
except errors.InvalidArgumentError as e:
if "without encountering a batch" in str(e):
six.reraise(
ValueError,
ValueError(
"Call the batch method on the input Dataset in order to be "
"able to split your input across {} replicas.\n Please see "
"the tf.distribute.Strategy guide. {}".format(
num_replicas_in_sync, e)),
sys.exc_info()[2])
else:
raise
return rebatch_fn
接下来是自动分片,这里返回 _AutoShardDataset。
def auto_shard_dataset(dataset, num_shards, index, num_replicas_in_sync=None):
"""Shard the input pipeline by sharding the underlying list of files.
Args:
dataset: A tf.data.Dataset instance, typically the result of a bunch of
dataset transformations.
num_shards: A tf.int64 scalar tf.Tensor, representing the number of
shards operating in parallel. Same usage as in tf.data.Dataset.shard.
index: A tf.int64 scalar tf.Tensor, representing the worker index.
Same usage as in tf.data.Dataset.shard.
num_replicas_in_sync: An integer representing the total number of replicas
across all workers. This is used in the rewrite when sharding by data.
Returns:
A modified Dataset obtained by updating the pipeline sharded by the
files. The input dataset will be returned if we cannot automatically
determine a good way to shard the input dataset.
"""
if (dataset.options().experimental_distribute.auto_shard_policy !=
AutoShardPolicy.OFF):
if num_replicas_in_sync is None:
num_replicas_in_sync = 1
if isinstance(dataset, dataset_ops.DatasetV1):
return distribute._AutoShardDatasetV1(dataset, num_shards, index,
num_replicas_in_sync)
else:
return distribute._AutoShardDataset(dataset, num_shards, index,
num_replicas_in_sync)
else:
return dataset
此时流程图如下,可以看到数据集功能逐渐加强,首先是 _RemoteDataset,然后升级到 _AutoShardDataset。

图 3 建立数据集
数据集因为上面涉及了几种数据集,所以我们要再仔细梳理一下这其中的关系,其具体可以理解为在数据集 DatasetV2 基础之上逐步添加功能,最终返回给用户。
_RemoteDataset 对应远端数据集。
_RemoteDataset 继承了 DatasetSource。dataset_ops.DatasetSource 继承 DatasetV2(就是data.Dataset)。
class DatasetSource(DatasetV2):
"""Abstract class representing a dataset with no inputs."""
@tf_export("data.Dataset", v1=[])
@six.add_metaclass(abc.ABCMeta)
class DatasetV2(collections_abc.Iterable, tracking_base.Trackable,
composite_tensor.CompositeTensor):
具体 _RemoteDataset 如下,其利用with ops.device(device)把数据集设定到远端设备上。
class _RemoteDataset(dataset_ops.DatasetSource):
"""Creates a dataset on a given device given a graph def."""
def __init__(self, graph_def, device, element_spec):
self._elem_spec = element_spec
with ops.device(device): # 这里会把数据集设定到远端设备上
variant_tensor = ged_ops.dataset_from_graph(graph_def)
super(_RemoteDataset, self).__init__(variant_tensor)
@property
def element_spec(self):
return self._elem_spec
_RebatchDataset 代表重新分批,具体使用参见如下:
ds = tf.data.Dataset.range(8)
ds = ds.batch(4)
ds = _RebatchDataset(ds, batch_sizes=[2, 1, 1])
for elem in ds:
print(elem)
>> [0, 1], [2], [3], [4, 5], [6], [7]
ds = tf.data.Dataset.range(16)
ds = ds.batch(4)
ds = _RebatchDataset(ds, batch_sizes=[6])
for elem in ds:
print(elem)
>> [0, 1, 2, 3, 4, 5], [6, 7, 8, 9, 10, 11], [12, 13, 14, 15]
具体代码如下:
class _RebatchDataset(dataset_ops.UnaryDataset):
"""A Dataset that rebatches elements from its input into new batch sizes.
_RebatchDataset(input_dataset, batch_sizes) is functionally equivalent to
input_dataset.unbatch().batch(N), where the value of N cycles through the
batch_sizes input list. The elements produced by this dataset have the same
rank as the elements of the input dataset.
"""
def __init__(self, input_dataset, batch_sizes, drop_remainder=False):
"""Creates a _RebatchDataset.
Args:
input_dataset: Dataset to rebatch.
batch_sizes: A tf.int64 scalar or vector, representing the size of
batches to produce. If this argument is a vector, these values are
cycled through in order.
drop_remainder: (Optional.) A tf.bool scalar tf.Tensor, representing
whether the last batch should be dropped in the case it has fewer than
batch_sizes[cycle_index] elements; the default behavior is not to drop
the smaller batch.
"""
self._input_dataset = input_dataset
self._batch_sizes = ops.convert_to_tensor(
batch_sizes, dtype=dtypes.int64, name="batch_sizes")
self._drop_remainder = ops.convert_to_tensor(
drop_remainder, dtype=dtypes.bool, name="drop_remainder")
new_batch_dim = self._compute_static_batch_dim()
self._element_spec = nest.map_structure(
lambda ts: ts._unbatch()._batch(new_batch_dim),
dataset_ops.get_structure(input_dataset))
# auto_shard rewrite assumes that there's normalize_to_dense before
# rebatch_dataset.
# LINT.IfChange
input_dataset = dataset_ops.normalize_to_dense(input_dataset)
variant_tensor = ged_ops.rebatch_dataset_v2(
input_dataset._variant_tensor,
batch_sizes=batch_sizes,
drop_remainder=drop_remainder,
**self._flat_structure)
super(_RebatchDataset, self).__init__(input_dataset, variant_tensor)
def _compute_static_batch_dim(self):
"""Computes the static batch dimension of a dataset if it can be determined.
Given the _RebatchDataset parameters, determines the batch dimension of this
dataset statically. Returns None if this cannot be determined or is
variable.
Returns:
An integer representing the batch dimension of the dataset. If it cannot
be determined statically, returns None.
Raises:
ValueError: The batch_sizes parameter is malformed, input_dataset is
not batched, or input_dataset batch sizes are incompatible with each
other.
"""
new_batch_dim = tensor_util.constant_value(self._batch_sizes)
if new_batch_dim is None:
return None
if isinstance(new_batch_dim, np.ndarray):
if len(new_batch_dim.shape) == 1:
if np.all(new_batch_dim == new_batch_dim[0]):
new_batch_dim = new_batch_dim[0]
else:
return None
elif len(new_batch_dim.shape) > 1:
raise ValueError(
f"Invalid batch_sizes. Expected batch_sizes to be a scalar or "
f"a vector. Received batch_sizes of rank "
f"{len(new_batch_dim.shape)}."
)
if self._may_form_partial_batches(new_batch_dim):
return None
return new_batch_dim
def _may_form_partial_batches(self, desired_batch_size):
"""Returns whether this dataset may form partial batches."""
if tensor_util.constant_value(self._drop_remainder):
return False
def get_batch_dim(type_spec):
shape = type_spec._to_legacy_output_shapes()
if not isinstance(shape, tensor_shape.TensorShape):
return None
if shape.rank is None:
return None
return shape.dims[0].value
input_batch_dims = [
get_batch_dim(ts)
for ts in nest.flatten(dataset_ops.get_structure(self._input_dataset))
]
known_input_batch_dims = [d for d in input_batch_dims if d is not None]
if not known_input_batch_dims:
return True
known_input_batch_dims = np.asarray(known_input_batch_dims)
return known_input_batch_dims[0] % desired_batch_size != 0
@property
def element_spec(self):
return self._element_spec
_AutoShardDataset 对数据集自动分片。
这个数据集接收了一个现有的数据集,并尝试自动找出如何在多工作者的情况下使用图来对数据集进行分片。
-
如果 AutoShardPolicy 设置为 FILE,它就会沿着数据集图向上走,直到找到一个读者数据集(reader dataset),然后在该节点之前插入一个 ShardDataset op,这样每个工作者只能看到一些文件。
-
如果 AutoShardPolicy 设置为 DATA,它会在输入流水线的末端,在 terminal PrefetchDataset(如果有)之前,插入一个 ShardDataset 操作。此外,如果输入管道中有 RebatchDatasetV2,出于正确性考虑,它将被写入 legacy RebatchDataset,因为 RebatchDatasetV2 与数据分片不兼容。
-
如果 AutoShardPolicy 设置为 AUTO,它将尝试进行基于文件的分片。如果找不到读者数据集,它就会退回到进行基于数据的分片。
-
如果 AutoShardPolicy 被设置为 OFF,则不进行处理。
class _AutoShardDataset(dataset_ops.UnaryDataset):
"""A Dataset that shards the Dataset automatically.
This dataset takes in an existing dataset and tries to automatically figure
out how to shard the dataset in a multi-worker scenario using graph rewrites.
If the AutoShardPolicy is set to FILE, it walks up the dataset graph until
it finds a reader dataset, then inserts a ShardDataset op before that node
so that each worker only sees some files.
If the AutoShardPolicy is set to DATA, it inserts a ShardDataset op at the
end of the input pipeline, before any terminal PrefetchDataset if there is
one. Additionally, if there is a RebatchDatasetV2 in the input pipeline, it
is written to legacy RebatchDataset for correctness reasons, since
RebatchDatasetV2 is incompatible with data sharding.
If the AutoShardPolicy is set to AUTO, it tries to do file-based sharding.
If it cannot find a reader dataset, it falls back to doing data-based
sharding.
If the AutoShardPolicy is set to OFF, it does nothing.
Attributes:
num_workers: Total number of workers to shard this dataset across.
index: The current worker index (out of the total number of workers) this
dataset is for.
num_replicas: The total number of replicas across all workers. This is used
only when sharding by data (either DATA or AUTO) in order to rewrite
RebatchDatasetV2 to RebatchDataset.
Raises:
NotFoundError: If we cannot find a suitable reader dataset to begin
automatically sharding the dataset.
"""
def __init__(self, input_dataset, num_workers, index, num_replicas=None):
self._input_dataset = input_dataset
self._element_spec = input_dataset.element_spec
variant_tensor = ged_ops.auto_shard_dataset(
self._input_dataset._variant_tensor,
num_workers=num_workers,
index=index,
auto_shard_policy=int(
input_dataset.options().experimental_distribute.auto_shard_policy),
num_replicas=num_replicas,
**self._flat_structure)
super(_AutoShardDataset, self).__init__(input_dataset, variant_tensor)
@property
def element_spec(self):
return self._element_spec
在 tensorflow\core\grappler\optimizers\data\auto_shard.cc 之中有如下做自动分片的代码,有兴趣的读者可以自行深入。
Status ApplyAutoShard(const NodeDef& sink_node, int64_t num_workers,
int64_t index, AutoShardPolicy policy,
int64_t num_replicas, MutableGraphView* graph,
AutoShardPolicy* policy_applied) {
*policy_applied = policy;
FunctionLibraryDefinition flib(OpRegistry::Global(),
graph->graph()->library());
switch (policy) {
case AutoShardPolicy::OFF:
return Status::OK();
case AutoShardPolicy::FILE:
return ShardByFile(sink_node, num_workers, index, &flib, graph);
case AutoShardPolicy::DATA:
return ShardByData(sink_node, num_workers, index, num_replicas, graph);
case AutoShardPolicy::HINT:
return ShardByHint(sink_node, num_workers, index, num_replicas, graph);
case AutoShardPolicy::AUTO:
default:
Status s = ShardByFile(sink_node, num_workers, index, &flib, graph);
if (errors::IsNotFound(s)) {
LOG(WARNING) << "AUTO sharding policy will apply DATA sharding policy "
"as it failed to apply FILE sharding policy because of "
"the following reason: "
<< s.error_message();
*policy_applied = AutoShardPolicy::DATA;
return ShardByData(sink_node, num_workers, index, num_replicas, graph);
}
*policy_applied = AutoShardPolicy::FILE;
return s;
}
}
具体关系如下,DistributedDataset 成员变量 _cloned_datasets 列表包括了多个 _AutoShardDataset,每个针对一个 Worker。

图 4 数据集关系
迭代数据我们接下来看看 DistributedDataset 如何迭代,iter 方法会针对每个 worker 建立一个 iterator,最后统一返回一个 DistributedIterator。
def __iter__(self):
canonicalize_devices = getattr(self._strategy, "_canonicalize_devices", True)
# 会针对每个 worker 建立一个 iterator
worker_iterators = _create_iterators_per_worker(
self._cloned_datasets,
self._input_workers,
enable_legacy_iterators=False,
options=self._options,
canonicalize_devices=canonicalize_devices)
# 统一返回一个 DistributedIterator
iterator = DistributedIterator(
self._input_workers,
worker_iterators,
self._strategy,
cardinality=self._cardinality,
enable_get_next_as_optional=self._enable_get_next_as_optional,
options=self._options)
iterator._element_spec = self._element_spec # pylint: disable=protected-access
# When async eager is enabled, sometimes the iterator may not finish
# initialization before passing to a multi device function, add a sync point
# here to make sure all underlying iterators are initialized.
if context.executing_eagerly():
context.async_wait()
return iterator
_create_iterators_per_worker 为每个 worker 建立一个 multidevice iterator。
def _create_iterators_per_worker(worker_datasets,
input_workers,
enable_legacy_iterators,
options=None,
canonicalize_devices=False):
"""Create a multidevice iterator on each of the workers."""
iterators = []
for i, worker in enumerate(input_workers.worker_devices):
with ops.device(worker):
worker_devices = input_workers.compute_devices_for_worker(i)
if tf2.enabled() and not enable_legacy_iterators:
iterator = _SingleWorkerOwnedDatasetIterator(
dataset=worker_datasets[i],
worker=worker,
devices=worker_devices,
options=options,
canonicalize_devices=canonicalize_devices)
else:
iterator = _SingleWorkerDatasetIterator(worker_datasets[i], worker,
worker_devices, options)
iterators.append(iterator)
return iterators
_SingleWorkerDatasetIterator 则会建立 MultiDeviceIterator。
class _SingleWorkerDatasetIterator(_SingleWorkerDatasetIteratorBase):
"""Iterator for a single DistributedDatasetV1 instance."""
def _make_iterator(self):
"""Make appropriate iterator on the dataset."""
with ops.device(self._worker):
if self._options is not None:
self._iterator = multi_device_iterator_ops.MultiDeviceIterator(
self._dataset,
self._devices,
max_buffer_size=self._options.experimental_per_replica_buffer_size,
prefetch_buffer_size=self._options
.experimental_per_replica_buffer_size)
else:
self._iterator = multi_device_iterator_ops.MultiDeviceIterator(
self._dataset,
self._devices,
)
def initialize(self):
"""Initialize underlying iterator.
In eager execution, this simply recreates the underlying iterator.
In graph execution, it returns the initializer ops for the underlying
iterator.
Returns:
A list of any initializer ops that should be run.
"""
if ops.executing_eagerly_outside_functions():
self._iterator._eager_reset() # pylint: disable=protected-access
return []
else:
return [self._iterator.initializer]
@property
def output_classes(self):
return dataset_ops.get_legacy_output_classes(self._iterator)
@property
def output_shapes(self):
return dataset_ops.get_legacy_output_shapes(self._iterator)
@property
def output_types(self):
return dataset_ops.get_legacy_output_types(self._iterator)
具体逻辑如下:
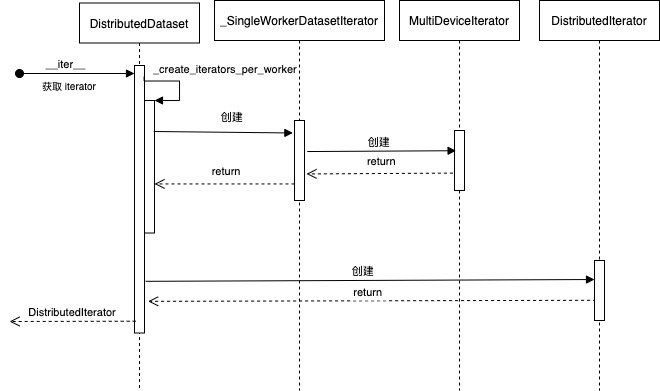
图 5 获取迭代器
2.1.7 DistributedIterator我们接下来看 DistributedIterator。
DistributedIteratorDistributedIterator 其实没有完成多少实际工作,主要功能是在基类 DistributedIteratorBase。
class DistributedIterator(DistributedIteratorBase,
composite_tensor.CompositeTensor):
"""Input Iterator for a distributed dataset."""
def __init__(self,
input_workers=None,
iterators=None,
strategy=None,
components=None,
element_spec=None,
cardinality=cardinality_lib.UNKNOWN,
enable_get_next_as_optional=False,
options=None):
error_message = ("Either input_workers or "
"both components and element_spec need to be "
"provided.")
self._options = options
if iterators is None:
if (components is None or element_spec is None):
raise ValueError(error_message)
self._element_spec = element_spec
self._input_workers = input_workers
self._iterators = components
self._strategy = strategy
self._cardinality = cardinality
self._enable_get_next_as_optional = enable_get_next_as_optional
else:
if (components is not None and element_spec is not None):
raise ValueError(error_message)
super(DistributedIterator,
self).__init__(input_workers, iterators, strategy, cardinality,
enable_get_next_as_optional)
@property
def element_spec(self):
# When partial batch handling is enabled, always set the batch dimension to
# None, otherwise we just follow element_spec of the underlying dataset
# (whose batch dimension may also be None). This is because with partial
# batching handling we could always produce empty batches.
if (self._enable_get_next_as_optional and
self._strategy.extended._in_multi_worker_mode()): # pylint: disable=protected-access
return nest.map_structure(
_rebatch_as_dynamic, self._element_spec, expand_composites=False)
return self._element_spec
@property
def _type_spec(self):
# Note that we use actual element_spec instead of the rebatched-as-dynamic
# one to create DistributedIteratorSpec, to be consistent with the
# underlying iterators' specs.
return DistributedIteratorSpec(self._input_workers, self._element_spec,
self._strategy,
self._options,
self._cardinality,
self._enable_get_next_as_optional)
DistributedIteratorBase 的主要方法和普通迭代器相同。
class DistributedIteratorBase(DistributedIteratorInterface):
"""Common implementation for all input iterators."""
# pylint: disable=super-init-not-called
def __init__(self, input_workers, iterators, strategy, cardinality,
enable_get_next_as_optional):
self._iterators = iterators
self._input_workers = input_workers
self._strategy = strategy
self._cardinality = cardinality
self._enable_get_next_as_optional = enable_get_next_as_optional
def next(self):
return self.__next__()
def __next__(self):
try:
return self.get_next()
except errors.OutOfRangeError:
raise StopIteration
def __iter__(self):
return self
get_next 完成了获取数据功能,具体我们关注一下 _create_per_replica,这里看起来和分布式最为相关,具体是:
- 找到所有 worker 信息。
- 计算副本数目。
- 获取数据,并且重新组合。
def get_next(self, name=None):
"""Returns the next input from the iterator for all replicas."""
with distribution_strategy_context.enter_or_assert_strategy(
self._strategy):
if not self._enable_get_next_as_optional:
return self._get_next_no_partial_batch_handling(name)
optional_list = []
# 找到 worker 信息
for i, worker in enumerate(self._input_workers.worker_devices):
with ops.device(worker):
optional_list.append(self._iterators[i].get_next_as_optional_list())
# 计算副本数目
num_replicas_with_values = _calculate_replicas_with_values(
self._strategy, self._input_workers, optional_list)
# 获取数据,并且重新组合
def _value_or_dummy():
value_list = _get_value_or_dummy( # 获取数据
self._input_workers, optional_list, produce_dummy=True)
return _create_per_replica(value_list, self._strategy)
def _eof():
# Optional.get_value raises InvalidArgumentError when there's no value,
# so we need to call GetNext to raise EOFError.
return self._get_next_no_partial_batch_handling()
return control_flow_ops.cond(
num_replicas_with_values > 0, _value_or_dummy, _eof, strict=True)
_calculate_replicas_with_values 计算出有数据的副本数目。
def _calculate_replicas_with_values(strategy, input_workers, optional_list):
"""Calcualates the number of replicas that have values.
Args:
strategy: the tf.distribute.Strategy.
input_workers: the InputWorkers.
optional_list: a list of lists tf.experimental.Optional. The values from
each compute device grouped by the input device.
Returns:
A scalar Tensor.
"""
worker_has_values = []
for worker, optionals in zip(input_workers.worker_devices, optional_list):
with ops.device(worker):
device_has_values = [
math_ops.cast(v.has_value(), dtypes.int64) for v in optionals
]
worker_has_values.append(
math_ops.reduce_sum(device_has_values, keepdims=True))
client_has_values = math_ops.reduce_sum(worker_has_values, keepdims=True)
if strategy.extended._in_multi_worker_mode():
global_has_values = strategy.reduce(
reduce_util.ReduceOp.SUM, client_has_values, axis=None)
return array_ops.reshape(global_has_values, [])
else:
return array_ops.reshape(client_has_values, [])
_get_value_or_dummy 获取具体数据。
def _get_value_or_dummy(input_workers, optional_list, produce_dummy):
"""Returns the value of the optionals or dummy values.
Args:
input_workers: the InputWorkers.
optional_list: a list of lists tf.experimental.Optional. The values from
each compute device grouped by the input device.
produce_dummy: a bool. Whether to produce dummy tensors when the optional
doesn't have a value.
Returns:
A flatten list of Tensors.
"""
value_list = []
for i, worker in enumerate(input_workers.worker_devices): # 遍历 worker
with ops.device(worker):
devices = input_workers.compute_devices_for_worker(i) # 遍历 worker 之中的设备
for j, device in enumerate(devices):
with ops.device(device):
if produce_dummy:
value_list.append( # 累计数据
control_flow_ops.cond(
optional_list[i][j].has_value(),
lambda: optional_list[i][j].get_value(),
lambda: _dummy_tensor_fn(optional_list[i][j].element_spec),
strict=True,
))
else:
value_list.append(optional_list[i][j].get_value())
return value_list
_create_per_replica 完成了具体数据的重新组合。
- 对于 OneDeviceStrategy 以外的策略,它会创建一个 PerReplica,其类型规格被设置为数据集的元素规格。这有助于避免对部分批次进行回溯。当多个客户在不同的时间回溯时,回溯对于多客户端来说是有问题的,因为回溯改变了 tf.function 的集合键(collective keys),并导致客户之间的不匹配。
- 对于单客户策略,_create_per_replica 只是调用 distribution_utils.regroup()。
def _create_per_replica(value_list, strategy):
"""Creates a PerReplica.
For strategies other than OneDeviceStrategy, it creates a PerReplica whose
type spec is set to the element spec of the dataset. This helps avoid
retracing for partial batches. Retracing is problematic for multi client when
different client retraces different time, since retracing changes the
collective keys in the tf.function, and causes mismatches among clients.
For single client strategies, this simply calls distribute_utils.regroup().
Args:
value_list: a list of values, one for each replica.
strategy: the tf.distribute.Strategy.
Returns:
a structure of PerReplica.
"""
always_wrap = _always_wrap(strategy)
per_replicas = distribute_utils.regroup(value_list, always_wrap=always_wrap)
return per_replicas
具体逻辑如下:
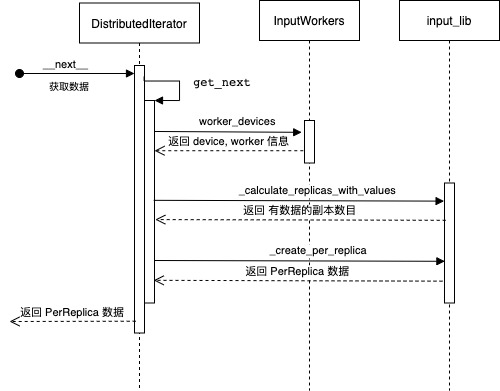
图 6 迭代器处理数据
至此,对于读取数据我们其实已经有了一个比较基础的分析,其中最主要几个类之间的逻辑如下:
- InputWorker 的作用是从输入 worker 设备到计算设备的 1-to-many mapping,可以认为 InputWorker 把 worker 绑定到设备之上。
- DistributedDataset 就是数据集了,其内部有一系列复杂处理,首先把数据集复制到一系列设备上,然后对数据集进行一系列加强,首先是 _RemoteDataset,然后升级到 _AutoShardDataset。
- DistributedDataset 的 iter 方法会针对每个 worker 建立一个 iterator,最后统一返回一个 DistributedIterator。
- DistributedIterator 的 get_next 方法完成了获取数据功能,用 _create_per_replica 来举例, 具体操作是:
- 找到所有 worker 信息。
- 计算副本数目。
- 获取数据,并且重新组合。
具体如下图(只是大致逻辑概念,仅仅为了更好的说明),数字与下图之中对应。
- 1.InputWorkers 提供了worker和设备的映射关系。
- 2.数据集被分配到各个设备或者说worker之上。
- 3.每个 worker 建立一个 iterator,最后统一返回一个 DistributedIterator。
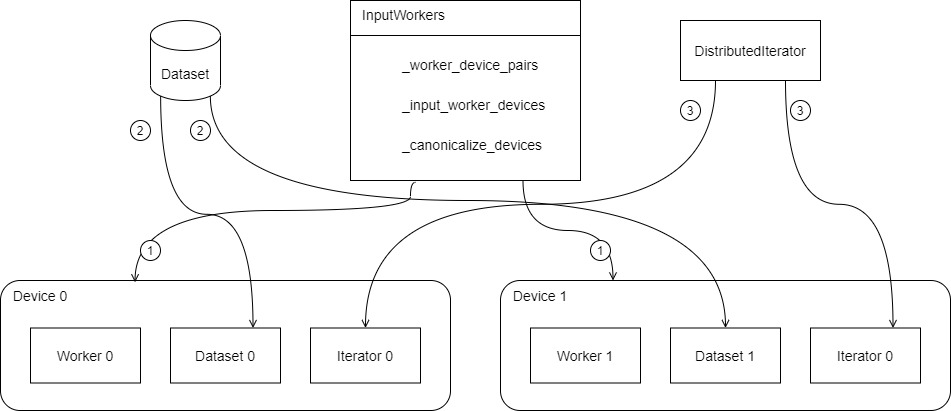
如果上述的批量分割和数据集分片逻辑(即,直接读取数据集逻辑)不能满足需求,用户可以使用tf.distribution.Strategy.distribution_datasets_from_function,它不会做任何自动的批量分割或分片。
2.2.1 StrategyBase我们首先来到 StrategyBase。distribute_datasets_from_function 会分发 tf.data.Dataset,这些实例是通过执行dataset_fn 来创建的。
用户传入的参数 dataset_fn 是一个输入函数,它有 tf.distribution.InputContext 参数,并返回一个 tf.data.Dataset 实例。从 dataset_fn 返回的数据集默认已经按每个副本的批处理量(即全局批处理量除以同步的副本数量)进行分批,也进行了分片处理。
tf.distribution.Strategy.distribution_datasets_from_function 不会对输入函数返回的 tf.dataset 实例进行批处理或分片。dataset_fn 将在每个 worker 的 CPU 设备上被调用,每次调用都会生成一个数据集,在此调用之中,该 worker 的每个副本都会从数据集获取一批输入(例如,如果一个 worke r有两个副本,每一步都会从 Dataset 中提取两个批次)。在几种情况下会使用这个方法。
- 首先,它允许您指定您自己的批处理和分片逻辑,相比之下,tf.distribution.experimental_distribute_dataset 会为您做批处理和分片。例如,当 experimental_distribute_dataset 无法对输入文件进行分片时,可以用这个方法来手动分片(避免 experimental_distribute_dataset 的缓慢回退行为)。
- 在无限数据集的情况下,可以通过创建数据集副本来完成分片,这些副本只在随机种子上有所不同。
dataset_fn 应该接受一个 tf.distribution.InputContext 实例,此实例包括了关于批处理和输入副本的信息。由dataset_fn 返回的 tf.data.Dataset 应该有一个每副本(per-replica)的批次大小,这与 experimental_distribute_dataset 不同,后者使用全局批次大小。全局批次大小可以通过 input_context.get_per_replica_batch_size 来计算得到。
def distribute_datasets_from_function(self, dataset_fn, options=None):
"""
Args:
dataset_fn: A function taking a tf.distribute.InputContext instance and
returning a tf.data.Dataset.
options: tf.distribute.InputOptions used to control options on how this
dataset is distributed.
Returns:
A tf.distribute.DistributedDataset.
"""
distribution_strategy_input_api_counter.get_cell(
self.__class__.__name__,
"distribute_datasets_from_function").increase_by(1)
return self._extended._distribute_datasets_from_function(
dataset_fn, options)
我们依然用MirroredStrategy作为例子来看。_distribute_datasets_from_function 这里会初始化 Input worker,然后配置上下文,读取数据。
def _distribute_datasets_from_function(self, dataset_fn, options):
input_workers = self._input_workers_with_options(options) # 构建 InputWorkers
input_contexts = []
num_workers = input_workers.num_workers
for i in range(num_workers):
input_contexts.append(distribute_lib.InputContext(
num_input_pipelines=num_workers,
input_pipeline_id=i,
num_replicas_in_sync=self._num_replicas_in_sync))
return input_lib.get_distributed_datasets_from_function(
dataset_fn, input_workers, input_contexts, self._container_strategy(),
options)
_input_workers_with_options 建立了 InputWorkers。
def _input_workers_with_options(self, options=None):
if not options:
return input_lib.InputWorkers(self._input_workers_devices)
if (options.experimental_replication_mode ==
distribute_lib.InputReplicationMode.PER_REPLICA):
if options.experimental_place_dataset_on_device:
self._input_workers_devices = (
tuple(
(device_util.canonicalize(d, d), (d,)) for d in self._devices))
else:
self._input_workers_devices = (
tuple((device_util.canonicalize("/device:CPU:0", d), (d,))
for d in self._devices))
return input_lib.InputWorkers(self._input_workers_devices)
else:
if not options.experimental_fetch_to_device:
return input_lib.InputWorkers([
(host_device, (host_device,) * len(compute_devices))
for host_device, compute_devices in self._input_workers_devices
])
else:
return input_lib.InputWorkers(self._input_workers_devices)
input_contexts 是一个包装输入函数所需信息的类,是一个传递给用户输入函数的上下文类,包含了关于计算副本和输入流水线的信息。
-
利用计算副本的数量(同步训练中)可以让我们从每个副本所需的全局批次大小中计算出本地批次大小。
-
利用输入流水线的信息则可以用来在每个副本中返回不同的输入子集(例如,分片输入流水线,使用不同的 input 源等)。
@tf_export("distribute.InputContext")
class InputContext(object):
"""A class wrapping information needed by an input function.
This is a context class that is passed to the user's input function and
contains information about the compute replicas and input pipelines. The
number of compute replicas (in sync training) helps compute the local batch
size from the desired global batch size for each replica. The input pipeline
information can be used to return a different subset of the input in each
replica (for e.g. shard the input pipeline, use a different input
source etc).
"""
__slots__ = [
"_num_input_pipelines", "_input_pipeline_id", "_num_replicas_in_sync"
]
def __init__(self,
num_input_pipelines=1,
input_pipeline_id=0,
num_replicas_in_sync=1):
"""Initializes an InputContext object.
Args:
num_input_pipelines: the number of input pipelines in a cluster.
input_pipeline_id: the current input pipeline id, should be an int in
[0,num_input_pipelines).
num_replicas_in_sync: the number of replicas that are in sync.
"""
self._num_input_pipelines = num_input_pipelines
self._input_pipeline_id = input_pipeline_id
self._num_replicas_in_sync = num_replicas_in_sync
@property
def num_replicas_in_sync(self):
"""Returns the number of compute replicas in sync."""
return self._num_replicas_in_sync
@property
def input_pipeline_id(self):
"""Returns the input pipeline ID."""
return self._input_pipeline_id
@property
def num_input_pipelines(self):
"""Returns the number of input pipelines."""
return self._num_input_pipelines
def get_per_replica_batch_size(self, global_batch_size):
"""Returns the per-replica batch size.
Args:
global_batch_size: the global batch size which should be divisible by
num_replicas_in_sync.
Returns:
the per-replica batch size.
Raises:
ValueError: if global_batch_size not divisible by
num_replicas_in_sync.
"""
if global_batch_size % self._num_replicas_in_sync != 0:
raise ValueError("The global_batch_size %r is not divisible by "
"num_replicas_in_sync %r " %
(global_batch_size, self._num_replicas_in_sync))
return global_batch_size // self._num_replicas_in_sync
def __str__(self):
return "tf.distribute.InputContext(input pipeline id {}, total: {})".format(
self.input_pipeline_id, self.num_input_pipelines)
get_distributed_datasets_from_function 从给定的输入函数返回一个分布式数据集。这是一个通用函数,所有策略都使用它来返回分布式数据集。取决于在 TF 1 还是 TF 2 的背景下而返回不同的分布式数据集实例,从而分布式数据集实例的 API 也有所不同。
def get_distributed_datasets_from_function(dataset_fn,
input_workers,
input_contexts,
strategy,
options=None):
"""Returns a distributed dataset from the given input function.
This is a common function that is used by all strategies to return a
distributed dataset. The distributed dataset instance returned is different
depending on if we are in a TF 1 or TF 2 context. The distributed dataset
instances returned differ from each other in the APIs supported by each of
them.
Args:
dataset_fn: a function that returns a tf.data.Dataset instance.
input_workers: an InputWorkers object which specifies devices on which
iterators should be created.
input_contexts: A list of InputContext instances to be passed to call(s)
to dataset_fn. Length and order should match worker order in
worker_device_pairs.
strategy: a tf.distribute.Strategy object, used to run all-reduce to
handle last partial batch.
options: Default is None. tf.distribute.InputOptions used to control
options on how this dataset is distributed.
Returns:
A distributed dataset instance.
Raises:
ValueError: if options.experimental_replication_mode and
options.experimental_place_dataset_on_device are not consistent
"""
if tf2.enabled():
return DistributedDatasetsFromFunction(input_workers, strategy,
input_contexts, dataset_fn, options)
else:
return DistributedDatasetsFromFunctionV1(input_workers, strategy,
input_contexts, dataset_fn,
options)
DistributedDatasetsFromFunction 会调用 _create_datasets_from_function_with_input_context。
class DistributedDatasetsFromFunction(_IterableInput,
composite_tensor.CompositeTensor):
"""Inputs created from dataset function."""
def __init__(self,
input_workers,
strategy,
input_contexts=None,
dataset_fn=None,
options=None,
components=None,
element_spec=None):
"""Makes an iterable from datasets created by the given function.
Args:
input_workers: an InputWorkers object.
strategy: a tf.distribute.Strategy object, used to run all-reduce to
handle last partial batch.
input_contexts: A list of InputContext instances to be passed to call(s)
to dataset_fn. Length and order should match worker order in
worker_device_pairs.
dataset_fn: A function that returns a Dataset given an InputContext.
Either dataset_fn or components should be passed to construct
DistributedDatasetsFromFunction. Use this when constructing
DistributedDataset using a function. Use components when constructing
using DistributedDatasetsFromFunctionSpec.
options: tf.distribute.InputOptions used to control options on how this
dataset is distributed.
components: datasets when DistributedDatasetsFromFunction is constructed
from DistributedDatasetsFromFunctionSpec. Only one of dataset or
components should be passed.
element_spec: element spec for DistributedDataset when constructing from
DistributedDatasetSpec. This will be used to set the element_spec for
DistributedDatasetsFromFunctionSpec and verified against element_spec
from components.
"""
super(DistributedDatasetsFromFunction, self).__init__(
input_workers=input_workers)
self._input_workers = input_workers
self._strategy = strategy
self._options = options
if dataset_fn is not None:
self._datasets, element_spec = (
_create_datasets_from_function_with_input_context(
input_contexts, self._input_workers, dataset_fn))
self._element_spec = _create_distributed_tensor_spec(
self._strategy, element_spec)
else:
self._element_spec = element_spec
self._datasets = components
self._enable_get_next_as_optional = _enable_get_next_as_optional(
self._strategy, self._datasets[0])
_create_datasets_from_function_with_input_context 函数会正式构建数据集。
def _create_datasets_from_function_with_input_context(input_contexts,
input_workers,
dataset_fn):
"""Create device datasets per worker given a dataset function."""
datasets = []
for i, ctx in enumerate(input_contexts): #遍历上下文
worker = input_workers.worker_devices[i] # 遍历 worker
with ops.device(worker):
dataset = dataset_fn(ctx) # 获取数据
datasets.append(dataset)
return datasets, dataset.element_spec
具体逻辑如下:

图 7 通过方法构建数据
2.3 高层使用 2.3.1 Keras我们首先看看 Keras 之中的使用。在 tensorflow/python/keras/distribute/distributed_training_utils_v1.py 之中有如下方法,这里会生成策略的数据迭代器。
def get_iterator(dataset, distribution_strategy):
with distribution_strategy.scope():
iterator = distribution_strategy.make_dataset_iterator(dataset)
initialize_iterator(iterator, distribution_strategy)
return iterator
tensorflow/python/distribute/distribute_lib.py 则会使用 _extended,比如 StrategyBase 有:
def make_dataset_iterator(self, dataset):
"""DEPRECATED TF 1.x ONLY."""
return self._extended._make_dataset_iterator(dataset)
对于 StrategyV1 有:
def make_dataset_iterator(self, dataset):
"""Makes an iterator for input provided via dataset.
DEPRECATED: This method is not available in TF 2.x.
Data from the given dataset will be distributed evenly across all the
compute replicas. We will assume that the input dataset is batched by the
global batch size. With this assumption, we will make a best effort to
divide each batch across all the replicas (one or more workers).
If this effort fails, an error will be thrown, and the user should instead
use make_input_fn_iterator which provides more control to the user, and
does not try to divide a batch across replicas.
The user could also use make_input_fn_iterator if they want to
customize which input is fed to which replica/worker etc.
Args:
dataset: tf.data.Dataset that will be distributed evenly across all
replicas.
Returns:
An tf.distribute.InputIterator which returns inputs for each step of the
computation. User should call initialize on the returned iterator.
"""
return self._extended._make_dataset_iterator(dataset)
来到 tensorflow/python/distribute/mirrored_strategy.py,则有如下代码生成 DatasetIterator:
def _make_dataset_iterator(self, dataset):
return input_lib.DatasetIterator(
dataset,
self._input_workers,
self._container_strategy(),
num_replicas_in_sync=self._num_replicas_in_sync)
具体逻辑如下:

图 9 Keras 使用
2.2.2 其他路径另一条执行路径如下:
def single_loss_example(optimizer_fn, distribution, use_bias=False,
iterations_per_step=1):
"""Build a very simple network to use in tests and examples."""
def dataset_fn():
return dataset_ops.Dataset.from_tensors([[1.]]).repeat()
optimizer = optimizer_fn()
layer = core.Dense(1, use_bias=use_bias)
def loss_fn(ctx, x):
del ctx
y = array_ops.reshape(layer(x), []) - constant_op.constant(1.)
return y * y
single_loss_step = step_fn.StandardSingleLossStep(
dataset_fn, loss_fn, optimizer, distribution, iterations_per_step)
StandardSingleLossStep 调用如下:
class StandardSingleLossStep(StandardInputStep):
"""A step function that implements a training step for a feed forward network.
An instance of this class is intended to be used as a callable:
```python
...
step = step_fn.StandardSingleLossStep(
dataset, loss_fn, optimizer, distribution)
# Run a single training step on a given DistributionStrategy:
step(distribution)
...
```
Args:
dataset_fn: a function that returns a tf.data Dataset that produces the
input for the model.
loss_fn: a function that takes a context and inputs as arguments. It returns
the loss for those inputs. context is an instance of
values.MultiStepContext that will be passed when loss_fn is run.
context can be used to specify the outputs to be returned from
loss_fn, among other things.
optimizer: an optimizer that implements an update rule.
distribution: a DistributionStrategy object.
"""
def __init__(self, dataset_fn, loss_fn, optimizer, distribution,
iterations_per_step=1):
super(StandardSingleLossStep, self).__init__(dataset_fn, distribution)
self._loss_fn = loss_fn
self._optimizer = optimizer
self._iterations_per_step = iterations_per_step
def __call__(self):
with self._distribution.scope():
def step_fn(ctx, inputs):
"""Function to run one iteration with one input."""
gradients_fn = backprop.implicit_grad(self._loss_fn)
gradients_fn = optimizer_lib.get_filtered_grad_fn(gradients_fn)
grads_and_vars = self.distribution.extended.call_for_each_replica(
gradients_fn, args=(ctx, inputs))
# If threads use layers, then we need to run the first step
# sequentially, so that layers.build() is not executed in parallel.
# Otherwise, multiple sets of mirrored variables are going to be
# created.
return self._optimizer._distributed_apply( # pylint: disable=protected-access
self.distribution, grads_and_vars)
ctx = self.distribution.extended.experimental_run_steps_on_iterator(
step_fn, self._iterator, self._iterations_per_step)
return ctx.run_op
StandardInputStep 这里生成了 _iterator。
class StandardInputStep(Step):
"""Step with a standard implementation of input handling.
Args:
dataset_fn: a function that returns a tf.data Dataset that produces the
input for the model.
"""
def __init__(self, dataset_fn, distribution):
super(StandardInputStep, self).__init__(distribution)
self._iterator = distribution.make_input_fn_iterator(lambda _: dataset_fn())
def initialize(self):
return self._iterator.initializer
StrategyV1之中有:
def make_input_fn_iterator(self, # pylint: disable=useless-super-delegation
input_fn,
replication_mode=InputReplicationMode.PER_WORKER):
"""Returns an iterator split across replicas created from an input function.
DEPRECATED: This method is not available in TF 2.x.
The input_fn should take an tf.distribute.InputContext object where
information about batching and input sharding can be accessed:
```
def input_fn(input_context):
batch_size = input_context.get_per_replica_batch_size(global_batch_size)
d = tf.data.Dataset.from_tensors([[1.]]).repeat().batch(batch_size)
return d.shard(input_context.num_input_pipelines,
input_context.input_pipeline_id)
with strategy.scope():
iterator = strategy.make_input_fn_iterator(input_fn)
replica_results = strategy.experimental_run(replica_fn, iterator)
```
The tf.data.Dataset returned by input_fn should have a per-replica
batch size, which may be computed using
input_context.get_per_replica_batch_size.
Args:
input_fn: A function taking a tf.distribute.InputContext object and
returning a tf.data.Dataset.
replication_mode: an enum value of tf.distribute.InputReplicationMode.
Only PER_WORKER is supported currently, which means there will be
a single call to input_fn per worker. Replicas will dequeue from the
local tf.data.Dataset on their worker.
Returns:
An iterator object that should first be .initialize()-ed. It may then
either be passed to strategy.experimental_run() or you can
iterator.get_next() to get the next value to pass to
strategy.extended.call_for_each_replica().
"""
return super(StrategyV1, self).make_input_fn_iterator(
input_fn, replication_mode)
StrategyBase 之中有:
@doc_controls.do_not_generate_docs # DEPRECATED: TF 1.x only
def make_input_fn_iterator(self,
input_fn,
replication_mode=InputReplicationMode.PER_WORKER):
"""DEPRECATED TF 1.x ONLY."""
if replication_mode != InputReplicationMode.PER_WORKER:
raise ValueError(
"Input replication mode not supported: %r" % replication_mode)
with self.scope():
return self.extended._make_input_fn_iterator( # pylint: disable=protected-access
input_fn, replication_mode=replication_mode)
最终来到 MirroredStrategy,生成了 InputFunctionIterator,其调用关系如下:
class InputFunctionIterator(DistributedIteratorV1)
class DistributedIteratorV1(DistributedIteratorBase)
具体代码如下:
def _make_input_fn_iterator(
self,
input_fn,
replication_mode=distribute_lib.InputReplicationMode.PER_WORKER):
input_contexts = []
num_workers = self._input_workers.num_workers
for i in range(num_workers):
input_contexts.append(distribute_lib.InputContext(
num_input_pipelines=num_workers,
input_pipeline_id=i,
num_replicas_in_sync=self._num_replicas_in_sync))
return input_lib.InputFunctionIterator(input_fn, self._input_workers,
input_contexts,
self._container_strategy())
逻辑如下:
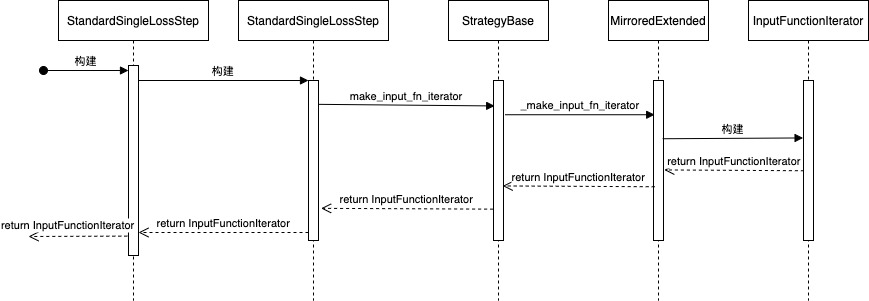
图 10 使用示例
0xFF 参考tensorflow源码解析之distributed_runtime
TensorFlow分布式训练
TensorFlow内核剖析
源代码
Tensorflow分布式原理理解
TensorFlow架构与设计:概述
Tensorflow 跨设备通信
TensorFlow 篇 | TensorFlow 2.x 分布式训练概览
【转自:香港高防 http://www.558idc.com/stgf.html转载请说明出处】