个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判。如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 issue,谢谢支持~
本篇文章参考了大量文章,文档以及论文,但是这块东西真的很繁杂,我的水平有限,可能理解的也不到位,如有异议欢迎留言提出。本系列会不断更新,结合大家的问题以及这里的错误和疏漏,欢迎大家留言
JMM 相关文档:
- Java Language Specification Chapter 17
- The JSR-133 Cookbook for Compiler Writers - Doug Lea's
- Using JDK 9 Memory Order Modes - Doug Lea's
内存屏障,CPU 与内存模型相关:
- Weak vs. Strong Memory Models
- Memory Barriers: a Hardware View for Software Hackers
- A Detailed Analysis of Contemporary ARM and x86 Architectures
- Memory Model = Instruction Reordering + Store Atomicity
- Out-of-Order Execution
x86 CPU 相关资料:
- x86 wiki
- Intel® 64 and IA-32 Architectures Software Developer Manuals
- Formal Specification of the x86 Instruction Set Architecture
ARM CPU 相关资料:
- ARM wiki
- aarch64 Cortex-A710 Specification
各种一致性的理解:
- Coherence and Consistency
Aleskey 大神的 JMM 讲解:
- Aleksey Shipilëv - 不要误解Java内存模型(上)
- Aleksey Shipilëv - 不要误解Java内存模型(下)
相信很多 Java 开发,都使用了 Java 的各种并发同步机制,例如 volatile,synchronized 以及 Lock 等等。也有很多人读过 JSR 第十七章 Threads and Locks(地址:https://docs.oracle.com/javase/specs/jls/se17/html/jls-17.html),其中包括同步、Wait/Notify、Sleep & Yield 以及内存模型等等做了很多规范讲解。但是也相信大多数人和我一样,第一次读的时候,感觉就是在看热闹,看完了只是知道他是这么规定的,但是为啥要这么规定,不这么规定会怎么样,并没有很清晰的认识。同时,结合 Hotspot 的实现,以及针对 Hotspot 的源码的解读,我们甚至还会发现,由于 javac 的静态代码编译优化以及 C1、C2 的 JIT 编译优化,导致最后代码的表现与我们的从规范上理解出代码可能的表现是不太一致的。并且,这种不一致,导致我们在学习 Java 内存模型(JMM,Java Memory Model),理解 Java 内存模型设计的时候,如果想通过实际的代码去试,结果是与自己本来可能正确的理解被带偏了,导致误解。
我本人也是不断地尝试理解 Java 内存模型,重读 JLS 以及各路大神的分析。这个系列,会梳理我个人在阅读这些规范以及分析还有通过 jcstress 做的一些实验而得出的一些理解,希望对于大家对 Java 9 之后的 Java 内存模型以及 API 抽象的理解有所帮助。但是,还是强调一点,内存模型的设计,出发点是让大家可以不用关心底层而抽象出来的一些设计,涉及的东西很多,我的水平有限,可能理解的也不到位,我会尽量把每一个论点的论据以及参考都摆出来,请大家不要完全相信这里的所有观点,如果有任何异议欢迎带着具体的实例反驳并留言。
首先,我想先参考 Aleksey Shipilëv 大神的理解思路,即首先分清楚规范(Specification)与实现(Implementation)的区别。前面提到的 JLS(Java Language Specification)其实就是一种规范,它规范了 Java 语言,并且所有能编译运行 Java 语言的 JDK 实现都要实现它里面规定的功能。但是对于实际的实现,例如 Hotspot JVM 的 JDK,就是具体的实现了,从规范到实际的实现,其实是有一定的差异的。首先是下面这个代码:

实际 HotSpot 最后编译并且经过 JIT 优化与 CPU 指令优化运行的代码其实是:

即将结果 3 放入寄存器并返回,这样与原始代码其实效果是一致的,省略了无用的本地变量操作,也是合理的。那么你可能会有疑问:不会呀,我打断点运行到这里的时候,能看到本地变量 x,y,result 呀。这个其实是 JVM 运行时做的工作,如果你是以 DEBUG 模式运行 JVM,那么其实 JIT 默认就不会启用,只会简单的解释执行,所以你能看到本地变量。但是实际执行中,如果这个方法是热点方法,经过 JIT 的优化,这些本地变量其实就不存在了。
还有一个例子是,Hotspot 会有锁膨胀机制(这个我们后面还会测试),即:
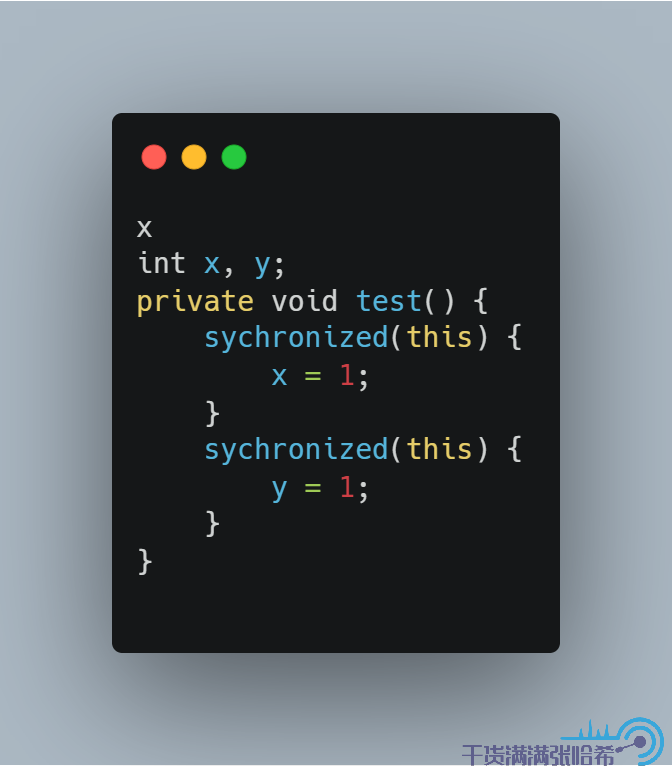
如果按照 JLS 的描述,那么 x = 1 与 y = 1 这两个操作是不能重排序的。但是 Hotspot 实际的实现会将上面的代码优化成:

那么这样,其实 x = 1 与 y = 1 这两个操作就可以重排序了,这个我们后面也会验证。
不同的 JVM 实现,实际的表现都会有些差异。并且就算是同一个 JVM 实现,在不同的操作系统,硬件环境等等,表现也有可能不一样。例如下面这个例子:

正常情况下,r1 的值应该只有 {-1, 0} 这两个结果之一。但是在某些 32 位的 JVM 上执行会有些问题,例如在 x86_32 的环境下,可能会有 {-1, 0, -4294967296, 4294967295} 这些结果。
所以,如果我们要全面的覆盖底层到 JMM 设计以及 Hotspot 实现和 JIT 优化等等等等,涉及的东西太多太多,一层逻辑套逻辑,面面俱到我真的做不到。并且我也没法保证我理解的百分百准确。如果我们要涉及太多的 HotSpot 实现,那么我们可能就偏离了我们这个系列的主题,我们其实主要关心的是 Java 本身内存模型的设计规范,然后从中总结出我们在实际使用中,需要知道并且注意的点的最小集合,这个也是本系列要梳理的,同时,为了保证本系列梳理出的这个最小集合准确,会加上很多实际测试的代码,大家也可以跑一下看看这里给出的结论以及对于 JMM 的理解是否正确。
2. 什么是内存模型任何需要访问内存的语言,都需要有内存模型,描述如何访问内存:即我可以用哪些方式去写内存,可以用哪些方式去读取内存,不同的写入方式以及读取方式,会有什么不同的表现。当然,如果你的程序是一个简单的串行程序,你读取到的一定是最新写入的值,这样的情况下,其实你并不需要内存模型这种东西。一般是并发的环境下,才会需要内存模型这个东西。
Java 内存模型其实就是规定了在 Java 多线程环境下,以不同的特定方式读取或者写入内存的时候,能观察到内存的合理的值。
也有是这么定义 Java 内存的,即 Java 指令是会重排序的,Java 内存模型规定了哪些指令是禁止重排序的,实际上这也是 JLS 第 17 章中 Java 内存模型中的主要内容。这其实也是实现观察到内存的合理的值的方式,即对于给定的源代码,可能的结果集是什么。
我们接下来看两个简单的入门例子,作为热身。分别是原子性访问,以及字分裂。
3. 原子性访问原子性访问,对于一个字段的写入与读取,这个操作本身是原子的不可分割的。可能大家不经常关注的一点是根据 JLS 第 17 章中的说明,下面这两个操作,并不是原子性访问的:

因为大家当前的系统通常都是 64 位的,得益于此,这两个操作大多是原子性的了。但是其实根据 Java 的规范,这两个并不是原子性的,在 32 位的系统上就保证不了原子性。我这里直接引用 JLS 第 17 章的一段原话:
For the purposes of the Java programming language memory model, a single write to a non-volatile long or double value is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.
Writes and reads of volatile long and double values are always atomic.
翻译过来,简单来说非 volatile 的 long 或者 double 可能会按照两次单独的 32 位写更新,所以是非原子性的。volatile 的 long 或者 double 读取和写入都是原子性的。
为了说明我们这里的原子性,我引用一个 jcstress 中的一个例子:
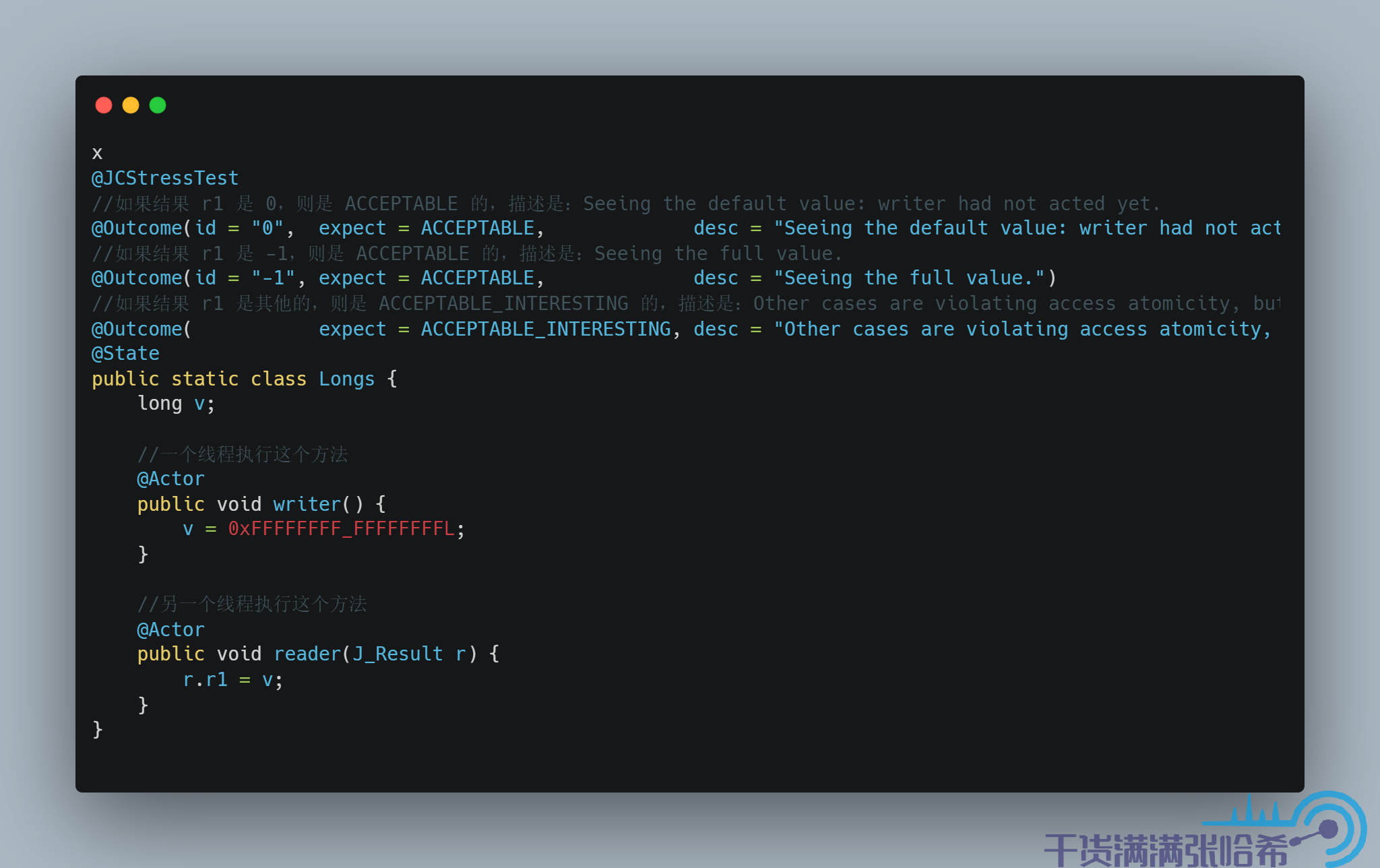
我们使用 Java 8 32bit (Java 9 之后就不再支持 32 位的机器了)的 JVM 运行这里的代码,结果是:

可以看到,结果不止 -1 和 0 这种我们代码中的指定的值,还有一些中间结果。
4. 字分裂(word tearing)字分裂(word tearing)即你更新一个字段,数组中的一个元素,会影响到另一个字段,数组中的另一个元素的值。例如处理器没有提供写单个 byte 的功能,假设最小维度是 int,在这样的处理器上更新 byte 数组,若只是简单地读取 byte 所在的整个 int,更新对应的 byte,然后将整个 int 再写回,这种做法是有问题的。Java 中没有字分裂现象,字段之间以及数组元素之间是独立的,更新一个字段或元素不能影响任何其它字段或元素的读取与更新。
为了说明什么是字分裂,举一个不太恰当的例子,即线程不安全的 BitSet。BitSet 的抽象是比特位集合(一个一个 0,1 这样,可以理解为一个 boolean 集合),底层实现是一个 long 数组,一个 long 保存 64 个比特位,每次更新都是读取这个 long 然后通过位运算更新对应的比特位,再更新回去。接口层面是一位一位更新,但是底层却是按照 long 的维度更新的(因为是底层 long 数组),很明显,如果没有同步锁,并发访问就会并发安全问题从而造成字分裂的问题:
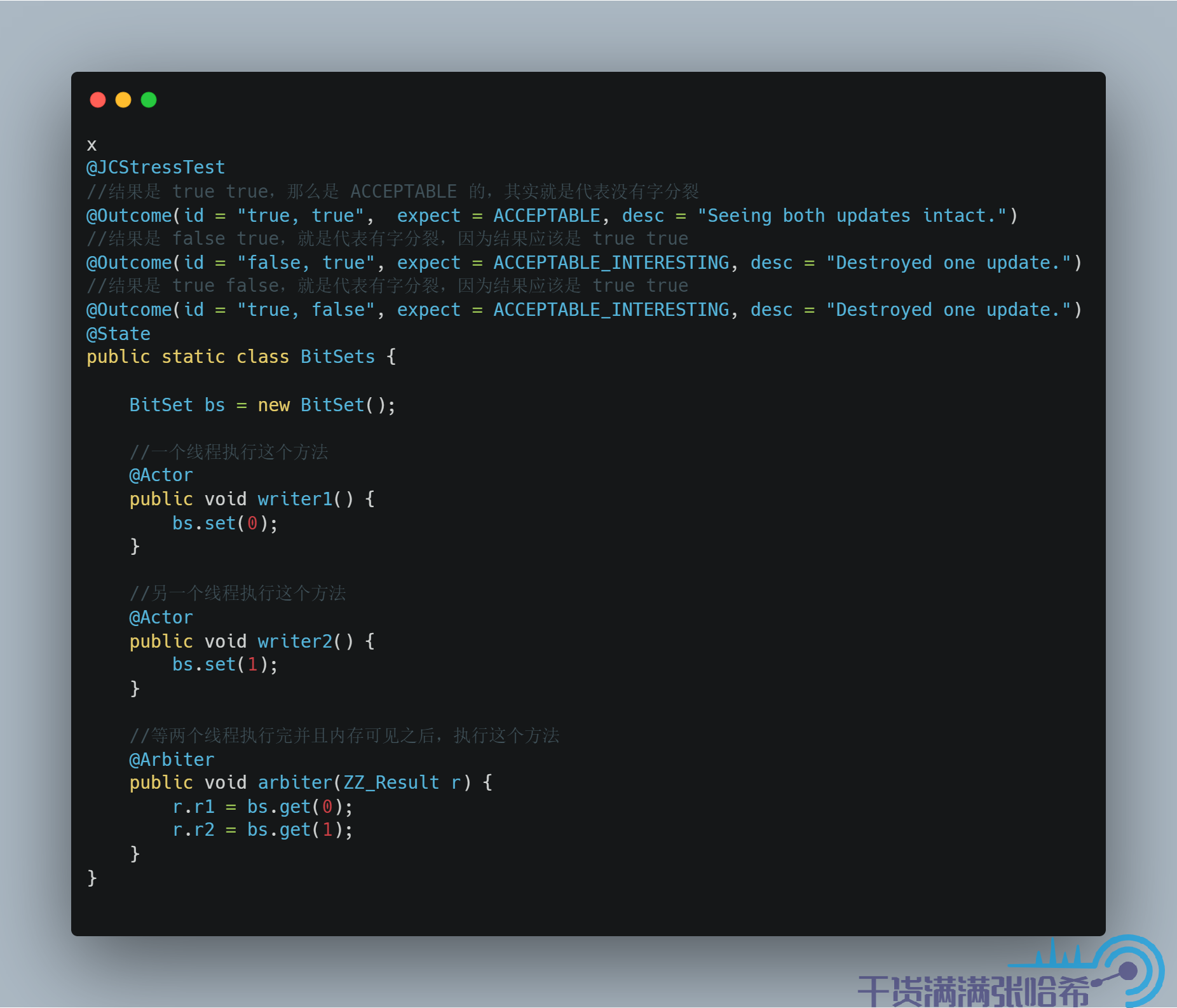
结果是:
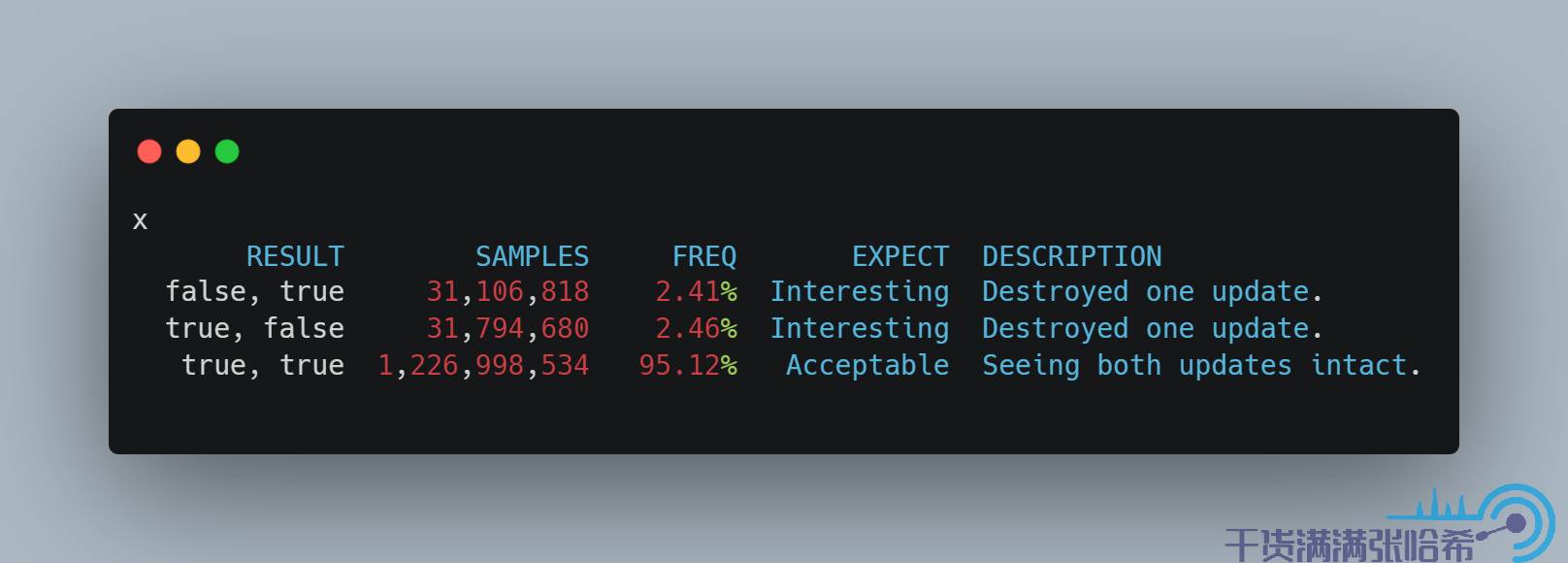
这里用了一个不太恰当的例子来说明什么是字分裂,Java 中是可以保证没有字分裂的,对应上面的 BitSet 的例子就是我们尝试更新一个 boolean 数组,这样结果就只会是 true true:
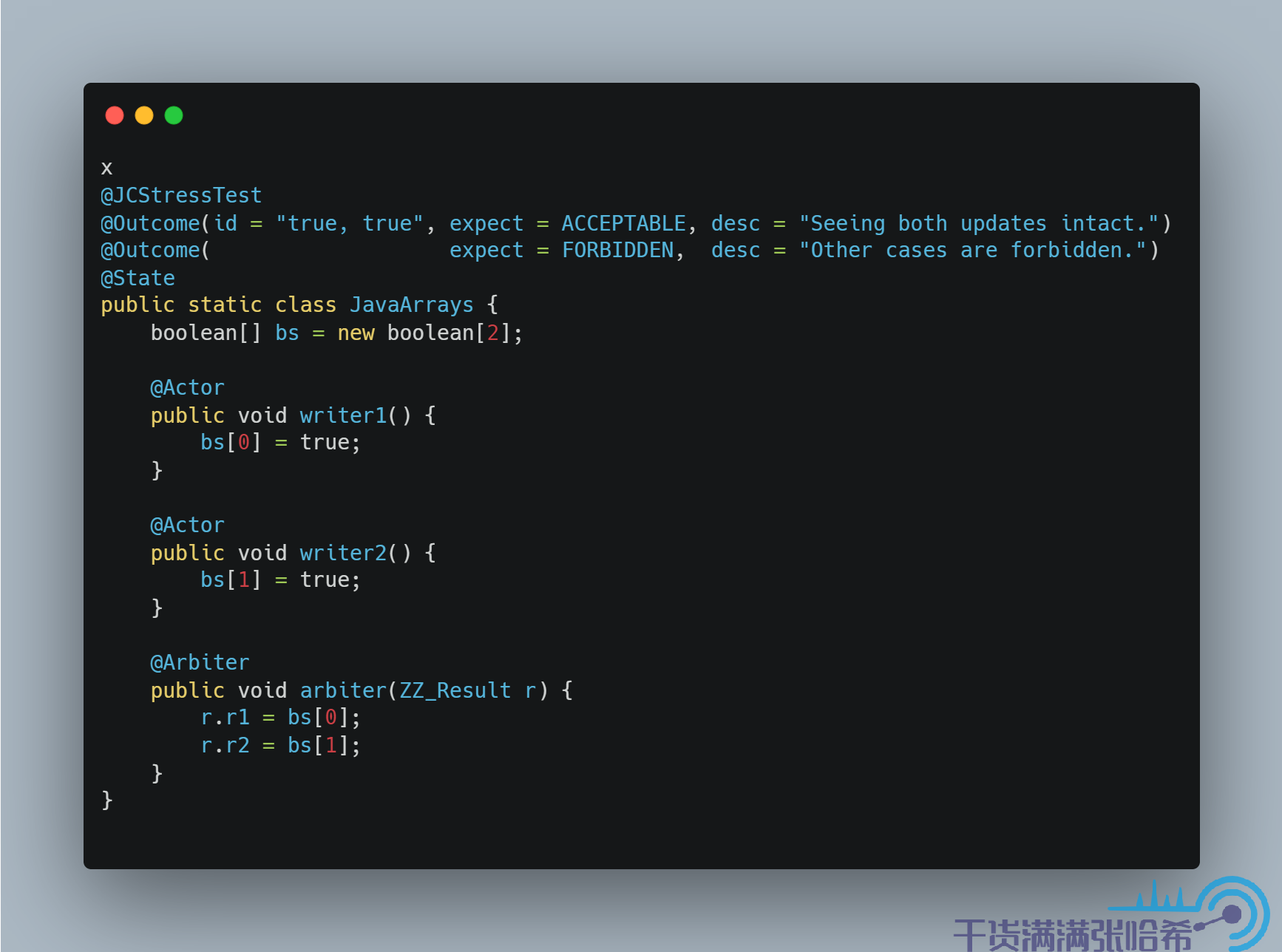
这个结果只会是 true true
接下来,我们将进入一个比较痛苦的章节了,内存屏障,不过大家也不用太担心,从我个人的经验来看,内存屏障很难理解的原因是因为网上基本上不会从 Java 已经为你屏蔽的底层细节去给你讲,直接理解会很难说服自己,于是就会猜想一些东西然后造成误解,所以本文不会上来丢给你 Doug Lea 抽象的并一直沿用至今的 Java 四种内存屏障(就是 LoadLoad,StoreStore,LoadStore 和 StoreLoad 这四个,其实通过后面的分析也能看出来,这四个内存屏障的设计对于现在的 CPU 来说已经有些过时了,现在用的更多的是 acquire, release 以及 fence)希望能通过笔者看的一些关于底层细节的文章论文中提取出便于大家理解的东西供大家参考,更好地更容易的理解内存屏障。
5. 内存屏障 5.1. 为何需要内存屏障内存屏障(Memory Barrier),也有叫内存栅栏(Memory Fence),还有的资料直接为了简便,就叫 membar,这些其实意思是一样的。内存屏障主要为了解决指令乱序带来了结果与预期不一致的问题,通过加入内存屏障防止指令乱序(或者称为重排序,reordering)。
那么为什么会有指令乱序呢?主要是因为 CPU 乱序(CPU乱序还包括 CPU 内存乱序以及 CPU 指令乱序)以及编译器乱序。内存屏障可以用于防止这些乱序。如果内存屏障对于编译器和 CPU 都生效,那么一般称为硬件内存屏障,如果只对编译器生效,那么一般被称为软件内存屏障。我们这里主要关注 CPU 带来的乱序,对于编译器的重排序我们会在最后简要介绍下。
5.2. CPU 内存乱序相关我们从 CPU 高速缓存以及缓存一致性协议出发,开始分析为何 CPU 中会有乱序。我们这里假设一种简易的 CPU 模型,请大家一定记住,实际的 CPU 要比这里列举的简易 CPU 模型复杂的多
5.2.1. 简易 CPU 模型 - CPU 高速缓存的出发点 - 减少 CPU Stall我们在这里会看到,现代的 CPU 的很多设计,一切以减少 CPU Stall 出发。什么是 CPU Stall 呢?举一个简单的例子,假设 CPU 需要直接读取内存中的数据(忽略其他的结构,例如 CPU 缓存,总线与总线事件等等):
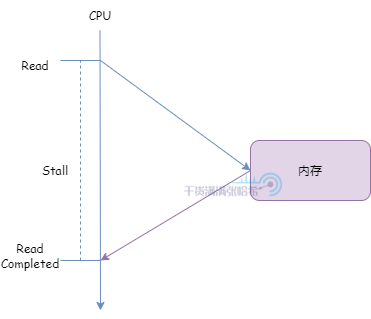
CPU 发出读取请求,在内存响应之前,CPU 需要一直等待,无法处理其他的事情。这一段 CPU 就是处于 Stall 状态。如果 CPU 一直直接从内存中读取,CPU 直接访问内存消耗时间很长,可能需要几百个指令周期,也就是每次访问都会有几百个指令周期内 CPU 处于 Stall 状态什么也干不了,这样效率会很低。一般需要引入若干个高速缓存(Cache)来减少 Stall:高速缓存即与处理器紧挨着的小型存储器,位于处理器和内存之间。
我们这里不关心多级高速缓存,以及是否存在多个 CPU 共用某一缓存的情况,我们就简单认为是下面这个架构:
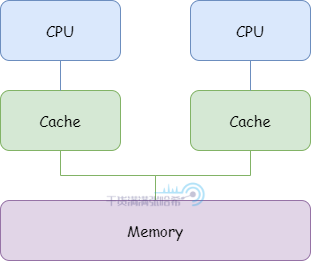
当需要读取一个地址的值时,访问高速缓存看是否存在:存在代表命中(hit),直接读取。不存在被称为缺失(miss)。同样的,如果需要写一个值到一个地址,这个地址在缓存中存在也就不需要访问内存了。大部分程序都表现出较高的局部性(locality):
- 如果处理器读或写一个内存地址,那么它很可能很快还会读或写同一个地址。
- 如果处理器读或写一个内存地址,那么它很可能很快还会读或写附近的地址。
针对局部性,高速缓存一般会一次操作不止一个字,而是一组临近的字,称为缓存行。
但是呢,由于告诉缓存的存在,就给更新内存带来了麻烦:当一个 CPU 需要更新一块缓存行对应内存的时候,它需要将其他 CPU 缓存中这块内存的缓存行也置为失效。为了维持每个 CPU 的缓存数据一致性,引入了缓存一致性协议(Cache Coherence Protocols)
5.2.2. 简易 CPU 模型 - 一种简单的缓存一致性协议(实际的 CPU 用的要比这个复杂) - MESI现代的缓存一致性的协议以及算法非常复杂,缓存行可能会有数十种不同的状态。这里我们并不需要研究这种复杂的算法,我们这里引入一个最经典最简单的缓存一致性协议即 4 状态 MESI 协议(再次强调,实际的 CPU 用的协议要比这个复杂,MESI 其实本身有些问题解决不了),MESI 其实指的就是缓存行的四个状态:
- Modified:缓存行被修改,最终一定会被写回入主存,在此之前其他处理器不能再缓存这个缓存行。
- Exclusive:缓存行还未被修改,但是其他的处理器不能将这个缓存行载入缓存
- Shared:缓存行未被修改,其他处理器可以加载这个缓存行到缓存
- Invalid:缓存行中没有有意义的数据
根据我们前面的 CPU 缓存结构图中所示,假设所有 CPU 都共用在同一个总线上,则会有如下这些信息在总线上发送:
- Read:这个事件包含要读取的缓存行的物理地址。
- Read Response:包含前面的读取事件请求的数据,数据来源可能是内存或者是其他高速缓存,例如,如果请求的数据在其他缓存处于 modified 状态的话,那么必须从这个缓存读取缓存行数据作为 Read Response
- Invalidate:这个事件包含要过期掉的缓存行的物理地址。其他的高速缓存必须移除这个缓存行并且响应 Invalidate Acknowledge 消息。
- Invalidate Acknowledge:收到 Invalidate 消息移除掉对应的缓存行之后,回复 Invalidate Acknowledge 消息。
- Read Invalidate:是 Read 消息还有 Invalidate 消息的组合,包含要读取的缓存行的物理地址。既读取这个缓存行并且需要 Read Response 消息响应,同时发给其他的高速缓存,移除这个缓存行并且响应 Invalidate Acknowledge 消息。
- Writeback:这个消息包含要更新的内存地址以及数据。同时,这个消息也允许状态为 modified 的缓存行被剔除,以给其他数据腾出空间。
缓存行状态转移与事件的关系:
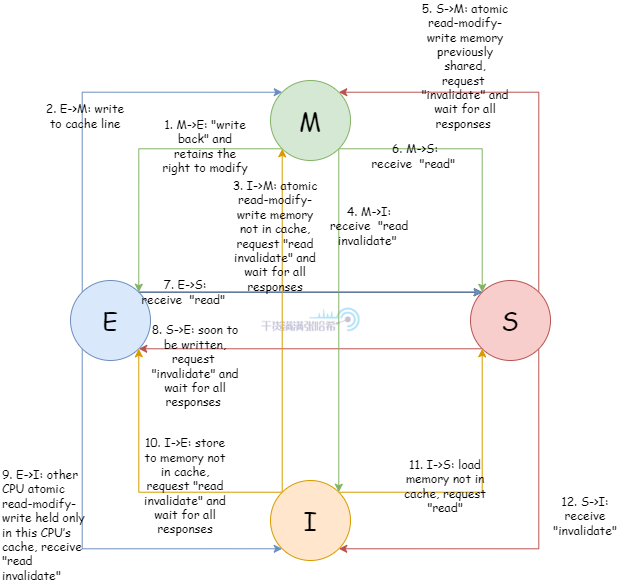
这里只是列出这个图,我们不会深入去讲的,因为 MESI 是一个非常精简的协议,具体实现的时候会有很多额外的问题 MESI 无法解决,如果详细的去讲,会把读者绕进去,读者会思考在某个极限情况下这个协议要怎么做才能保证正确,但是 MESI 实际上解决不了这些。在实际的实现中,CPU 一致性协议要比 MESI 复杂的多得多,但是一般都是基于 MESI 扩展的。
举一个简单的 MESI 的例子:
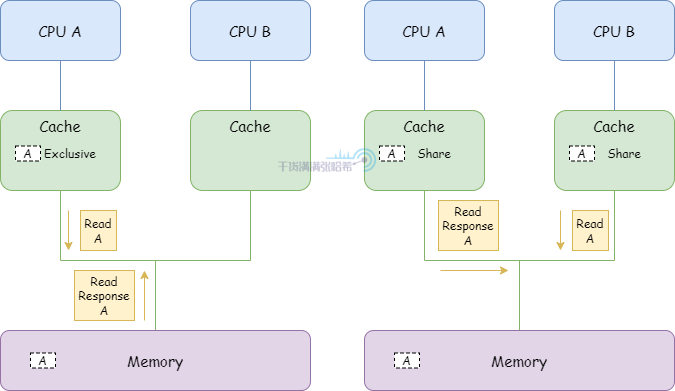
1.CPU A 发送 Read 从地址 a 读取数据,收到 Read Response 将数据存入他的高速缓存并将对应的缓存行置为 Exclusive
2.CPU B 发送 Read 从地址 a 读取数据,CPU A 检测到地址冲突,CPU A 响应 Read Response 返回缓存中包含 a 地址的缓存行数据,之后,地址 a 的数据对应的缓存行被 A 和 B 以 Shared 状态装入缓存
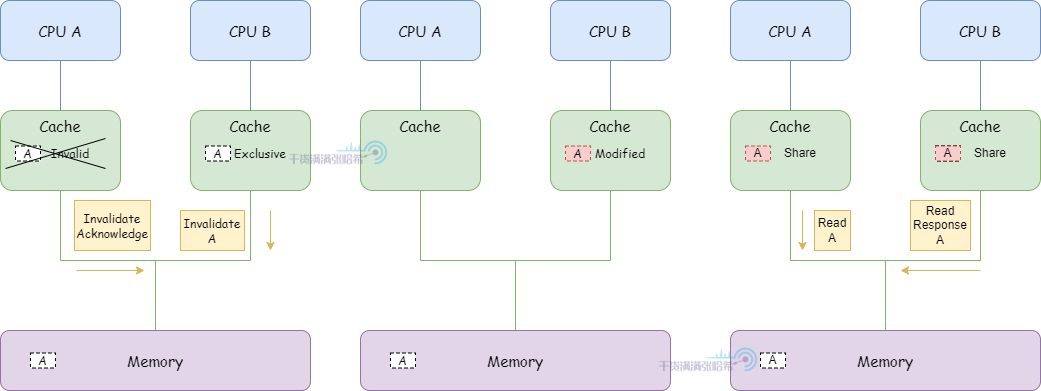
3.CPU B 对于 a 马上要进行写操作,发送 Invalidate,等待 CPU A 的 Invalidate Acknowledge 响应之后,状态修改为 Exclusive。CPU A 收到 Invalidate 之后,将 a 所在的缓存行状态置为 Invalid 失效
4.CPU B 修改数据存储到包含地址 a 的缓存行上,缓存行状态置为 modified
5.这时候 CPU A 又需要 a 数据,发送 Read 从地址 a 读取数据,CPU B 检测到地址冲突,CPU B 响应 Read Response 返回缓存中包含 a 地址的缓存行数据,之后,地址 a 的数据对应的缓存行被 A 和 B 以 Shared 状态装入缓存
我们这里可以看到,MESI 协议中,发送 Invalidate 消息需要当前 CPU 等待其他 CPU 的 Invalidate Acknowledge,也就是这里有 CPU Stall。为了避免这个 Stall,引入了 Store Buffer
5.2.3. 简易 CPU 模型 - 避免等待 Invalidate Response 的 Stall - Store Buffer为了避免这种 Stall,在 CPU 与 CPU 缓存之间添加 Store Buffer,如下图所示:
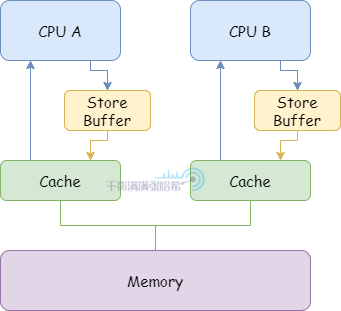
有了 Store Buffer,CPU 在发送 Invalidate 消息的时候,不用等待 Invalidate Acknowledge 的返回,将修改的数据直接放入 Store Buffer。如果收到了所有的 Invalidate Acknowledge 再从 Store Buffer 放入 CPU 的高速缓存的对应缓存行中。但是加入的这个 Store Buffer 又带来了新的问题:
假设有两个变量 a 和 b,不会处于同一个缓存行,初始都是 0,a 现在位于 CPU A 的缓存行中,b 现在位于 CPU B 的缓存行中:
假设 CPU B 要执行下面的代码:

我们肯定是期望最后 b 会等于 2 的。但是真的会如我们所愿么?我们来详细看下下面这个运行步骤:
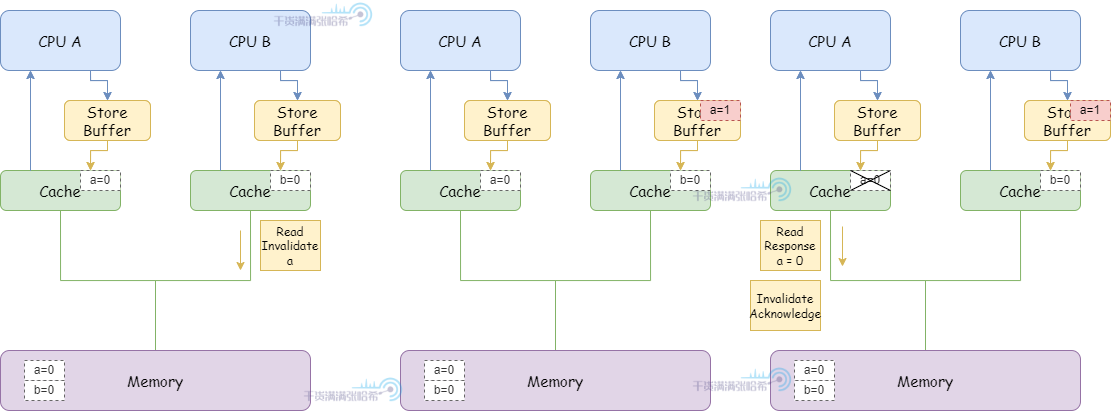
1.CPU B 执行 a = 1:
(1)由于 CPU B 缓存中没有 a,并且要修改,所以发布 Read Invalidate 消息(因为是要先把包含 a 的整个缓存行读取后才能更新,所以发的是 Read Invalidate,而不只是 Invalidate)。
(2)CPU B 将 a 的修改(a=1)放入 Storage Buffer
(3)CPU A 收到 Read Invalidate 消息,将 a 所在的缓存行标记为 Invalid 并清除出缓存,并响应 Read Response(a=0) 和 Invalidate Acknowlegde。

2.CPU B 执行 b = a + 1:
(1)CPU B 收到来自于 CPU A 的 Read Response,这时候这里面 a 还是等于 0。
(2)CPU B 将 a + 1 的结果(0+1=1)存入缓存中已经包含的 b。
3.CPU B 执行 assert(b == 2) 失败
这个错误的原因主要是我们在加载到缓存的时候没考虑从 store buffer 最新的值,所以我们可以加上一步,在加载到缓存的时候从 store buffer 读取最新的值。这样,就能保证上面我们看到的结果 b 最后是 2:

我们下面再来看一个示例:假设有两个变量 a 和 b,不会处于同一个缓存行,初始都是 0。假设 CPU A (缓存行里面包含 b,这个缓存行状态是 Exclusive)执行:

假设 CPU B 执行:

如果一切按照程序顺序预期执行,那么我们期望 CPU B 执行 assert(a == 1) 是成功的,但是我们来看下面这种执行流程:
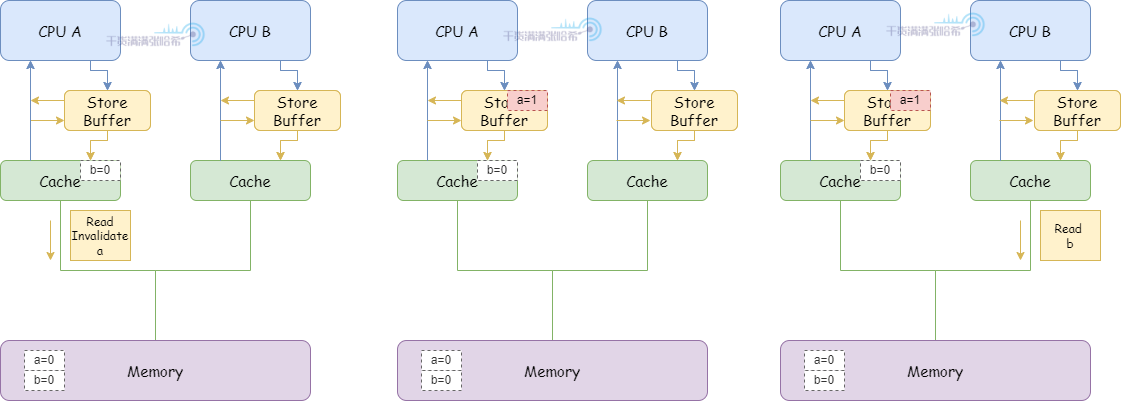
1.CPU A 执行 a = 1:
(1)CPU A 缓存里面没有 a,并且要修改,所以发布 Read Invalidate 消息。
(2)CPU A 将 a 的修改(a=1)放入 Storage Buffer
2.CPU B 执行 while (b == 0) continue:
(1)CPU B 缓存里面没有 b,发布 Read 消息。
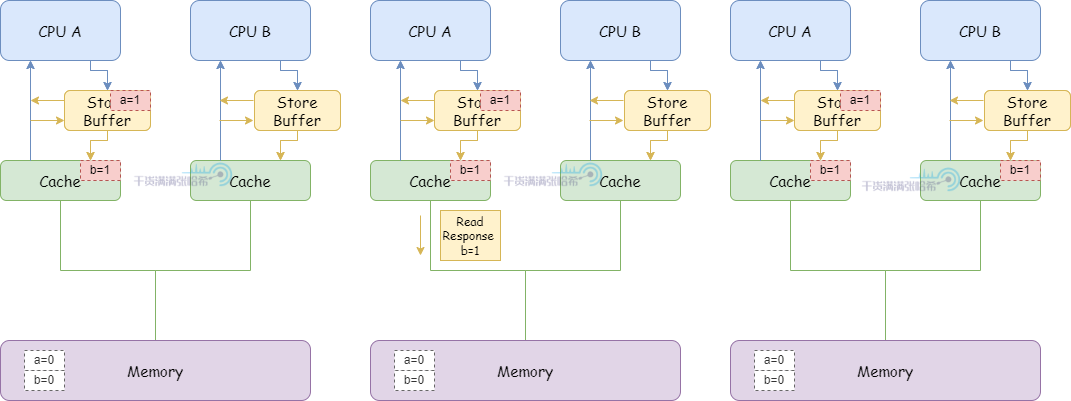
3.CPU A 执行 b = 1:
(1)CPU A 缓存行里面有 b,并且状态是 Exclusive,直接更新缓存行。
(2)之后,CPU A 收到了来自于 CPU B 的关于 b 的 Read 消息。
(3)CPU A 响应缓存中的 b = 1,发送 Read Response 消息,并且缓存行状态修改为 Shared
(4)CPU B 收到 Read Response 消息,将 b 放入缓存
(5)CPU B 代码可以退出循环了,因为 CPU B 看到 b 此时为 1
4.CPU B 执行 assert(a == 1),但是由于 a 的更改还没更新,所以失败了。
像这种乱序,CPU 一般是无法自动控制的,但是一般会提供内存屏障指令,告诉 CPU 防止乱序,例如:

smp_mb() 会让 CPU 将 Store Buffer 中的内容刷入缓存。加入这个内存屏障指令后,执行流程变成:
1.CPU A 执行 a = 1:
(1)CPU A 缓存里面没有 a,并且要修改,所以发布 Read Invalidate 消息。
(2)CPU A 将 a 的修改(a=1)放入 Storage Buffer
2.CPU B 执行 while (b == 0) continue:
(1)CPU B 缓存里面没有 b,发布 Read 消息。
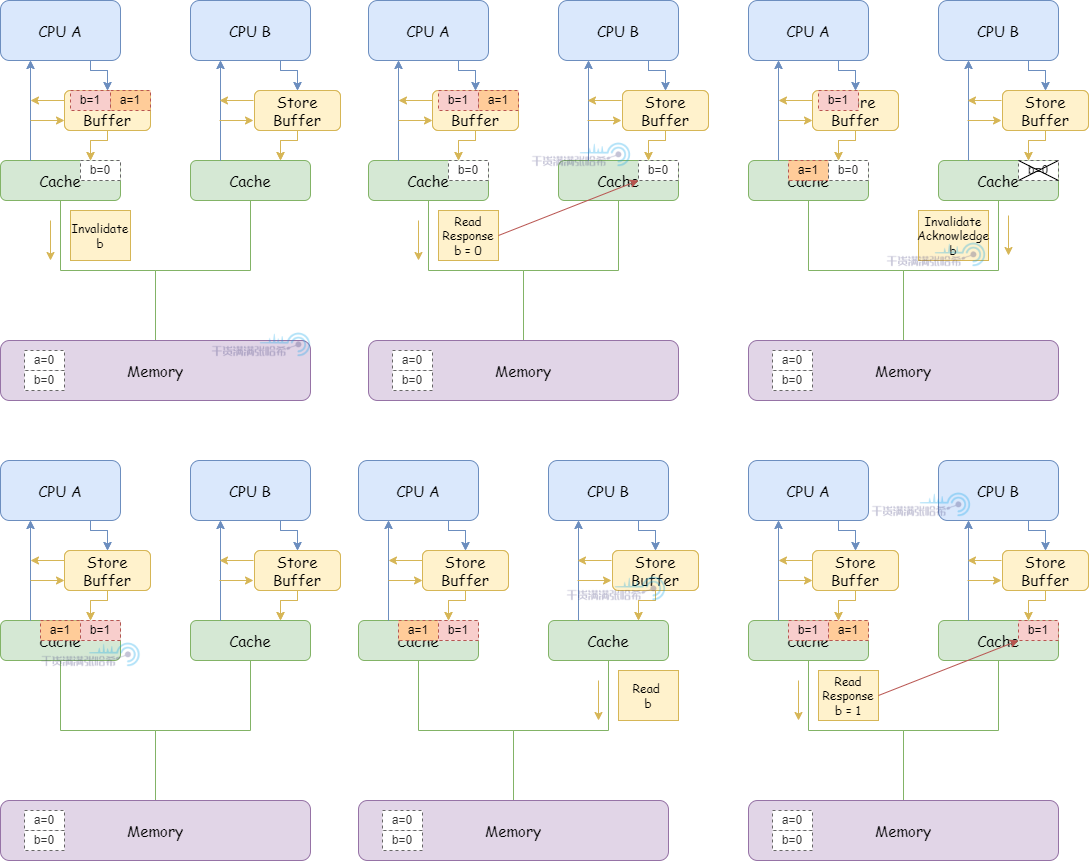
3.CPU B 执行 smp_mb():
(1)CPU B 将当前 Store Buffer 的所有条目打上标记(目前这里只有 a,就是对 a 打上标记)
4.CPU A 执行 b = 1:
(1)CPU A 缓存行里面有 b,并且状态是 Exclusive,但是由于 Store Buffer 中有标记的条目 a,不直接更新缓存行,而是放入 Store Buffer(与 a 不同,没有标记)。并发出 Invalidate 消息。
(2)之后,CPU A 收到了来自于 CPU B 的关于 b 的 Read 消息。
(3)CPU A 响应缓存中的 b = 0,发送 Read Response 消息,并且缓存行状态修改为 Shared
(4)CPU B 收到 Read Response 消息,将 b 放入缓存
(5)CPU B 代码不断循环,因为 CPU B 看到 b 还是 0
(6)CPU A 收到前面对于 a 的 "Read Invalidate" 相关的消息响应,将 Store Buffer 中打好标记的 a 条目刷入缓存,这个缓存行状态为 modified。
(7)CPU B 收到 CPU A 发的 Invalidate b 的消息,将 b 的缓存行失效,回复 Invalidate Acknowledge
(8)CPU A 收到 Invalidate Acknowledge,将 b 从 Store Buffer 刷入缓存。
(9)由于 CPU B 不断读取 b,但是 b 已经不在缓存中了,所以发送 Read 消息。
(10)CPU A 收到 CPU B 的 Read 消息,设置 b 的缓存行状态为 shared,返回缓存中 b = 1 的 Read Response
(11)CPU B 收到 Read Response,得知 b = 1,放入缓存行,状态为 shared
5.CPU B 得知 b = 1,退出 while (b == 0) continue 循环
6.CPU B 执行 assert(a == 1)(这个比较简单,就不画图了):
(1)CPU B 缓存中没有 a,发出 Read 消息。
(2)CPU A 从缓存中读取 a = 1,响应 Read Response
(3)CPU B 执行 assert(a == 1) 成功
Store Buffer 一般都会比较小,如果 Store Buffer 满了,那么还是会发生 Stall 的问题。我们期望 Store Buffer 能比较快的刷入 CPU 缓存,这是在收到对应的 Invalidate Acknowledge 之后进行的。但是,其他的 CPU 可能在忙,没发很快应对收到的 Invalidate 消息并响应 Invalidate Acknowledge,这样可能造成 Store Buffer 满了导致 CPU Stall 的发生。所以,可以引入每个 CPU 的 Invalidate queue 来缓存要处理的 Invalidate 消息。
5.2.5. 简易 CPU 模型 - 解耦 CPU 的 Invalidate 与 Store Buffer - Invalidate Queues加入 Invalidate Queues 之后,CPU 结构如下所示:
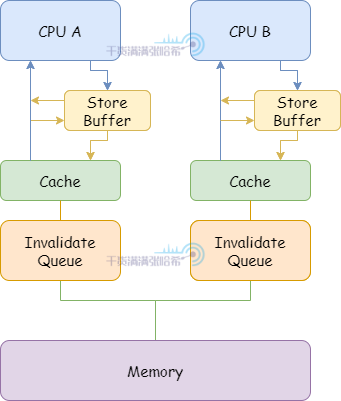
有了 Invalidate Queue,CPU 可以将 Invalidate 放入这个队列之后立刻将 Store Buffer 中的对应数据刷入 CPU 缓存。同时,CPU 在想主动发某个缓存行的 Invalidate 消息之前,必须检查自己的 Invalidate Queue 中是否有相同的缓存行的 Invalidate 消息。如果有,必须等处理完自己的 Invalidate Queue 中的对应消息再发。
同样的,Invalidate Queue 也带来了乱序执行。
5.2.6. 简易 CPU 模型 - 由于 Invalidate Queues 带来的进一步乱序 - 需要内存屏障假设有两个变量 a 和 b,不会处于同一个缓存行,初始都是 0。假设 CPU A (缓存行里面包含 a(shared), b(Exclusive))执行:

CPU B(缓存行里面包含 a(shared))执行:

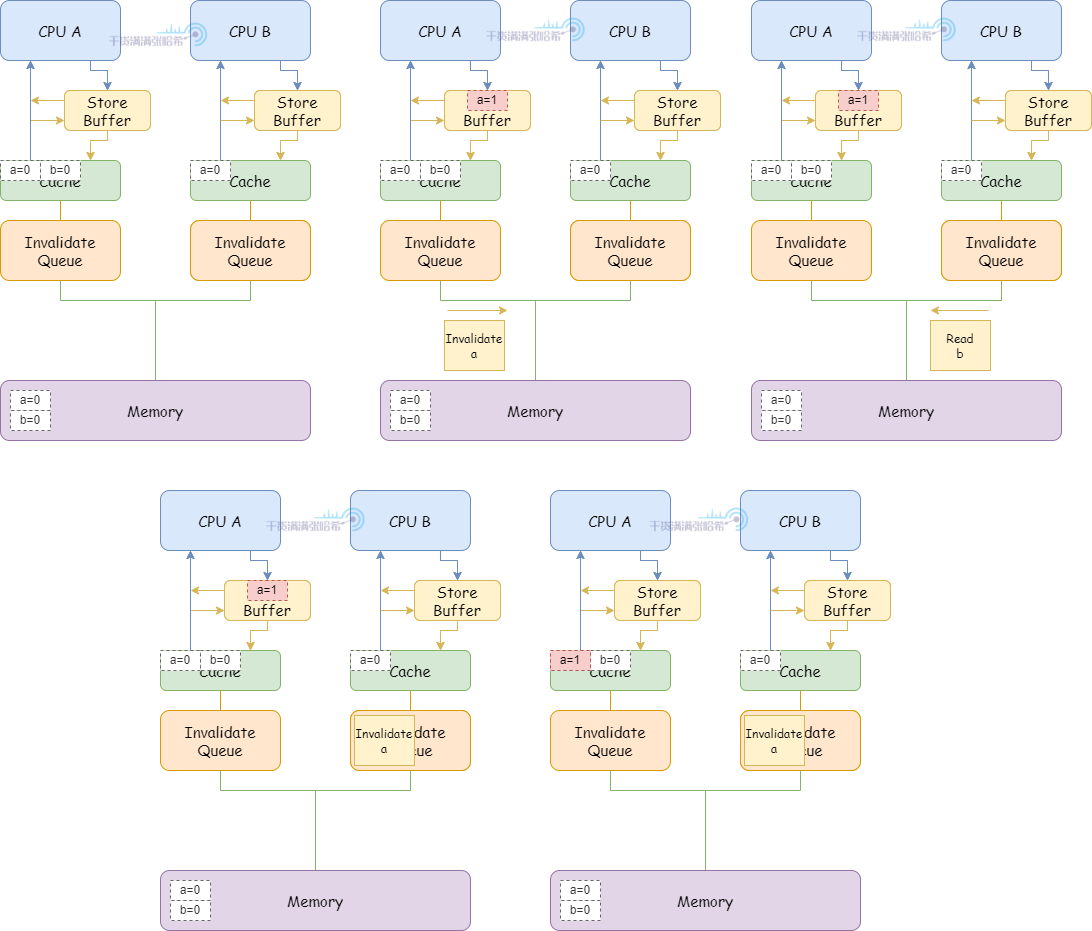
1.CPU A 执行 a = 1:
(1)CPU A 缓存里面有 a(shared),CPU A 将 a 的修改(a=1)放入 Store Buffer,发送 Invalidate 消息。
2.CPU B 执行 while (b == 0) continue:
(1)CPU B 缓存里面没有 b,发布 Read 消息。
(2)CPU B 收到 CPU A 的 Invalidate 消息,放入 Invalidate Queue 之后立刻返回。
(3)CPU A 收到 Invalidate 消息的响应,将 Store Buffer 中的缓存行刷入 CPU 缓存
3.CPU A 执行 smp_mb():
(1)因为 CPU A 已经把 Store Buffer 中的缓存行刷入 CPU 缓存,所以这里直接通过
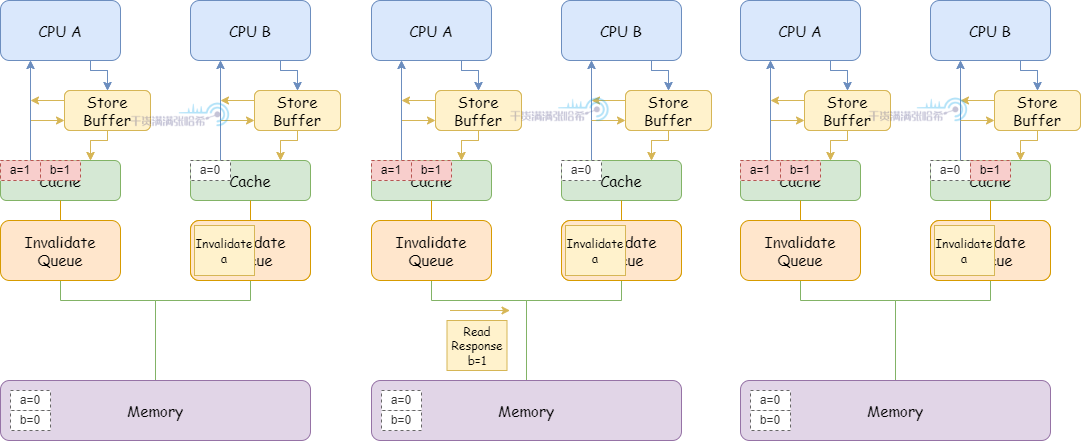
4.CPU A 执行 b = 1:
(1)因为 CPU A 本身包含 b 的缓存行 (Exclusive),直接更新缓存行即可。
(2)CPU A 收到 CPU B 之前发的 Read 消息,将 b 的缓存行状态更新为 Shared,之后发送 Read Response 包含 b 的最新值
(3)CPU B 收到 Read Response, b 的值为 1
5.CPU B 退出循环,开始执行 assert(a == 1)
(1)由于目前关于 a 的 Invalidate 消息还在 Invalidate queue 中没有处理,所以 CPU B 看到的还是 a = 0,assert 失败
所以,我们针对这种乱序,在 CPU B 执行的代码中也加入内存屏障,这里内存屏障不仅等待 CPU 刷完所有的 Store Buffer,还要等待 CPU 的 Invalidate Queue 全部处理完。加入内存屏障,CPU B 执行的代码是:

这样,在前面的第 5 步,CPU B 退出循环,执行 assert(a == 1) 之前需要等待 Invalidate queue 处理完:
(1)处理 Invalidate 消息,将 b 置为 Invalid
(2)继续代码,执行 assert(a == 1),这时候缓存内不存在 b,需要发 Read 消息,这样就能看到 b 的最新值 1 了,assert 成功。
我们前面提到,在我们前面提到的 CPU 模型中,smp_mb() 这个内存屏障指令,做了两件事:等待 CPU 刷完所有的 Store Buffer,等待 CPU 的 Invalidate Queue 全部处理完。但是,对于我们这里 CPU A 与 CPU B 执行的代码中的内存屏障,并不是每次都要这两个操作同时存在:
所以,一般 CPU 还会抽象出更细粒度的内存屏障指令,我们这里管等待 CPU 刷完所有的 Store Buffer 的指令叫做写内存屏障(Write Memory Buffer),等待 CPU 的 Invalidate Queue 全部处理完的指令叫做读内存屏障(Read Memory Buffer)。
5.2.8. 简易 CPU 模型 - 总结我们这里通过一个简单的 CPU 架构出发,层层递进,讲述了一些简易的 CPU 结构以及为何会需要内存屏障,可以总结为下面这个简单思路流程图:
- CPU 每次直接访问内存太慢,会让 CPU 一直处于 Stall 等待。为了减少 CPU Stall,加入了 CPU 缓存。
- CPU 缓存带来了多 CPU 间的缓存不一致性,所以通过 MESI 这种简易的 CPU 缓存一致性协议协调不同 CPU 之间的缓存一致性
- 对于 MESI 协议中的一些机制进行优化,进一步减少 CPU Stall:
- 通过将更新放入 Store Buffer,让更新发出的 Invalidate 消息不用 CPU Stall 等待 Invalidate Response。
- Store Buffer 带来了指令(代码)乱序,需要内存屏障指令,强制当前 CPU Stall 等待刷完所有 Store Buffer 中的内容。这个内存屏障指令一般称为写屏障。
- 为了加快 Store Buffer 刷入缓存,增加 Invalidate Queue,
CPU 指令的执行,也可能会乱序,我们这里只说一种比较常见的 - 指令并行化。
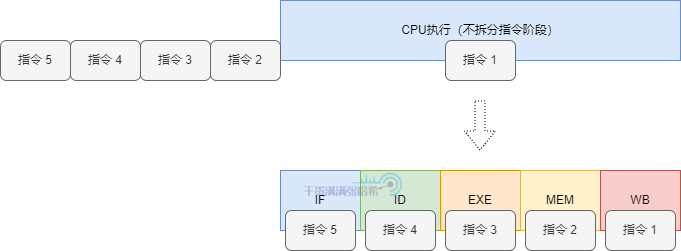
5.3.1. 增加 CPU 执行效率 - CPU 流水线模式(CPU Pipeline)现代 CPU 在执行指令时,是以指令流水线的模式来运行的。因为 CPU 内部也有不同的组件,我们可以将执行一条指令分成不同阶段,不同的阶段涉及的组件不同,这样伪解耦可以让每个组件独立的执行,不用等待一个指令完全执行完再处理下一个指令。
一般分为如下几个阶段:取指(Instrcution Fetch,IF)、译码(Instruction Decode,ID)、执行(Execute,EXE)、存取(Memory,MEM)、写回(Write-Back, WB)
由于指令的数据是否就绪也是不确定的,比如下面这个例子:

倘若数据 a 没有就绪,还没有载入到寄存器,那么我们其实没必要 Stall 等待加载 a,可以先执行 c = 1; 由此,我们可以将程序中,可以并行的指令提取出来同时安排执行,CPU 乱序流水线(Out of order execution Pipeline)就是基于这种思路:
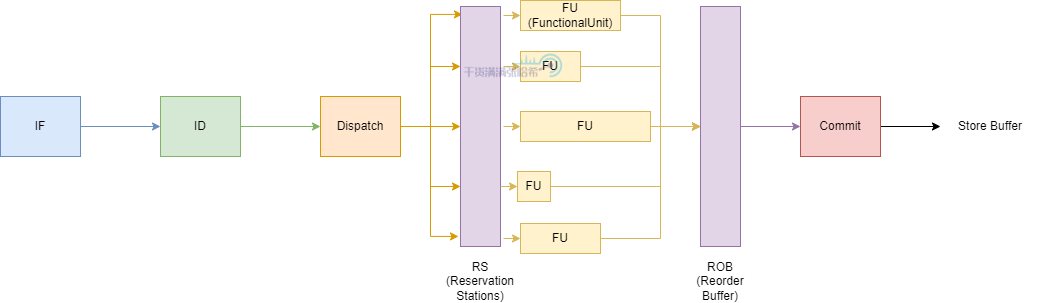
如图所示,CPU 的执行阶段分为:
- Instructions Fetch:批量拉取一批指令,进行指令分析,分析其中的循环以及依赖,分支预测等等
- Instruction Decode:指令译码,与前面的流水线模式大同小异
- Reservation stations:需要操作数输入的指令,如果输入就绪,就进入 Functoinal Unit (FU) 处理,如果没有没有就绪就监听 Bypass network,数据就绪发回信号到 Reservation stations,让指令进图 FU 处理。
- Functional Unit:处理指令
- Reorder Buffer:会将指令按照原有程序的顺序保存,这些指令会在被 dispatched 后添加到列表的一端,而当他们完成执行后,从列表的另一端移除。通过这种方式,指令会按他们 dispatch 的顺序完成。
这样的结构设计下,可以保证写入 Store Buffer 的顺序,与原始的指令顺序一样。但是加载数据,以及计算,是并行执行的。前面我们已经知道了在我们的简易 CPU 架构里面,有着多 CPU 缓存 MESI, Store Buffer 以及 Invalidate Queue 导致读取不到最新的值,这里的乱序并行加载以及处理更加剧了这一点。并且,结构设计下,仅能保证检测出同一个线程下的指令之间的互相依赖,保证这样的互相依赖之间的指令执行顺序是对的,但是多线程程序之间的指令依赖,CPU 批量取指令以及分支预测是无法感知的。所以还是会有乱序。这种乱序,同样可以通过前面的内存屏障避免。
5.4. 实际的 CPU实际的 CPU 多种多样,有着不同的 CPU 结构设计以及不同的 CPU 缓存一致性协议,就会有不同种类的乱序,如果每种单独来看,就太复杂了。所以,大家通过一种标准来抽象描述不同的 CPU 的乱序现象(即第一个操作为 M,第二个操作为 N,这两个操作是否会乱序,是不是很像 Doug Lea 对于 JMM 的描述,其实 Java 内存模型也是参考这个设计的),参考下面这个表格:
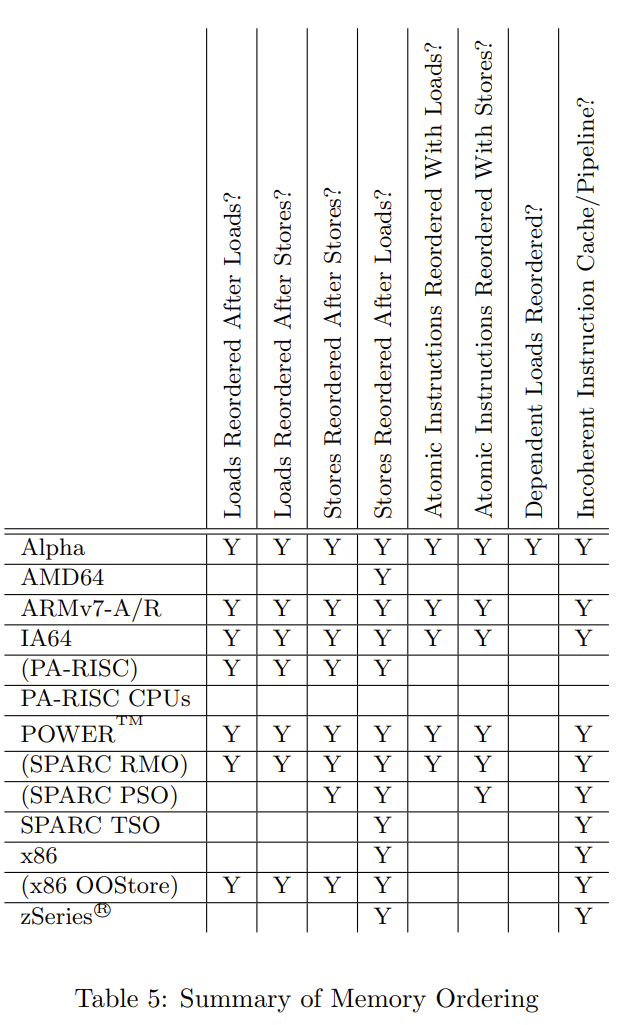
我们先来说一下每一列的意思:
- Loads Reordered After Loads:第一个操作是读取,第二个也是读取,是否会乱序。
- Loads Reordered After Stores:第一个操作是读取,第二个是写入,是否会乱序。
- Stores Reordered After Stores:第一个操作是写入,第二个也是写入,是否会乱序。
- Stores Reordered After Loads:第一个操作是写入,第二个是读取,是否会乱序。
- Atomic Instructions Reordered With Loads:两个操作是原子操作(一组操作,同时发生,例如同时修改两个字这种指令)与读取,这两个互相是否会乱序。
- Atomic Instructions Reordered With Stores:两个操作是原子操作(一组操作,同时发生,例如同时修改两个字这种指令)与写入,这两个互相是否会乱序。
- Dependent Loads Reordered:如果一个读取依赖另一个读取的结果,是否会乱序。
- Incoherent Instruction Cache/Pipeline:是否会有指令乱序执行。
举一个例子来看即我们自己的 PC 上面常用的 x86 结构,在这种结构下,仅仅会发生 Stores Reordered After Loads 以及 Incoherent Instruction Cache/Pipeline。其实后面要提到的 LoadLoad,LoadStore,StoreLoad,StoreStore 这四个 Java 中的内存屏障,为啥在 x86 的环境下其实只需要实现 StoreLoad,其实就是这个原因。
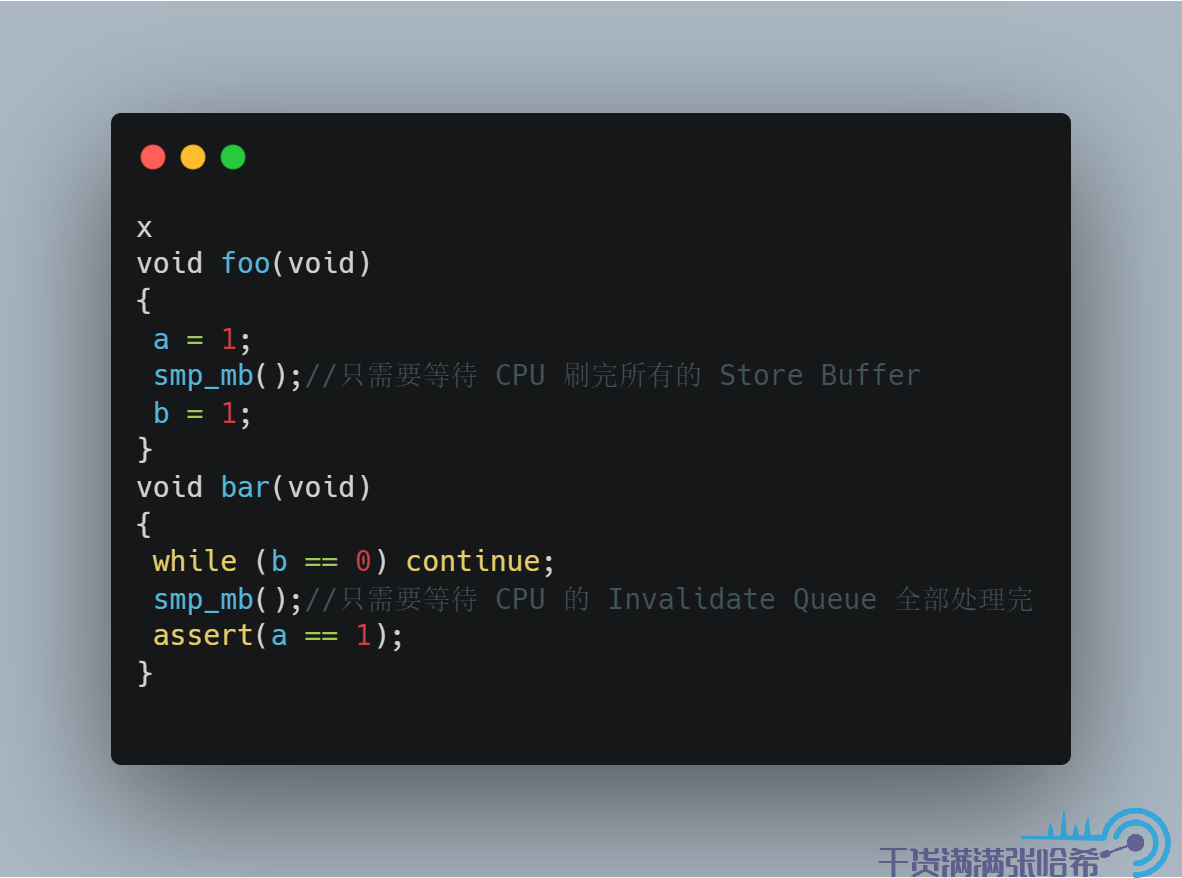
5.5. 编译器乱序除了 CPU 乱序以外,在软件层面还有编译器优化重排序导致的,其实编译器优化的一些思路与上面说的 CPU 的指令流水线优化其实有些类似。比如编译器也会分析你的代码,对相互不依赖的语句进行优化。对于相互没有依赖的语句,就可以随意的进行重排了。但是同样的,编译器也是只能从单线程的角度去考虑以及分析,并不知道你程序在多线程环境下的依赖以及联系。再举一个简单的例子,假设没有任何 CPU 乱序的环境下,有两个变量 x = 0,y = 0,线程 1 执行:

线程 2 执行:

那么线程 2 是可能 assert 失败的,因为编译器可能会让 x = 1 与 y = 1 之间乱序。
编译器乱序,可以通过增加不同操作系统上的编译器屏障语句进行避免。例如线程一执行:

这样就不会出现 x = 1 与 y = 1 之间乱序的情况。
同时,我们在实际使用的时候,一般内存屏障指的是硬件内存屏障,即通过硬件 CPU 指令实现的内存屏障,这种硬件内存屏障一般也会隐式地带上编译器屏障。编译器屏障一般被称为软件内存屏障,仅仅是控制编译器软件层面的屏障,举一个例子即 C++ 中的 volaile,它与 Java 中的 volatile 不一样, C++ 中的 volatile 仅仅是禁止编译器重排即有编译器屏障,但是无法避免 CPU 乱序。
以上,我们就基本搞清楚了乱序的来源,以及内存屏障的作用。接下来,我们即将步入正题,开始我们的 Java 9+ 内存模型之旅。在这之前,再说一件需要注意的事情:为什么最好不要自己写代码验证 JMM 的一些结论,而是使用专业的框架去测试
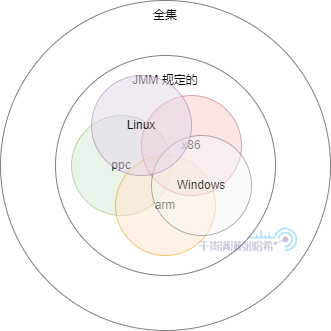
6. 为什么最好不要自己写代码验证 JMM 的一些结论通过前面的一系列分析我们知道,程序乱序的问题错综复杂,假设一段代码,没有任何限制所有可能的输出结果是如下图所示这个全集:

在 Java 内存模型的限制下,可能的结果被限制到了所有乱序结果中的一个子集:
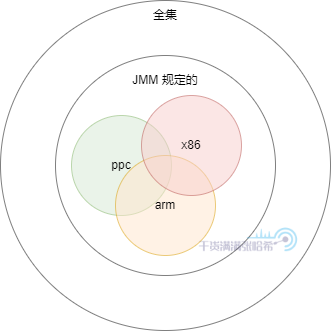
在 Java 内存模型的限制下,在不同的 CPU 架构上,CPU 乱序情况不同,有的场景有的 CPU 会乱序,有的则不会,但是都在 JMM 的范围内所以是合理的,这样所有可能的结果集又被限制到 JMM 的一个个不同子集:
在 Java 内存模型的限制下,在不同的操作系统的编译器编译出来的 JVM 的代码执行顺序不同,底层系统调用定义不同,在不同操作系统执行的 Java 代码又有可能会有些微小的差异,但是由于都在 JMM 的限制范围内,所以也是合理的:
最后呢,在不同的执行方式以及 JIT 编译下,底层执行的代码还是有差异的,进一步导致了结果集的分化:
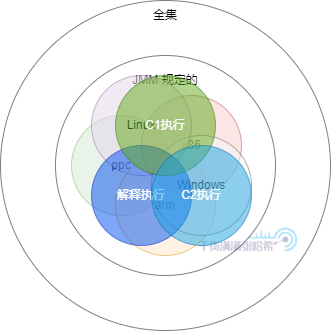
所以,如果你自己编写代码在自己的唯一一台电脑唯一一种操作系统上面去试,那么你所能试出来的结果集只是 JMM 的一个子集,很可能有些乱序结果你是看不到的。并且,有些乱序执行次数少或者没走到 JIT 优化,还看不到,所以,真的不建议你自己写代码去实验。
那么应该怎么做呢?使用较为官方的用来测试并发可见性的框架 - jcstress,这个框架虽然不能模拟不同的 CPU 架构和不同操作系统,但是能让你排除不同执行(解释执行,C1执行,C2执行)以及测试压力不足次数少的原因,后面的所有讲解都会附上对应的 jcstress 代码实例供大家使用。
7. 层层递进可见性与 Java 9+ 内存模型的对应 API这里主要参考了 Aleksey 大神的思路,去总结出不同层次,层层递进的 Java 中的一些内存可见性限制性质以及对应的 API。Java 9+ 中,将原来的普通变量(非 volatile,final 变量)的普通访问,定义为了 Plain。普通访问,没有对这个访问的地址做任何屏障(不同 GC 的那些屏障,比如分代 GC 需要的指针屏障,不是这里要考虑的,那些屏障只是 GC 层面的,对于这里的可见性没啥影响),会有前面提到的各种乱序。那么 Java 9+ 内存模型中究竟提出了那些限制以及对应这些限制的 API 是啥,我们接下层层递进讲述。
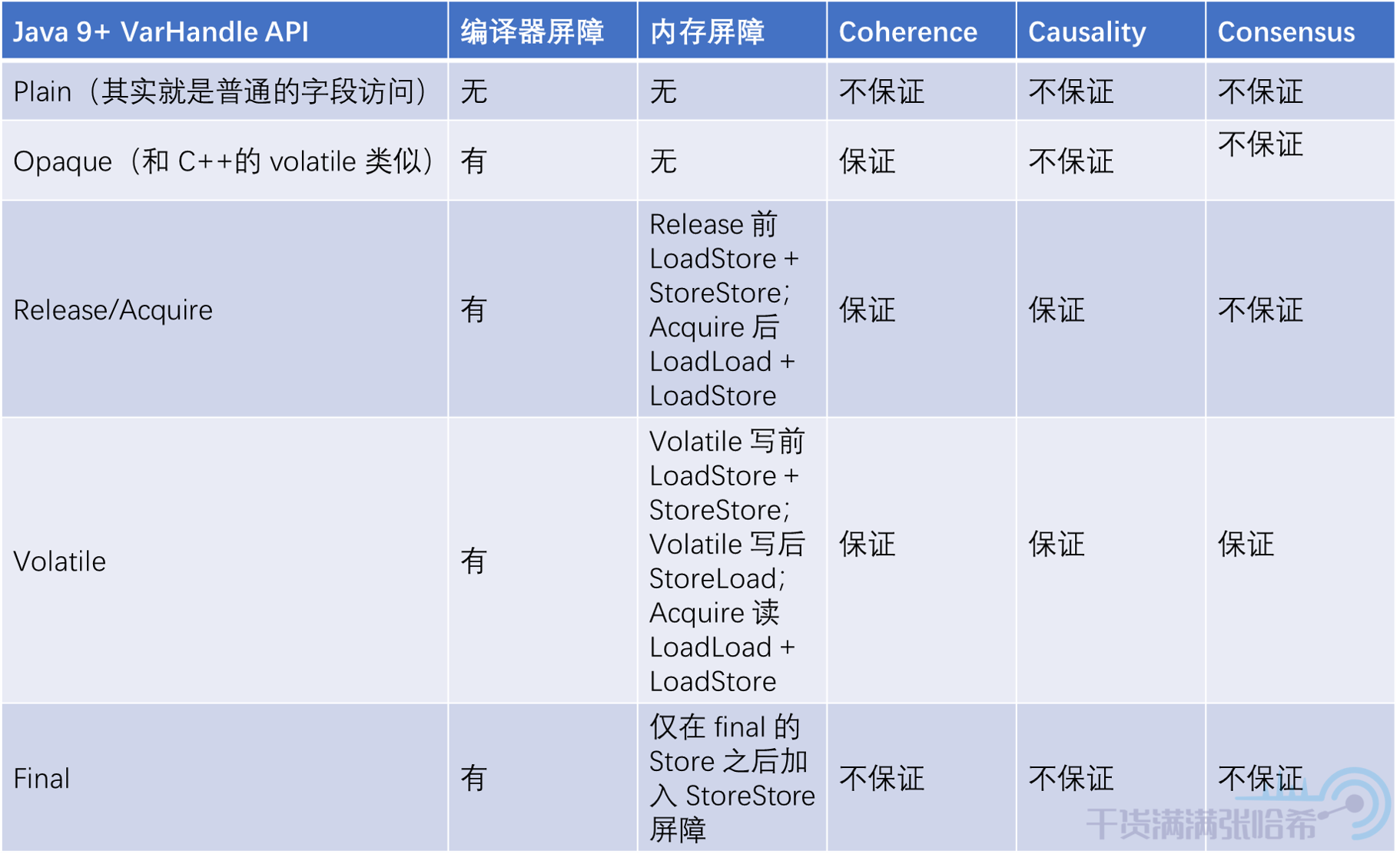
7.1. Coherence(相干性,连贯性)与 Opaque
这里的标题我不太清楚究竟应该翻译成什么,因为我看网上很多地方把 CPU Cache Coherence Protocol 翻译成了 CPU 缓存一致性协议,即 Coherence 在那种语境下代表一致性,但是我们这里的 Coherence 如果翻译成一致性就不太合适。所以,之后的一些名词我也直接沿用 Doug Lea 大神的以及 Aleksey 大神的定义。
那么这里什么是 coherence 呢?举一个简单的例子:假设某个对象字段 int x 初始为 0,一个线程执行:

另一个线程执行(r1, r2 为本地变量):

那么在 Java 内存模型下,可能的结果是包括:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
其中第三个结果很有意思,从程序上理解即我们先看到了 x = 1,之后又看到了 x 变成了 0.当然,通过前面的分析,我们知道实际上是因为编译器乱序。如果我们不想看到这个第三种结果,我们所需要的特性即 coherence。
coherence 的定义,我引用下原文:
The writes to the single memory location appear to be in a total order consistent with program order.
即对单个内存位置的写看上去是按照与程序顺序一致的总顺序进行的。看上去有点难以理解,结合上面的例子,可以这样理解:在全局,x 由 0 变成了 1,那么每个线程中看到的 x 只能从 0 变成 1,而不会可能看到从 1 变成 0.
正如前面所说,Java 内存模型定义中的 Plain 读写,是不能保证 coherence 的。但是如果大家跑一下针对上面的测试代码,会发现跑不出来第三种结果。这是因为 Hotspot 虚拟机中的语义分析会认为这两个对于 x 的读取(load)是互相依赖的,进而限制了这种乱序:
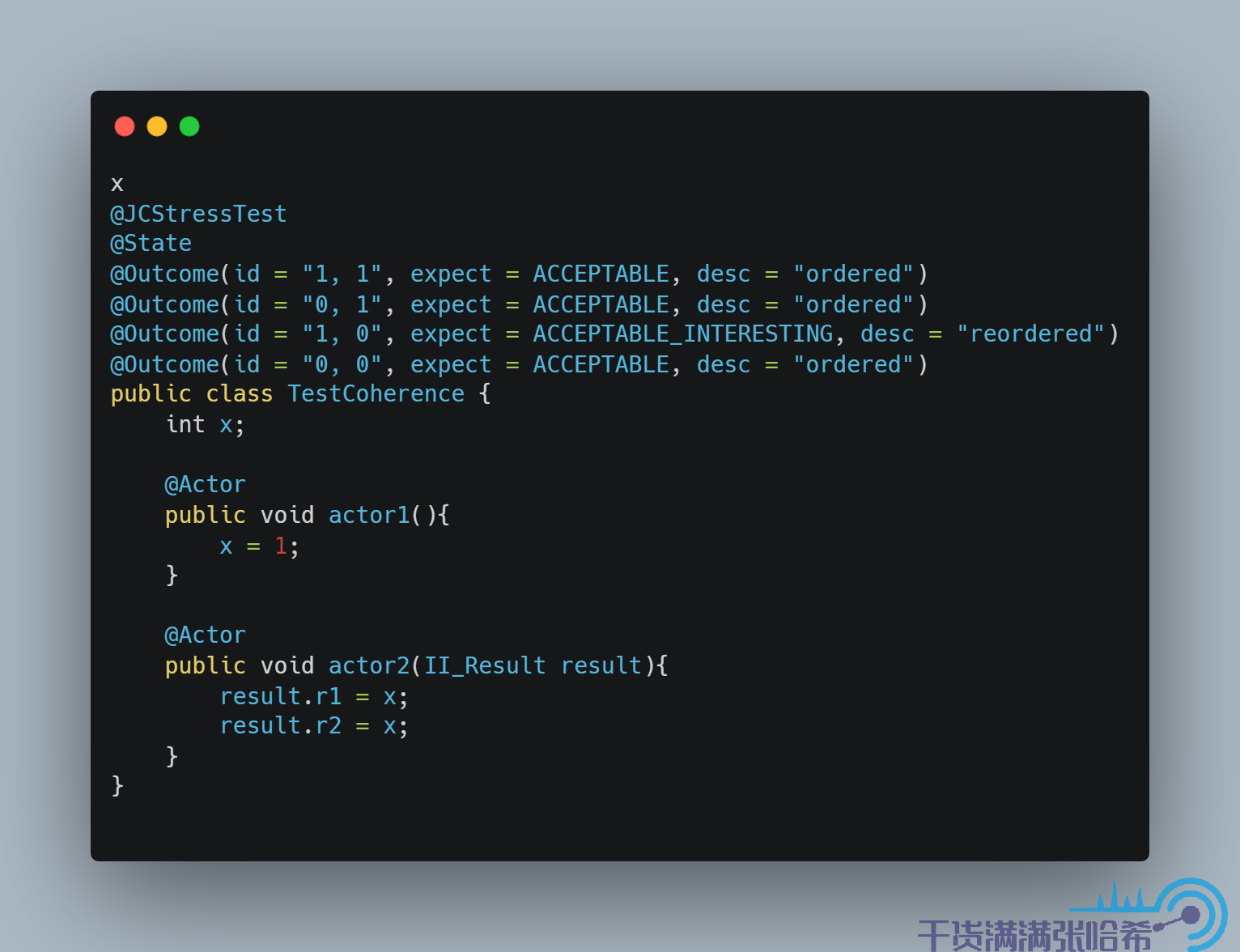
这就是我在前面一章中提到的,为什么最好不要自己写代码验证 JMM 的一些结论。虽然在 Java 内存模型的限制中,是允许第三种结果 1, 0 的,但是这里通过这个例子是试不出来的。
我们这里通过一个别扭的例子来骗过 Java 编译器造成这种乱序:
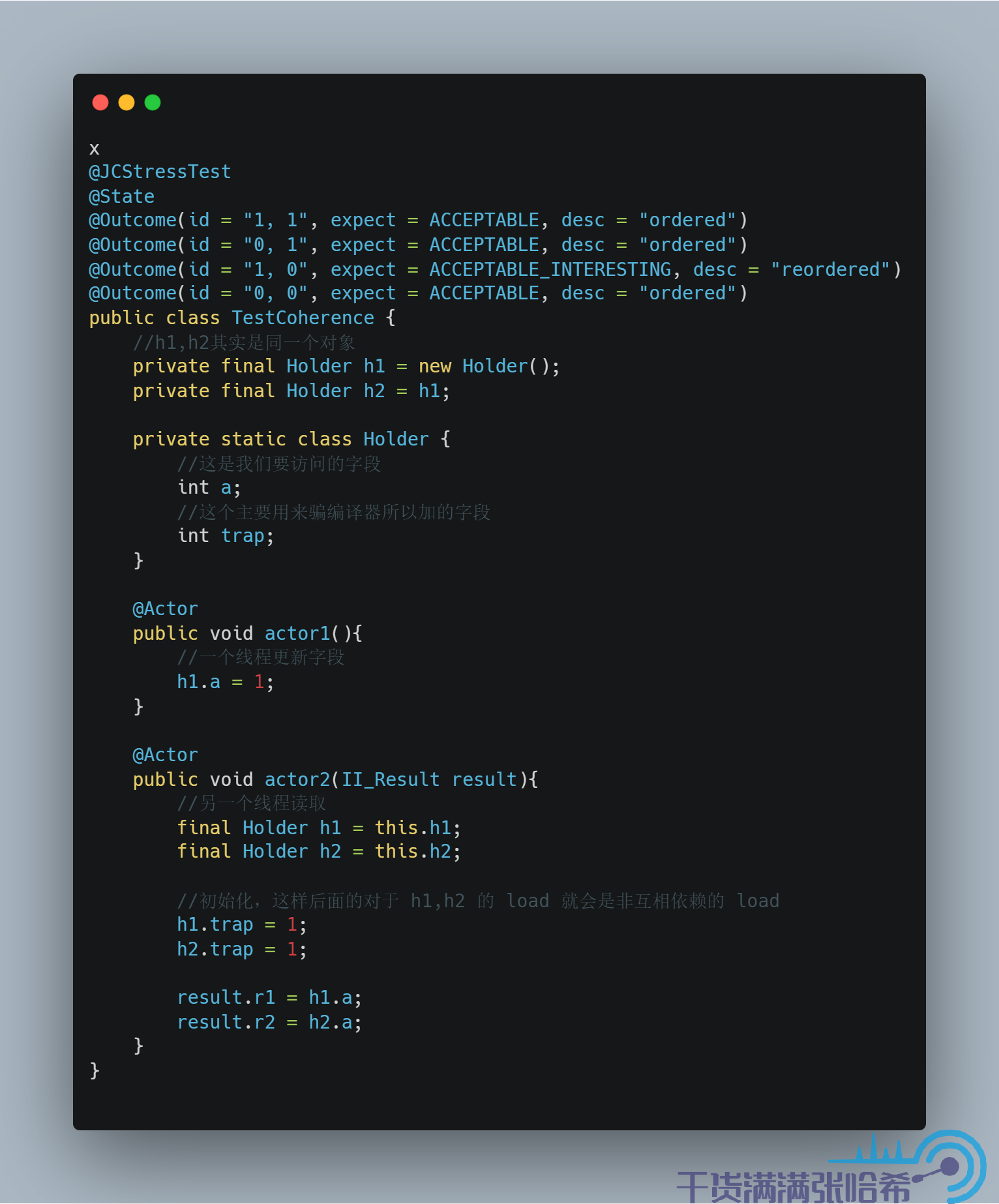
我们不用太深究其原理,直接看结果:
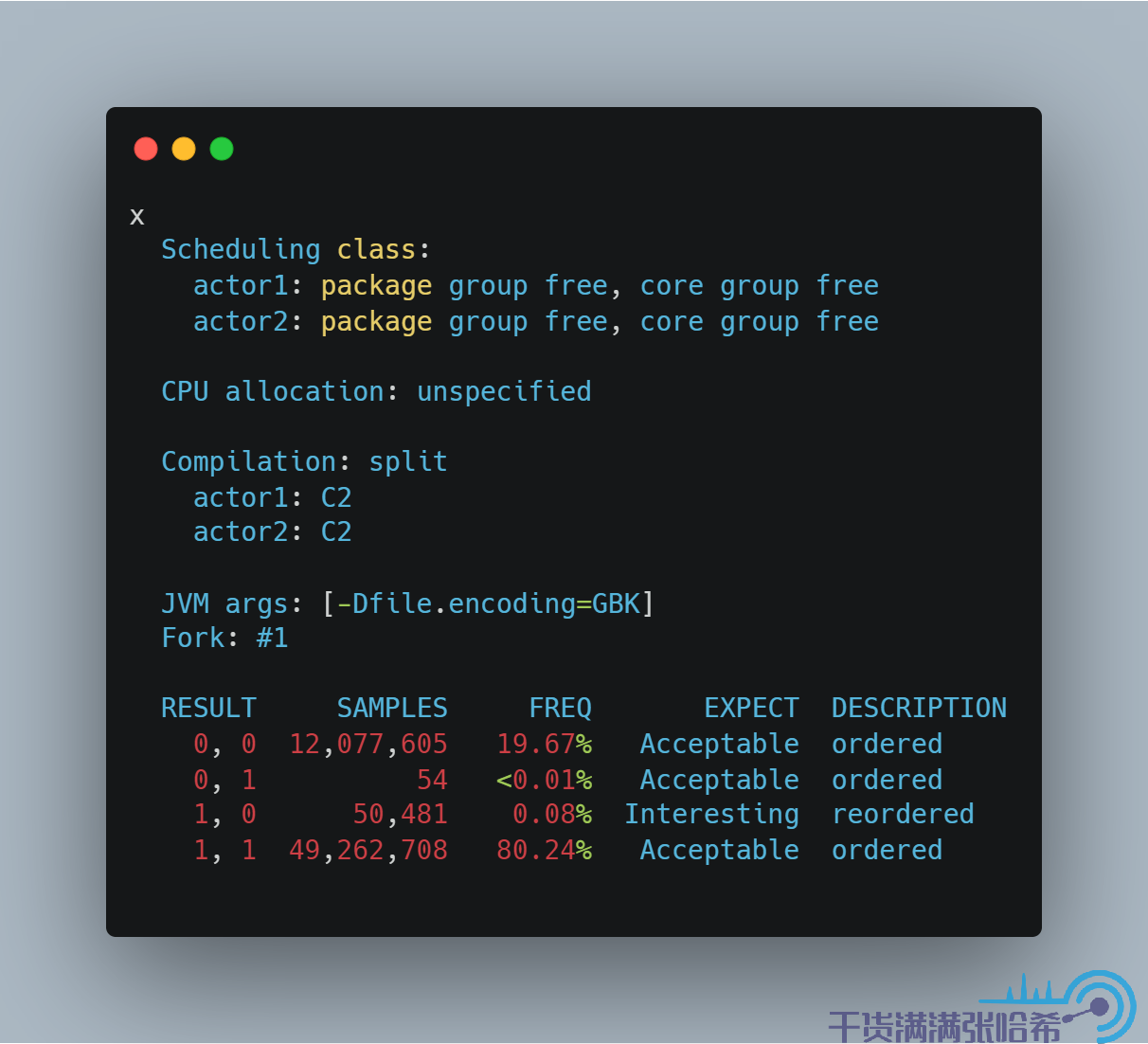
发现出现了乱序的结果,并且,如果你自己跑一下这个例子,会发现这个乱序是发生在执行 JIT C2 编译后的 actor2 方法才会出现。
那么如何避免这种乱序呢?使用 volatile 肯定是可以避免的,但是这里我们并不用劳烦 volatile 这种重操作出马,就用 Opaque 访问即可。Opaque 其实就是禁止 Java 编译器优化,但是没有涉及任何的内存屏障,和 C++ 中的 volatile 非常类似。测试下:
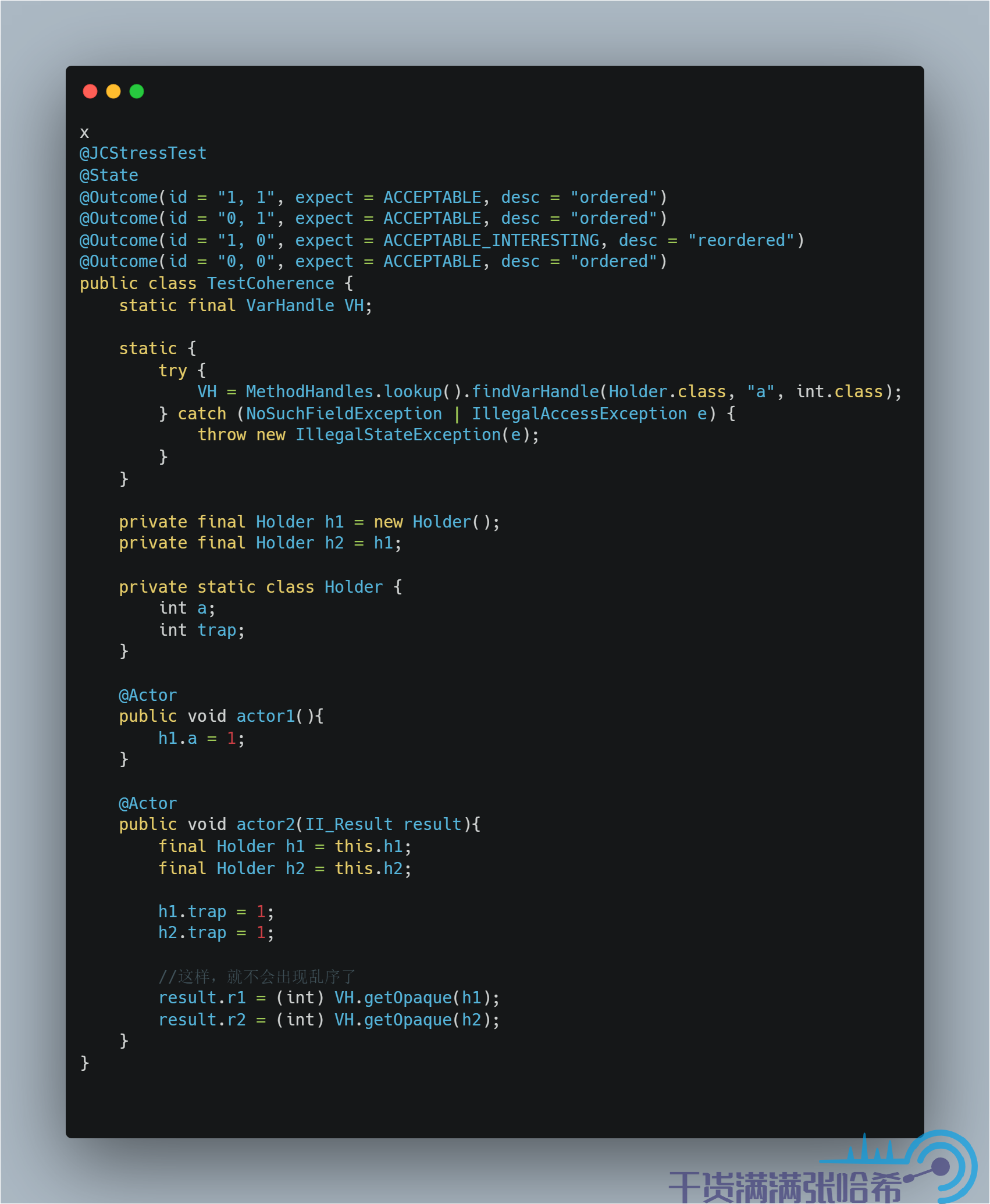
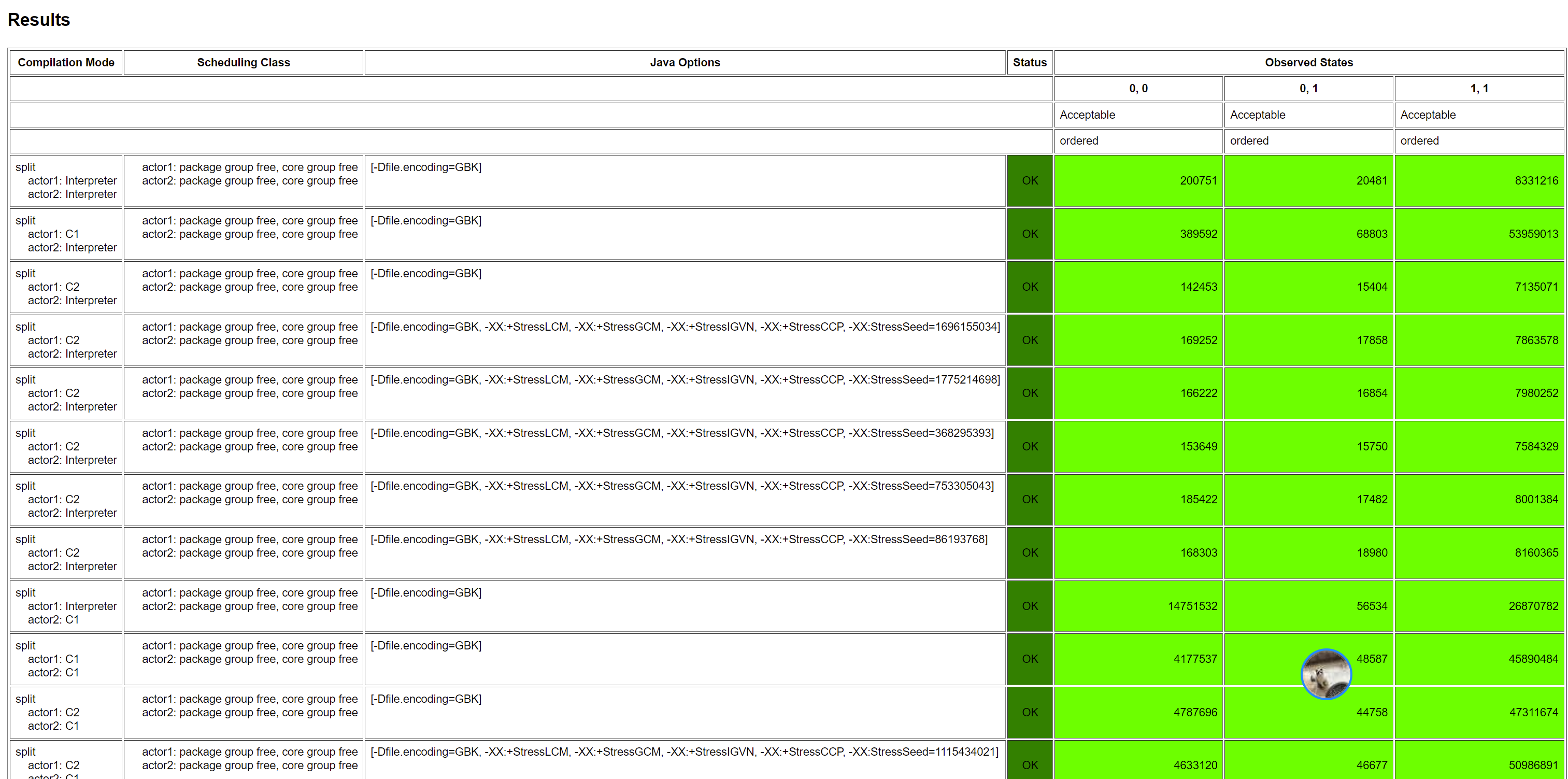
运行下,可以发现,这个就没有乱序了(命令行如果没有 ACCEPTABLE_INTERESTING,FORBIDDEN,UNKNOWN 的 结果就不会输出了,只能最后看输出的 html):

在 Coherence 的基础上,我们一般在某些场景还会需要 Causality
一般到这里,大家会接触到两个很常见的词,即 happens-before 以及 synchronized-with order,我们这里先不从这两个比较晦涩的概念开始介绍(具体概念介绍不会在这一章节解释),而是通过一个例子,即假设某个对象字段 int x 初始为 0,int y 也初始为 0,这两个字段不在同一个缓存行中(后面的 jcstress 框架会自动帮我们进行缓存行填充),一个线程执行:

另一个线程执行(r1, r2 为本地变量):

这个例子与我们前面的 CPU 缓存那里的乱序分析举得例子很像,在 Java 内存模型中,可能的结果有:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
同样的,第三个结果也是很有趣的,第二个线程先看到 y 更新,但是没有看到 x 的更新。这个在前面的 CPU 缓存乱序那里我们详细分析,在前面的分析中,我们需要像这样加内存屏障才能避免第三种情况的出现,即:

以及

简单回顾下,线程 1 执行 x = 1 之后,在 y = 1 之前执行了写屏障,保证 store buffer 的更新都更新到了缓存,y = 1 之前的更新都保证了不会因为存在 store buffer 中导致不可见。线程 2 执行 int r1 = y 之后执行了读屏障,保证 invalidate queue 中的需要失效的数据全部被失效,保证当前缓存中不会有脏数据。这样,如果线程 2 看到了 y 的更新,就一定能看到 x 的更新。
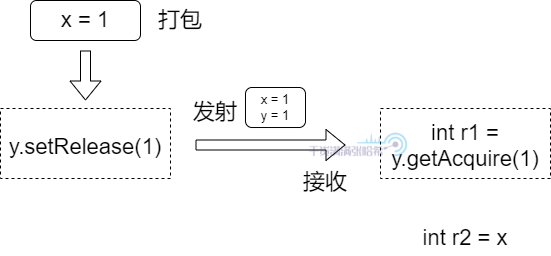
我们进一步更形象的描述一下:我们把写屏障以及后面的一个 Store(即 y = 1)理解为将前面的更新打包,然后将这个包在这点发射出去,读屏障与前面一个 Load(即 int r1 = y)理解成一个接收点,如果接收到发出的包,就在这里将包打开并读取进来。所以,如下图所示:
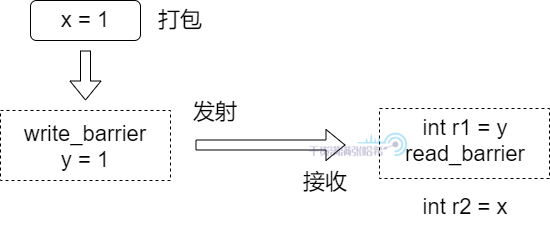
在发射点,会将发射点之前(包括发射点本身的信息)的所有结果打包,如果在执行接收点的代码的时候接收到了这个包,那么在这个接收点之后的所有指令就能看到包里面的所有内容,即发射点之前以及发射点的内容。Causality(因果性),有的地方也叫做 Casual Consistency(因果一致性),它在不同的语境下有不同的含义,我们这里仅特指:可以定义一系列写入操作,如果读取看到了最后一个写入,那么这个读取之后的所有读取操作,都能看到这个写入以及之前的所有写入操作。这是一种 Partial Order(半顺序),而不是 Total Order(全顺序),关于这个定义将在后面的章节详细说明。
在 Java 中,Plain 访问与 Opaque 访问都不能保证 Causality,因为 Plain 没有任何的内存屏障,Opaque 只是有编译器屏障,我们可以通过如下代码测试出来:
首先是 Plain:
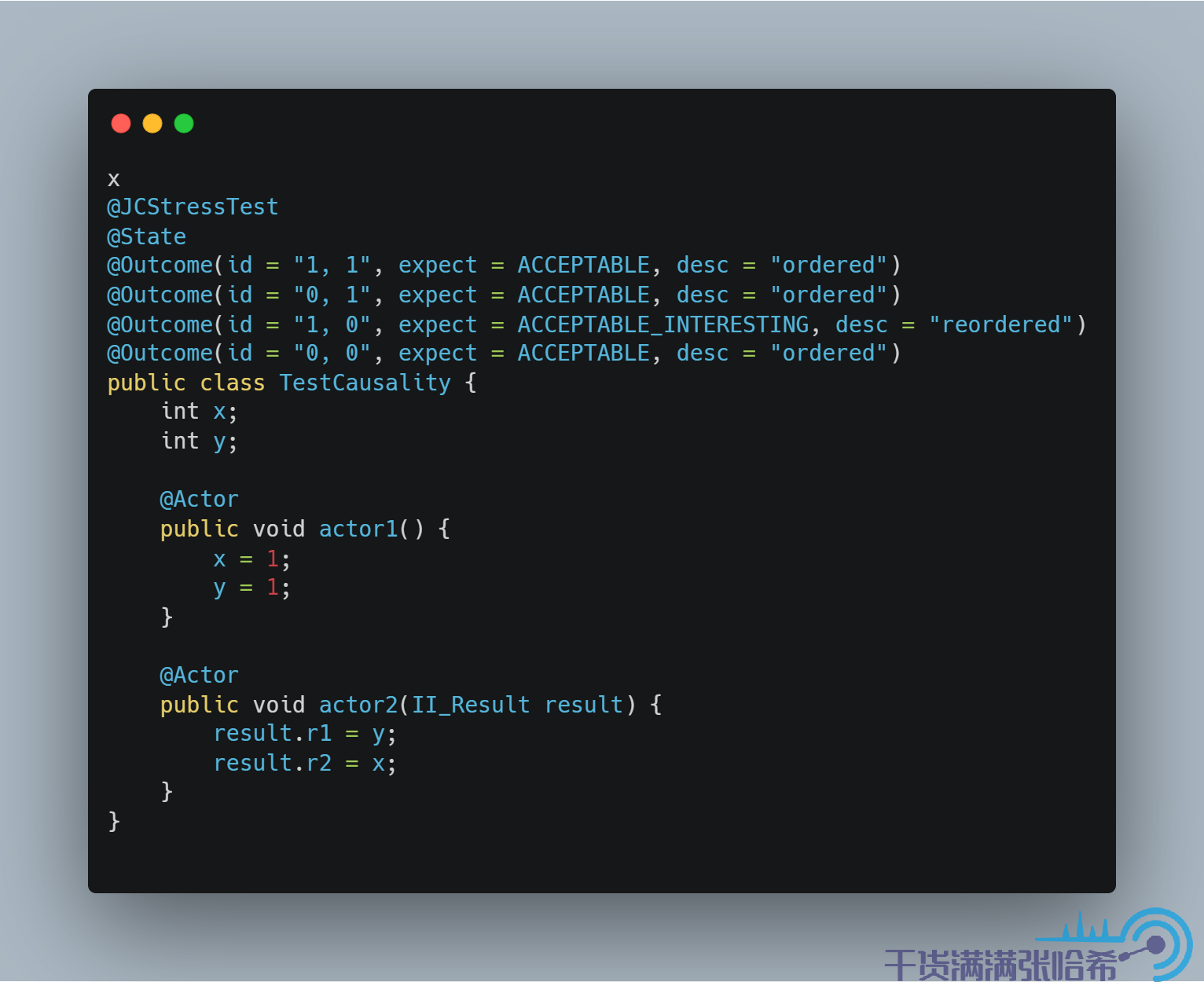
结果是:
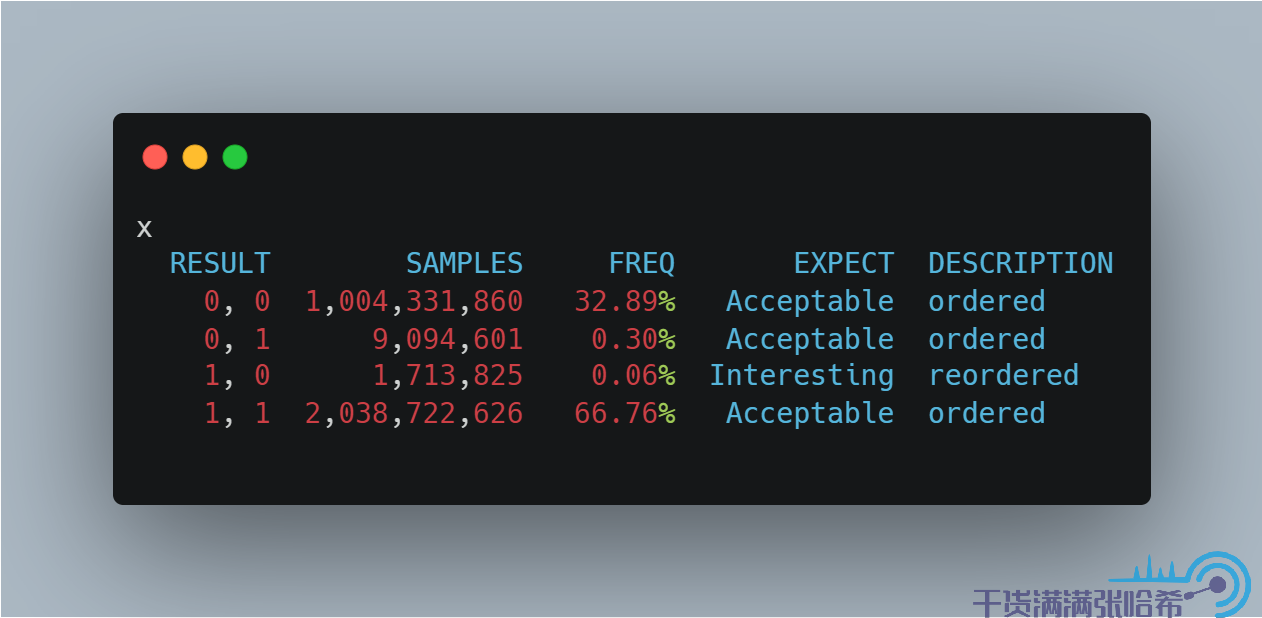
然后是 Opaque:
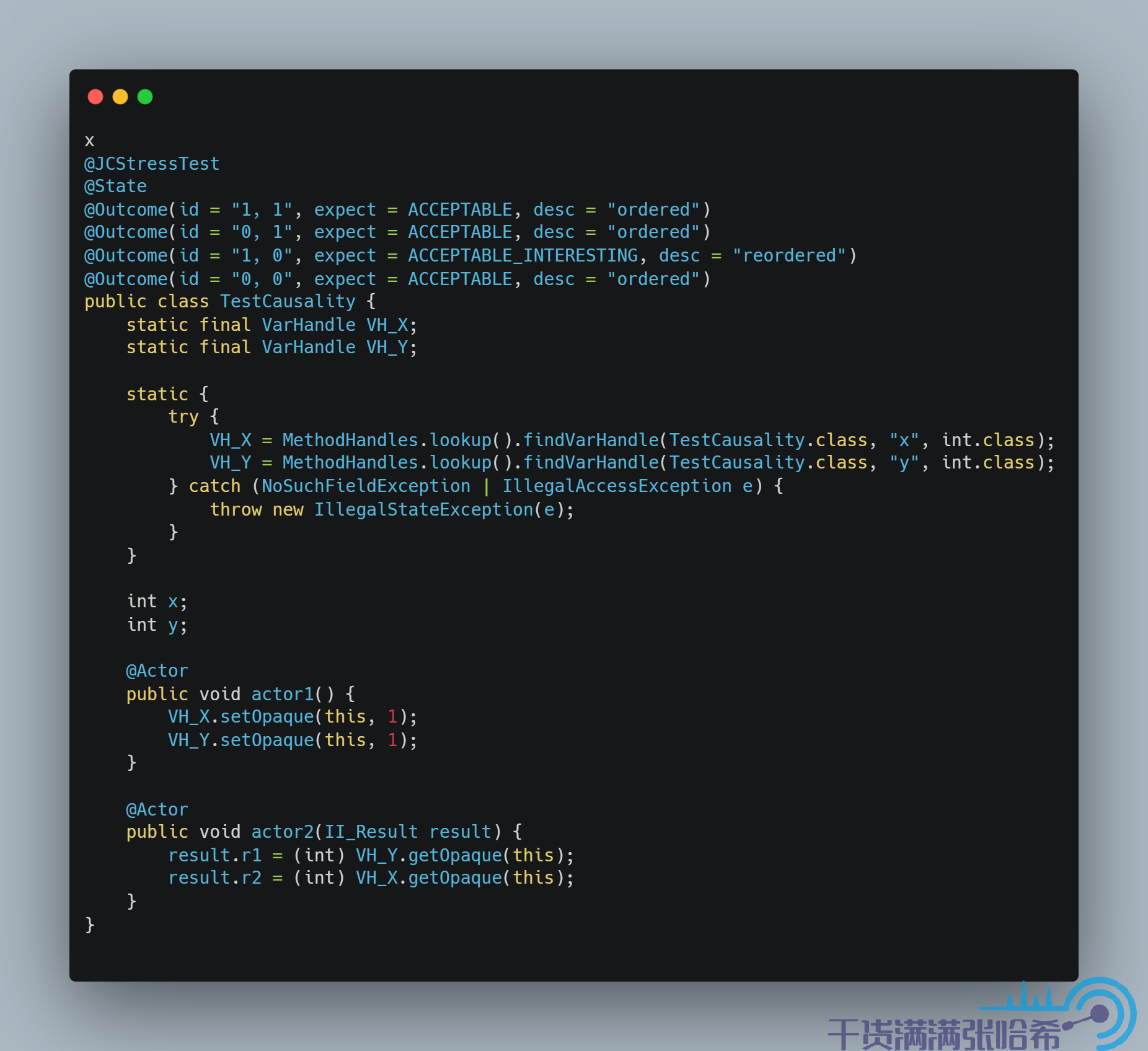
这里我们需要注意:由于前面我们看到, x86 CPU 是天然保证一些指令不乱序的,稍后我们就能看到是哪些不乱序保证了这里的 Causality,所以 x86 的 CPU 都看不到乱序,Opaque 访问就能看到因果一致性的结果,如下图所示(AMD64 是一种 x86 的实现):
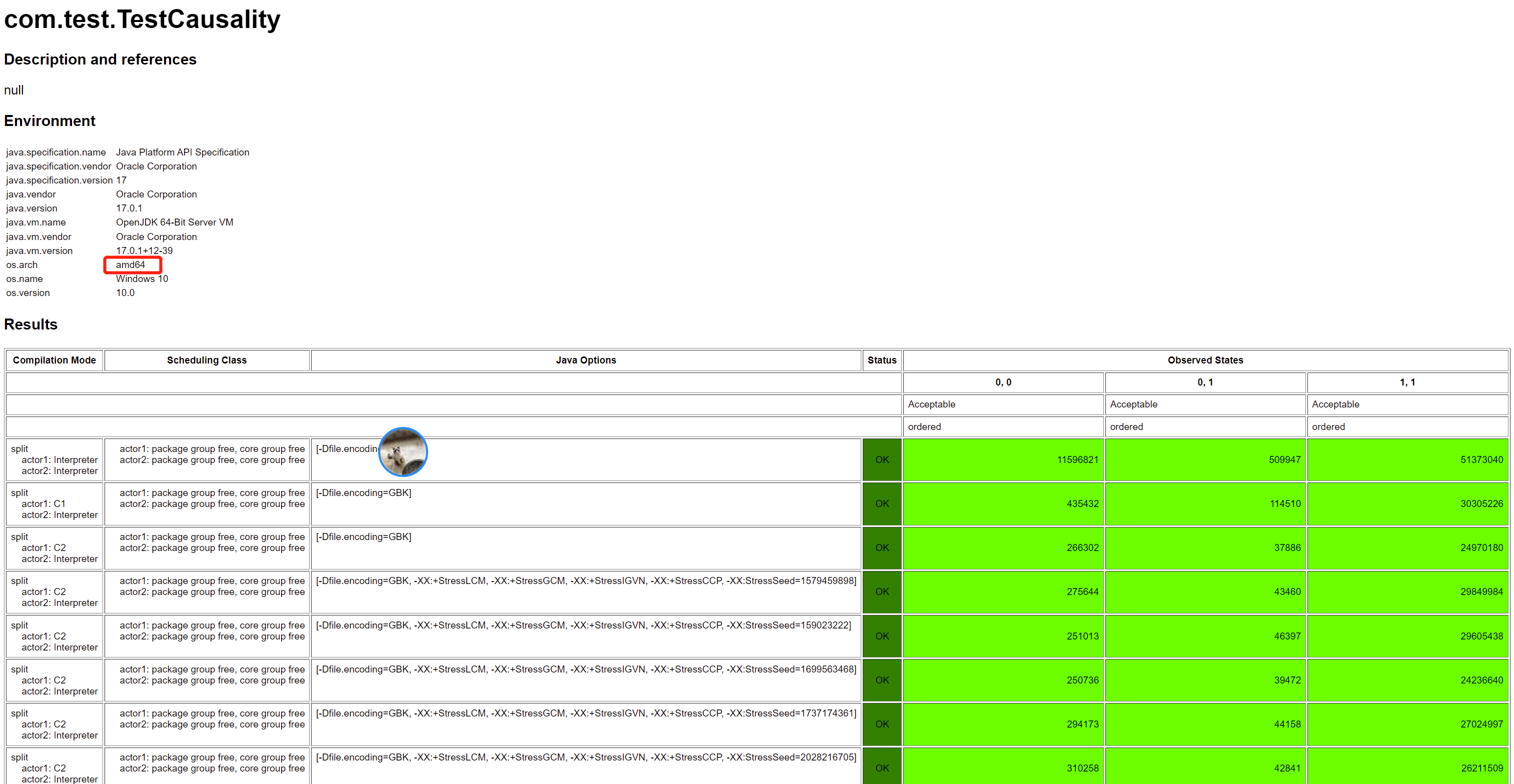
但是,如果我们换成其他稍微弱一致一些的 CPU,就能看到 Opaque 访问保证不了因果一致性,下面的结果是我在 aarch64 (是一种 arm 的实现):

并且,还有一个比较有意思的点,即乱序都是 C2 编译执行的时候发生的。
那么,我们如何保证 Causality 呢?同样的,我们同样不必劳烦 volatile 这么重的操作,采用 release/acquire 模式即可。release/acquire 可以保证 Coherence + Causality。release/acquire 必须成对出现(一个 acquire 对应一个 release),可以将 release 视为前面提到的发射点,acquire 视为前面提到的接收点,那么我们就可以像下图这样实现代码:
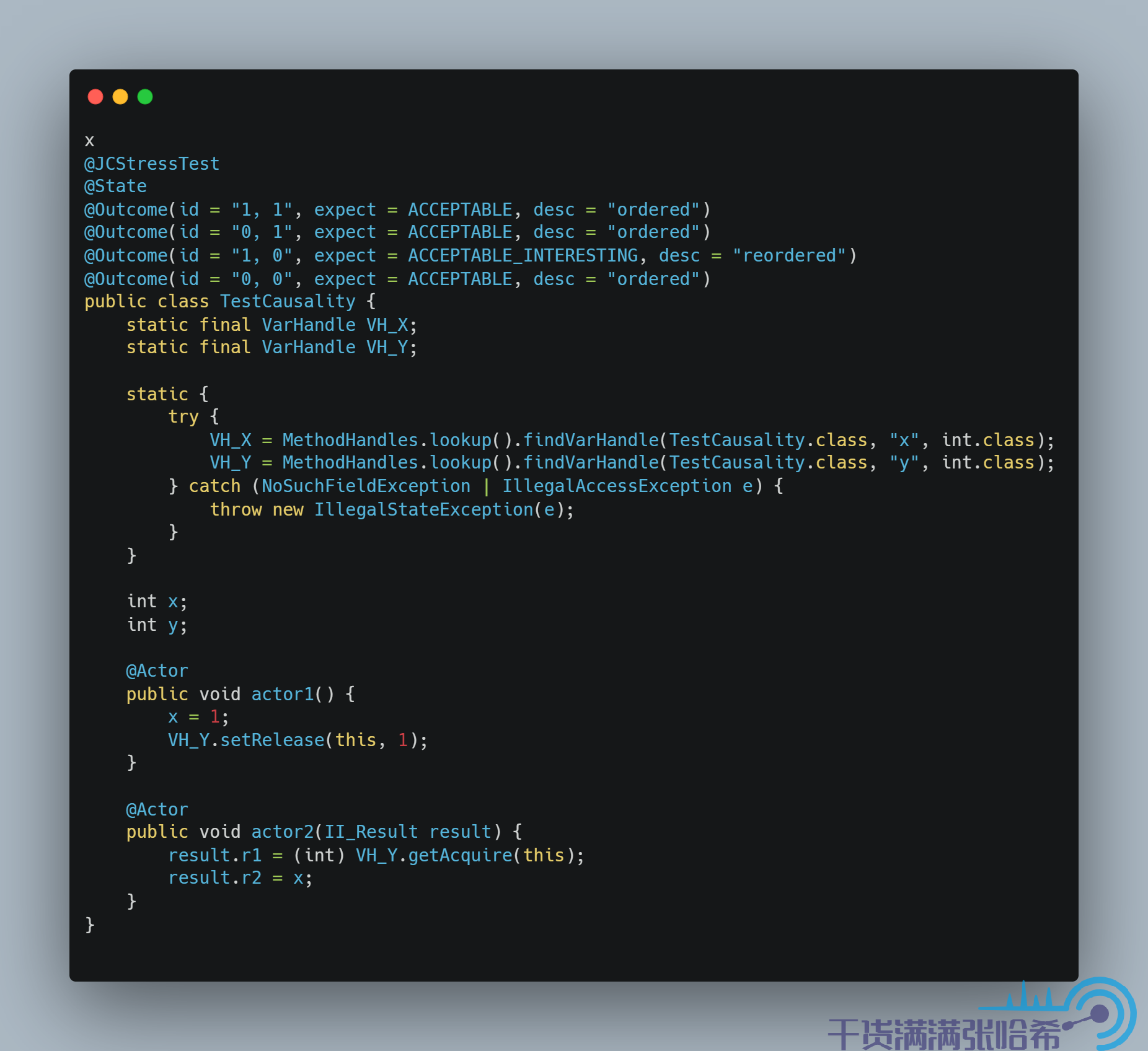
然后,继续在刚刚的 aarch64 的机器上面执行,结果是:
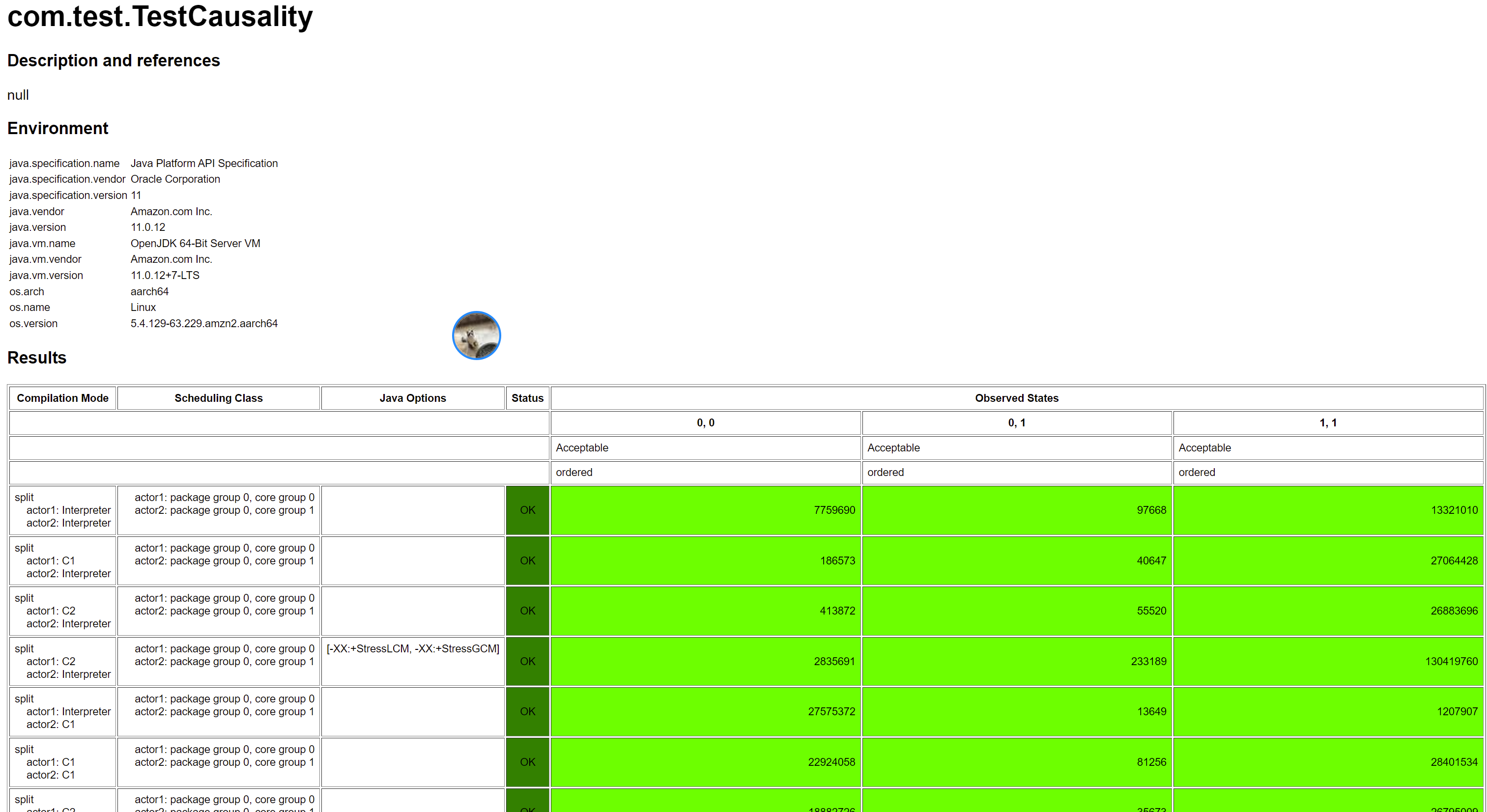
可以看出,Causuality 由于使用了 Release/Acquire 保证了 Causality。注意,对于发射点和接收点的选取一定要选好,例如这里我们如果换个位置,那么就不对了:
示例一:发射点只会打包之前的所有更新,对于 x = 1 的更新在发射点之后,相当于没有打包进去,所以还是会出现 1,0 的结果。

示例二:在接收点会解包,从而让后面的读取看到包里面的结果,对于 x 的读取在接收点之前,相当于没有看到包里面的更新,所以还是会出现 1,0 的结果。

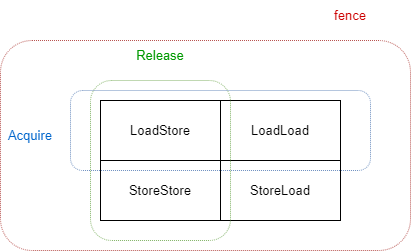
由此,我们类比下 Doug Lea 的 Java 内存屏障设计,来看看这里究竟用了哪些 Java 中设计的内存屏障。在 Doug Lea 的很早也是很经典的一篇文章中,介绍了 Java 内存模型以及其中的内存屏障设计,提出了四种屏障:
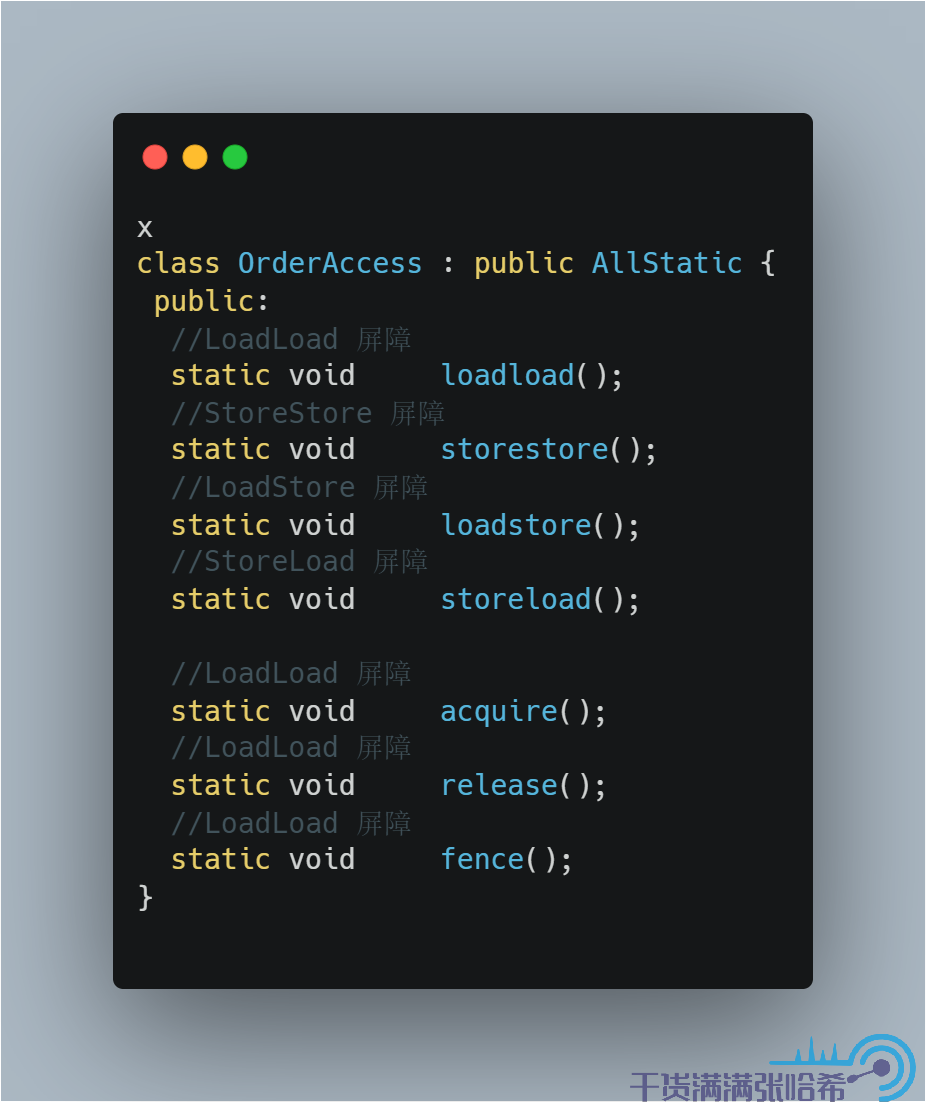
1.LoadLoad
如果有两个完全不相干的互不依赖(即可以乱序执行的)的读取(Load),可以通过 LoadLoad 屏障避免它们的乱序执行(即在 Load(x) 执行之前不会执行 Load(y)):

2.LoadStore
如果有一个读取(Load)以及一个完全不相干的(即可以乱序执行的)的写入(Store),可以通过 LoadStore 屏障避免它们的乱序执行(即在 Load(x) 执行之前不会执行 Store(y)):

3.StoreStore
如果有两个完全不相干的互不依赖(即可以乱序执行的)的写入(Store),可以通过 StoreStore 屏障避免它们的乱序执行(即在 Store(x) 执行之前不会执行 Store(y)):

4.StoreLoad
如果有一个写入(Store)以及一个完全不相干的(即可以乱序执行的)的读取(Load),可以通过 LoadStore 屏障避免它们的乱序执行(即在 Store(x) 执行之前不会执行 Load(y)):

那么如何通过这些内存屏障实现的 Release/Acquire 呢?我们可以通过前面我们的抽象推出来,首先是发射点。发射点首先是一个 Store,并且保证打包前面的所有,那么不论是 Load 还是 Store 都要打包,都不能跑到后面去,所以需要在 Release 的前面加上 LoadStore,StoreStore 两种内存屏障来实现。同理,接收点是一个 Load,并且保证后面的都能看到包里面的值,那么无论 Load 还是 Store 都不能跑到前面去,所以需要在 Acquire 的后面加上 LoadLoad,LoadStore 两种内存屏障来实现。
但是呢我们可以在下一章中看到,其实目前来看这四个内存屏障的设计有些过时了(由于 CPU 的发展以及 C++ 语言的发展) ,JVM 内部用的更多的是 acquire,release,fence 这三个。这里的 acquire 以及 release 其实就是我们这里提到的 Release/Acquire。这三个与传统的四屏障的设计的关系是:
我们这里知道了 Release/Acquire 的内存屏障,x86 为何没有设置这个内存屏障就没有这种乱序呢?参考前面的 CPU 乱序图:
通过这里我们知道,x86 对于 Store 与 Store,Load 与 Load,Load 与 Store 都不会乱序,所以天然就能保证 Casuality
7.3. Consensus(共识性)与 Volatile
最后终于来到我们所熟悉的 Volatile 了,Volatile 其实就是在 Release/Acquire 的基础上,进一步保证了 Consensus;Consensus 即所有线程看到的内存更新顺序是一致的,即所有线程看到的内存顺序全局一致,举个例子:假设某个对象字段 int x 初始为 0,int y 也初始为 0,这两个字段不在同一个缓存行中(后面的 jcstress 框架会自动帮我们进行缓存行填充),一个线程执行:

另一个执行:

在 Java 内存模型下,同样可能有4种结果:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
第四个结果比较有意思,他是不符合 Consensus 的,因为两个线程看到的更新顺序不一样(第一个线程看到 0 代表他认为 x 的更新是在 y 的更新之前执行的,第二个线程看到 0 代表他认为 y 的更新是在 x 的更新之前执行的)。如果没有乱序,那么肯定不会看到 x, y 都是 0,因为线程 1 和线程 2 都是先更新后读取的。但是也正如前面所有的讲述一样,各种乱序造成了我们可以看大第三个这样的结果。那么 Release/Acquire 能否保证不会出现这样的结果呢?我们来简单分析下,如果对于 x,y 的访问都是 Release/Acquire 模式的,那么线程 1 实际执行的就是:
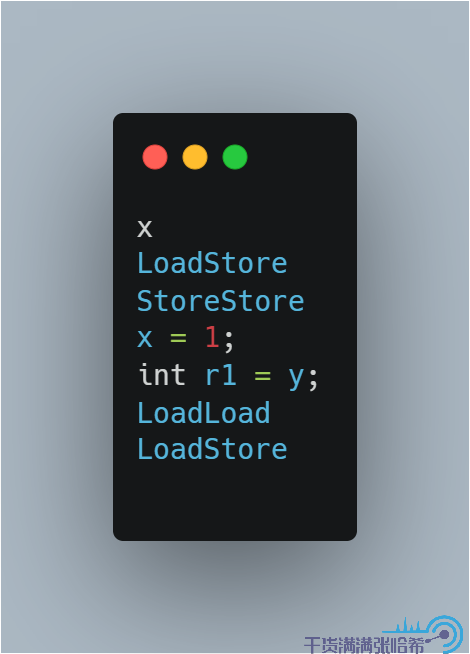
这里我们就可以看出来,x = 1 与 int r1 = y 之间没有任何内存屏障,所以实际可能执行的是:
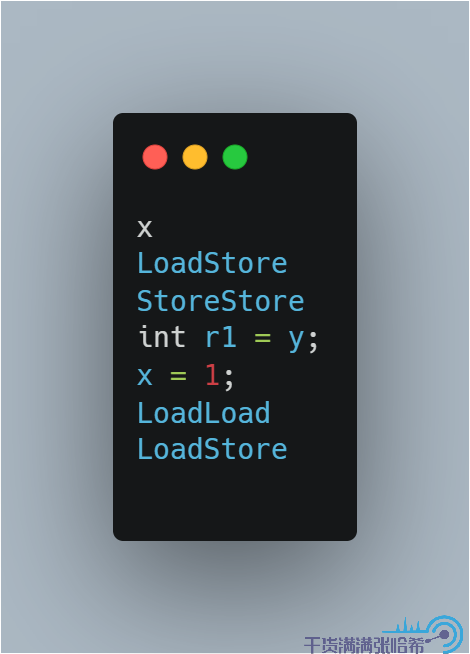
同理,线程 2 可能执行的是:
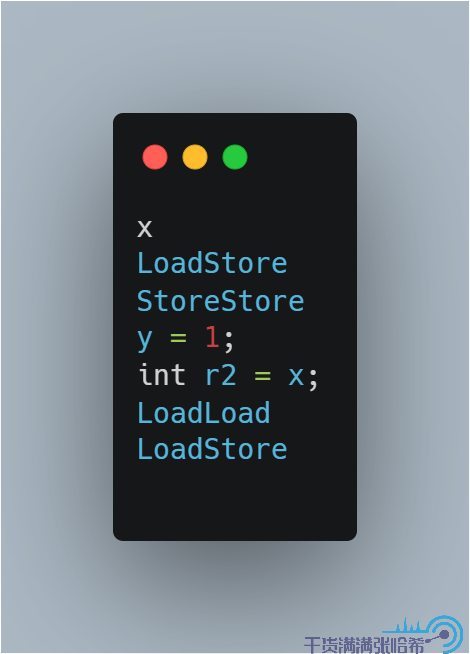
或者:
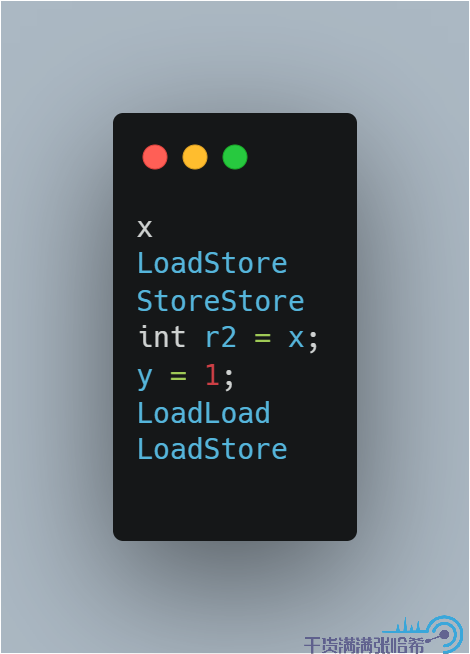
这样,就会造成我们可能看到第四种结果。我们通过代码测试下:
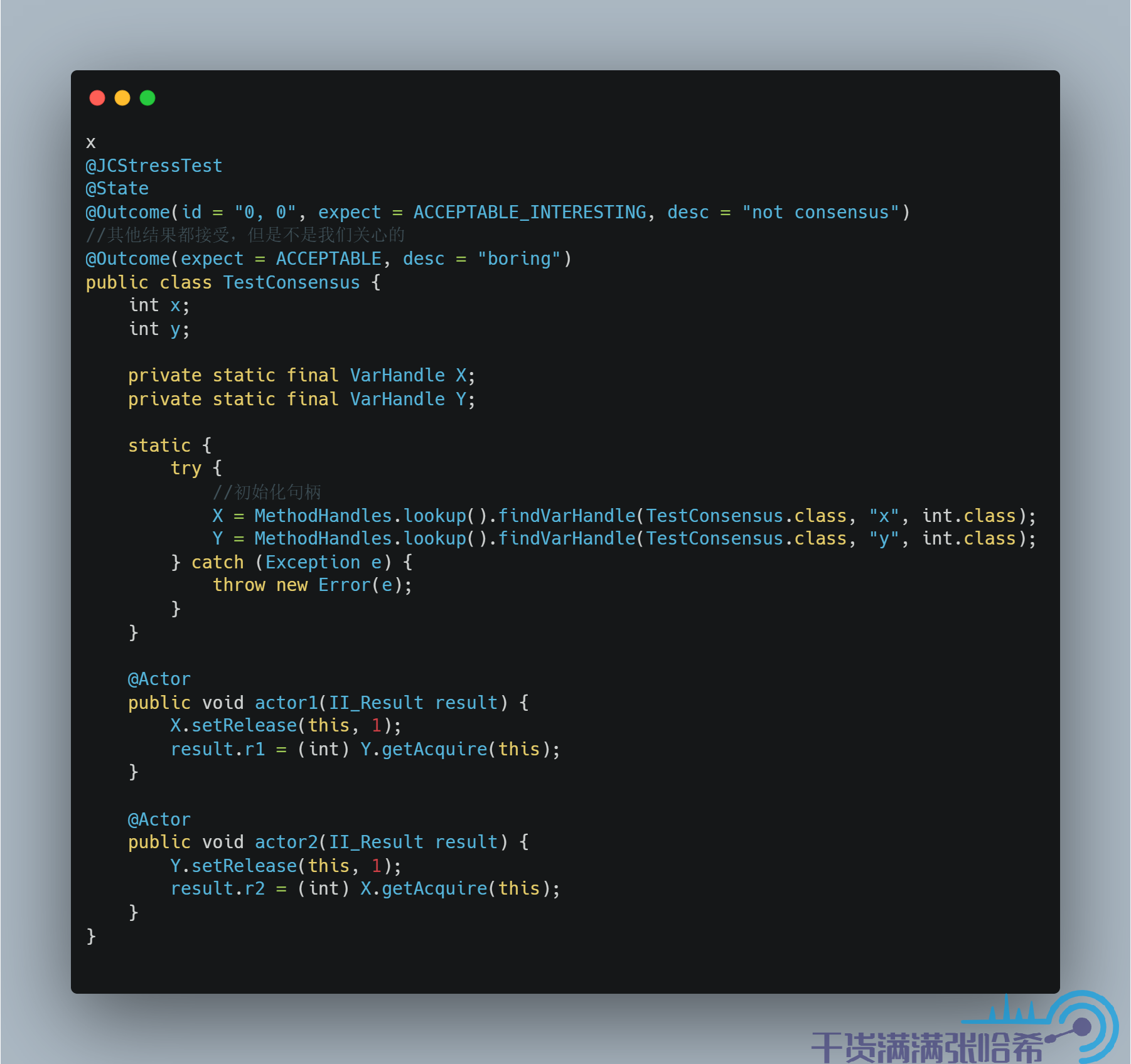
测试结果是:
如果要保证 Consensus,我们只要保证线程 1 的代码与线程 2 的代码不乱序即可,即在原本的内存屏障的基础上,添加 StoreLoad 内存屏障,即线程 1 执行:

线程 2 执行:

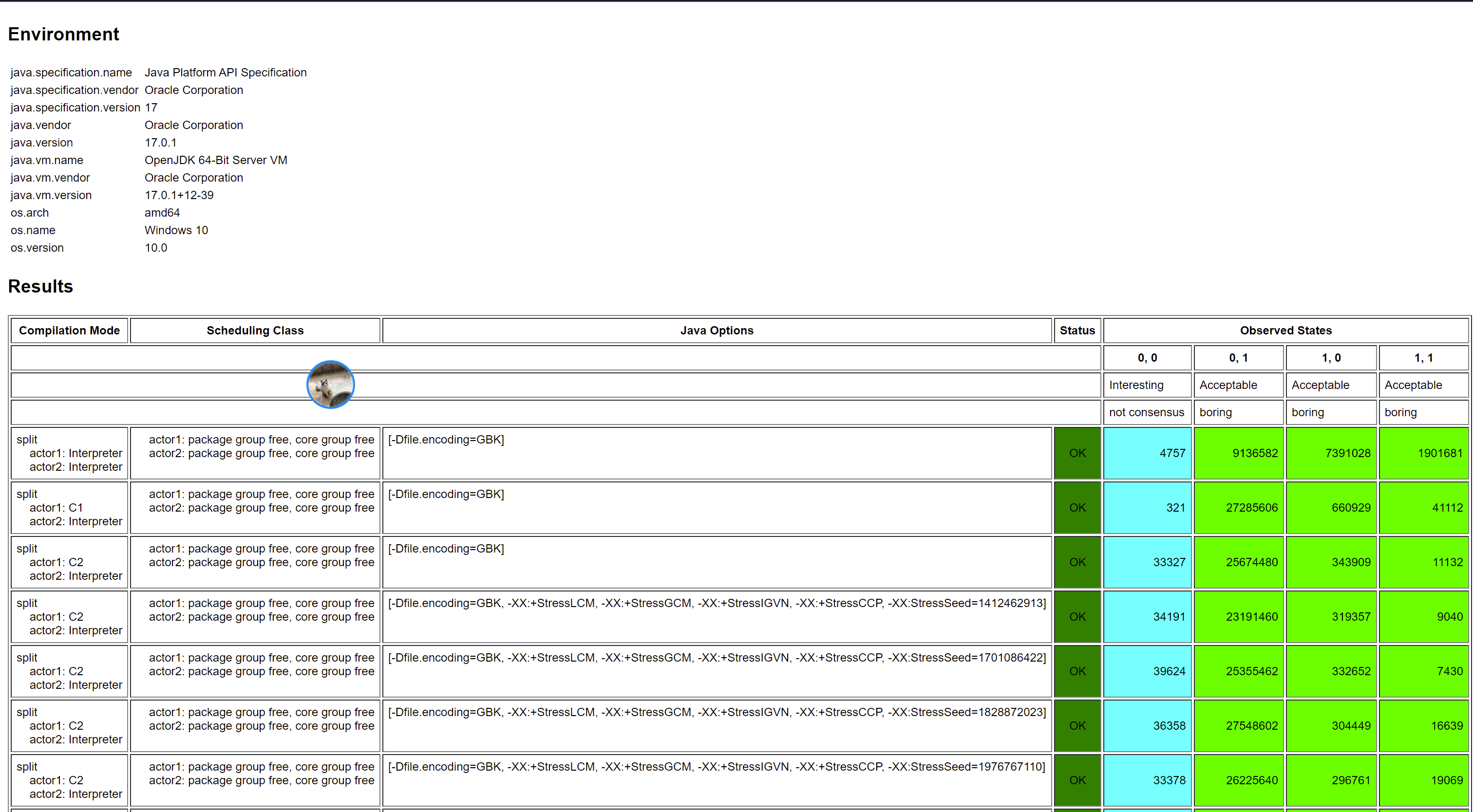
这样就能保证不会乱序,这其实就是 volatile 访问了。Volatile 访问即在 Release/Acquire 的基础上增加 StoreLoad 屏障,我们来测试下:
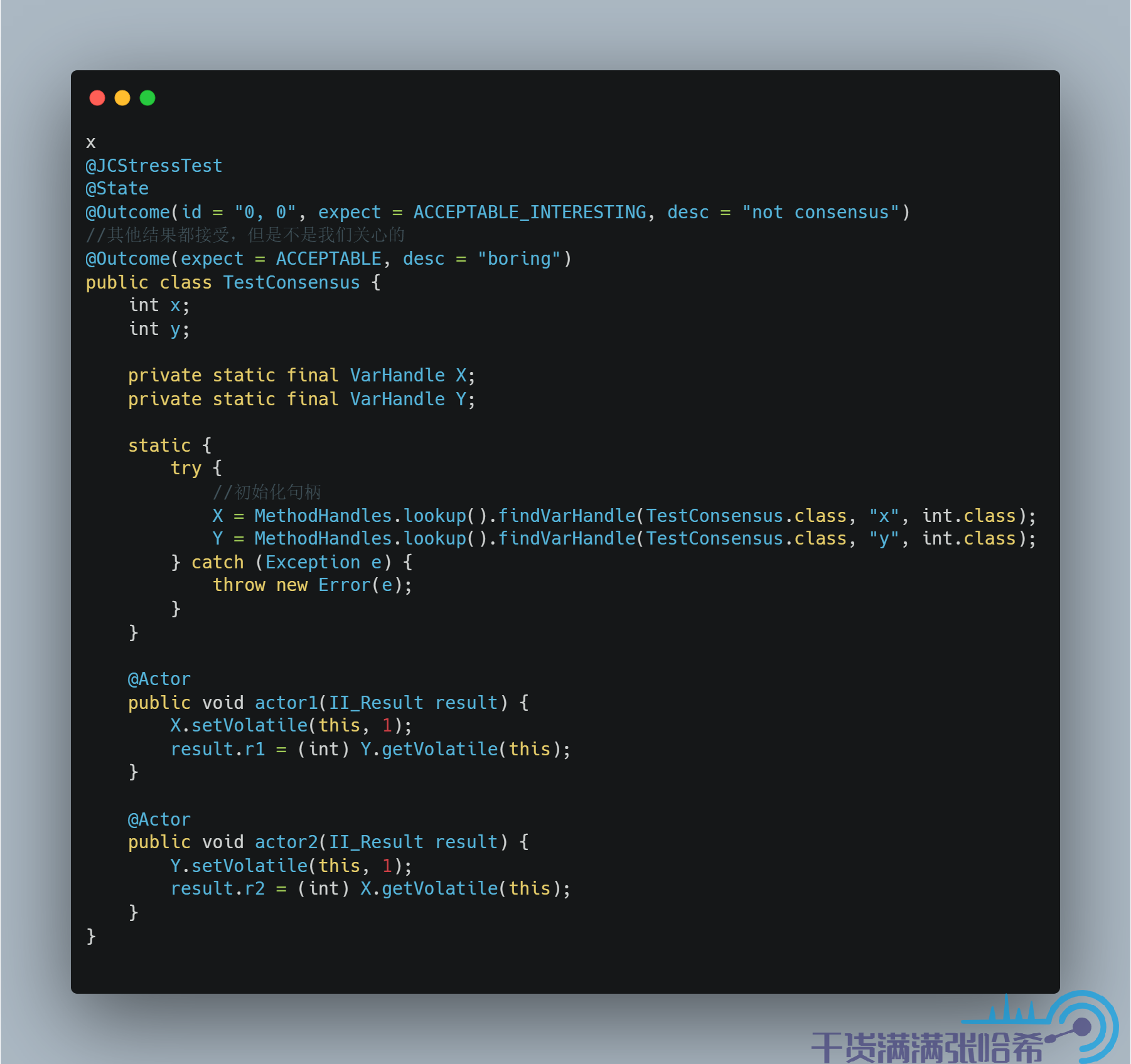
结果是:
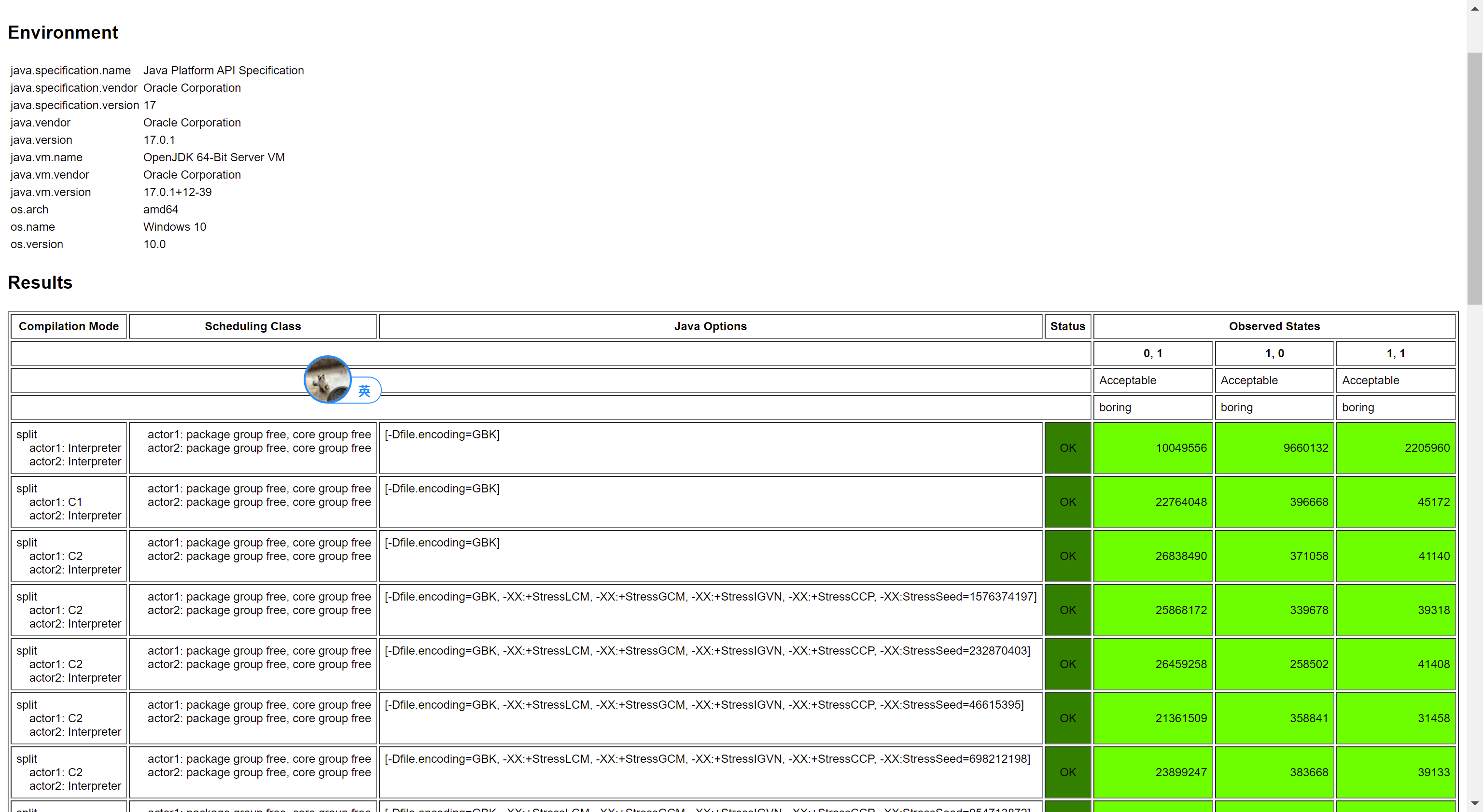
那么引出另一个问题,这个 StoreLoad 屏障是 Volatile Store 之后添加,还是 Volatile Load 之前添加呢?我们来做下这个实验:
首先保留 Volatile Store,将 Volatile Load 改成 Plain Load,即:
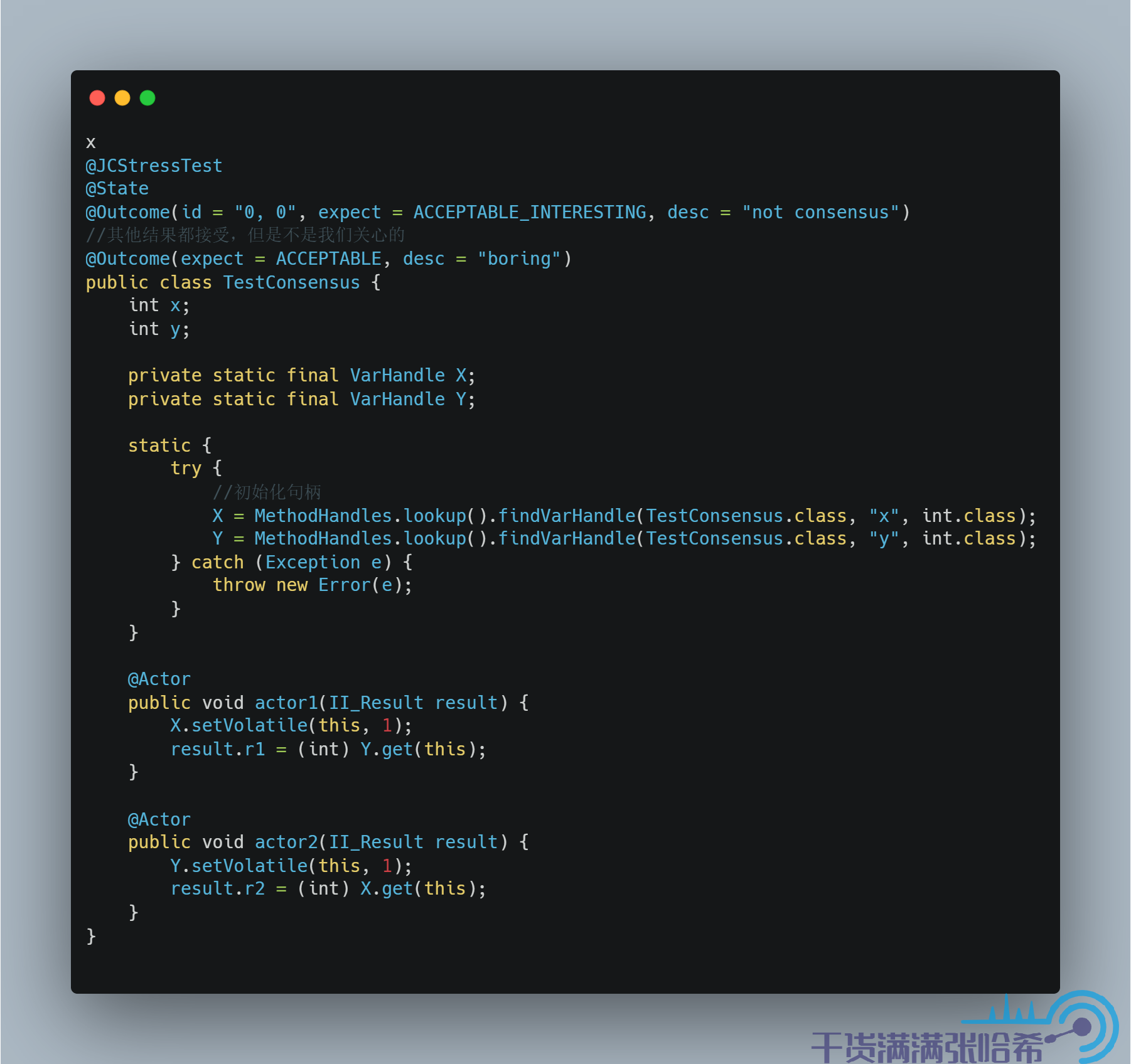
测试结果:
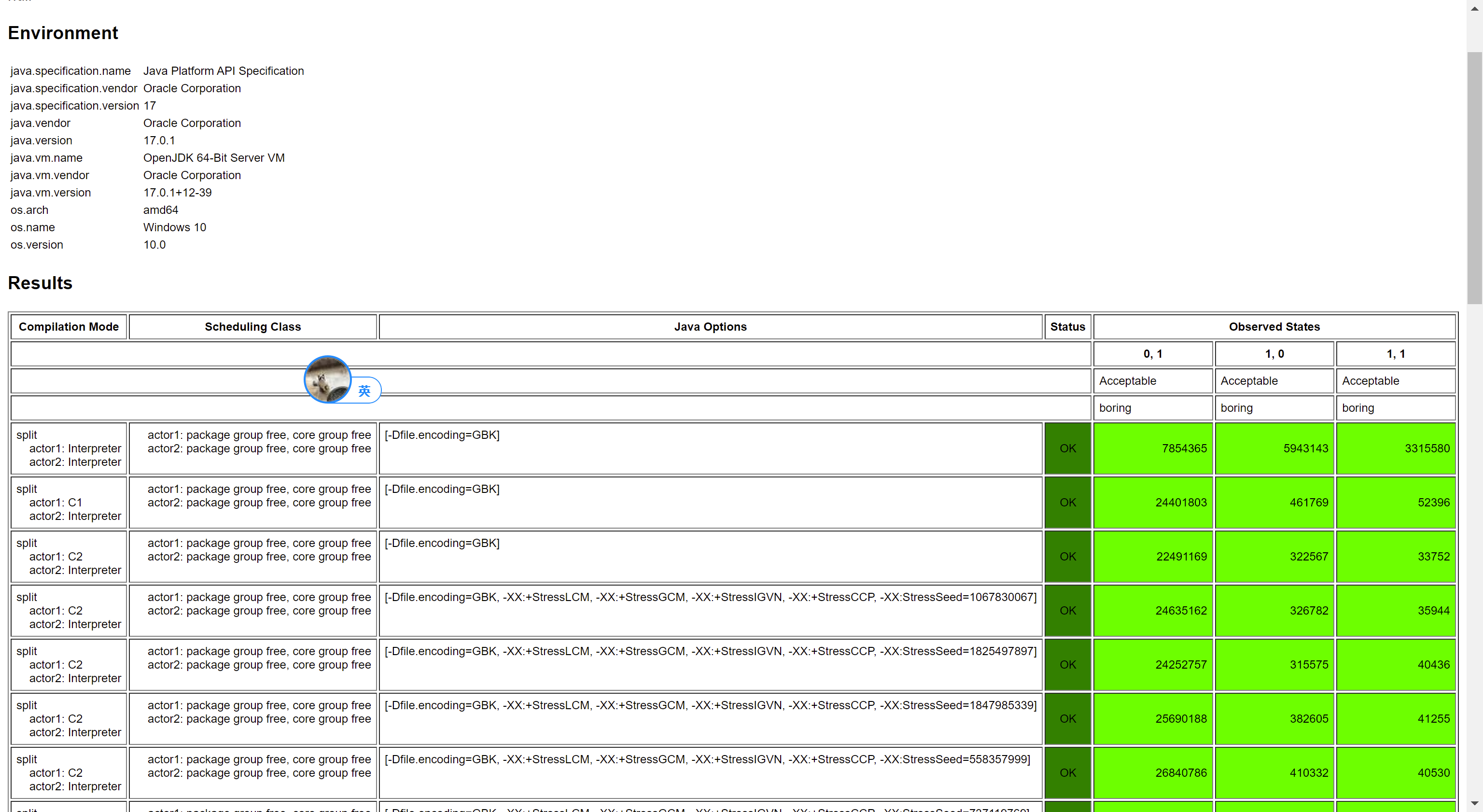
从结果中可以看出,仍然保持了 Consensus。再来看保留 Volatile Load,将 Volatile Store 改成 Plain Store:
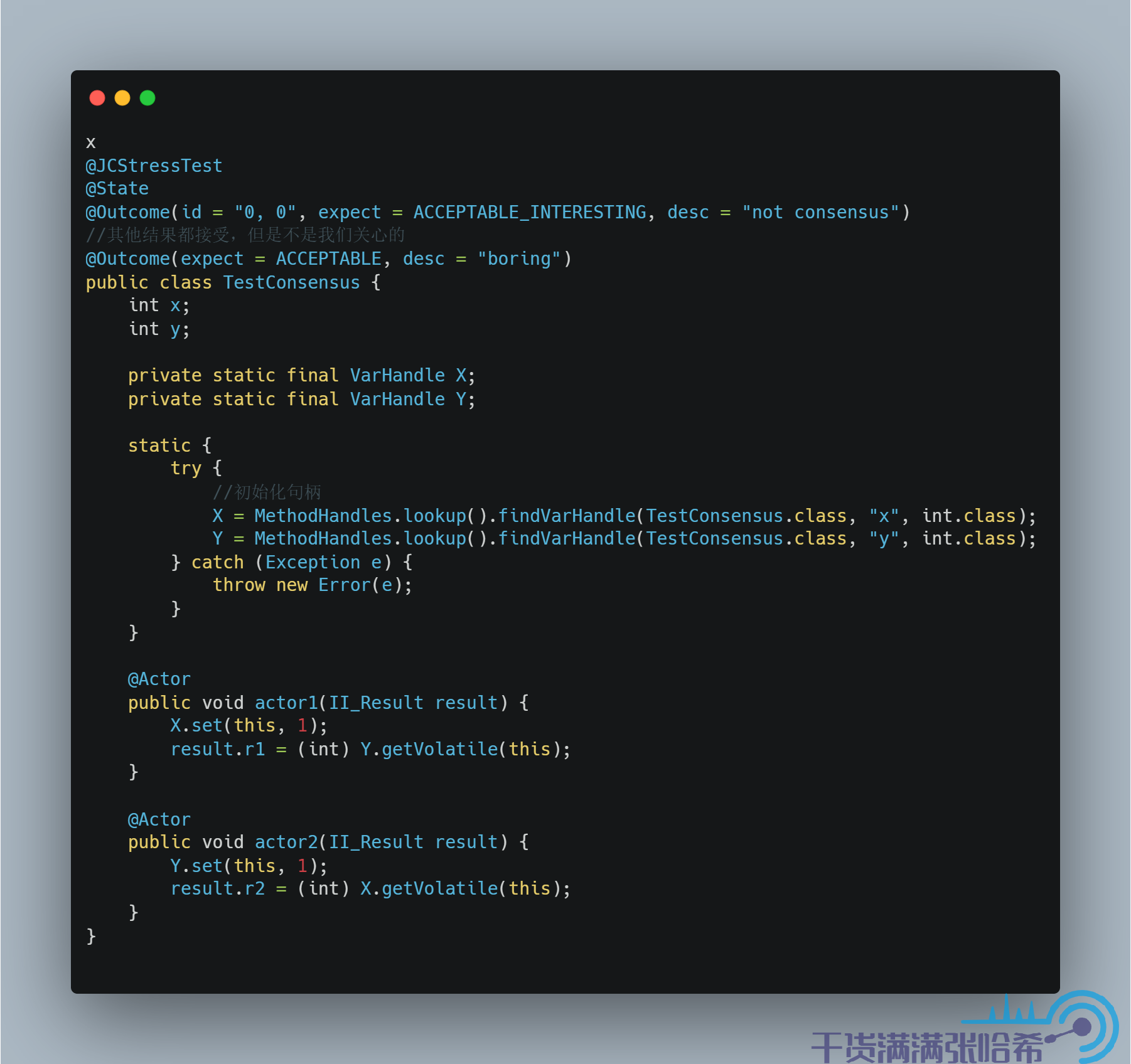
测试结果:
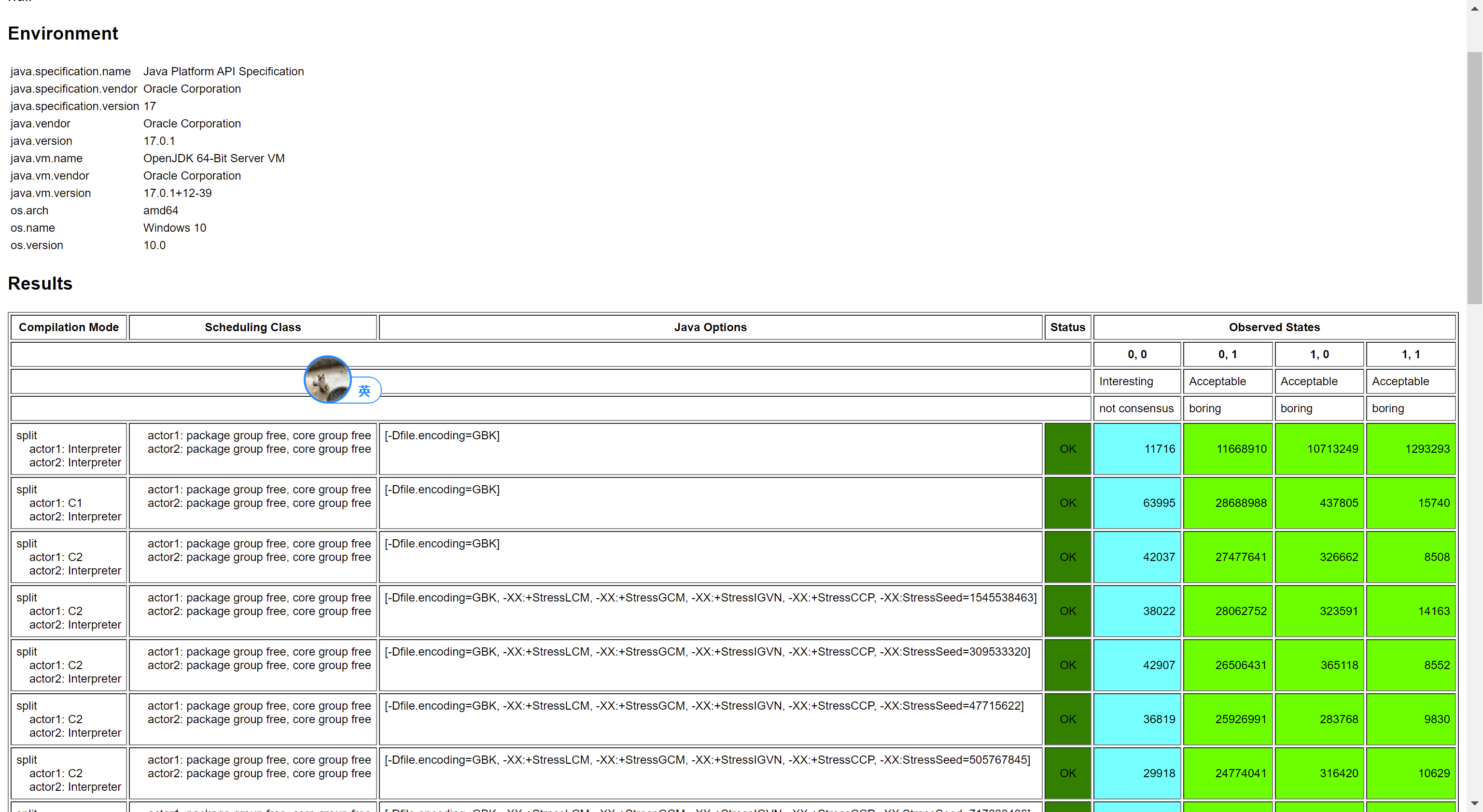
发现又乱序了。
所以,可以得出结论,这个 StoreLoad 是加在 Volatile 写之后的,在后面的 JVM 底层源码分析我们也能看出来。
7.4 Final 的作用Java 中,创建对象通过调用类的构造函数实现,我们还可能在构造函数中放一些初始化一些字段的值,例如:
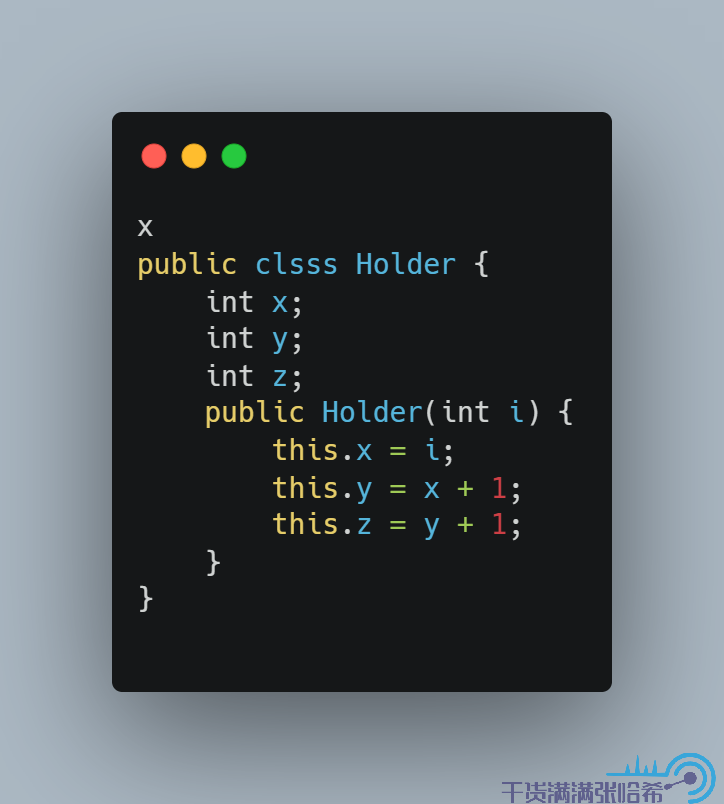
我们可以这样调用构造器创建一个对象:
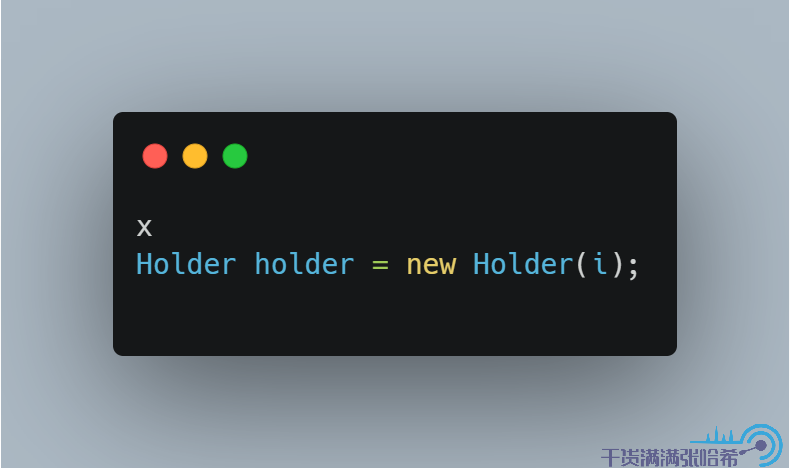
我们合并这些步骤,用伪代码表示底层实际执行的是:
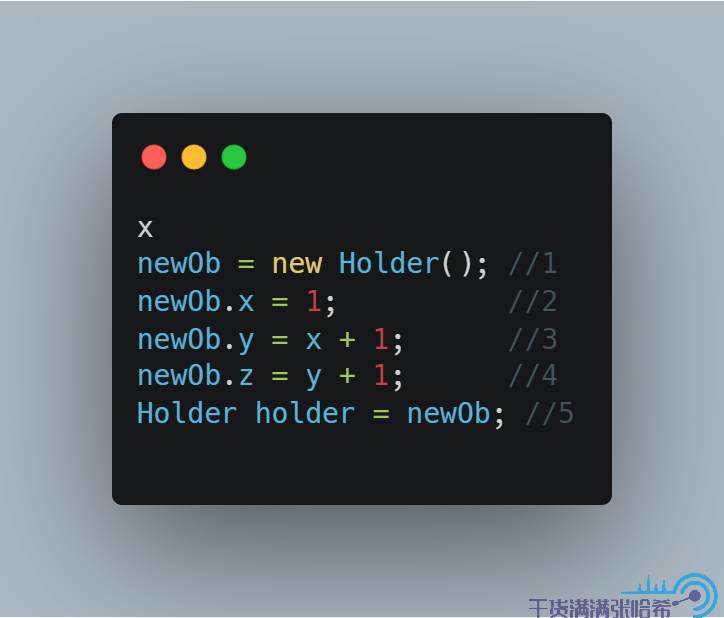
他们之间,没有任何内存屏障,同时根据语义分析,1 和 5 之间有依赖关系,所以 1 和 5 的前后顺序不能变。1,2,3,4 之间有依赖,所以 1,2,3,4 的前后顺序也不能变。2,3,4 与 5 之间,没有任何关系,他们之间的执行顺序是可能乱序的。如果 5 在 2,3,4 中的任一一步之前执行,那么就会造成我们可能看到构造器还未执行完,x,y,z 还是初始值的情况。测试下:
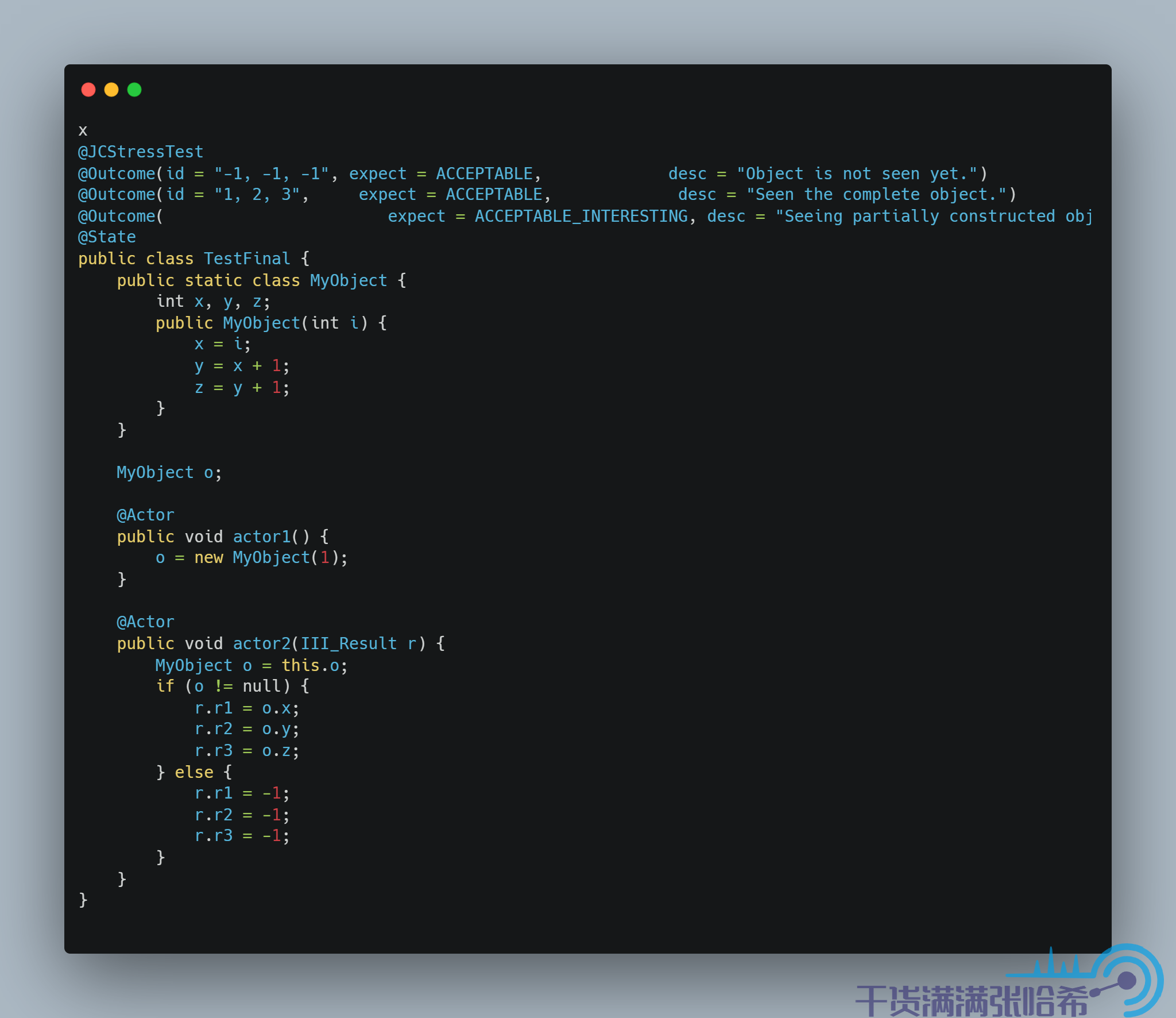
在 x86 平台的测试结果,你只会看到两个结果,即 -1, -1, -1(代表没看到对象初始化)和 1, 2, 3(看到对象初始化,并且没有乱序),结果如下图所示(AMD64 是一种 x86 的实现):
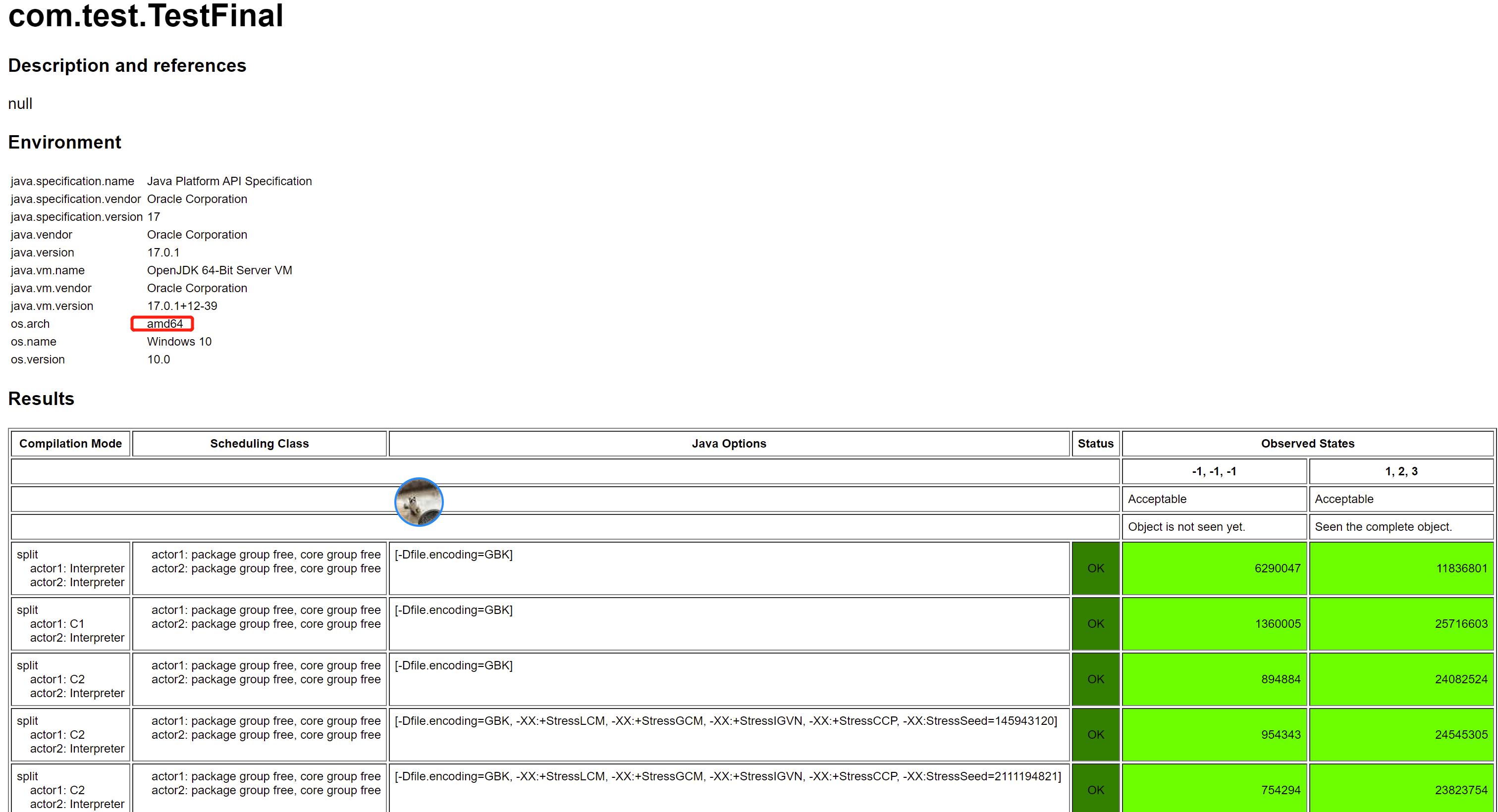
这是因为,前文我们也提到过类似的, x86 CPU 是比较强一致性的 CPU,这里不会乱序。至于由于 x86 哪种不乱序性质这里才不乱序,我们后面会看到。
还是和前文一样,我们换到不那么强一致性的 CPU (ARM)上执行,这里看到的结果就比较热闹了,如下图所示(aarch64 是一种 ARM 实现):

那我们如何保证看到构造器执行完的结果呢?
用前面的内存屏障设计,我们可以把伪代码的第五步改成 setRelease,即:
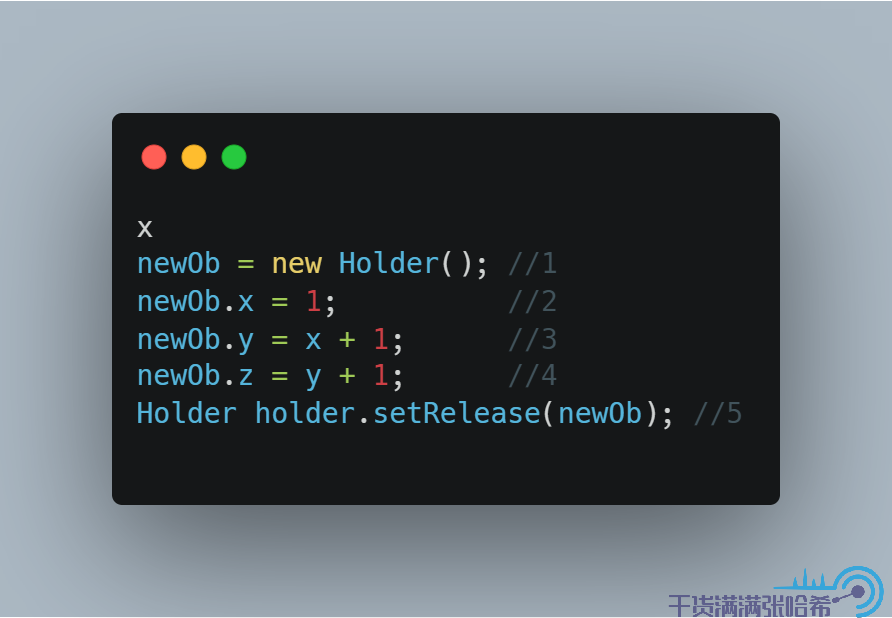
前面我们提到过 setRelease 会在前面加上 LoadStore 和 StoreStore 屏障,StoreStore 屏障会防止 2,3,4 与 5 乱序,所以可以避免这个问题,我们来试试看:
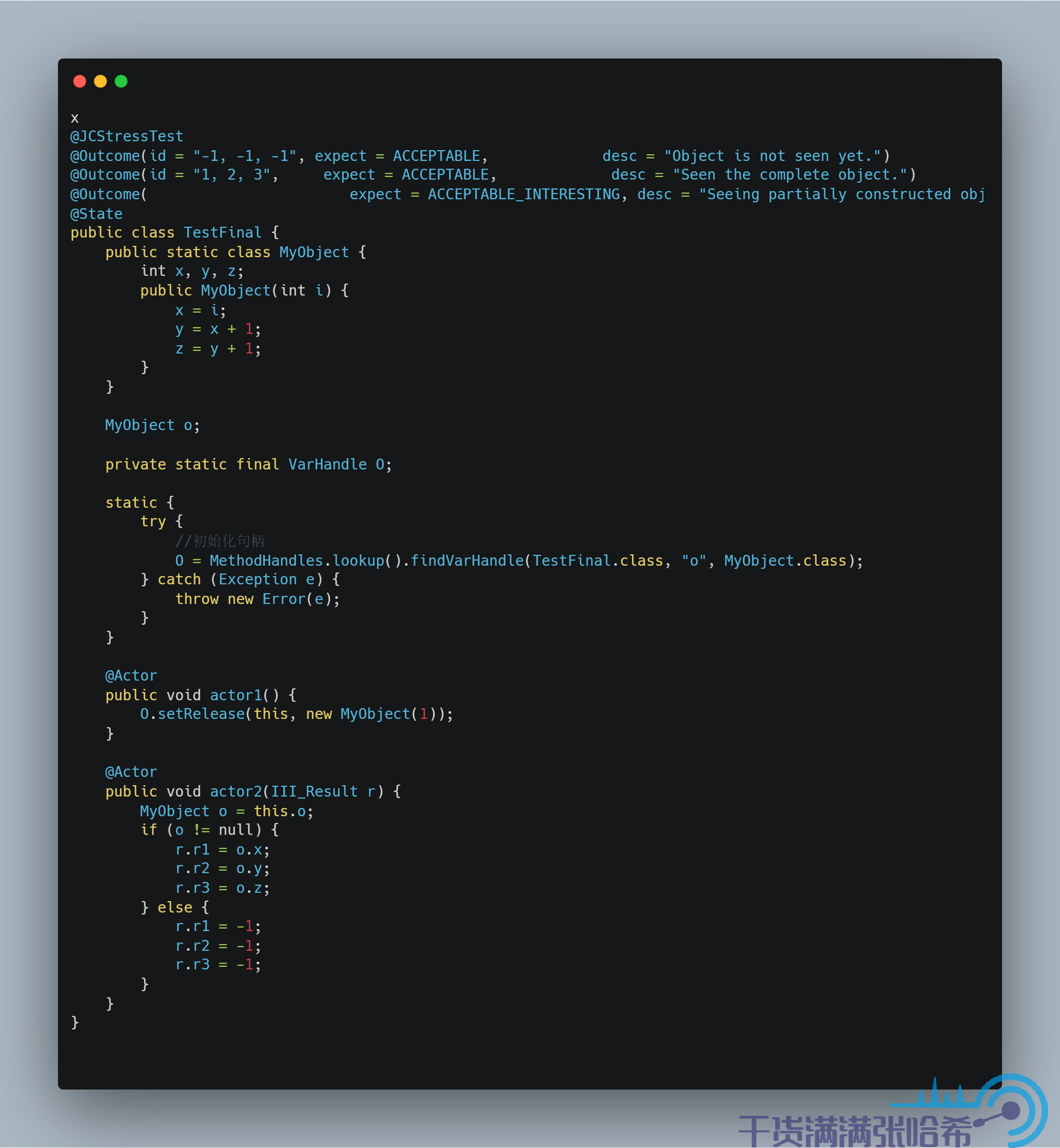
再到前面的 aarch64 机器上试一下,结果是:
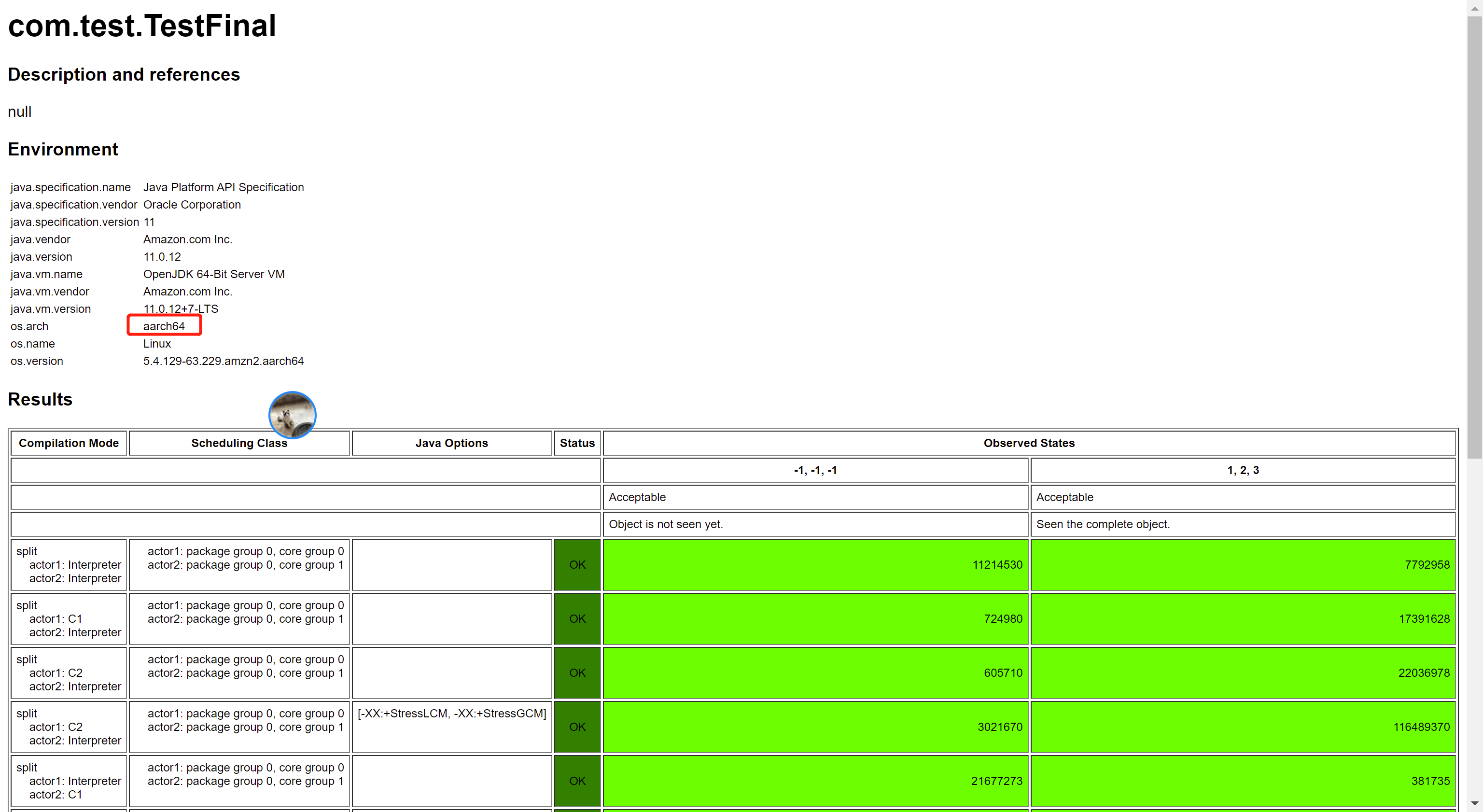
从结果可以看出,只能看到要么没初始化,要么完整的构造器执行后的结果了。
我们再进一步,其实我们这里只需要 StoreStore 屏障就够了,由此引出了 Java 的 final 关键字:final 其实就是在更新后面紧接着加入 StoreStore 屏障,这样也相当于在构造器结束之前加入 StoreStore 屏障,保证了只要我们能看到对象,对象的构造器一定是执行完了的。测试代码:
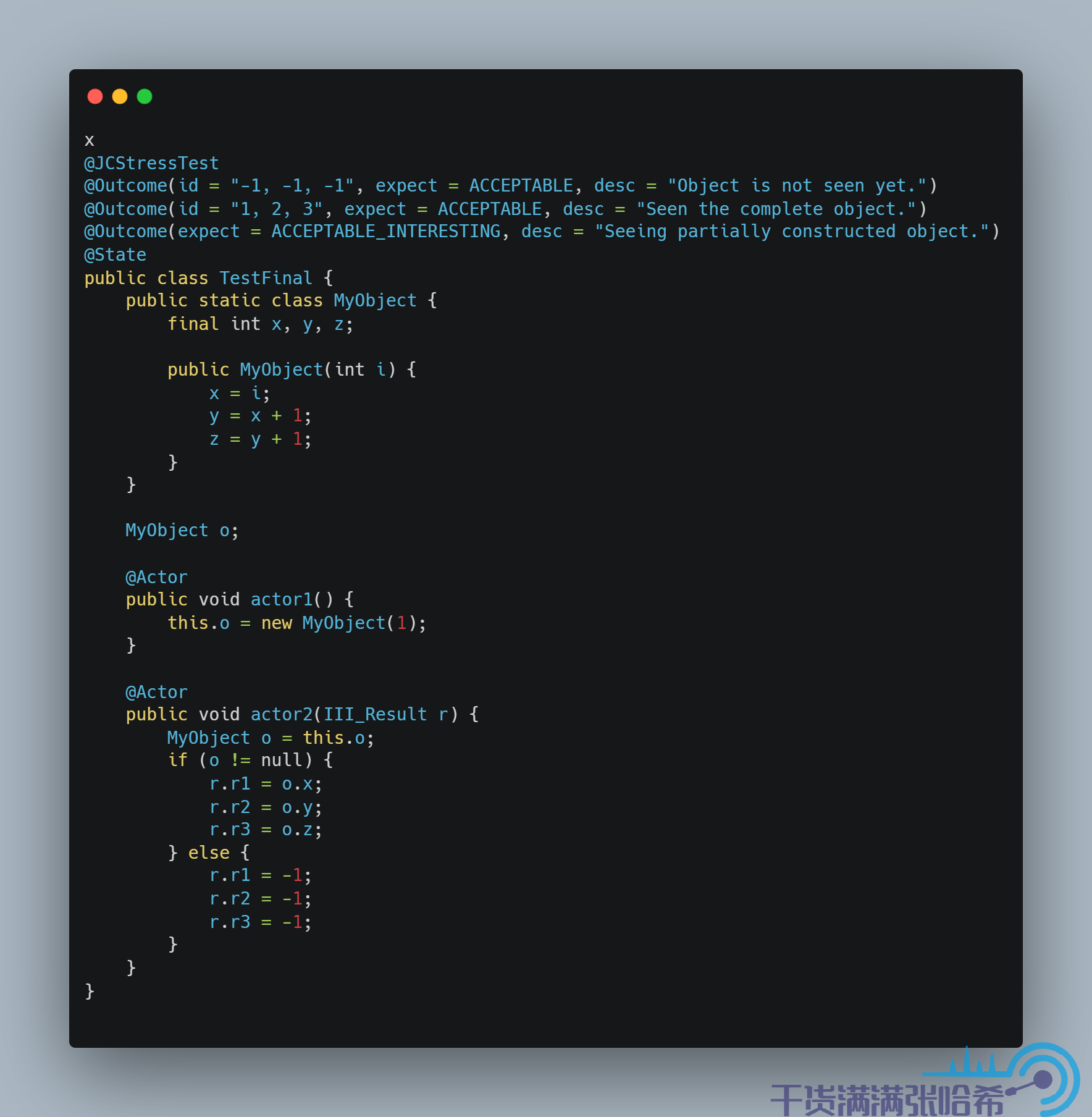
我们再进一步,由于伪代码中 2,3,4 是互相依赖的,所以这里我们只要保证 4 先于 5 执行,那么2,3,一定先于 5 执行,也就是我们只需要对 z 设置为 final,从而加 StoreStore 内存屏障,而不是每个都声明为 final,从而多加内存屏障:
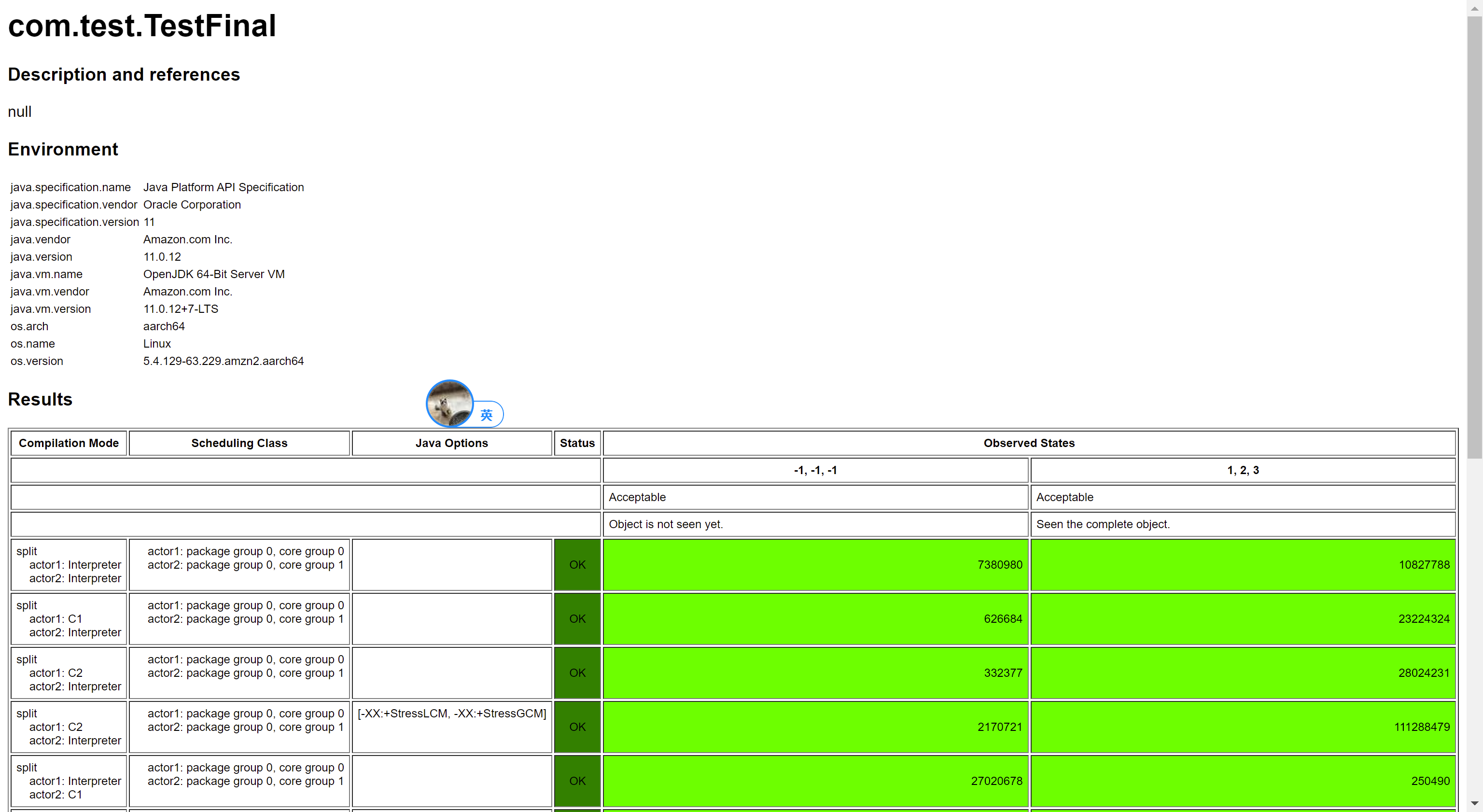
然后,我们继续用 aarch64 测试,测试结果依然是对的:
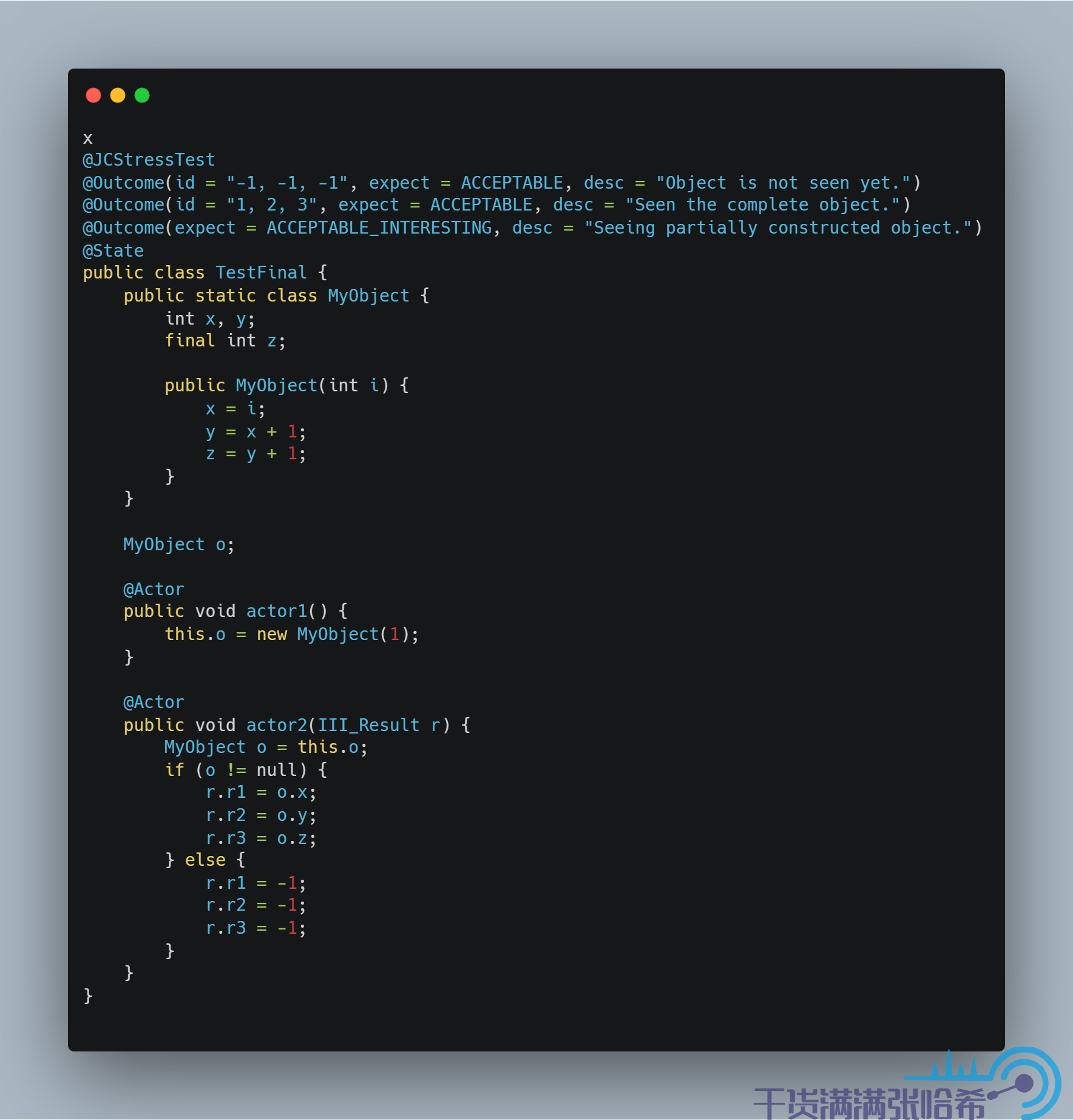
最后我们需要注意,final 仅仅是在更新后面加上 StoreStore 屏障,如果你在构造器过程中,将 this 暴露了出去,那么还是会看到 final 的值没有初始化,我们测试下:
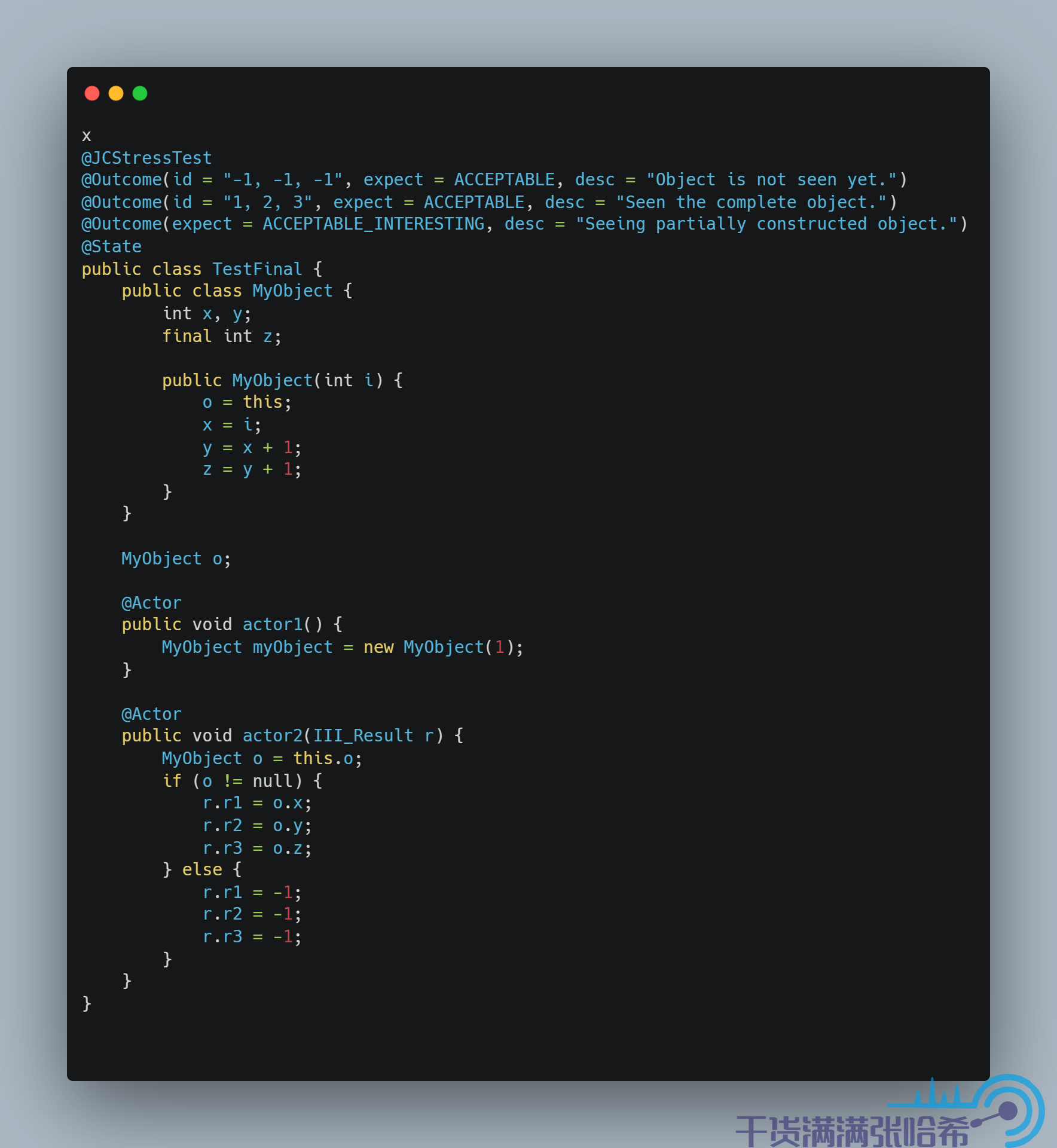
这次我们在 x86 的机器上就能看到 final 没有初始化:
最后,为何这里的示例中 x86 不需要内存屏障就能实现,参考前面的 CPU 图:
x86 本身 Store 与 Store 之间就不会乱序,天然就有保证。
最后给上表格:
JVM 中有各种用到内存屏障的地方:
- 实现 Java 的各种语法元素(volatile,final,synchronized,等等)
- 实现 JDK 的各种 API(VarHandle,Unsafe,Thread,等等)
- GC 需要的内存屏障:因为要考虑 GC 多线程与应用线程(在 GC 算法中叫做 Mutator)的工作方式,究竟是停止世界(Stop-the-world, STW)的方式,还是并发的方式
- 对象引用屏障:例如分代 GC,复制算法,年轻代 GC 的时候我们一般是从一个 S 区复制存活对象到另一个 S 区,如果复制的过程,我们不想停止世界(Stop-the-world, STW),而是和应用线程同时进行,那么我们就需要内存屏障,例如;
- 维护屏障:例如分区 GC 算法,我们需要维护每个区的跨区引用表以及使用情况表,例如 Card Table。这个如果我们想要应用线程与 GC 线程并发修改访问,而不是停止世界,那么也需要内存屏障。
- JIT 也需要内存屏障:同样地,应用线程究竟是解释执行代码还是执行 JIT 优化后的代码,这里也是需要内存屏障的。
这些内存屏障,不同的 CPU,不同的操作系统,底层需要不同的代码实现,统一的接口设计是:
源代码地址:orderAccess.hpp
不同的 CPU,不同的操作系统实现是不一样的,结合前面 CPU 乱序表格:
我们来看下 linux + x86 的实现:
源代码地址:orderAccess_linux_x86.hpp

对于 x86,由于 Load 与 Load,Load 与 Store,Store 与 Store 本来有一致性保证,所以只要没有编译器乱序,那么就天生有 StoreStore,LoadLoad,LoadStore 屏障,所以这里我们看到 StoreStore,LoadLoad,LoadStore 屏障的实现都只是加了编译器屏障。同时,前文中我们分析过,acquire 其实就是相当于在 Load 后面加上 LoadLoad,LoadStore 屏障,对于 x86 还是需要编译器屏障就够了。release 我们前文中也分析过,其实相当于在 Store 前面加上 LoadStore 和 StoreStore,对于 x86 还是需要编译器屏障就够了。于是,我们有如下表格:
我们再看下前面我们经常使用的 Linux aarch64 下的实现:
源代码地址:orderAccess_linux_aarch64.hpp
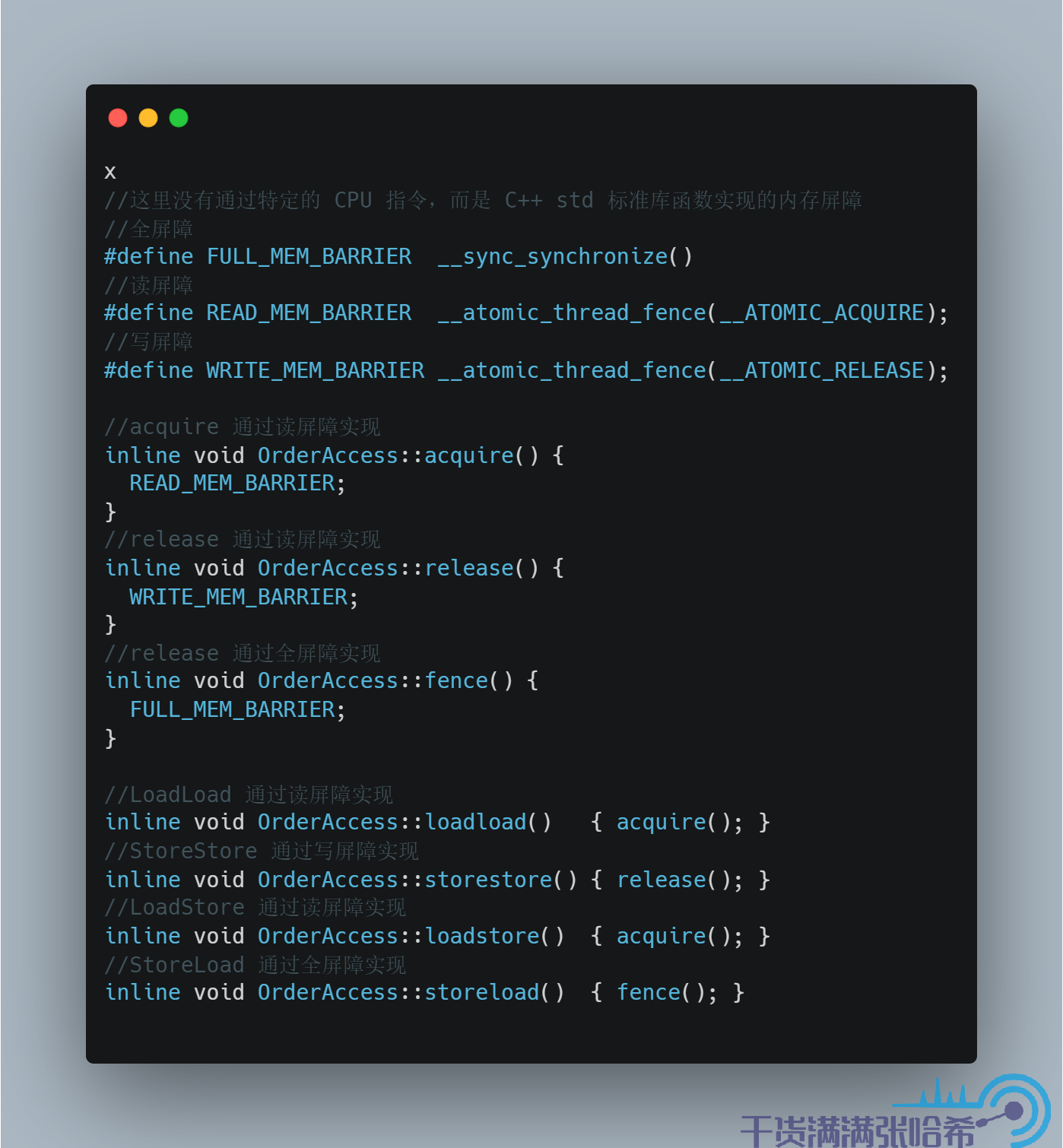
如前面表格里面说,ARM 的 CPU Load 与 Load,Load 与 Store,Store 与 Store,Store 与 Load 都会乱序。JVM 针对 aarch64 没有直接使用 CPU 指令,而是使用了 C++ 封装好的内存屏障实现。C++ 封装好的很像我们前面讲的简易 CPU 模型的内存屏障,即读内存屏障(__atomic_thread_fence(__ATOMIC_ACQUIRE)),写内存屏障(__atomic_thread_fence(__ATOMIC_RELEASE)),读写内存屏障(全内存屏障,__sync_synchronize())。acquire 的作用是作为接收点解包让后面的都看到包里面的内容,类比简易 CPU 模型,其实就是阻塞等待 invalidate queue 完全处理完保证 CPU 缓存没有脏数据。release 的作用是作为发射点将前面的更新打包发出去,类比简易 CPU 模型,其实就是阻塞等待 store buffer 完全刷入 CPU 缓存。所以,acquire,release 分别使用读内存屏障和写内存屏障实现。
LoadLoad 保证第一个 Load 先于第二个,那么其实就是在第一个 Load 后面加入读内存屏障,阻塞等待 invalidate queue 完全处理完;LoadStore 同理,保证第一个 Load 先于第二个 Store,只要 invalidate queue 处理完,那么当前 CPU 中就没有对应的脏数据了,就不需要等待当前的 CPU 的 store buffer 也清空。
StoreStore 保证第一个 Store 先于第二个,那么其实就是在第一个写入后面放读内存屏障,阻塞等待 store buffer 完全刷入 CPU 缓存;对于 StoreLoad,比较特殊,由于第二个 Load 需要看到 Store 的最新值,也就是更新不能只到 store buffer,同时过期不能存在于 invalidate queue 未处理,所以需要读写内存屏障,即全屏障。
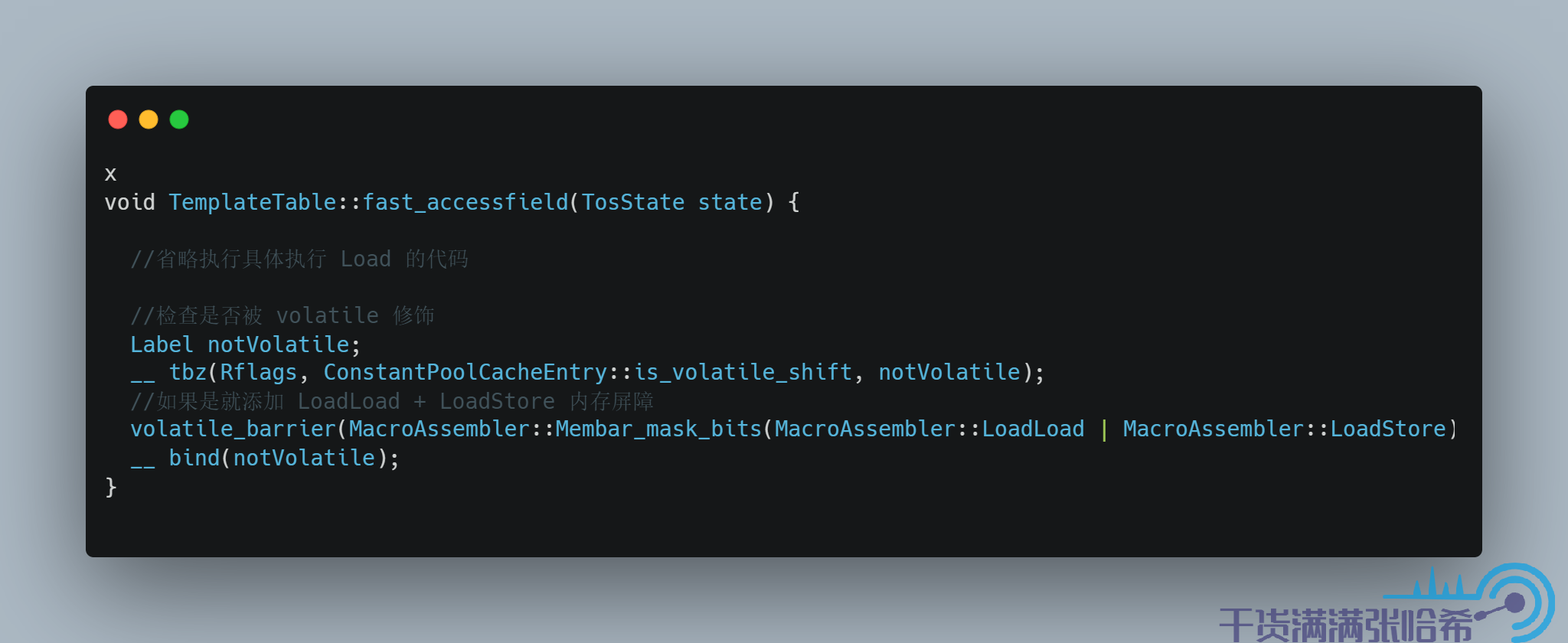
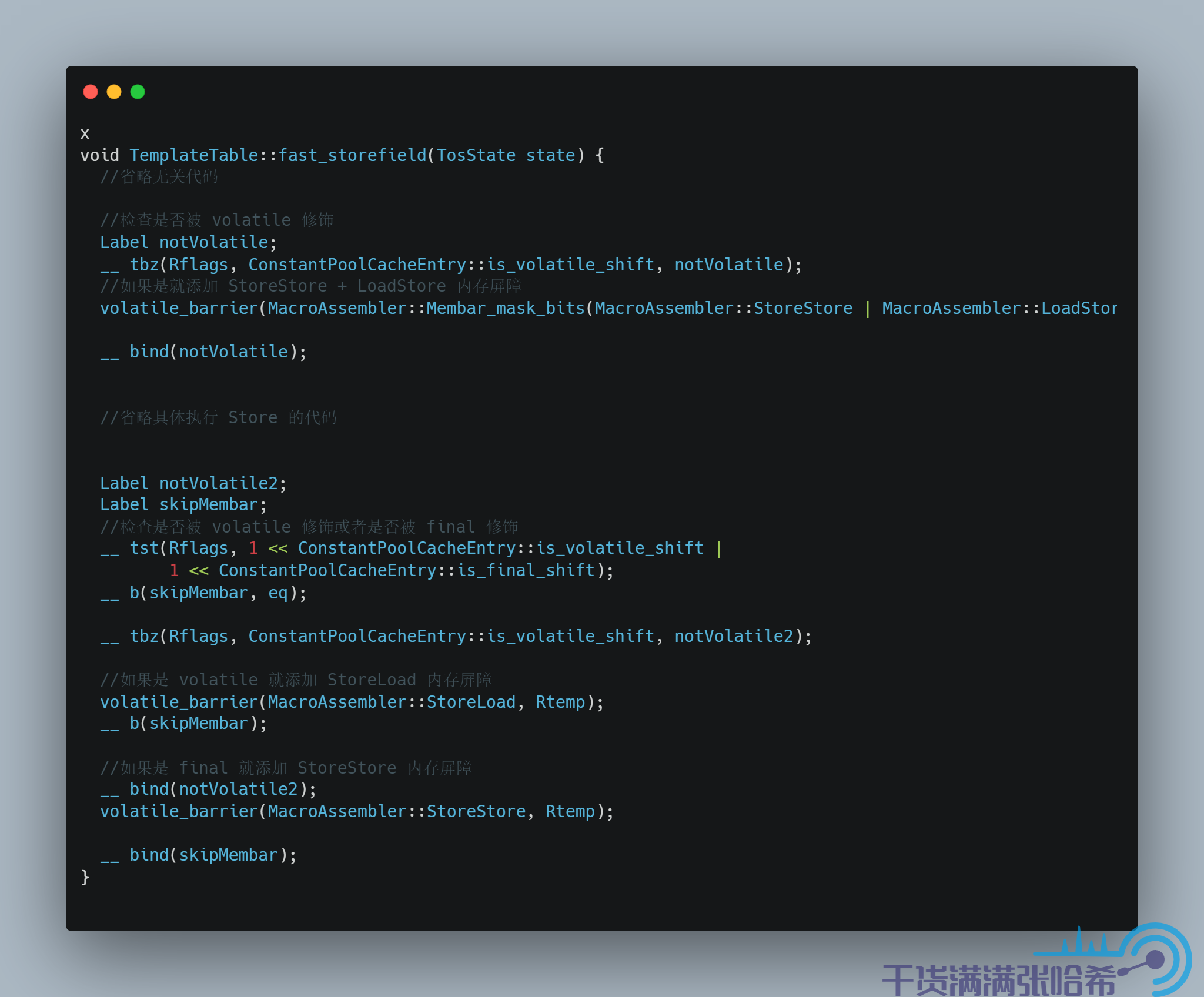
8.2. volatile 与 final 的内存屏障源码我们接下来看一下 volatile 的内存屏障插入的相关代码,以 arm 为例子. 我们其实通过跟踪 iload 这个字节码就可以看出来如果 load 的是 volatile 关键字或者 final 关键字修饰的字段会怎么样,以及 istore就可以看出来如果 store的是 volatile 关键字或者 final 关键字修饰的字段会怎么样
对于字段访问,JVM 中也有快速路径和慢速路径,我们这里只看快速路径的代码:
对应源码:
源代码地址:templateTable_arm.cpp
对于本地变量中的 final(和前面提到的修饰字段的 final 不是一回事),这个单纯从语义上讲,其实并没有什么性能方面的考虑,仅仅是作为一种标记。即:你可能在方法本地声明很多变量,但是为了语义清晰,就将肯定不会改的声明为 final。
JDK 的开发者一般用 final 本地变量来做这样一件事,假设有如下代码:

假设编译器不会做任何优化,那么 1,2,4 我们都各做了一次对于字段的访问。如果有编译器优化参与进来,那么是有可能优化成下面的代码的:
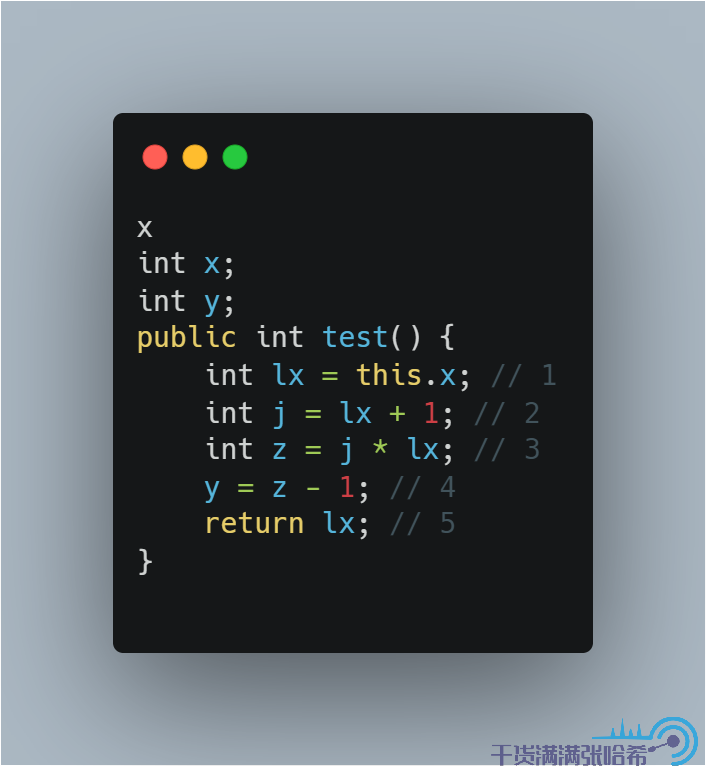
这样,只会读取 1 次 x 字段。这样造成的问题是,代码在被解释器执行,不同的 JIT 优化执行的时候,如果 x 有并发的更新,那么看到的可能的结果集是不一样的。为了避免这种歧义,如果我们确定我们这里的函数只想读取一次 x,那么就直接写成:

为了标记 lx 是不会变的(同时也为了表达我们只想读一次 x),加上 final,就变成:
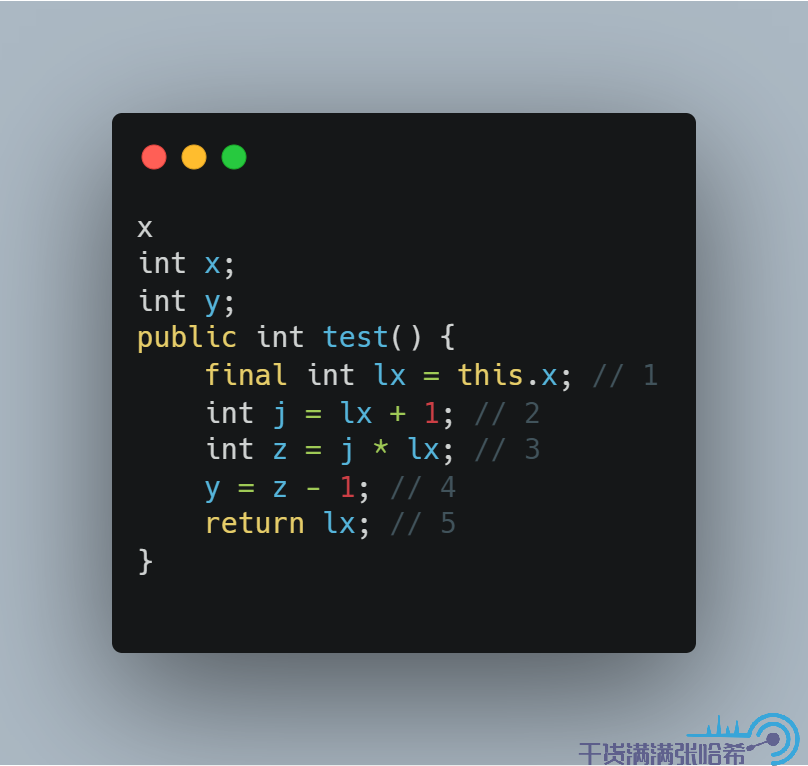
这个就不只是编译器乱序了,还涉及了 CPU 指令乱序以及 CPU 缓存乱序,需要内存屏障解决可见性问题。
我们从 Value 类的构造器入手:
对于 value = new Value(10); 这一步,将代码分解为更详细易于理解的伪代码则是:
这中间没有任何内存屏障,根据语义分析,1 与 5 之间有依赖关系,因为 5 依赖于 1 的结果,必须先执行 1 再执行 5。 2 与 3 之间也是有依赖关系的,因为 3 依赖 2 的结果。但是,2和3,与 4,以及 5 这三个之间没有依赖关系,是可以乱序的。我们使用使用代码测试下这个乱序:
虽然在注释中写出了这么编写代码的原因,但是这里还是想强调下这么写的原因:
- jcstress 的 @Actor 是使用一个线程执行这个方法中的代码,在测试中,每次会用不同的 JVM 启动参数让这段代码解释执行,C1编译执行,C2编译执行,同时对于 JIT 编译还会修改编译参数让它的编译代码效果不一样。这样我们就可以看到在不同的执行方式下是否会有不同的编译器乱序效果。
- jcstress 的 @Actor 是使用一个线程执行这个方法中的代码,在每次使用不同的 JVM 测试启动时,会将这个 @Actor 绑定到一个 CPU 执行,这样保证在测试的过程中,这个方法只会在这个 CPU 上执行, CPU 缓存由这个方法的代码独占,这样才能更容易的测试出 CPU 缓存不一致导致的乱序。所以,我们的 @Actor 注解方法的数量需要小于 CPU 个数。
- 我们测试机这里只有两个 CPU,那么只能有两个线程,如果都执行原始代码的话,那么很可能都执行到 synchronized 同步块等待,synchronized 本身有内存屏障的作用(后面会提到)。为了更容易测试出没有走 synchronized 同步块的情况,我们第二个 @Actor 注解的方法直接去掉同步块逻辑,并且如果 value 为 null,我们就设置结果都是 -1 用来区分
我分别在 x86 和 arm CPU 上测试了这个程序,结果分别是:
x86 - AMD64:
arm - aarch64:
我们可以看到,在比较强一致性的 CPU 如 x86 中,是没有看到未初始化的字段值的,但是在 arm 这种弱一致性的 CPU 上面,我们就看到了未初始化的值。在我的另一个系列 - 全网最硬核 Java 新内存模型解析与实验中,我们也多次提到了这个 CPU 乱序表格:
在这里,我们需要的内存屏障是 StoreStore(同时我们也从上面的表格看出,x86 天生不需要 StoreStore,只要没有编译器乱序的话,CPU 层面是不会乱序的,而 arm 需要内存屏障保证 Store 与 Store 不会乱序),只要这个内存屏障保证我们前面伪代码中第 2,3 步在第 5 步前,第 4 步在第 5 步之前即可,那么我们可以怎么做呢?参考我的那篇全网最硬核 Java 新内存模型解析与实验中各种内存屏障对应关系,我们可以有如下做法,每种做法我们都会对比其内存屏障消耗:
9.2.2.1. 使用 finalfinal 是在赋值语句末尾添加 StoreStore 内存屏障,所以我们只需要在第 2,3 步以及第 4 步末尾添加 StoreStore 内存屏障即把 a2 和 b 设置成 final 即可,如下所示:
对应伪代码:
我们测试下:
这次在 arm 上的结果是:
如你所见,这次 arm CPU 上也没有看到未初始化的值了。
这里 a1 不需要设置成 final,因为前面我们说过,2 与 3 之间是有依赖的,可以把他们看成一个整体,只需要整体后面添加好内存屏障即可。但是这个并不可靠!!!!因为在某些 JDK 中可能会把这个代码:
优化成这样:
这样 a1, a2 之间就没有依赖了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!所以最好还是所有的变量都设置为 final
但是,这在我们不能将字段设置为 final 的时候,就不好使了。
9.2.2.2. 使用 volatile,这是大家常用以及官方推荐的做法将 value 设置为 volatile 的,在我的另一系列文章 全网最硬核 Java 新内存模型解析与实验中,我们知道对于 volatile 写入,我们通过在写入之前加入 LoadStore + StoreStore 内存屏障,在写入之后加入 StoreLoad 内存屏障实现的,如果把 value 设置为 volatile 的,那么前面的伪代码就变成了:
我们通过下面的代码测试下:
依旧在 arm 机器上面测试,结果是:
没有看到未初始化值了
9.2.2.3. 对于 Java 9+ 可以使用 Varhandle 的 acquire/release前面分析,我们其实只需要保证在伪代码第五步之前保证有 StoreStore 内存屏障即可,所以 volatile 其实有点重,我们可以通过使用 Varhandle 的 acquire/release 这一级别的可见性 api 实现,这样伪代码就变成了:
我们的测试代码变成了:
测试结果是:
也是没有看到未初始化值了。这种方式是用内存屏障最少,同时不用限制目标类型里面不必使用 final 字段的方式。
9.2.2.4. 一种有趣但是没啥用的思路 - 如果是静态方法,可以通过类加载器机制实现很简便的写法如果我们,ValueHolder 里面的方法以及字段可以是 static 的,例如:
将 ValueHolder 作为一个单独的类,或者一个内部类,这样也是能保证 Value 里面字段的可见性的,这是通过类加载器机制实现的,在加载同一个类的时候(类加载的过程中会初始化 static 字段并且运行 static 块代码),是通过 synchronized 关键字同步块保护的,参考其中类加载器(ClassLoader.java)的源码:
ClassLoader.java
对于 syncrhonized 底层对应的 monitorenter 和 monitorexit,monitorenter 与 volatile 读有一样的内存屏障,即在操作之后加入 LoadLoad 和 LoadStore,monitorexit 与 volatile 写有一样的内存屏障,在操作之前加入 LoadStore + StoreStore 内存屏障,在操作之后加入 StoreLoad 内存屏障。所以,也是能保证可见性的。但是这样虽然写起来貌似很简便,效率上更加低(低了很多,类加载需要更多事情)并且不够灵活,只是作为一种扩展知识知道就好。
微信搜索“我的编程喵”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:
- 知乎:https://www.zhihu.com/people/zhxhash
- B 站:https://space.bilibili.com/31359187
