本篇参考:
https://max.book118.com/html/2017/1126/141669829.shtm
https://baike.baidu.com/item/5why%E5%88%86%E6%9E%90%E6%B3%95/575907
上课在项目质量管理的章节的管理质量中提出了根本原因分析工具,提了一下5 why分析法,感觉工作中这种思想还是会用到,所以简单查阅以后,闲聊一下5- why root cause分析法,并且以一个相关的项目例子来带入对自己也更好的了解。
5 why root cause分析
我们在做项目时,通常会遇见客户或者自己查到的问题,遇见问题以后,我们便会找到root cause,进行快速的紧急处理。当然,有的场景,这种root cause识别只是指标的对策,无法从根本上抑制这种问题以后继续发生。以后出现这种情况,包括但不限于继续在手动修改数据或者定期执行脚本修复等等。这种尽管可以解决问题,但是客户总归是不开心或者不一定买账的,这种root cause也不是真正意义上打破砂锅问到底的root cause。
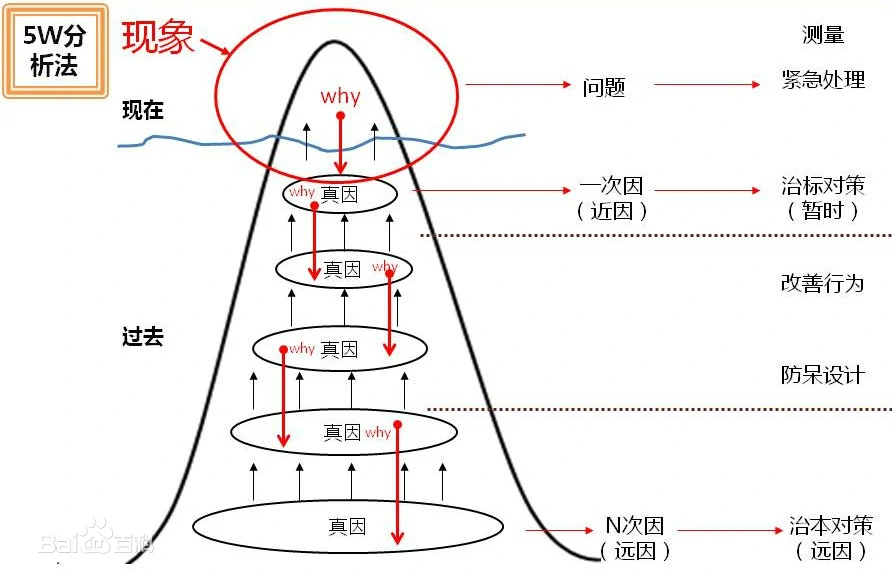
5 why分析法主要用于在品质问题分析和解决上,所谓5why分析法,又称“5问法”,也就是对一个问题点连续以5个“为什么”来自问,以追究其根本原因。虽为5个为什么,但使用时不限定只做“5次为什么的探讨”,主要是必须找到根本原因为止,有时可能只要几次,有时也许要十几次,5why法的关键所在:鼓励解决问题的人要努力避开主观或自负的假设和逻辑陷阱,从结果着手,沿着因果关系链条,顺藤摸瓜,直至找出原有问题的根本原因。5 why分析法可以通过4步来进行分解和操作。
一. 了解问题/ 现状
针对当前的问题,我们需要先了解现状,通常可以分成以下的几个步骤:
1. 识别/确认问题: 在最开始的阶段,你可能会得到一定的情报,但是无法得到详细的描述。这时候更关注的是我知道什么。比如当前页面崩了或者数据没有获取到。
2. 澄清(clarify)问题:在第一步的基础上,这步需要获取更精确的情报,而进行问题澄清继续提问。比如当前操作的步骤,正常的操作会发生什么?现在发生了什么?比如进行一个表单的提交,有一些条件没有满足,正常操作应该是在本页面提示哪些有问题,现在是直接跳转到共用的error页面了。
3. 分解(breakdown)问题:如果当前的问题,不是一个小的维度问题,需要进行更细化更独立元素,则需要进行问题的分解,比如关于当前的问题,我还知道什么?还有什么子问题吗?比如我们在做多系统交互集成时,出现了问题,澄清问题以后,可能还需要进一步的分解当前问题,才可以定位到哪一方的具体问题。
4. 查找原因要点(Point Of Cause):既然我们已经将一个问题分解成更细化的元素,这个阶段我们就需要找到这个问题原因的实际要点。为了确认root cause有必要进行逆向追溯,比如我需要看什么?谁可能更了解这个问题的信息?
5. 把握问题的倾向和特征: 什么时间?在哪? 什么频率?等等信息。比如这个问题什么时间发生的? 怎么操作的? 错误频率什么样是否可以复现等等。
注意点: 在我们问 why以前,了解上述问题很有必要
二. 调查原因
1. 识别并确认异常现象的直接原因。问题复现时,如果原因是可见的,验证它。如果原因是不可见的,考虑潜在原因并核实最可能的原因。这里可以问:
- 为什么会发生这个问题?
- 我能否看到这个问题的直接原因?
- 如果不能看到直接原因? 我怀疑什么是潜在原因?
- 怎么核实最可能的潜在原因?
- 怎么确认最直接原因?
2. 为了原因/ 影响关系使用 5 why调查方法,提出疑问。这里可以问:
- 我们选定的root cause能否预防这个问题再次发生?
- 如果无法预防的情况下,能否发现下一个阶段的原因?
- 如果发现不了下一个阶段原因, 能否怀疑什么是潜在原因?
- 如何检查和确认下一阶段原因?
- 处理这个水平(下一阶段)原因,能否预防这个问题再次发生?
针对必须处理以防止再发生的原因处停止的情况下问,需要问:
- 我已经找到问题的根本原因了吗?
- 解决这个问题能否预防再发生?
- 这个原因是否跟事实为依据的原因/影响有联系?
- 这个链通过 'therefore'测试了吗?
- 如果再问为什么,我还会遇到什么问题吗?
除此之外,确认已经使用“5个为什么”调查方法来回答这些问题。
- 为什么我们有了这个问题?
- 为什么问题会到达顾客处?
- 为什么我们的系统允许问题发生?
三. 问题纠正措施
1. 实施纠正措施,至少是临时措施。这里需要根据纠正措施还是临时措施来问:
使用临时措施来去除异常现象直到根本原因能够被处理掉。问:- 临时措施会遏止问题直到永久解决措施能被实施吗?
- 纠正措施会防止问题发生吗?
四. 防止错误预防
1. 防止root cause对策
2. 记录教训
demo引入
上面的概念都比较偏向于客观概念,很难读进去以及了解,下面以一个例子融入进去进行更好的通过 5 why 方式去穿插。

上图中是我们的一个项目的集成流向图。主要的需求为:
SF为某些表的源数据,比如SF为account的source of truth,前端系统想要使用account信息只能通过SF来同步,SF的account数据变化了也要实时的同步到前端系统。前端会作为一些自定义表的数据入口,然后通过 rest 调用中间件,中间件将报文整合以后,通过标准salesforce的REST API插入到salesforce,后续实现报表等需求。
每个平台都有一个 team lead,根据约定的开始干活了,等到客户UAT的时候,发现了一个问题: 前端数据做了数据(包含父子层级)以后,当在前端针对这个父层级的数据继续创建子以后,报错了。报错内容: 你所插入的数据,父数据在SF中不存在。你作为项目经理,如何通过5 why方式去找到 root cause并且去更好的给出方案?
第一部分,先了解问题和现状:
1. 根据这个报错,先澄清问题。正常现象应该是第一次已经发送了父子数据,SF端已经包含了父的数据,第二次直接创建子数据会关联到SF父数据,可以正常创建。实际问题是,当前端创建子数据时报错,SF端父数据不存在。
2. 分解一下问题。既然涉及到3端的系统,先询问一下SF的lead,这条父记录是否在SF端生成,是否按照前端的描述,SF端没有父数据。询问一下前端,除了这条数据是否还包括其他的数据?父子层级操作以前是否有什么特殊的报错信息等。
3. 查找问题要点(POC)。SF端反馈父端数据以及第一次子表数据已经顺利进入到SF端数据库了,不存在前端说的不存在场景。中间件端查看报文确实前端发送的报文中不包含父表数据ID,同时中间件端反馈没有通过LOG查看到中间件端没有订阅到这条数据的ID相关的数据消息。
4. 问题特征: 偶发性,不可复现。
第二部分,调查原因:
通过第一部分了解问题现状以后,我们发现 前端发送了父子表给SF端,SF端收到了,但是前端没有接收到SF端父子数据的ID,然后第二次创建子时,获取不到父的数据导致了报错。
1. 识别并确认异常现象的直接原因。直接原因是不可见的,潜在原因最可能的是: 当前端数据通过REST插入到SF以后,SF发送了 push topic,中间件会将ID信息再给挂到前端DB指定数据。但是 push topic因为SF国内没有服务器,会有延时,导致偶尔不会实时的广播出去,或者中间件端握手失败。前端获取到这条数据ID就会有延迟,在这个期间,再创建子数据时,就会报错,因为这条数据的ID还没有回写到前端。
2. 使用 5 why调查方法:这个选定的 root cause能否预防问题发生?不能,客户不会接受因为产品限制导致的这种偶发性的问题。如果不能情况下,我们想一下下一阶段的root cause,前端在做这个以前,需要先进行一下validation check,如果没有,则不执行,或者延后执行。继续思考,这个 root cause能否预防问题发生?答案是还是不能。因为如果 push topic半天才回来或者挂了今天就没有,但是这条数据着急,终端用户会很着急,是一个workaround方案,但是用户不一定会采纳这个建议。继续思考下一个阶段的 root cause, ID这种信息,中间件通过rest api调用成功以后,就可以获取到,这时就直接返回给前台,前台解析然后更新到DB,就可以不用 push topic发送ID信息,这样就可以大概率减轻问题发生。root cause能否预防问题发生? 貌似可以。
第三部分,问题纠正:
纠正措施:排期让中间件的response body修改一下,将父子文件的ID作为报文传回。前端修改一下解析部分,直接将ID更新到DB中,push topic只用于将 source of truth数据传递。
临时措施:有问题的情况下,AO先手动跑脚本保证数据正常运行。毕竟数据量不大,而且修改难度不高,不会block住后续流程运行。
第四部分,防止错误预防:
此问题更多是中间件的team member不太清楚rest api的文档内容,在解析处没有思考到直接传回,而是使用通用的push topic方式去接收,尽管省了effort,但是容易导致这种性能问题。SF端的同事也应该给予一些技术的支持和建议。
总结:不是所有的问题都一定适应这种模型分析,本质上这种情况适用于品质提升打破砂锅问到底的场景。以上的整理并不一定完全的合理,只是用于自己更好的了解这个步骤分析。篇中有错误地方欢迎指出,有不懂欢迎留言。