摘要论文地址:面向基于深度学习的语音增强模型压缩
论文代码:没开源,鼓励大家去向作者要呀,作者是中国人,在语音增强领域 深耕多年
引用格式:Tan K, Wang D L. Towards model compression for deep learning based speech enhancement[J]. IEEE/ACM transactions on audio, speech, and language processing, 2021, 29: 1785-1794.
在过去的十年里,深度神经网络(DNNs)的使用极大地提高了语音增强的性能。然而,要实现较强的增强性能通常需要较大的DNN,而DNN既消耗内存又消耗计算量,这使得这种语音增强系统很难部署在硬件资源有限的设备或延迟要求严格的应用程序上。在本研究中,我们提出了两个压缩方法来减小基于DNN的语音增强模型的size,其中包含了三种不同的技术:稀疏正则化、迭代剪枝和基于聚类的量化。我们系统地研究了这些技术,并评估了建议的压缩方法。实验结果表明,我们的方法在不显著牺牲增强性能的前提下,大大减小了四个不同模型的尺寸。此外,我们发现所提出的方法对说话人分离有很好的效果,进一步证明了该方法对语音分离模型压缩的有效性。
关键字:模型压缩,稀疏正则化,剪枝,量化,语音增强
1 引言语音增强的目的是将目标语音从背景噪声中分离出来。受计算听觉场景分析中时频(T-F)掩蔽概念的启发,语音增强被表述为有监督学习[45],[46]。在过去的十年里,许多数据驱动的算法已经被开发出来解决这个问题,其中信号中的鉴别模式是从训练数据中学习的。深度学习的迅速发展极大地促进了有监督语音增强。自从深度学习成为研究界语音增强的主要方法以来,人们对在现实世界的应用和产品(如耳机)中部署基于DNN的增强系统越来越感兴趣。然而,由于DNN[1]、[5]具有可识别的过参数化特性,要获得满意的增强性能,需要较大的DNN,这既需要计算量,又需要占用内存。这类DNN很难部署在对延迟敏感的应用程序或资源有限的设备上。因此,如何在语音增强中减少内存和计算量成为一个日益重要的问题。
深度学习社区开发了各种模型压缩技术,大致可以分为以下几类[4]。
- 网络剪枝:旨在减少了可训练参数的数量。它根据一定的准则[34]来选择和删除最不重要的权值集。两项开创性工作是最优脑损伤[23]和最优脑外科医生[12],它们利用损失函数的hessian矩阵来确定每个权重的重要性(即权重显著性)。剔除显著性最小的权重,对剩余权重进行微调,以恢复丢失的精度。
- 张量分解:它通过基于权重张量的低秩将一个大的权重张量分解为多个较小的张量来减少冗余。
- 知识蒸馏:将知识从一个预先训练好的大模型转移到一个相对较小的模型,称为知识蒸馏[15]。大DNN产生的软目标用于指导小DNN的训练。该方法在图像分类[36]和语音识别[2],[27]等分类任务中被证明是有效的。
- 轻量化模型设计:通过设计参数更高效的网络结构[16],[17],[52]来降低DNN的推理成本。
- 网络量化:它减少权值、激活或两者的位宽。一种简单的方法是用全精度训练DNN,然后直接量化学习到的权值,结果表明,对于相对较小的DNN[18],[22],这将显著降低精度。为了弥补准确性的损失,在[18]中开发了量化感知训练,在训练过程中引入了模拟量化效应。对训练好的权值[3],[10],[11],[19]进行聚类,实现权值量化。
在过去的几年里,越来越多的研究致力于提高DNN用于语音增强的推理效率。在[25]中,开发了整数加法器DNN,使用整数加法器实现浮点乘法。评估结果表明,整数加法器DNN与具有相同结构的全精度DNN的语音质量相当,但在计算和内存方面更高效。Ye等人[50]迭代地修剪DNN用于语音增强,其中权值的重要性是通过简单地将权值的绝对值与预定义阈值进行比较来确定的。实验结果表明,他们的修剪方法可以将前馈DNN压缩约2倍,且不会降低主观可理解性的增强性能。在[49]中,Wu等人使用修剪和量化技术压缩全卷积神经网络(FCN),用于时域语音增强。他们的结果表明,这些技术可以显著减小FCN的大小而不降低性能。最近,Fedorov等人的[6]进行了剪枝和整数量化来压缩递归神经网络(RNN)以增强语音,这可以将RNN的大小降低到37%,同时尺度不变信噪比(SI-SNR)降低了0.2 dB。
尽管DNN压缩技术在图像处理等其他领域得到了广泛的发展和研究,但这些技术大多只在分类任务上进行了评估。由于基于DNN的语音增强通常被视为回归任务,对于语音增强,特定的压缩技术是否有效以及如何结合不同的技术来实现高压缩率仍不清楚。此外,由于语音增强模型的多样性和快速发展,需要一个通用的压缩管道(pipelines)。考虑到这些因素,我们最近开发了两个用于基于DNN的语音增强的初步模型压缩管道[41]。压缩管道包括稀疏正则化、迭代剪枝和基于聚类的量化。稀疏正则化通过DNN训练增加了权值张量的稀疏性,从而在不显著牺牲增强性能的情况下获得更高的剪枝率。我们交替迭代地训练和修剪DNN,然后对剩余的权值进行基于k-means聚类的量化。我们基于单张量灵敏度分析进行剪枝和量化,当权值分布在张量之间变化很大时,这将有利于剪枝率和位宽(bitwidths)的选择。在[41]的基础上,本研究进一步考察了每种技术及其组合对不同类型语音增强模型的影响,并进一步研究了说话人分离模型的压缩管道。具体来说,我们评估了不同设计的语音增强模型的压缩管道,包括DNN类型、训练目标和处理域。评估结果表明,所提出的方法大大减小了所有这些模型的尺寸,而没有显著的性能下降。此外,我们发现我们的方法在两种具有代表性的说话者独立的说话者分离模型上都有很好的效果。
本文的其余部分组织如下。在第二节中,我们将详细描述我们建议的方法。在第三节中,我们提供了实验设置。第四节给出了实验结果并进行了分析。第五节总结了本文的内容。
2 算法描述 A 基于DNN的语音增强在本研究中,我们专注于DNN压缩用于单耳语音增强,尽管我们的方法有望应用于多通道语音增强的DNN。给定一个单通道混合信道$y$,单耳语音增强的目标是估计目标语音$s$。混合信道可以被建模为:
$$公式1:y=s+v$$
式中$v$为背景噪声。因此基于DNN的增强可以表述为:
$$公式2:z=F_1(y)$$
$$公式3:\hat{x}=H(z;\Theta )$$
$$公式4:\hat{s}=F_2(\hat{x},y)$$
式中,$F_1$和$F_2$表示变换,$H$表示DNN表示的非线性映射函数。对于T-F域增强,$F_1$和$F_2$可以分别进行短时傅里叶变换和波形合成。对于时域增强,$F_1$和$F_2$可以分别进行分割和叠加。符号$\Theta$表示DNN中所有可训练参数的集合,表示估计的语音信号。符号$z$和$\hat{x}$分别表示DNN的输入和输出。训练参数$\Theta$使损失函数$L(x,\hat{x})=L(x,H(F_1(y);\Theta))$,其中$x$为训练目标。
B 迭代非结构化和结构化剪枝一个典型的网络剪枝过程包括三个阶段:
- 训练一个获得满意性能的大DNN,
- 按照一定的准则去除被训练DNN中的一组特定的权值,
- 对修剪后的DNN进行微调。
我们可以将去除的权值视为零,因此剪枝可以得到稀疏的权值张量。张量稀疏的粒度影响硬件体系结构的效率。细粒度稀疏性是一种稀疏性模式,其中每个权重设置为0[23]。这种稀疏模式通常是不规则的,这使得很难应用硬件加速[30]。这个问题可以通过施加粗粒度的稀疏性来缓解,这种稀疏性的模式更加规则。我们研究了非结构化和结构化的剪枝。其中,非结构化剪枝是将每个单独的权重单独去除,而结构化剪枝是权重的分组,如图1所示。例如,可以删除权重矩阵的整个列或行。

图1所示。非结构化和结构化修剪的说明,白色表示修剪后的权重,蓝色表示剩余的权重
为了进行结构化剪枝,我们将剪枝粒度定义如下:对于卷积/反卷积层,我们将每个核作为一个权重组进行修剪。其中,对于二维卷积/反卷积层,每个权值组为一个矩阵,对于一维卷积/反卷积层,每个权值组为一个向量。对于循环层和全连通层,每个权值张量都是一个矩阵,其中的每一列都作为权值组进行剪枝。例如,LSTM (long short-term memory)层有8个权重矩阵,其中4个是输入层,其余的是最后一个时间步的隐藏状态,对应4个门(input, forget, cell, output)。在LSTM的实现中,四个门的每一组权重矩阵通常是串联起来的,相当于两个更大的矩阵($W_s$和$W_h$,想了解更清楚的可以移步循环神经网络(RNN)及衍生LSTM、GRU详解)。我们将这些矩阵的每一列作为权重组进行剪枝。这种剪枝粒度将导致较高的压缩比,并产生比细粒度稀疏[30]更硬件友好的粗粒度稀疏(也就是使用结构化剪枝)。请注意,我们没有删除偏置项,因为偏置项的数量相对于权重的数量来说很小。
网络剪枝的关键问题是确定剪枝准则,确定要删除的权值集合。为了进行非结构化剪枝,我们将特定的权值集合$U$的显著性定义为删除它们所引起的误差的增加。具体来说,权重显著性是使用验证集$V$来测量的:
$$公式5:\mathcal{I}_{\mathcal{U}}=\mathcal{L}(\mathcal{V}, \Theta \mid w=0, \forall w \in \mathcal{U})-\mathcal{L}(\mathcal{V}, \Theta)$$

与[6],[49],[50]不同的是,我们按照算法1对所有权值张量进行了逐张量剪枝灵敏度分析,以确定其剪枝率。然后,根据张量剪枝率进行非结构化剪枝。然后对修剪后的DNN进行微调以恢复增强性能。我们通过短时客观可解性(STOI)[39]和语音质量感知评价(PESQ)[35]两个度量来评估 经过微调的DNN在验证集上的性能。这种修剪和微调操作是迭代交替执行的。我们重复这个过程,直到经过修剪的权值的数量在一次迭代中变得微不足道,或者在验证集中观察到STOI或PESQ的显著下降。注意,修剪和微调都是在整个网络上执行的。
对于结构化修剪,权值组显著性测量为:
$$公式6:\mathcal{I}_{\mathcal{U}}=\mathcal{L}(\mathcal{V}, \Theta \mid \mathbf{g}=0, \forall \mathrm{g} \in \mathcal{U})-\mathcal{L}(\mathcal{V}, \Theta)$$
其中$U$表示权重组的集合。同样,我们在算法2之后进行敏感性分析。然后对多个迭代执行结构化剪枝和微调。请注意,每次修剪迭代后,参数集$\Theta $的大小都会减小。

我们的方法在两个方面是有益的。首先,现有的一些修剪方法(如[50])使用一个共同的阈值来区分整个DNN的所有层中不重要的权重。这可以极大地限制对冗余的层进行修剪,或者过度修剪冗余的层,特别是在各层的重要性显著不同的情况下。我们的敏感性分析可以缓解这样的问题。其次,我们迭代地进行剪枝和微调,并在每次迭代的语音增强度量(STOI和PESQ)上评估得到的模型。这可以大大降低过度剪枝的风险和相应的不可恢复的性能退化,即使权值的重要性与其大小[31]没有很强的相关性。
在非结构化和结构化剪枝之间的选择取决于底层设备是否可以访问硬件加速。具体来说,当无法加速时,使用非结构化剪枝会更好,因为在增强性能没有显著下降的约束下,它通常允许比结构化剪枝更高的压缩率。对于带有加速器的设备,结构剪枝是更好的选择。
C 稀疏正则化为了在不降低性能的情况下提高剪枝率,我们提出在训练和微调过程中使用稀疏正则化。施加权重级稀疏性的一种主要方法是$l_1$正则化,它惩罚训练过程中权重绝对值的总和。具体来说,$l_1$正则化鼓励不太重要的权值变为零,从而减少了性能的下降。因此,在我们的修剪准则下,可以得到更高的修剪率。$l_1$正则化器可以写成:
$$公式7:\mathcal{R}_{\ell_{1}}=\frac{\lambda_{1}}{n(\mathcal{W})} \sum_{w \in \mathcal{W}}|w|$$
其中$W$为所有非零权值的集合,$\lambda_1$为预定义的权值因子。函数$n(·)$计算集合的基数。因此,新的损失函数为$L_{l_1}=L+R_{l_1}$。
Group-level 稀疏性可以由 group lasso 惩罚引起[7]:
$$公式8:\mathcal{R}_{\ell_{2,1}}=\frac{\lambda_{2}}{n(\mathcal{G})} \sum_{\mathbf{g} \in \mathcal{G}} \sqrt{p_{\mathbf{g}}}\|\mathbf{g}\|_{2}$$
式中,$\mathcal{G}$为所有权重组的集合,$||·||_2$为$l_2$范数。符号$p_g$表示每个权重群$g$中的权重个数,$\lambda_2$为权重因子。在这种惩罚下,一组中的所有权重同时被鼓励为零或不为零。
一个扩展版本:稀疏组lasso (sparse group lasso,SGL),它通过加入$l_1$正则化[37],[38]进一步增强了非稀疏组的稀疏性:
$$公式9:\begin{aligned}
\mathcal{R}_{\mathrm{SGL}} &=\mathcal{R}_{\ell_{1}}+\mathcal{R}_{\ell_{2,1}} \\
&=\frac{\lambda_{1}}{n(\mathcal{W})} \sum_{w \in \mathcal{W}}|w|+\frac{\lambda_{2}}{n(\mathcal{G})} \sum_{\mathbf{g} \in \mathcal{G}} \sqrt{p_{\mathbf{g}}}\|\mathbf{g}\|_{2}
\end{aligned}$$
对应的损失函数为$L_{SGL}=L+R_{SGL}$。根据不同的剪枝粒度,非结构化剪枝采用L1,结构化剪枝采用$L_{SGL}$。
D 基于聚类的量化为了进一步压缩经过修剪的DNN,我们提出使用基于聚类的量化[10],[11]。具体来说,将每个张量的权值划分为K个簇$S_1$、$S_2$、…, $S_K$通过k-means聚类:
$$公式10:\underset{S_{1}, S_{2}, \ldots, S_{K}}{\arg \min } \sum_{k=1}^{K} \sum_{w \in S_{k}}\left|w-\mu_{k}\right|^{2}$$
在[11]之后,在进行k-means聚类之前,我们先用均匀间隔在$[w_{min}, w_{max}]$区间内的$K$值初始化聚类中心,其中$w_{min}$和$w_{max}$分别代表权重张量的最小值和最大值。一旦聚类算法收敛,我们将属于同一聚类的所有权值重置为相应质心的值。因此,原始的权值由这些星团中心近似表示。这种权重共享机制大大减少了需要存储的有效权重值的数量。每个权重可以表示为一个聚类指数。请注意,只有非零权值才受聚类和权值共享的约束。

图2:基于聚类的量化说明
我们创建了一个代码本来存储每个权值张量的群集重心值,其中每个非零权值被绑定到相应的群集索引上。在推理过程中,将在码本中查找每个权重的值。图2说明了基于聚类的量化。具体来说,我们将每个权值量化为$log_2K$ bit。换句话说,它需要$log_2K$ bits来存储相应的集群索引。假设最初的权值是32位浮点数,为了存储代码本需要额外的32K bits。因此,量化的压缩率计算为:
$$公式11:r=\frac{32 N}{N \log _{2} K+32 K}$$
其中N表示张量中非零权值的个数。
量化技术中一个常见的问题是如何保持DNN的性能。对于基于聚类的量化,选择一个合适的K值是实现这一目标的关键。鉴于权值张量之间非零权值的数量可能会有很大的差异,我们建议在算法3之后对量化进行逐张量灵敏度分析。其思想是逐步增加每个权值张量的聚类数量,并度量相应的验证损失增加。灵敏度分析的结果用于量化每个权值张量中的权值。与[11]中对所有权值张量使用相同数量的簇不同,我们的方法允许使用不同的比特数量化每个张量,这可能导致更高的压缩率。

因此,结合稀疏正则化、迭代剪枝和基于聚类的量化,我们可以得到两个压缩管道,如图3所示。在图3(a)所示的压缩管道中,我们应用$l_1$正则化和非结构化剪枝。在另一个管道(见图3(b))中,我们应用了群稀疏正则化(见式(9))和结构化剪
枝。

图3:压缩管道的图示
3 实验步骤 A 数据处理在实验中,我们使用WSJ0数据集[8]作为训练集进行评价,该训练集包含101个说话人的12 776个话语。这些讲者被分为三组,分别为89人、6人和6人进行培训、验证和测试。更具体地说,验证和测试的说话者群体包括3名男性和3名女性。我们使用来自声音效果库1的10000个噪音进行训练,使用来自NOISEX-92数据集[43]的工厂噪音进行验证。为了创建测试集,我们使用两个高度非平稳噪声,即babble (BAB)和自助餐厅(CAF),从一个Auditec CD。
我们的训练集包括32万种混合物,总持续时间约为600小时。为了创建一个训练混合物,我们将一个随机采样的训练声音与从10000个训练噪声中随机提取的片段混合起来。信噪比(SNR)在-5和0 dB之间随机采样。按照相同的步骤,我们创建一个由846种混合物组成的验证集。一个包含846个混合混合的测试集被创建为两个噪音和三个信噪比,即-5,0和5 dB。
在这项研究中,所有的信号都是在16khz采样。每个噪声混合被一个因子缩放,使混合波形的均方根为1。我们使用相同的因子来缩放相应的目标语音波形。利用20毫秒的汉明窗口产生一组时间帧,相邻帧之间有50%的重叠。我们对每一帧应用320点(16 kHz 20 ms)离散傅里叶变换,产生161维单边光谱。
B 语音增强模型为了系统地研究所提出的模型压缩管道,我们使用以下四个模型进行单耳语音增强,它们有不同的设计,包括DNN类型、训练目标和处理域。
1)前馈DNN:第一个模型是前馈ddn (FDNN),它有三个隐藏层,每层2048个单元。我们使用理想的比例掩模[48]作为训练目标:
$$公式12:\operatorname{IRM}(m, f)=\sqrt{\frac{|S(m, f)|^{2}}{|S(m, f)|^{2}+|N(m, f)|^{2}}}$$
其中,$|S(m, f)|^2$和$|N(m, f)|^2$分别表示时间帧$m$和频率bin $f$时T-F单元内的语音能量和噪声能量。频谱(magnitude)用作FDNN输入。
2) Lstm:第二种是递归Lstm模型,在幅度域进行光谱映射。它有4个LSTM隐藏层,每层1024个单元,输出层为全连接层,后接整流线性激活函数[9]。
3)Temporal Convolutional Neural Network:第三个模型是在最近的研究[32]中开发的时域卷积神经网络(TCNN)。tcnnis是一种全卷积神经网络,它可以在时域直接从有噪声的语音映射到干净的语音。
4)Gated Convolutional Recurrent Network:第四个是新开发的门控卷积循环网络(GCRN)[40]。GCRN有一个编码器-解码器架构,它包含了卷积层和循环层。训练该算法进行复杂的频谱映射,从噪声语音的真实谱图和虚谱图中估计出纯净语音的真实谱图和虚谱图。
对于TCNN和GCRN,我们在[32]和[40]中使用相同的网络超参数。请注意,这四个DNN都是因果关系。根据压缩DNN的需要,我们选择因果DNN以避免不可接受的延迟。
C 训练细节和敏感性分析配置我们使用AMSGrad优化器[33]在4秒的片段上训练模型,小批量尺寸为16。学习速率初始化为0.001,每两个时代衰减98%。目标函数为均方误差,即T-F单位(对于FDNN、LSTM和GCRN)或时间样本(对于TCNN)的平均值。我们使用验证集来选择不同时期的最佳模型,并对剪枝和量化进行灵敏度分析。
对于非结构化剪枝,FDNN、LSTM、TCNN和GCRN的λ1的初始值(见式(7))经验设置为0.1、10、0.02和1。对于结构修剪,采用相同的λ1初始值,FDNN、LSTM、TCNN和GCRN的$\lambda_2$初始值(见式(9))分别设为0.0005、0.005、0.02和0.05。在这些值下,$R_{l_1}$和$R_{l_{2,1}}$的数量级几乎相同,且比l小一个数量级。$\lambda_1$和$\lambda_2$在每次修剪迭代时均衰减10%。敏感性分析(见算法1、2和3)的耐受值($\alpha_1$、$\alpha_2$)经验设置为FDNN、LSTM、TCNN和GCRN的分别为(0.003、0.0005)、(0.03、0.01)、(0.0002、0.00 005)和(0.02、0.005)。
4 实验结果及分析 A 压缩管道的评估未压缩模型与压缩模型的综合比较如表1所示。下标U为未压缩模型,C1和C2为我们提出的压缩管道压缩模型,分别如图3(a)和3(b)所示。STOI和PESQ分数代表每个测试条件下测试示例的平均值。我们观察到,在STOI和PESQ方面,建议的压缩管道对所有四种模型的性能都有轻微或没有影响。以LSTM模型为例。两个管道将LSTM模型尺寸从115.27 MB压缩到2.49 MB和9.97 MB,压缩率分别为46x和12x。注意,对于这三个信噪比,$LSTM_{C_1}$和$LSTM_{C_2}$都产生与$LSTM_U$相似的STOI和PESQ。
表1:比较未压缩和压缩模型

在城市公园(NPARK)、地铁站(PSTATION)、会议室(OMEETING)和城市广场(SPSQUARE)四个不同的环境中记录了这四种噪音。表2中的STOI和PESQ分数代表了四种噪声的平均值。我们可以看到,我们的方法导致轻微或没有退化的模型性能在这些噪声。
表2:在四种附加噪声下,由未压缩和压缩模型产生的平均stoi和pesq结果
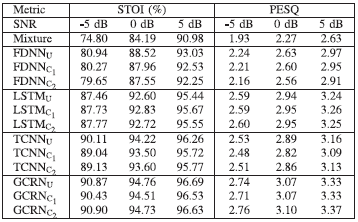
此外,从表I可以看出,对于FDNN、LSTM和GCRN, $C_1$比$C_2$具有更高的压缩率。这可能是因为非结构化剪枝比结构化剪枝使用更小的剪枝粒度,这允许更少的规则稀疏模式和更高的权值张量稀疏。因此,非结构化剪枝比结构化剪枝约束更少,通常导致更高的剪枝率。对于TCNN来说,这两条管道的压缩率相似。一种解释是,对于全卷积神经网络,结构化剪枝可以实现与非结构化剪枝相似的压缩比,与[30]一致。
表3给出了未压缩和压缩模型处理4秒噪声混合时的乘法累加(MAC)操作的数量。我们可以观察到,我们的方法显著地减少了所有四个模型的MAC操作的数量,表明计算复杂度也降低了提出的压缩管道。
表3:未压缩和压缩模型处理4秒噪声混合物的MAC操作数。“Percent”表示MAC操作原始次数的百分比

我们现在研究稀疏正则化和迭代剪枝的效果。图4给出了有无l1正则化(见式(7))时,用于非结构化剪枝的原始可训练参数数量的百分比。如图4所示,通过迭代剪枝对模型进行增量压缩。例如,在不进行稀疏正则化的情况下,经过一次修剪迭代后,TCNN原始可训练参数数量的百分比降至55%,经过5次修剪迭代后降至30%。
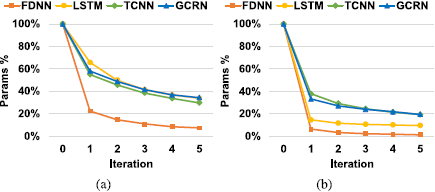
图4所示。在不同的剪枝迭代中,原始可训练参数数目的百分比。
(a).不带;(b).带稀疏正则化。注意,执行的是非结构化剪枝。
此外,可以观察到,稀疏正则化的使用导致所有四个模型的压缩率更高。 例如,通过对 GCRN 进行 5 次迭代,通过应用 l1 正则化,可以将压缩率从 2.9× 提高到 5.1×。 -5 dB SNR 的相应 STOI 和 PESQ 结果如图 5 所示,这表明我们提出的剪枝方法不会显着降低增强性能。 为了进一步研究稀疏正则化对剪枝的影响,我们在图 6 中显示了 FDNN 中不同层的剪枝率在一次剪枝迭代后。我们可以看到稀疏正则化增加了所有 FDNN 层的剪枝率。 结构化修剪的这些诱导增加明显大于非结构化修剪,这进一步证明了组稀疏正则化对结构化修剪的有效性。
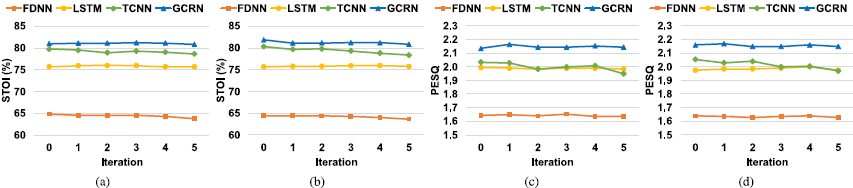
图5所示。在不同的剪枝迭代下- 5db信噪比的STOI和PESQ评分。(a)和(c)。没有,和(b)和(d)。与稀疏正则化。注意,执行的是非结构化剪枝

图6所示。一次剪枝迭代后FDNN中不同层的剪枝率。非结构化剪枝采用$l_1$正则化,结构化剪枝采用群稀疏正则化
我们还训练了四个相对较小的DNNs,即FDNNS、LSTMS、TCNNS和GCRNS。它们都具有与第三- b节中描述的FDNN、LSTM、TCNN和GCRN相同的结构,只是减少了层宽或网络深度。其中,FDNNS和LSTMS各隐层单元数分别重置为200个和320个。对于TCNNS,每个残块的中间层输出通道数从512减少到256,扩张块数从3减少到2。对于GCRNS,编码器中的第四和第五门控块的输出通道数分别重置为64和128。每个解码器中的第一门控块中的输出通道数从128减少到64。我们对FDNNS、LSTMS、TCNN和GCRNS分别进行了5次、5次、3次和5次的剪枝,使其与原始FDNN、LSTM、TCNN和GCRN的模型大小相当。我们将这些剪枝模型分别表示为FDNNP、LSTMP、TCNNP和GCRNP。表4比较了这些模型产生的STOI和PESQ结果。我们发现FDNNP、LSTMP、TCNNP和GCRNP产生的STOI和PESQ显著高于FDNNS、LSTMS、TCNNS和GCRNS。这说明训练和修剪一个大的冗余DNN比直接训练一个较小的DNN的优势,与[13],[24],[28],[51]一致。
表4 比较修剪模型和比较大小的未修剪模型

现在,我们将我们提出的基于单张量敏感性分析的剪枝方法,与一种使用共同阈值来确定DNN中所有权重张量的权值进行剪枝的方法进行比较。这样的策略被采用在许多现有的方法(如[50])。具体来说,我们比较了由两个不同修剪后的gcrn产生的STOI和PESQ分数。其中一个基于算法1(记为GCRNP1)的结果进行非结构剪枝。另一个(标记为GCRNP2)通过删除绝对值小于阈值的权值来进行修剪,这对所有权值张量都是一样的。这个阈值是经过仔细选择的,以便GCRNP2具有与GCRNP1完全相同的压缩率。这两个gcrn只在一次迭代中进行修剪,然后进行微调。我们使用不同的公差α1值(0.02,0.04,0.08,0.16和0.32)来得到不同的压缩率。STOI和PESQ结果如图7所示,它们表明我们提出的方法产生了更高的STOI和PESQ。这证明了逐张量灵敏度分析比使用公共剪枝阈值的替代方法的优势。
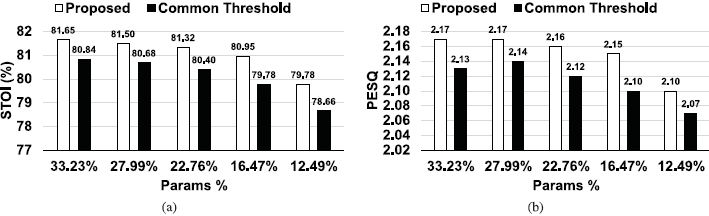
图7 本文提出的剪枝方法与一种对所有权值张量使用公共剪枝阈值的方法的比较
C 基于聚类的量化效应为了研究基于聚类的量化效果,我们将原始未压缩模型的权值直接量化(不进行剪枝),即四个量化模型,即FDNNQ、LSTMQ、TCNNQ和GCRNQ。未压缩模型和量化模型的对比如表5所示。可以看出,我们提出的量化方法在不降低增强性能的前提下,大幅减小了模型的尺寸。例如,在三种信噪比下,LSTMU和LSTMQ产生的STOI和PESQ得分的差异分别小于0.2%和0.01。通过基于聚类的量化,将LSTM模型从115.27 MB压缩到21.42 MB,压缩率为5。
表5:未压缩和量化模型的比较

本节评估提议的压缩管道在多说话者扬声器分离。具体来说,我们选择Tas- Net[29]和一个基于话语级置换不变训练(uPIT)[21]的LSTM模型作为说话者独立分离的代表方法来应用我们的压缩。我们对TasNet和uPIT-LSTM分别使用与[29]和[21]中相同的因果网络配置。模型在广泛使用的WSJ0-2mix数据集[8]、[14]上进行评估,该数据集在训练集、验证集和测试集中分别包含20000个、5000个和3000个混合集。采样频率设置为8khz,如[21]和[29]。在[26]之后,我们使用扩展短时间客观可解度(ESTOI)[20]、PESQ、SI-SNR[29]和信号失真比(SDR)[44]来测量扬声器分离性能。其他配置与第三- c节相同。
根据四个指标,说话人分离的结果见表六。我们可以看到,我们提出的方法在保持分离性能的同时显著压缩了两个模型。例如,管道C1将LSTM模型从250.46 MB压缩到2.50 MB,而不减少四个性能指标中的任何一个。这进一步证明了我们的方法对语音分离模型的有效性。此外,对于uPIT-LSTM, C1管道比C2管道的压缩率更高,而对于全卷积神经网络TasNet,这两个管道的压缩率相当。这与我们对压缩语音增强模型的发现是一致的(见IV-A节)。
5 结论在本研究中,我们提出了两个新的管道压缩DNN语音增强。提出的管道包括三种不同的技术:稀疏正则化、迭代剪枝和基于聚类的量化。我们在不同类型的语音增强模型上系统地研究了这些技术。我们的实验结果表明,所提出的管道大大减小了四个不同的DNN用于语音增强的尺寸,而没有显著的性能退化。此外,对于全卷积神经网络,结构化剪枝可以获得与非结构化剪枝相似的压缩率,而对于其他类型的DNN,非结构化剪枝可以获得更高的压缩率。我们还发现,训练和修剪一个过度参数化的DNN比直接训练一个小的DNN(与修剪后的DNN大小相当)能获得更好的增强结果。此外,我们的方法在两个有代表性的说话人分离模型上运行良好,进一步表明我们的管道对语音分离模型的压缩能力。
感谢作者要感谢Ashutosh Pandey提供了他对TCNN的实施。
参考文献[1] L. J. Ba and R. Caruana, Do deep nets really need to be deep? , in Proc. 27th Int. Conf. Neural Inf. Process. Syst. , vol. 2, 2014, pp. 2654 2662,.
[2] Y. Chebotar and A. Waters, Distilling knowledge from ensembles of neural networks for speech recognition, in Proc. Annu. Conf. Int.Speech Commun. Assoc. (INTERSPEECH), 2016, pp. 3439 3443.
[3] Y. Chen, T. Guan, and C.Wang, Approximate nearest neighbor search by residual vector quantization, Sensors, vol. 10, no. 12, pp. 11259 11273, 2010.
[4] L. Deng, G. Li, S. Han, L. Shi, and Y. Xie, Model compression and hardware acceleration for neural networks: A comprehensive survey, Proc. IEEE IRE, vol. 108, no. 4, pp. 485 532, Apr. 2020.
[5] E.Denton,W. Zaremba, J. Bruna,Y. LeCun, andR. Fergus, Exploiting linear structure within convolutional networks for efficient evaluation, Proc. 27th Int.Conf. Neural Inf. Process. Syst. , vol. 1, 2014, pp. 1269 1277,.
[6] I. Fedorov et al., TinyLSTMs: Efficient neural speech enhancement for hearing aids, in INTERSPEECH, 2020, pp. 4054 4058.
[7] J. Friedman, T. Hastie, and R. Tibshirani, A. note on the group lasso and a sparse group lasso, 2010, arXiv:1001.0736.
[8] J. Garofolo, D. Graff, D. Paul, and D. Pallett, CSR-I (WSJ0) Complete LDC93S6A, Web Download. Philadelphia: Linguistic Data Consortium, vol. 83, 1993.
[9] X. Glorot, A. Bordes, and Y. Bengio, Deep sparse rectifier neural networks, in Proc. 14th Int. Conf. Artif. Intell.Statist.. JMLR Workshop, 2011, pp. 315 323.
[10] Y. Gong, L. Liu, M. Yang, and L. Bourdev, Compressing deep convolutional networks using vector quantization, 2014, arXiv:1412.6115.
[11] S. Han, H. Mao, and W. J. Dally, Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding, in Proc. Int. Conf. Learn. Representations, 2015.
[12] B. Hassibi andD.G. Stork, Second order derivatives for network pruning: Optimal brain surgeon, in Proc. Adv. Neural Inf. Process. Syst., 1993, pp. 164 171.
[13] Y. He, X. Zhang, and J. Sun, Channel pruning for accelerating very deep neural networks, in Proc. IEEE Int. Conf. Comput. Vis., 2017, pp. 1389 1397.
[14] J. R. Hershey, Z. Chen, J. Le Roux, and S. Watanabe, Deep clustering: Discriminative embeddings for segmentation and separation, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2016, pp. 31 35.
[15] G. Hinton, O. Vinyals, and J. Dean, Distilling the knowledge in a neural network, in Proc. Int. Conf. Neural Inf. Process. Syst. Deep Learn. Representation Learn. Workshop, 2015.
[16] A. G. Howard et al., MobileNets: Efficient convolutional neural networks for mobile vision applications. 2017, arXiv:1704.04861.
[17] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, SqueezeNet: Alexnet-level accuracy with 50x fewer parameters and <5 MB model size . 2016, arXiv:1602.07360.
[18] B. Jacob et al., Quantization and training of neural networks for efficient integer-arithmetic-only inference, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 2704 2713.
[19] H. Jegou, M. Douze, and C. Schmid, Product quantization for nearest neighbor search, IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 1, pp. 117 128, Jan. 2010.
[20] J. Jensen and C. H. Taal, An algorithm for predicting the intelligibility of speech masked by modulated noise maskers, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 24, no. 11, pp. 2009 2022, Nov. 2016.
[21] M.Kolbæk,D.Yu, Z.-H. Tan, and J. Jensen, Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 25, no. 10, pp. 1901 1913, Oct. 2017.
[22] R. Krishnamoorthi, Quantizing deep convolutional networks for efficient inference: A whitepaper, 2018, arXiv:1806.08342.
[23] Y. LeCun, J. S. Denker, and S. A. Solla, Optimal brain damage, in Proc. Adv. Neural Inf. Process. Syst., 1990, pp. 598 605.
[24] J. Lin, Y. Rao, J. Lu, and J. Zhou, Runtime neural pruning, in Proc. 31st Int. Conf. Neural Inf. Process. Syst., 2017, pp. 2178 2188.
[25] Y.-C. Lin, Y.-T. Hsu, S.-W. Fu, Y. Tsao, and T.-W. Kuo, IA-NET: Acceleration and compression of speech enhancement using integer-adder deep neural network, in INTERSPEECH, 2019, pp. 1801 1805.
[26] Y. Liu and D. L. Wang, Divide and conquer: A deep CASA approach to talker-independent monaural speaker separation, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 27, no. 12, pp. 2092 2102, Dec. 2019.
[27] L. Lu,M. Guo, and S. Renals, Knowledge distillation for small-footprint highway networks, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2017, pp. 4820 4824.
[28] J.-H. Luo, J. Wu, and W. Lin, ThiNet: A filter level pruning method for deep neural network compression, in Proc. IEEE Int. Conf. Comput. Vis., 2017, pp. 5058 5066.
[29] Y. Luo and N. Mesgarani, Conv-TasNet: Surpassing ideal time-frequency magnitude masking for speech separation, IEEE/ACM Trans Audio, Speech, Lang. Process., vol. 27, no. 8, pp. 1256 1266, Aug. 2019.
[30] H. Mao et al., Exploring the granularity of sparsity in convolutional neural networks, in Proc. IEEE Conf.Comput. Vis. Pattern Recognit.Workshops, 2017, pp. 13 20.
[31] P. Molchanov, A. Mallya, S. Tyree, I. Frosio, and J. Kautz, Importance estimation for neural network pruning, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 11264 11272.
[32] A. Pandey and D. L. Wang, TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2019, pp. 6875 6879.
[33] S. J. Reddi, S. Kale, and S. Kumar, On the convergence of adam and beyond, in Proc. Int. Conf. Learn. Representations, 2018.
[34] R. Reed, Pruning algorithms-a survey, IEEE Trans. Neural Netw. , vol. 4, no. 5, pp. 740 747, Sep. 1993.
[35] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, Perceptual evaluation of speech quality (PESQ)-A new method for speech quality assessment of telephone networks and codecs, in Proc. IEEE Int. Conf. Acoust. , Speech, Signal Process. (Cat. No 01CH37221), vol. 2, 2001, pp. 749 752.
[36] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, FitNets: Hints for thin deep nets, in Int. Conf. Learn. Representations, 2015.
[37] S. Scardapane, D. Comminiello, A. Hussain, and A. Uncini, Group sparse regularization for deep neural networks, Neurocomputing, vol. 241, pp. 81 89, 2017.
[38] N. Simon, J. Friedman, T. Hastie, and R. Tibshirani, A. sparse-group lasso, J. Comput. Graphical Statist. , vol. 22, no. 2, pp. 231 245, 2013.
[39] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, An algorithm for intelligibility prediction of time-frequency weighted noisy speech, IEEE Trans. Audio, Speech, Lang. Process. , vol. 19, no. 7, pp. 2125 2136, Sep. 2011.
[40] K. Tan and D. L. Wang, Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 28, pp. 380 390, 2020.
[41] K. Tan and D. L. Wang, Compressing deep neural networks for efficient speech enhancement, in Proc. IEEE Int. Conf. Acoust. , Speech Signal Process. 2021, pp. 8358 8362.
[42] J. Thiemann, N. Ito, and E. Vincent, The diverse environments multichannel acoustic noise database: A database of multichannel environmental noise recordings, J. Acoust. Soc. Amer. , vol. 133, no. 5, pp. 3591 3591, 2013.
[43] A. Varga and H. J. Steeneken, Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems, Speech Commun. , vol. 12, no. 3, pp. 247 251, 1993.
[44] E. Vincent, R. Gribonval, and C. Févotte, Performance measurement in blind audio source separation, IEEE Trans. Audio, Speech, Lang. Process. , vol. 14, no. 4, pp. 1462 1469, Jul. 2006.
[45] D. L. Wang, On ideal binary mask as the computational goal of auditory scene analysis, in P. Divenyi, ed., Speech Separation by Humans Machines. Springer, 2005, pp. 181 197.
[46] D. L. Wang and G. J. Brown, editors. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications. Hoboken, NJ, USA, Wiley, 2006.
[47] D. L. Wang and J. Chen, Supervised speech separation based on deep learning: An overview, IEEE/ACMTrans. Audio, Speech, Lang. Process. , vol. 26, no. 10, pp. 1702 1726, Oct. 2018.
[48] Y. Wang, A. Narayanan, and D. L. Wang, On training targets for supervised speech separation, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 22, no. 12, pp. 1849 1858, Dec. 2014.
[49] J.-Y. Wu, C. Yu, S.-W. Fu, C.-T. Liu, S.-Y. Chien, and Y. Tsao, Increasing compactness of deep learning based speech enhancement models with parameter pruning and quantization techniques, IEEE Signal Process. Lett. , vol. 26, no. 12, pp. 1887 1891, Dec. 2019.
[50] F. Ye, Y. Tsao, and F. Chen, Subjective feedback-based neural network pruning for speech enhancement, in Proc. IEEE Asia-Pacific Signal Inf. Process. Assoc. Annu. Summit Conf., 2019, pp. 673 677.
[51] R. Yu et al., NISP: Pruning networks using neuron importance score propagation, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. , 2018, pp. 9194 9203.
[52] X. Zhang, X. Zhou, M. Lin, and J. Sun, ShuffleNet: An extremely efficient convolutional neural network for mobile devices, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. , 2018, pp. 6848 6856.